End-to-end Autonomous Driving: Challenges and Frontiers
文章脉路
Introduction
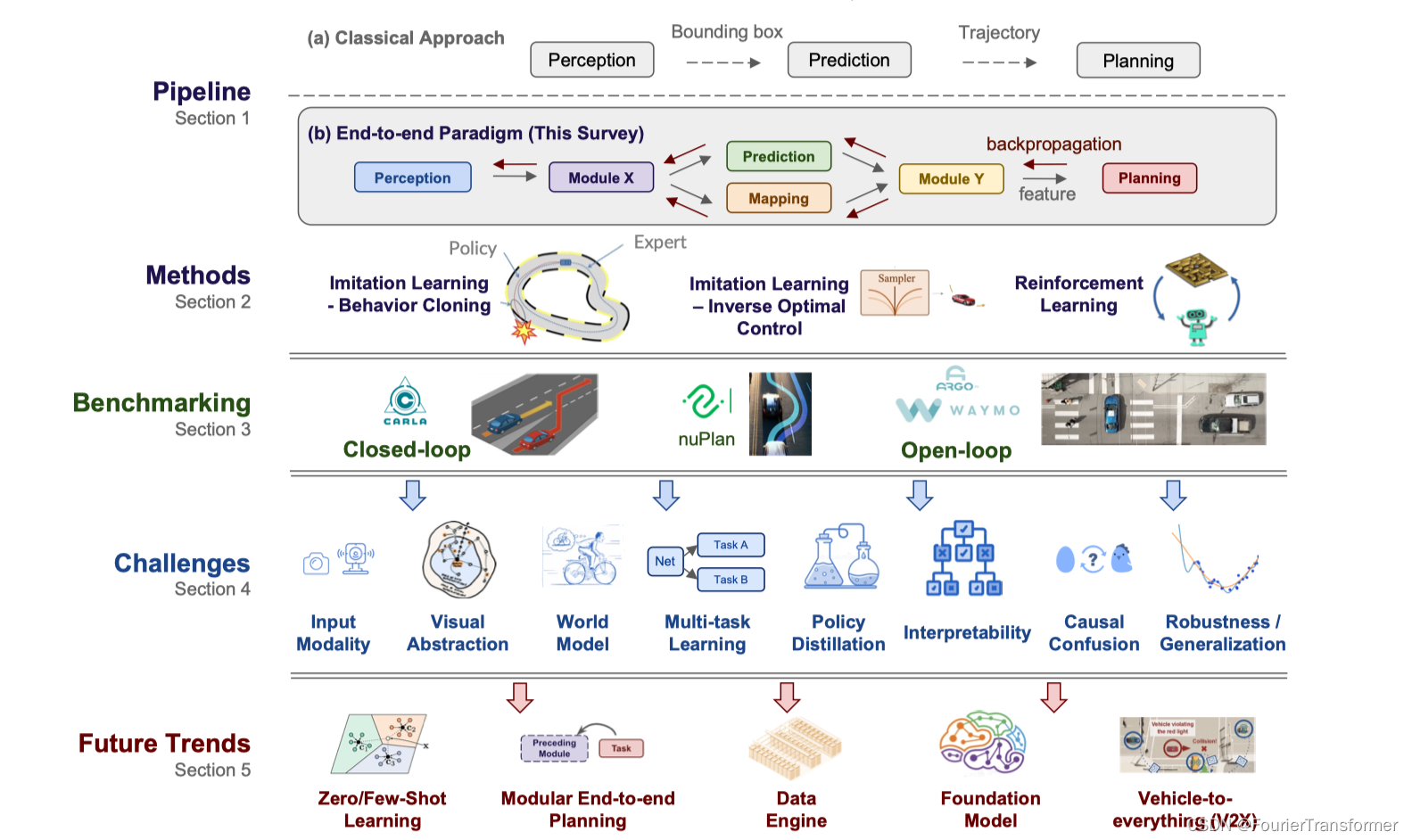
- 从经典的模块化的方法到端到端方法的一个对比, 讲了各自的优缺点, 模块化的好处是各个模块都有自己明确的优化的目标, 可解释性较强, 且容易debug, 缺点是各个模块优化的目标并不是最终的驾驶任务, 并且每个模块的误差容易往下游累积; 而端到端的优点就是可以global的优化, 以最终的驾驶为目的, 通过全局可微分的方式, 通过送入大量数据学到驾驶能力; 把整个问题归化成了, 数据和网络本身,而不再是corner-case的解决方式;
- 但是有一点需要注意, 端到端并不意味着,输入传感器数据,用一个黑盒子仅仅输出驾驶行为; 可以是模块化的方式, 如上图中的(b), 可以通过feature来贯穿始终; 而且可以做成multi-task learning的方式.
Roadmap
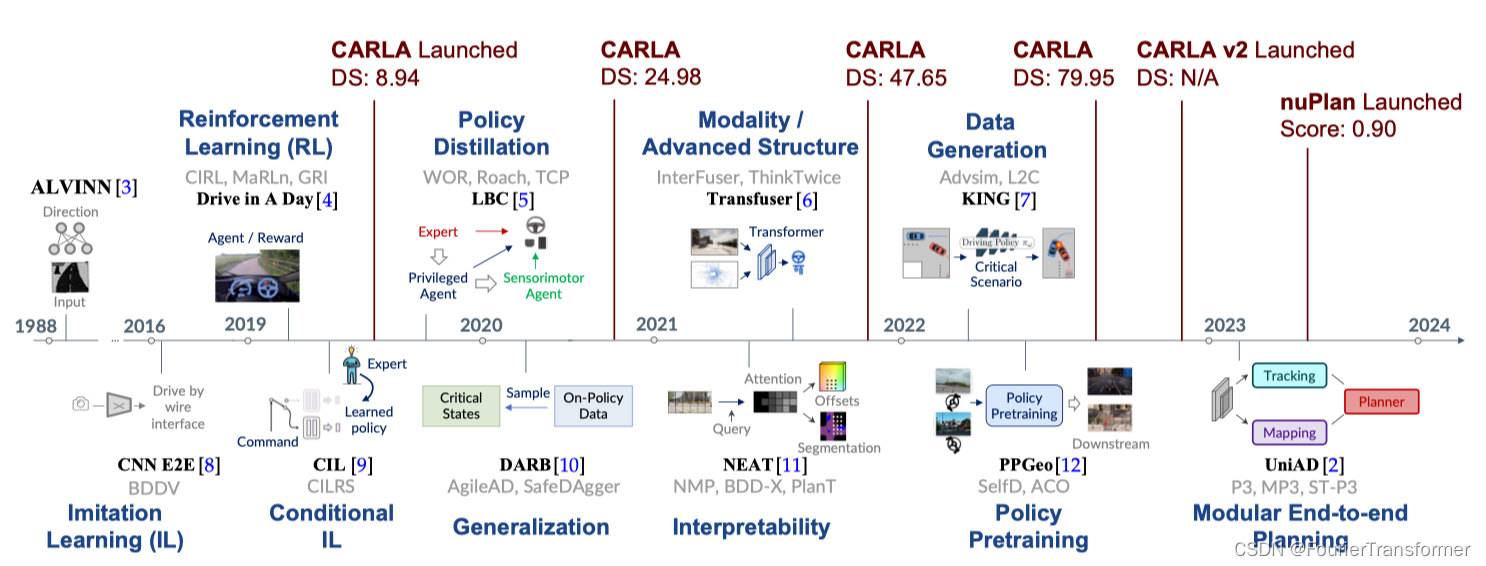
● 1988. ALVINN 输入camera和laser range finder, 经过一个简单的NN得到 steering output.
Methods
Imitation Learning
任务描述, 是学习到一个policy 逼近 expert的policy.

Imitation learning 又分成了两大类, 分别是
BC: behavior cloing
‒ 简单,有效, 不需要手工设计,
‒ 在训练的时候, BC 会把每一个状态看成是独立同分布的, 这会导致一个问题, 叫 “covariate shift”;
‒ 我理解这里的独立同分布指的就是训练的时候, 数据集中的{(s, a)} 是以相同的概率被采样的.即一个状态对应着一个action; 那如果训练的时候没有见过某个state时, 模型就不知道该怎么做了, 独立同分布可以理解为没有任何规律可严; 比如训练的时候见到的都是路口停车等待的情况, 那如果测试的时候, 路口一辆车都没有, 哪怕是绿灯, 模型可能都不知道是要往前走的;
IOC: inverse Optimal Control 或者是 invese RL.
他们和强化学习的区别可以用一个图来看出来
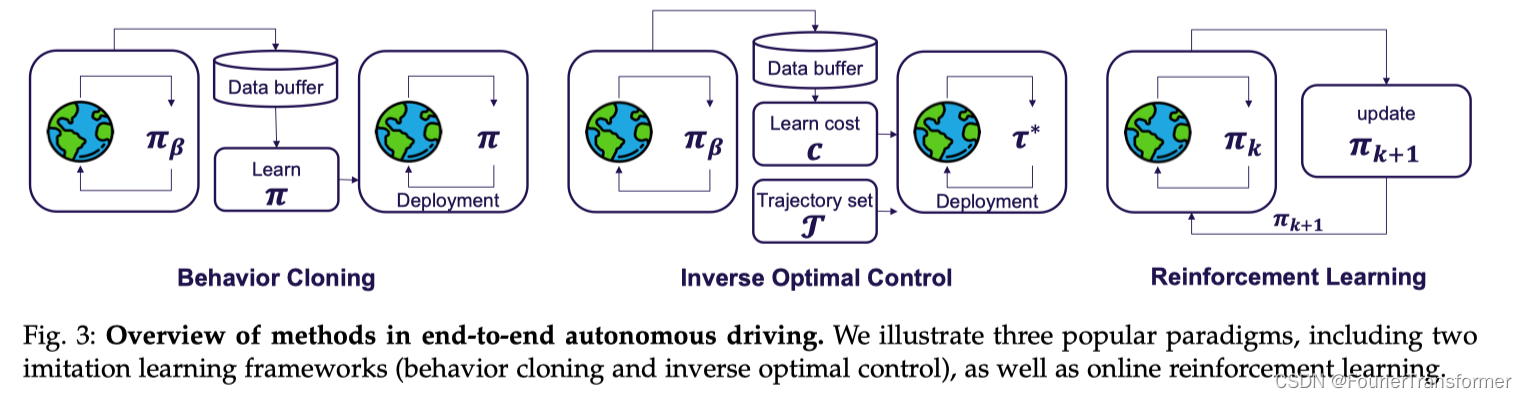
- BC是输入原始数据, 学习专家的policy,即看专家基于这些数据是如何做的;
- IOC是输入原始数据, 构建一个cost, 在实际用的时候, 会有不同cost的输出选择, 可以基于某种方式选择一个最好的, 比如说选择cost最低的; 代表作可以看NMP[32]
- RL即强化学习, 根据环境不断地回馈与迭代;
Challenges
多模态问题
不同的模态如何融合
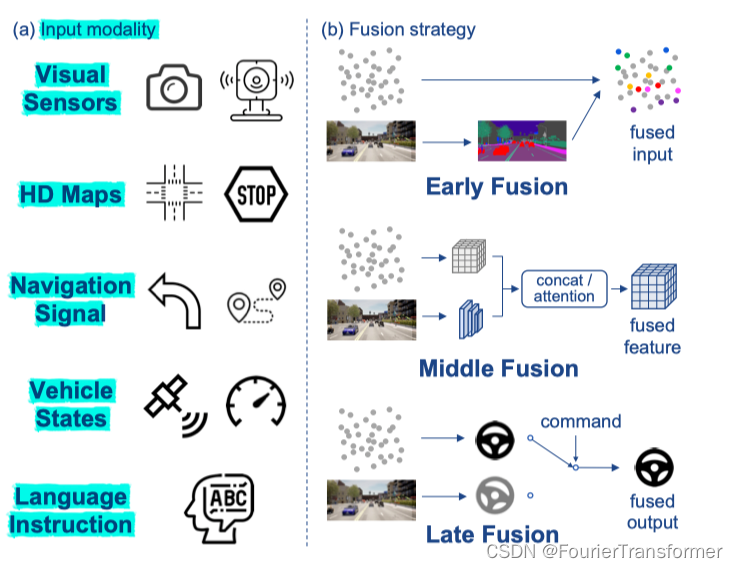
这里面很重要的一个是
Language as input
Visual Abstraction
作者把端到端的AD任务分成了两个阶段:
- 编码阶段, 即把state space 编码成为一个latent feature representation.
- 解码阶段, 用中间feature, 解码得到driving policy, 或者其他的输出;
这里面相关的工作有, PPGeo, 它是为了学到一个好的和自驾相关的visual encoder;
World Model
什么是world model, world model 就是理解世界, 理解过去发生的事情, 并能预测将来;
这里面提到, 在图像空间里面做world model不太容易(即预测接下来的图片), 比如一些很重要的细节, 像交通信号灯的变化等就很容易在预测的图片中丢失;
MILE就是把这个难度降低成为了, bev-semantic-segmentation. 这也从某种程度上代表了世界的演化, 所以mile确实是一个world model; 或者说是把world model融合进了policy learning里面了; 或者说把 Dreamer-style world model learning 当成了一个辅助的任务; 想想也自然, 即要想开好车, 首先得理解周围的世界; 这样才会对世界有一个判断和预测;
Multi-task learning with Policy prediction
为什么要做multi-task learning?
除了polcy prediction之外, 加一些其它的任务进来, 还是希望模型确实能够学到对于当前环境的理解;
比如对于图像的输入, 可以加入的有语义分割, 或深度估计,
语义分割是为了让模型学习到场景信息, 添加深度估计是为了让模型学习到几何空间信息;
而且这些辅助任务的增加,对于增加可解释性,也起到了至关重要的作用;
Policy Distillation
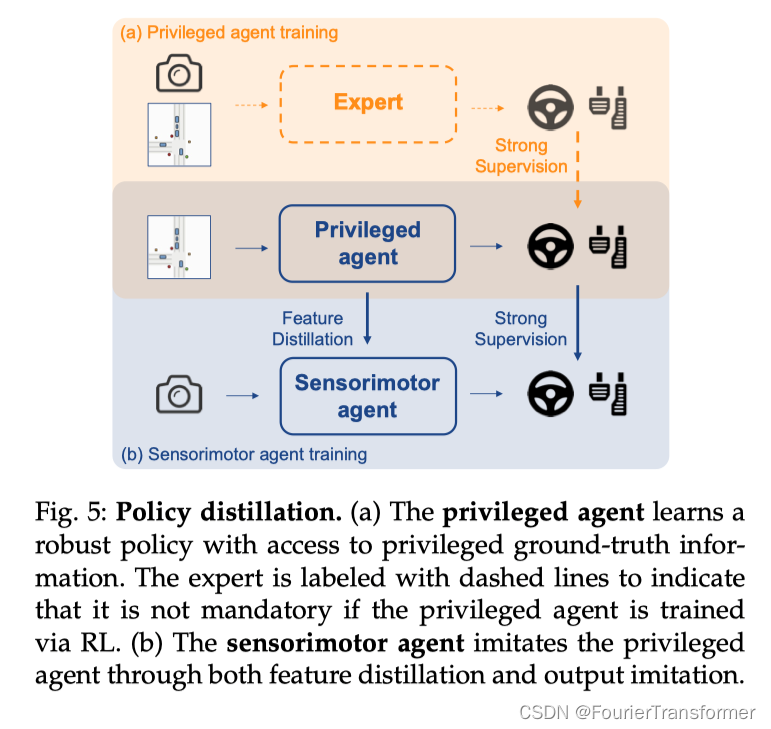
● Expert
专家会根据自身的观测, 比如图片和bev结果(不是真值), 来去采取具体的行动(专家自己的行动, 不一定是标准的GT);
● 特权的agent, 直接能够拿到bev的真值, 也能够拿到 ground truth的行动;
● sensorimotor agent 就是一个普通的agent, 只有传感器的输入,
举一个例子, 拿侧方停车为例, 教练就是专家, 教练会根据观测(看后视镜),产生他自己对于环境的理解(BEV), 通过他自己的经验, 做出具体的判断; 可能和标准的行驶轨迹不完全一样, 但是却是合理的; 这里教练对于环境的理解不一定全对, 比如有盲区没有看到;
而Privileged agent 可以理解为全程拿着360的bev结果, 无死角,无盲区, 全程不需要看后视镜, 好像有人告诉他该怎么开一样, 而且采取的行动就是标准答案;
而sensorimotor agent 就可以理解为一个考生了, 完全要靠看后视镜, 才能采取行动;
Interpretability
- 可视化中间的feature, 这种太抽象, 不好理解, 无法评测
- 通过可解释的任务, 比如 semnatic segmentation, depth estimation, object detection, 等任务,
- Cost-learning. 提供一个有意义的cost 函数, 也可以具有可解释性;
- 通过语言进行解释,
- 不确定性建模, 没太理解
Future trends
Modular end to end planning
模块化的端到端, 像Tesla和Wayve 都是这么做的; 但是模块化设计的时候, 不知道什么样的任务是好的,
比如对于感知模块而言, 不知道是目标检测, occupancy,
再比如 bev分割和车道拓扑map, 哪个任务更好;
Foundation Model

自驾的模型的输出得是稳定且精确的, 但是LLM这种生成式的输出只是表现的像一个人, 但是其实并不精确; 所以对于自动驾驶来说, 如何设计一个模型,让其能够稳定地预测 长时间的 2d 或者是3d是非常重要的; 只有这点做到了, 才算自驾中的一个foundation model; 这样的模型才能够再下游的planning任务上有用;