问题:
现在已知有一个16进制字符串
435550D3C3D3DAD4DABDBBD2D7CFECD3A6CFFBCFA2D6D0B4E6B7C5D5DBBFDBD0C5CFA2A3ACD5DBBFDBBDF0B6EE3130302E3036
而且知道这串的字符串对应的内容是:
CUP用于在交易响应消息中存放折扣信息,折扣金额100.06
但是这个怎么对应的呢,怎么转换来的呢?
一脸问号???
慢慢看:ASCII 编码表 - 在线工具
43 对应ASCII编码的 C 字母
55 对应ASCII编码的 U 字母
50 对应ASCII编码的 P 字母3130302E3036 这一串对应的是100.06
似乎很简单是不是,实际上并不是,因为ASCII编码中没有中文,怎么去解析呢?
继续发现规律
中间那么多字符,刚好对应这么多4个字符的16进制字符串
D3C3
D3DA
D4DA
BDBB
D2D7
CFEC
D3A6
CFFB
CFA2
D6D0
B4E6
B7C5
D5DB
BFDB
D0C5
CFA2
A3AC
D5DB
BFDB
BDF0
B6EE
于是,就很自然的想到,每4个就对应一个汉字,于是去查了一下
GBK 编码表 - 在线工具

它就浓眉大眼地躺在那儿!
还真是!
所以说每4个字符就代表GBK编码一个汉字,至于为什么呢,可以去查查汉字编码的字节(汉字两个字节,字母数字是1个字节)
到这儿,似乎很简单了,就是把4个字符的字符串解析成汉字啦
工具方法:
/**
* 将16进制字符串转成字符串
* @param hex 类似于D3C3D3DABDBBD2D7
* @return
*/
public static String hexStr2GBKStr(String hex) {
String hexStr = "";
String str = "0123456789ABCDEF"; //16进制能用到的所有字符 0-15
for(int i=0;i<hex.length();i++){
String s = hex.substring(i, i+1);
if(s.equals("a")||s.equals("b")||s.equals("c")||s.equals("d")||s.equals("e")||s.equals("f")){
s=s.toUpperCase().substring(0, 1);
}
hexStr+=s;
}
char[] hexs = hexStr.toCharArray();//toCharArray() 方法将字符串转换为字符数组。
int length = (hexStr.length() / 2);//1个byte数值 -> 两个16进制字符
byte[] bytes = new byte[length];
int n;
for (int i = 0; i < bytes.length; i++) {
int position = i * 2;//两个16进制字符 -> 1个byte数值
n = str.indexOf(hexs[position]) * 16;
n += str.indexOf(hexs[position + 1]);
// 保持二进制补码的一致性 因为byte类型字符是8bit的 而int为32bit 会自动补齐高位1 所以与上0xFF之后可以保持高位一致性
//当byte要转化为int的时候,高的24位必然会补1,这样,其二进制补码其实已经不一致了,&0xff可以将高的24位置为0,低8位保持原样,这样做的目的就是为了保证二进制数据的一致性。
bytes[i] = (byte) (n & 0xff);
}
String result = "";
try {
result = new String(bytes,"GBK");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return result;
}测试:
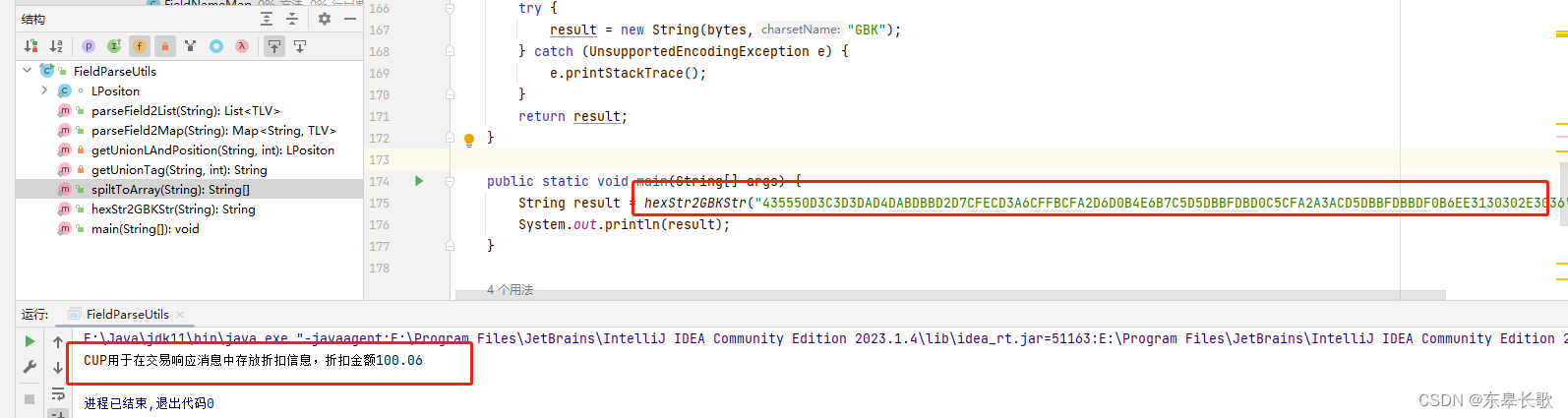
完美!
码字不易,记得点赞关注哟!