目录
- 生僻字消失?
- hexdump
生僻字消失?
前段时间遇到一个问题,对方系统确认推送的文件里客户姓名为3个字:倪明,中间字如下:
PS: 忽略上面的编码哈,只看汉字

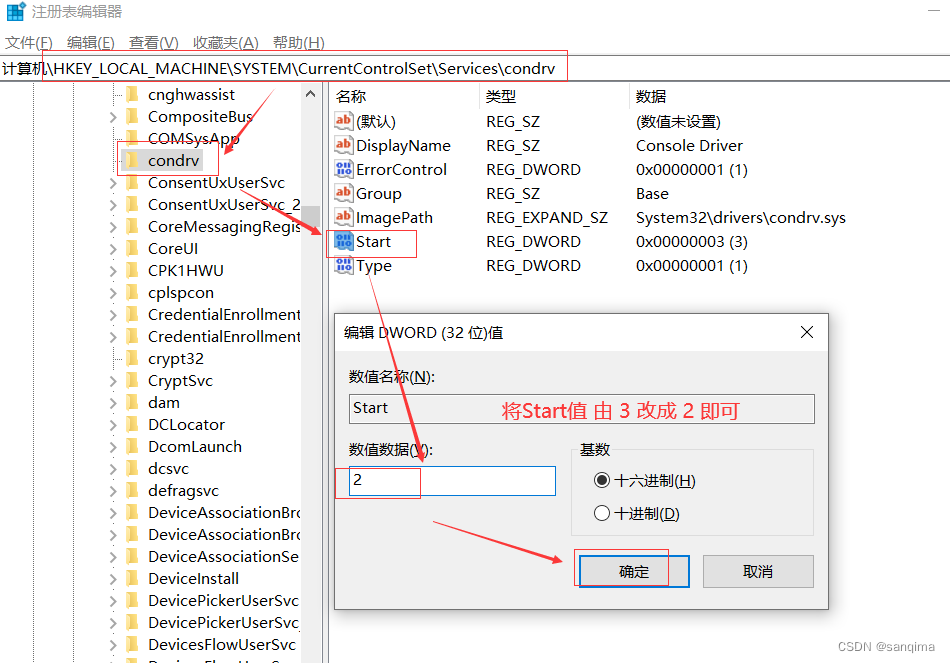
且文件为UTF8格式,本系统接收后转码为GB18030后,在服务器上cat 命令查看此行数据, 姓名如下图:中间看起来有个空格
倪 明|10|
hexdump
问题1: 对方系统的UTF8文件是否有这个生僻字
查看十六进制内容:

倪明的UTF8编码:
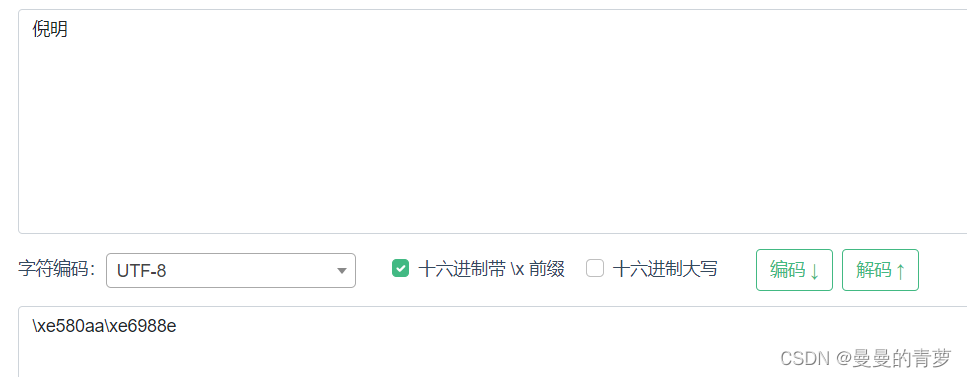
对比可以看出:中间生僻字的编码为:\xee90a1
将UTF8编码转换为unicode 编码–U+e421, 转换规则参考:
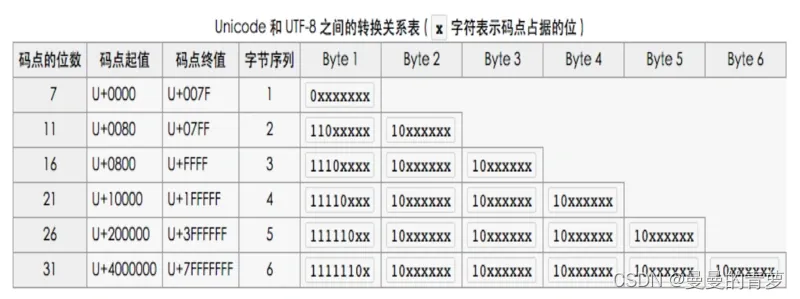
而unicode 这个区是属于私有区:
补充知识: 主要私有区由U+E000到U+F8FF范围内的代码点组成,总共6400个私有字符。
编码结构。按照惯例,主要私有区被划分为平台编写器的公司级使用分区,从U+F8FF开始向下扩展,以及从U+E000开始向上扩展的最终用户分区。
问题2:转码后GB18030是否有这个生僻字
查看十六进制内容:

倪明的GB18030编码:
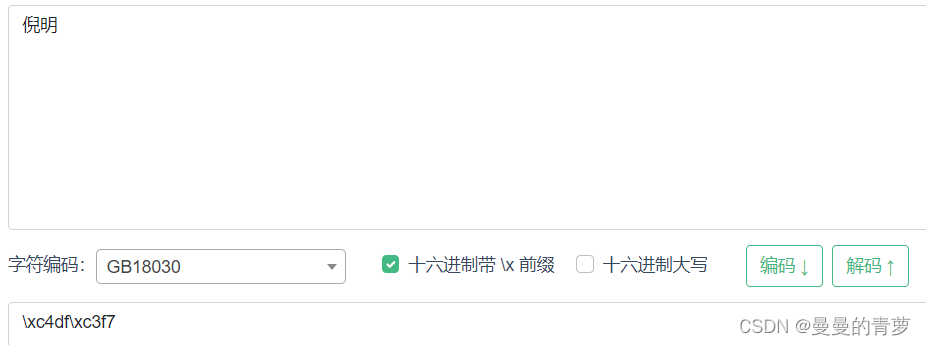
对比可知生僻字的GB18030 编码为\xfdb8
属于用户自定义区2 属于字库中不存在的字,所以终端没有显示

具体的GB18030 可以下载完整文件:
国家标准全文公开系统–GB18030编码表文件
疑问:
Q1. 图片中的码值为啥与实际文件中的值不一致呢
A1: 姓名生僻字处理平台—此网站写得挺明白的,生僻字会有正式码值与PUA码两种编码形式,而公安部是使用PUA编码,而图片中的码值却属于正式码。对于我的业务场景,此客户是需要过联网核查系统,故这里使用的是PUA码值。
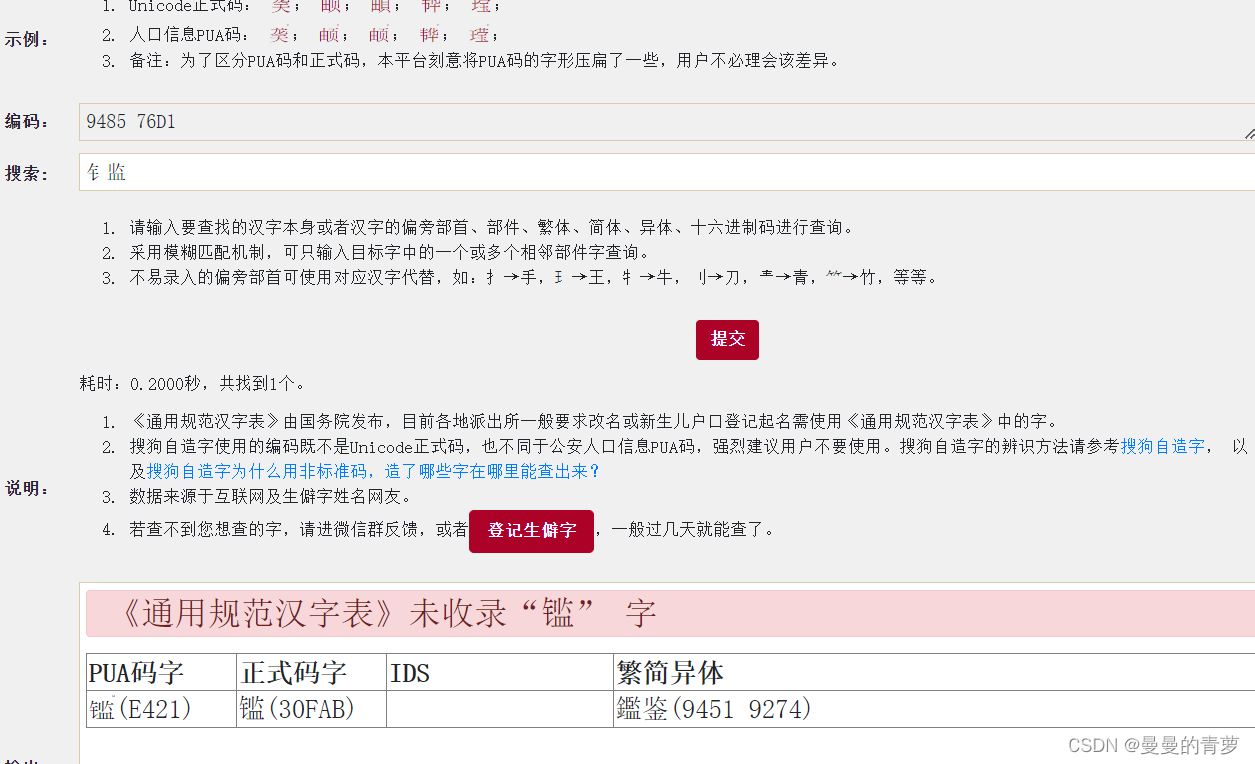
参考链接:–宝藏网站
汉字字符集编码查询
姓名生僻字处理平台