本文基于对并行模式的分层架构、数据局部性和控制流的抽象,提出了Plasticine架构,从而为并行模式计算提供更好的灵活性和更低的能耗支持。原文: Plasticine: A Reconfigurable Architecture For Parallel Patterns

摘要
近年来,由于可重配架构有助于设计高能效加速器,迅速得到普及。由于位级(bit-level)的可重配抽象,细粒度结构(如FPGA)传统上存在着性能和能效低下的问题。细粒度和粗粒度架构(如CGRA)传统上都需要低级编程,并忍受漫长的编译时间。我们用Plasticine来解决这两个挑战,这是一个新的空间可重配架构,旨在有效执行由并行模式组成的应用程序。并行模式已经从最近的并行编程研究中脱颖而出,成为强大的高级抽象,可以优雅捕捉数据位置、内存访问模式和跨越广泛的密集和稀疏应用的并行性。
首先,我们通过观察关键应用的并行模式特征,发现这些特征适合于硬件加速,如分层并行、数据局部性、内存访问模式和控制流,从而激发我们构思了Plasticine。基于这些观察,我们将Plasticine架构为模式计算单元(Pattern Compute Units) 和模式存储单元(Pattern Memory Units) 的集合。模式计算单元是可重配的SIMD功能单元的多级流水线,可以有效执行嵌套模式。模式存储单元使用分组暂存器(banked scratchpad memories)和可配置的地址解码器实现数据定位。多个片上地址生成器和scatter-gather引擎通过支持大量未完成的内存请求、内存合并和密集访问的突发模式,有效利用了DRAM带宽。Plasticine基于28纳米工艺实现的芯片面积为113 ,在1GHz时钟下的最大功耗为49瓦。通过使用周期精确的模拟器,证明Plasticine在广泛的密集和稀疏应用中比传统的FPGA提供了高达76.9倍的每瓦性能改进。
1. 简介
为了寻求更高的性能和能源效率,计算系统正越来越多的使用专门的加速器[7, 9-11, 19, 33, 44]。加速器实现了定制的数据和控制路径,以适应某一领域的应用,从而避免通用处理器中的大量灵活性开销。然而,由于设计和制造的一次性工程(NRE, non-recurring engineering)成本高,以及部署和迭代时间长,以专用ASIC的形式进行专业化很昂贵,因此ASIC加速器只适合最普遍的应用。
像FPGA这样的可重配架构(reconfigurable architectures) 通过在静态可编程网络互连中提供灵活的逻辑块来实现自定义数据路径,从而抵消高额的NRE制造成本。通过FPGA,可以在位级(bit-level)定制数据通路,允许用户对任意数字逻辑进行原型化,并利用架构支持任意精度的计算,这种灵活性已经吸引了一些数据中心成功部署了基于FPGA的商业加速器[28, 29, 37]。然而,灵活性是以架构的低效为代价的。计算和网络资源的位级(bit-level)可重配带来了巨大的芯片面积和功耗开销。例如,FPGA中超过60%的芯片面积和功耗是用在可编程网络上[4, 5, 22, 35]。通过多个逻辑元件的长组合路径限制了加速器设计可以运行的最大时钟频率。低效率促使了粗粒度可重配架构(CGRA, Coarse-Grain Reconfigurable Architecture)的发展,其字级(word-level)功能单元符合大多数加速器应用的计算需求。CGRAs提供密集的计算资源、电源效率以及比FPGA高一个数量级的时钟频率。现代商业FPGA架构,如英特尔的Arria 10和Stratix 10器件系列,已经发展到包括越来越多的粗粒度块,包括整数乘积器("DSP")、浮点单元、流水线互连和DRAM存储控制器。然而,FPGA中的互连仍然是细粒度的,以使这些器件能够发挥其作为任意数字逻辑原型验证结构的最初目的。
不幸的是,FPGA和以前提出的CGRA都很难用。加速器设计通常造成低级编程模型和长编译时间[3, 21, 22]。大多数CGRA和带有粗粒度块的FPGA中资源的异质性进一步增加了复杂度。简化加速器开发的一个有希望的方法是用特定领域语言,这些语言可以捕捉到高级别的并行模式,如map、reduce、filter和flatmap[38, 41]。并行模式已经成功用于简化并行编程和代码生成,适用于各种并行架构,包括多核芯片[27, 34, 40]和GPU[8, 23]。最近的工作表明,并行模式也可用于从高级语言中为FPGA生成优化的加速器[15, 36]。在这项工作中,我们专注于开发粗粒度、可重配的架构,对并行模式有直接的架构支持,在面积、功耗和性能方面都很高效,在编程和编译的复杂性方面也很容易使用。
为此我们引入了Plasticine,作为新的空间可重配加速器架构,为高效执行并行模式进行了优化。Plasticine是由两种粗粒度的可重配单元组成的二维阵列: 模式计算单元(PCU, Pattern Compute Unit) 和模式存储单元(PMU, Pattern Memory Unit) 。每个PCU由一个可重配流水线组成,具有多级SIMD功能单元,并支持跨SIMD通道的转移和简化。PMU由一个分组暂存器(banked scratchpad memory )和专用寻址逻辑及地址解码器组成。这些单元通过流水线静态混合互连(static hybrid interconnect) 相互通信,具有独立的总线级(bus-level)和字级(word-level)数据,以及位级(bit-level)控制网络。Plasticine架构中的层次结构简化了编译器映射,提高了执行效率。编译器可以将内循环计算映射到一个PCU上,这样大多数操作数就可以直接在功能单元之间传输,而不需要使用scratchpad存储器或PCU之间的通信。片上scratchpad存储器可配置为支持流式和双缓冲访问,片外存储控制器支持流式(突发)模式和scatter/gather访问。最后,片上控制逻辑可配置为支持嵌套模式。
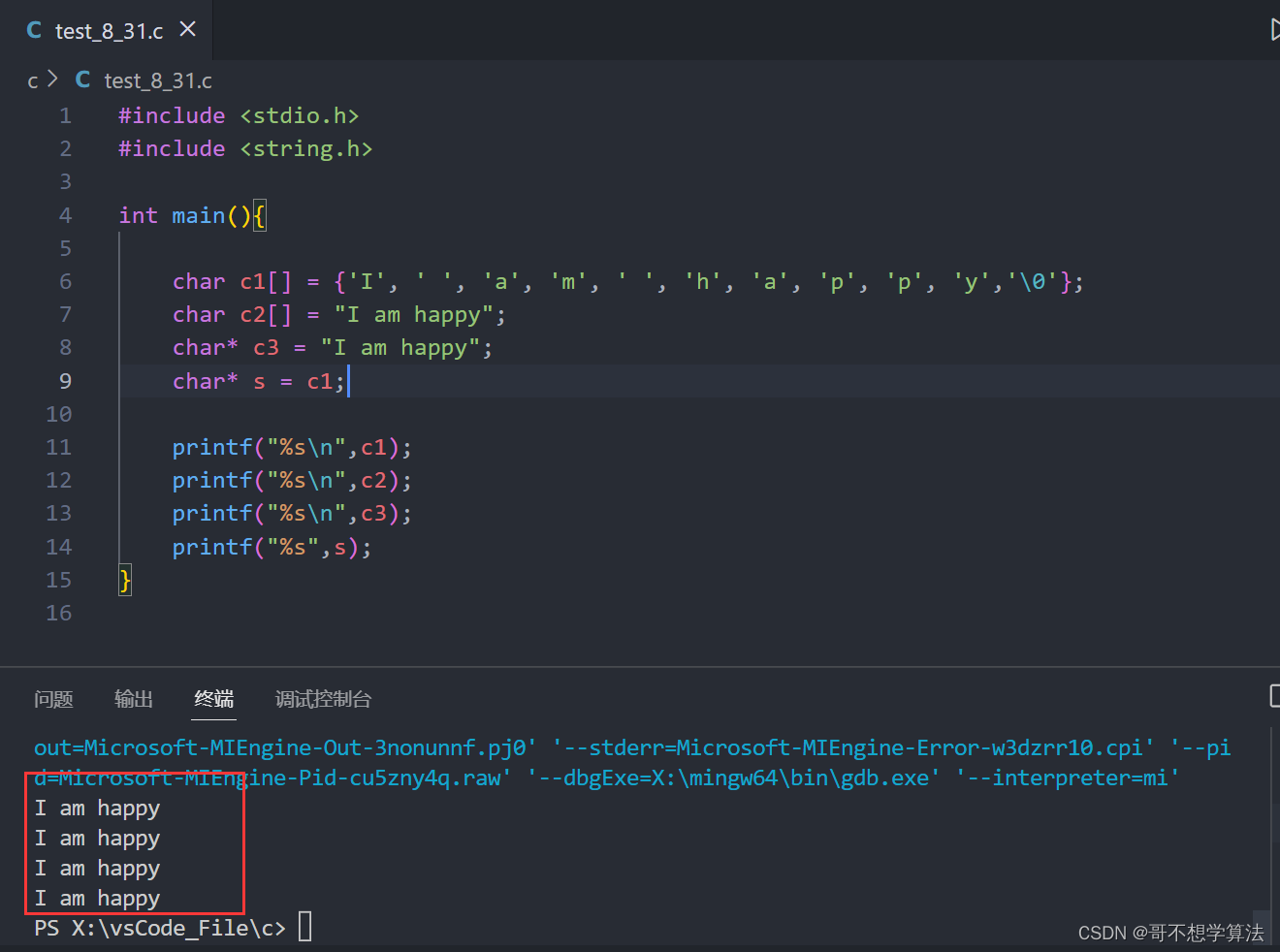
我们用基于Scala的硬件定义语言Chisel[2]实现Plasticine,使用Synopsys Design Compiler综合设计后得到面积估算,通过模拟轨迹和PrimeTime得到功率数。使用VCS和DRAM-Sim2进行精确周期模拟,在线性代数、机器学习、数据分析和图分析等领域大量密集、稀疏计算基准测试的基础上对Plasticine架构进行详细评估。
本文的其余部分组织如下: 第2节回顾并行模式中的关键概念及其硬件实现。第3节介绍了Plasticine架构并探讨了关键的设计权衡。第4节介绍了与FPGA相比,Plasticine的电源和性能效率。第5节讨论相关工作。
2. 并行模式
2.1. 并行模式编程
并行模式是对传统函数式编程的扩展,包括密集和稀疏数据集合上的可并行计算,以及相应的内存访问模式。并行模式为常见计算任务提供了简单、自动的程序并行化规则,同时也通过更高层次的抽象来提升程序员的生产力。并行化带来的性能优势,加上程序员生产力的提高,使得并行模式在各种领域越来越受欢迎,包括机器学习、图形处理和数据库分析[38, 41]。以前的工作以及证明,并行模式可以在函数式编程模型中应用,为CPU生成可与手工优化代码相媲美的多线程C++[40]以及为FPGA生成高效的加速器设计[1, 15, 36]。与FPGA和多核CPU一样,在针对CGRA时,数据并行性的知识对于实现良好的性能至关重要。这种隐含的知识使得并行模式成为驱动CGRA设计的自然编程模型。
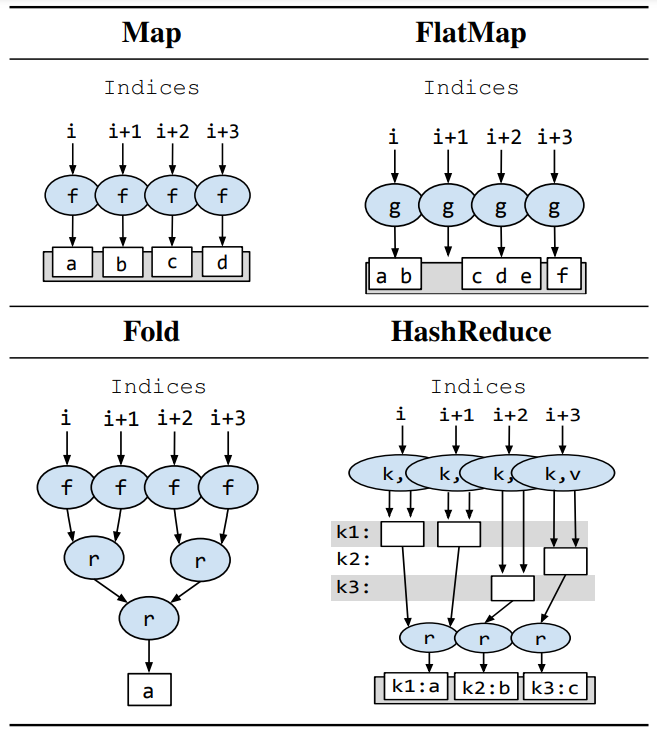
和以前并行模式的硬件生成工作一样[15, 36],我们的编程模型基于并行模式Map、FlatMap、Fold和HashReduce,选择这些模式是因为它们最适合硬件加速。表1介绍了每种模式的概念性例子,显示了同时在四个索引上进行的计算。每个模式都有一个或多个函数和一个描述该模式操作的数值范围的索引域(index domain) 作为输入。每个模式都有一个输出,并能够读取任意数量的输入集合。
Map使用函数f为每个索引创建输出元素,f的每次执行都被保证是独立的。Map的输出元素的数量与输入迭代域的大小相同。基于f读取的集合数量和每次读取的访问模式,Map可以获取集合、标准元素级映射、压缩包、窗口过滤器或其任何组合的行为。

FlatMap使用函数g为每个索引产生任意数量的元素,其中函数的执行也是独立的。产生的元素被串联成一个扁平输出。有条件数据查询(例如SQL中的WHERE,Haskell或Scala中的filter)是FlatMap的特例,其中g产生零个或一个元素。
Fold首先充当Map,使用函数f为每个索引生成单个元素,然后使用关联组合函数r对这些元素进行约简。
HashReduce使用函数k和v分别为每个索引生成哈希键和值。具有相同对应键的值在执行中被放到单个累加器中,使用同一个关联的组合函数r。HashReduce可以是密集型的,即键的空间是提前知道的,所有累加器都可以静态分配,也可以是稀疏型的,即模式可以在运行时产生任意数量的键。直方图创建是一个常见的、简单的HashReduce的例子,其中key函数给出了直方图的堆,value函数被定义为总是"1",而combine函数是整数加。
图1显示了用明确的并行模式语法编写无约束矩阵(untiled matrix)乘法的例子。在这种情况下,Map创建大小为M×P的输出矩阵,Fold使用N个元素的点乘法产生这个矩阵的每个元素。Fold的map函数(f2)访问矩阵a和矩阵b中的元素,并将它们相乘。Fold的组合函数(r)定义了如何组合由f2产生的任意元素,在示例中使用求和。
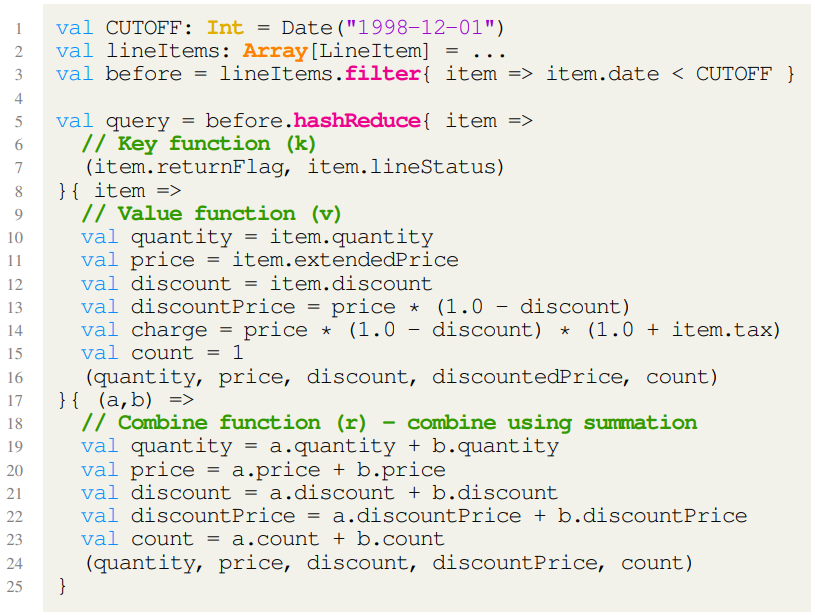
图2给出了基于Scala语言中使用并行模式的示例,在并行模式实例对应的集合上定义了中缀操作符。注意,本例第3行的filter创建了一个FlatMap,其索引域等于lineItems集合的大小。第5行的hashReduce创建了一个HashReduce,其索引域的大小为before集合的大小。
2.2. 硬件实现需求
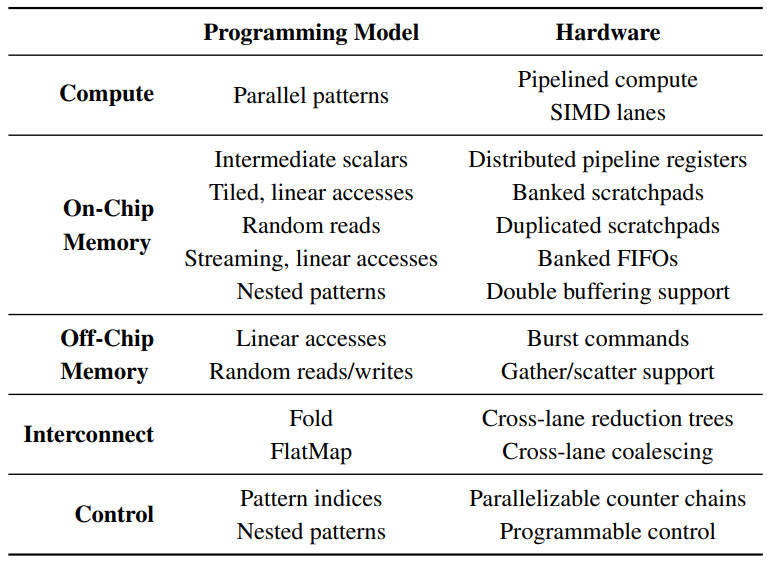
并行模式提供了一组简洁的并行抽象,可以简洁表达各种机器学习和数据分析算法[8,36,38,41]。通过创建专门支持这些模式的体系架构,可以有效执行这些算法。这种并行模式体系架构需要几个关键硬件特性,下面将逐一介绍,表2进行了总结。
首先,所有四种模式都可以实现并行数据计算,每个索引上的操作都完全独立,一个流水线计算架构被构建成SIMD通道,利用数据并行性实现每周期多元素的吞吐量。此外,除了无法在循环中维持依赖,表1中的函数f、g、k和v在其他方面不受限制,这意味着该架构的流水线计算必须是可编程的,以便实现这些函数。
其次,为了利用流水线SIMD通道提供的高吞吐量,该架构必须能够提供高片上内存带宽。在我们的编程模型中,函数中间值通常是具有静态已知位宽的标量,这些标量值可以存储在小型分布式流水线寄存器中。
集合被用来在并行模式之间进行数据通信,对集合架构的支持取决于相关内存访问模式,并通过分析用于计算内存地址的函数来确定。为了简单起见,我们将访问模式分为静态可预测线性函数模式或不可预测随机访问模式。此外,我们将访问要么标记为流式(即在静态可确定的函数执行数量中不发生数据重用),要么tiled(即可能发生重用)。我们使用领域知识和编译器启发式方法来确定随机访问是否可能表现出重用。以前的工作显示了如何将并行模式平铺(tile)从而使用静态大小的重用窗口,并有可能提升数据的局部性[36]。
支持tiled访问的集合可以被存储在scratchpad中。为了驱动SIMD计算,这些scratchpad存储器应该尽可能支持多个并行地址流。在线性访问情况下,地址流可以通过堆叠(banking)来创建。并发随机读取可以通过本地内存的复制来支持,而随机写入命令必须顺序化并且尽量合并操作。
虽然流访问不可避免需要访问主存,但通过合并内存命令和线性访问预取数据,可以将主存读写成本降至最低,架构中的本地FIFO为这两种优化提供了备份存储。
本地存储器使我们能够利用应用程序的局部性,尽量减少对昂贵的主存储器的加载或数量要求[32]。本地存储器中的可重配支持增加了这些片上存储器的可用带宽,从而使计算得到更好的利用。在scratchpad存储器中支持双重缓冲,一般称为N-缓冲(N-buffering),可以实现不完全嵌套模式的粗粒度流水线执行。
该架构还需要高效的内存控制器来填充本地内存并提交计算结果。与片上存储器一样,存储控制器应该专门用于不同的访问模式。线性访问对应于DRAM突发命令,而并行模式下的随机读写分别对应于gather和scatter。
Fold和FlatMap也暗示了细粒度的跨SIMD通道通信。Fold需要跨通道的简化树,而FlatMap中的拼接最好由有效的跨通道字合并(word coalescing)硬件来支持。
最后,所有并行模式都有一个或多个相关的循环索引。这些索引可以在硬件中实现为并行、可编程的计数器链。由于并行模式可以任意嵌套,因此体系架构必须具有可编程控制逻辑,以确定每个模式何时允许执行。
虽然已经提出了许多粗粒度硬件加速器,但以前的工作所描述的单一加速器都不具备所有这些硬件特征。这意味着虽然这些加速器中的一部分可以成为并行模式的目标,但没有一个可以完全利用这些模式的特性来实现性能的最大化。传统FPGA也可以被配置来实现这些模式,但正如我们在第4节中所展示的那样,能效要差得多。我们将在第5节进一步讨论相关工作。
3. Plasticine架构
Plasticine是一个由可重配模式计算单元(PCU) 和模式存储单元(PMU) 组成的tiled结构,我们将其统称为"单元"。单元与三种静态互连进行通信: 字级标量(word-level scalar)、多字级矢量(multiple-wordlevel vector)和位级控制互连(bit-level control interconnects)。Plasticine的单元阵列通过多个DDR通道与DRAM连接,每个通道都有相关的地址管理单元,在多个地址流之间进行仲裁,并由缓冲器支持多个未完成的内存请求和地址聚合,以尽量减少DRAM的访问。每个Plasticine组件用于映射应用程序的特定部分: 本地地址计算在PMU中完成,DRAM地址计算发生在DRAM地址管理单元中,其余的数据计算发生在PCU中。请注意,Plasticine架构是参数化的,我们将在第3.7节讨论这些参数的取值。
3.1. 模式计算单元(Pattern Compute Unit)
PCU被设计为在应用程序中执行内部单个并行模式。如图3所示,PCU数据路径被组织为多阶段、可重配的SIMD管道。这种设计使每个PCU实现了高计算密度,并利用了跨通道的循环级并行和跨阶段的流水线并行。
SIMD通道的每个阶段由一个功能单元(FU, functional unit) 和相关流水线寄存器(PR, pipeline register)组成。功能单元执行32位字级算术运算和二进制操作,包括对浮点数和整数操作的支持。由于单个流水线阶段的功能单元以SIMD方式操作,每个阶段只需要一个配置寄存器,每个FU的结果都被写入其相关的寄存器中。每个通道中的PR是跨流水线阶段链在一起的,允许在同一通道内的阶段之间传播实时值。FU之间的跨道通信通过两种类型的PCU内部网络实现: 一种是还原树网络,允许将多个通道的值还原成一个标量; 另一种是移位网络,允许将PR作为跨阶段滑动窗口从而在模版应用中复用。这两个网络都在PR内使用专用寄存器,以尽量减少硬件开销。
PCU使用三种输入输出(IO)作为全局互连接口: 标量(scalar)、矢量(vector)和控制(control)。标量IO用于单字数据的通信,如Fold的结果等。每个矢量IO允许在PCU中的每个通道上通信一个字,并用于诸如读写PMU中的scratchpad存储器和在多个PCU之间的长管道上传输中间数据。每个矢量和标量输入都使用一个小型FIFO进行缓冲。通过输入端FIFO解耦数据生产者和消费者,并通过增强鲁棒性减少输入延迟从而简化PCU间的控制逻辑。控制IO用于通信控制信号,如PCU执行的开始或结束,或指示背压。
一个可重配计数器链产生模式迭代指数和控制信号以协调执行。当控制块启用其中一个计数器时,PCU开始执行。根据应用的控制和数据依赖性,控制块可以被配置为结合来自本地FIFO和全局控制输入的多个控制信号来触发PCU的执行。控制块使用可重配组合逻辑和用于状态机的可编程计数器来实现。
3.2. 模式存储单元(Pattern Memory Unit)
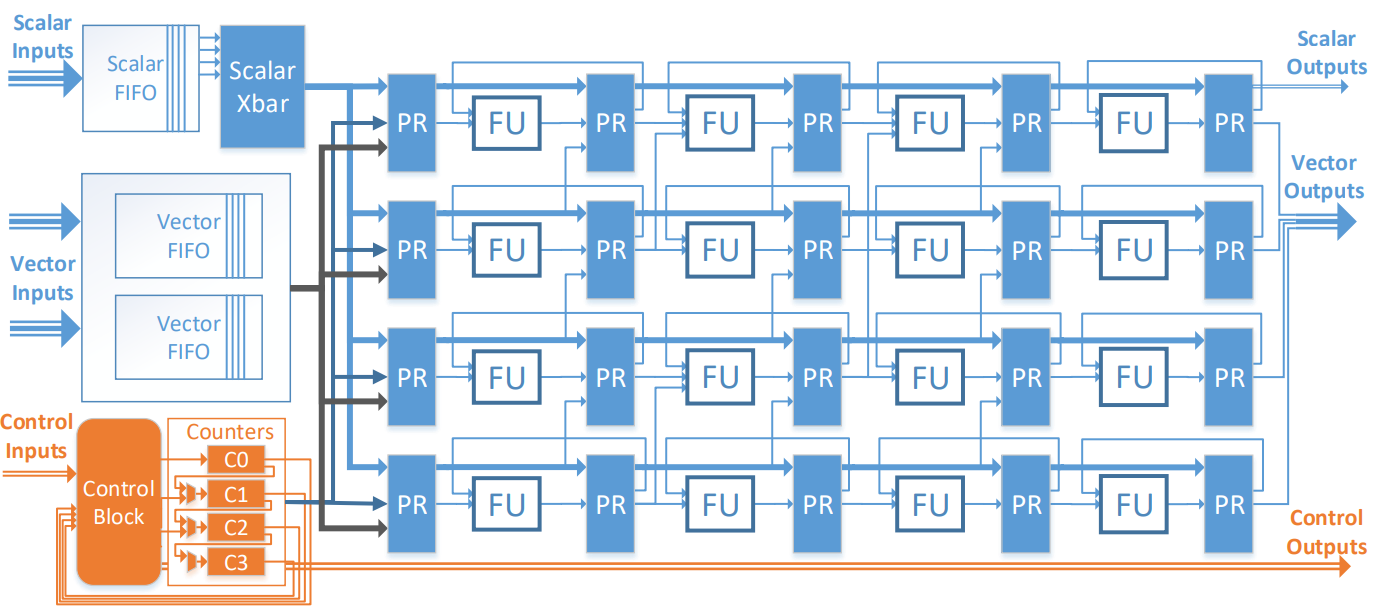
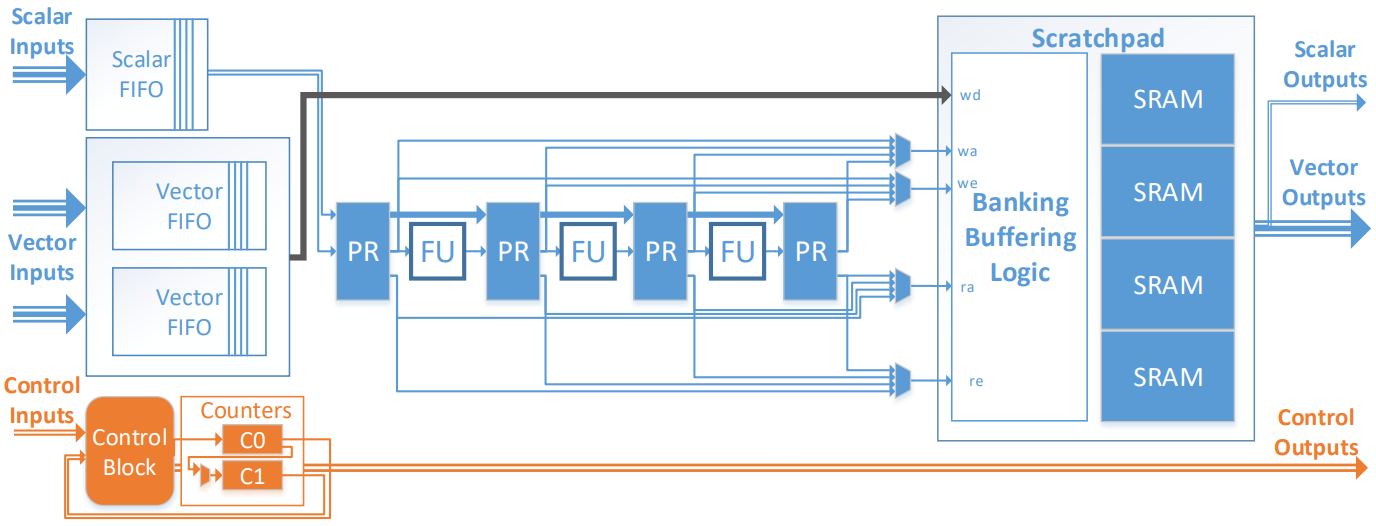
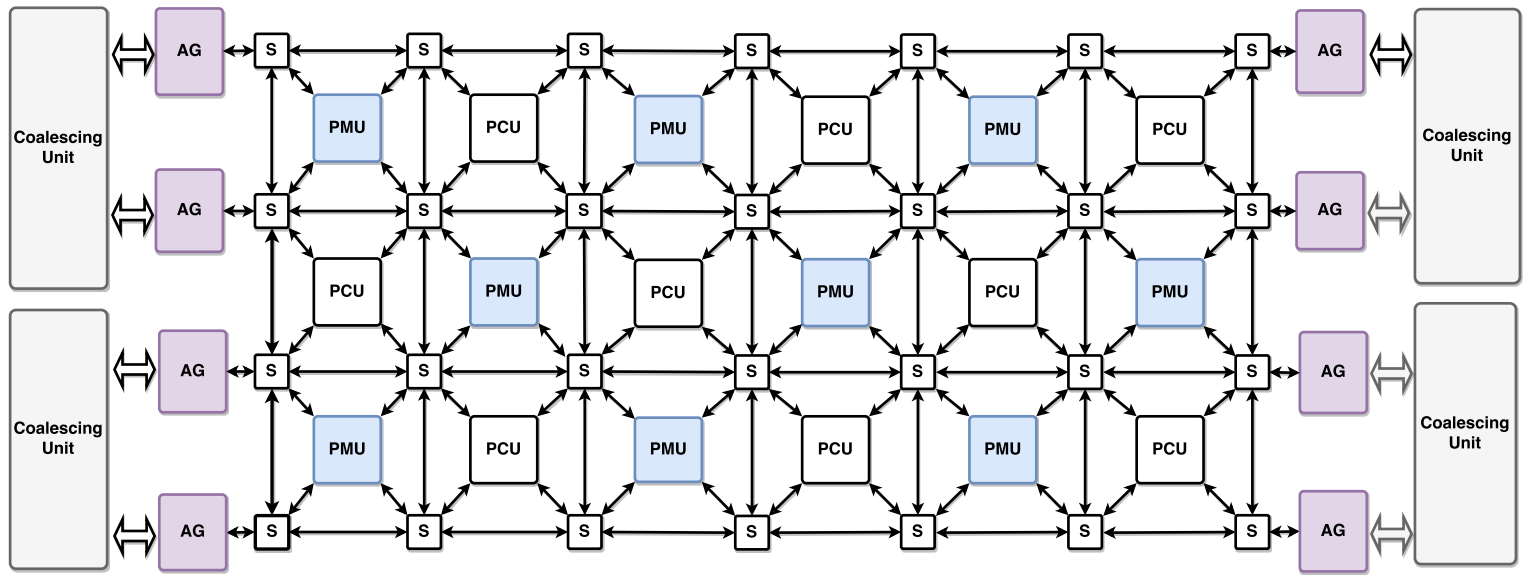

图4显示了PMU架构。每个PMU包含一个由程序员管理的scratchpad存储器,加上一个用于地址计算的可重配标量数据通路。如图5所示,PMU被用来在整个Plasticine架构中分配片上存储器。Plasticine对参与内存地址计算的操作和应用基础的核心计算进行了区分。地址计算在PMU数据通路上进行,而核心计算则在PCU内进行。一些观察结果促使采用了这种设计选择:(i)地址计算涉及简单的标量数学,这需要比PCU中的FU更简单的ALU;(ii)对大多数片上访问模式来说,使用多个通道进行地址计算通常并不必要;(iii)在PCU内执行地址计算需要将地址从PCU路由到PMU,这占用了PCU阶段和输出链接,并可能导致PCU利用率不足。
scratchpad上有多个SRAM堆叠,与PCU通道的数量相匹配。scratchpad周围的地址解码逻辑可以被配置为在几种堆叠模式下运行,以支持各种访问模式。Strided banking模式支持密集数据结构上经常出现的线性访问模式。FIFO模式支持流式访问。行缓冲(Line buffer) 模式支持类似于滑动窗口的访问模式。复制(Duplication) 模式,即内容在所有存储器中复制,提供多个读取地址通道,以支持并行的片上gather操作。
正如堆叠对于支持多个SIMD单元以维持计算吞吐量很重要,N-缓冲(N-buffering) 或广义上的双缓冲对于支持粗粒度管道也同样重要。PMU scratchpad可以被配置成N-buffer,并采用上述任何一种堆叠模式进行操作。N-buffer是通过将每个SRAM的地址空间划分为N个不相连的区域来实现的。利用写和读的状态信息,在每个存储器的本地地址上增加适当偏移量,以访问正确的数据。
类似于PCU,一个可编程的计数器链和控制块触发PMU执行。每个PMU通常包含来自生产者模式的写地址计算逻辑,以及来自消费者模式的读地址计算逻辑。根据本地FIFO和外部控制输入的状态,可以配置控制块,通过启用适当的计数器来分别或者同时触发写地址计算和读地址计算。
3.3. 互联(Interconnect)
Plasticine支持通过三种方式实现PMU、PCU和外围元件之间的通信: 标量、矢量和控制。这些网络在传输数据的粒度上有所不同: 标量网络以字级粒度运行,矢量网络以多字级粒度运行,而控制网络以位级粒度运行。所有三个网络的拓扑结构都是相同的,如图5所示。所有网络都是静态配置的。网络交换机中的链接包括寄存器,以避免长线延迟。
应用程序通常包含嵌套流水线,其中外围流水线层只需要计数器和一些可重配控制。此外,由于外部流水线逻辑通常涉及某种程度的控制信号同步,因此是控制热点,需要大量控制和标量输入输出。为了有效处理外部流水线逻辑,标量和控制交换机共享同一个可重配控制块和计数器。将控制逻辑纳入交换机内,可以减少对热点的路由,以提高PCU利用率。
3.4. 片外存储访问(Off-chip Memory Access)
Plasticine通过4个DDR内存通道访问片外DRAM,每个DRAM通道基于芯片两侧的若干个地址生成器(AG, address generator) 访问,如图5所示。每个AG包含一个可重配标量数据路径生成DRAM请求,其架构与图4所示的PMU数据路径类似。此外,每个AG包含FIFO缓冲从DRAM发出的指令、数据和传入的响应。多个AG连接到一个地址聚合单元(coalescing unit) ,地址聚合单元负责AG之间的仲裁并处理内存请求。
AG可以产生或密集(dense) 或稀疏(sparse) 的内存指令。密集请求用于批量传输连续的DRAM区域,通常用于读取或写入数据块。密集请求被聚合单元转换为多个DRAM突发请求。稀疏请求将地址流输入聚合单元,聚合单元通过聚合缓存维护已发出的DRAM请求元数据,并合并属于同一DRAM请求的稀疏地址,以尽量减少发出的DRAM请求数量。换句话说,稀疏内存的加载触发了聚合单元的gather操作,而稀疏内存的存储则触发了scatter操作。
3.5. 控制流(Control Flow)
Plasticine使用分布式、分层的控制方案,尽量减少单元之间的同步,以适应网络中有限的位数连接。我们支持从高级语言结构推断出三种类型的控制器协议: (a) 顺序(sequential) 执行,(b) 粗粒度流水线(coarse-grained pipelining) ,和(c) 流式(streaming) (图6)。这些控制方案对应于输入程序中的外循环,并决定单个单元的执行如何相对于其他单元进行调度。单元被分组为 层次分明的控制器集,同级控制器的控制方案基于其直属父控制器的方案。
在顺序执行父控制器中,任何时候都只有一个数据依赖的子节点处于活动状态,这通常应用在有循环依赖的时候。我们通过令牌(token) 强制执行数据依赖,其实现是通过控制网络路由的前馈脉冲信号。当父控制器被启用时,一个令牌被发送给所有对其兄弟节点没有数据依赖的头部(head) 子程序。在完成执行后,每个子节点会将令牌传递给其输出数据的消费者。每个控制器只有在所有依赖数据源的令牌被收集后才会被启用。来自最后一组控制器的令牌,其数据不被同级别的任何兄弟控制器所消耗,被送回给父控制器。父控制器将令牌收集起来,要么将令牌送回给头部进行下一次迭代,要么在其所有迭代完成后在自己的层次结构中传递令牌。
在粗粒度流水线中,子控制器以流水线方式执行。为了允许并发,父控制器向头部发送N个令牌,其中N是关键路径中的数据依赖子节点数量,从而允许所有子节点在稳定状态下处于活动状态。为了允许生产者和消费者在不同的迭代中对相同数据进行处理,每个中间存储器都有M个缓冲区,其中M是在其数据依赖路径上相应的生产者和消费者之间的距离。为了防止生产者溢出下行缓冲区,每个子控制器通过使用点数(credit) 跟踪可用的下行缓冲区大小来处理背压。每个生产者在生产完父代"当前"迭代的所有数据后,递减其点数。同样,消费者在消费完父代"当前"迭代的所有数据后,通过网络送回一个点数。在粗粒度流水线方案中,当每个子节点至少有一个令牌和一个点数可用时,就会被启用。
最后,流式父控制器的子控制器以细粒度流水线方式执行。这使得编译器可以通过串联多个单元形成一个大流水线来适应大型内部模式体。在流式模式中,子节点通过FIFO进行通信。当某个控制器的所有读FIFO都不为空,且所有写FIFO都不满时,该控制器被启用。FIFO在消费者控制器本地,所以入队以及非空信号是通过控制网络从消费者发送到生产者的。
为了执行这些控制协议,我们使用静态可编程计数器、状态机和组合查询表来实现专门的可重配控制块,架构中的每个PCU、PMU、交换机和存储控制器都有一个控制块。一般来说,没有任何子节点的控制器被映射到PCU,而外部控制器被映射到交换机的控制逻辑。由于外部控制器通常有许多子节点需要同步,这种映射为外部控制器提供了较高的通信基数。Plasticine控制方案中的层次架构和分布式通信使编译器能够利用嵌套并行模式中的多层次并行性,而只需最小的位级可重配开销。
3.6. 应用映射(Application Mapping)
我们从一个被表示为并行数据流流水线层次结构的应用开始,该应用是用一种基于并行模式的语言--Delite硬件定义语言(DHDL, Delite Hardware Definition Language)[20]编写的。之前的工作[36]显示了以第2节所述的并行模式表达的应用程序如何能够自动分解为DHDL中的流水线,这些流水线要么只包含其他流水线的外部控制器,要么是不包含其他控制器(只包含计算和存储操作的数据流图)的内部控制器。
为了将DHDL映射到Plasticine,我们首先基于用户指定的或自动调整的并行化系数展开外部流水线。然后,基于展开的结果分配和安排虚拟PMU和PCU。这些虚拟单元是对Plasticine单元的抽象表示,有无限多的可用输入、输出、寄存器、计算阶段和计数器链。由于外部控制器不包含计算,只包含控制逻辑,它们被映射到虚拟PCU,没有计算阶段,只有控制逻辑和计数器链。内部控制器中的计算是通过线性化数据流图和将产生的操作列表映射到虚拟阶段和寄存器来实现的。每个本地存储器映射到一个虚拟PMU,用于计算该存储器读写地址的阶段被复制到虚拟PMU上。
然后,通过划分阶段将每个虚拟单元映射为一组物理单元。虚拟PCU被划分为多个PCU,而PMU则成为一个具有零个或多个支持PCU的PMU。虽然一般来说图分区(graph partitioning )是NP-hard问题,但每个虚拟单元的计算阶段往往远少于200个,而且循环依赖性非常小。这意味着,带有简单启发式的贪婪算法可以实现接近完美的物理单元分区。在我们的分区算法中,使用一个成本指标计算物理阶段的数量,每阶段的活跃变量,以及给定分区所需的标量和矢量输入/输出总线。请注意,由于我们从应用程序的完整数据流表示开始,这些通信和计算成本总是可以静态预测的。使用启发式方法,编译器会选择一个建议分区,其中所有PCU和PMU在物理上都是可实现的,并给定一些选定的Plasticine架构参数(PCU、PMU、阶段、流水线、总线等的数量),并使ALU和本地内存利用率最大化。
在分区之后,按照第3.5节所述,生成与控制器层次结构相对应的控制逻辑。然后,我们将虚拟硬件节点与物理硬件资源进行分层绑定,包括数据通路和控制通路的放置和路由,SIMD单元的寄存器分配,包括将阶段映射到物理ALU,并分配scratchpad和控制资源。Plasticine的分层性质使得每层映射的节点少于1000个,从而极大减少了搜索空间。
给定配置和路由信息,然后生成类似于汇编语言的Plasticine配置描述,用于为架构生成静态配置"位流(bitstream)"。由于分层体系架构,以及计算单元之间的粗总线粒度,使得整个编译过程只需几分钟就可以完成(或失败),而生成FPGA配置则需要数小时。
3.7. 架构规模(Architecture Sizing)
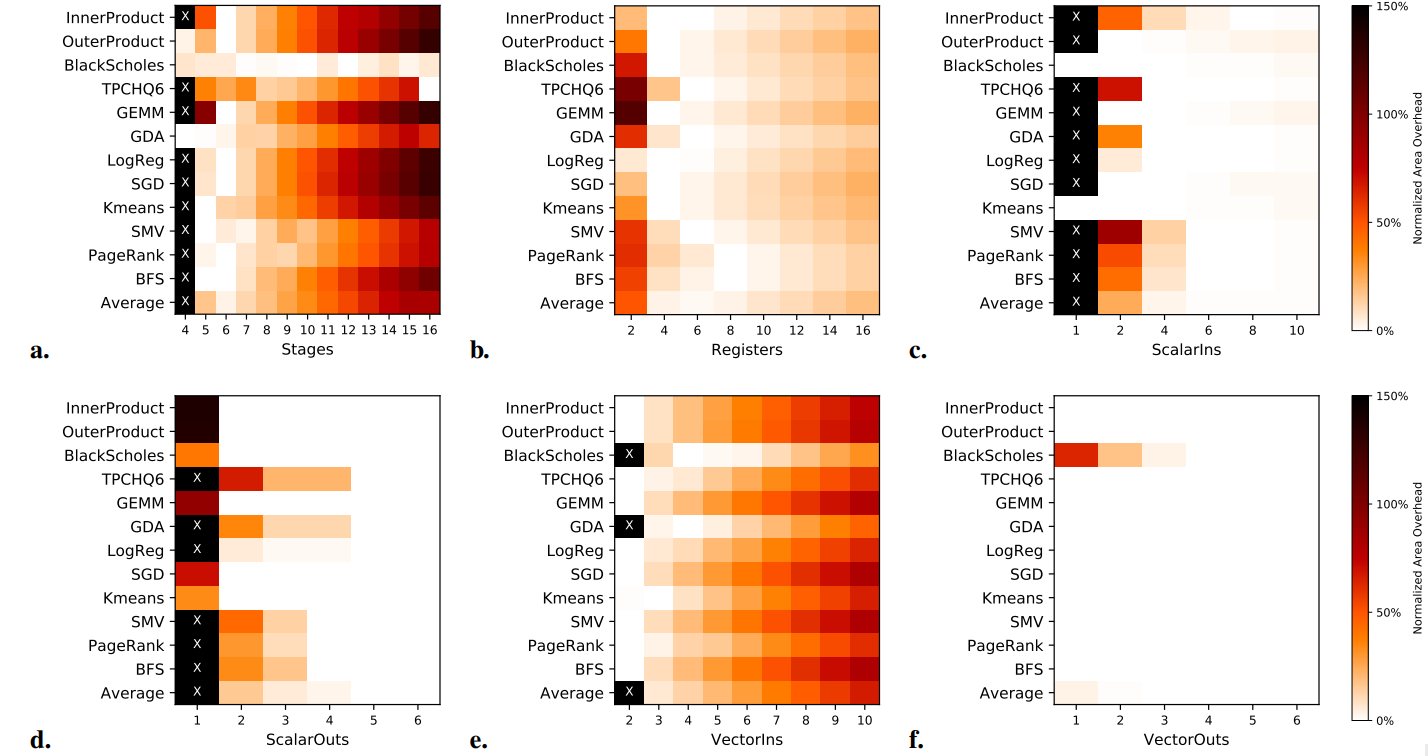
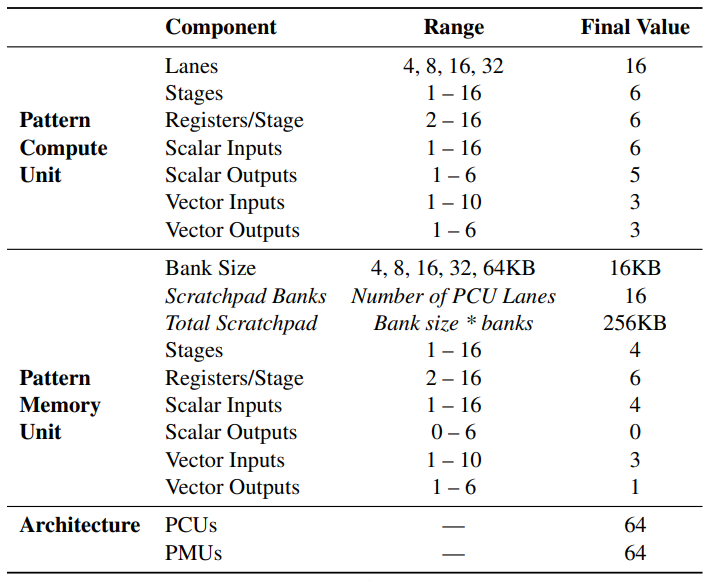
目前为止,我们已经介绍了由PCU、PMU和网络等组成的参数化架构。现在我们介绍调整PCU和PMU参数的过程,以创建最终的Plasticine架构,我们将在第4节对其进行评估。表3总结了所考虑的架构参数,每个参数的可能值,以及所选的最终值。为了提高应用路由性的概率,我们要求架构中的PMU和PCU是同质的。
在选择设计参数时,首先分析表4中所列基准测试的特点来剪裁空间。根据每个基准测试的性能模型,确定所有基准测试的理想内部控制器的并行化系数在8到32之间。在Plasticine中,对应于具有8至32条SIMD通道的模式计算单元。我们选择了具有16条通道的平衡架构。16个4字节矢量也方便与我们的主存储器的64字节突发大小相匹配。对于PMU的scratchpad,我们发现对于基准测试来说,理想的tile大小最多为每组4000字。因此,我们将PMU设置为有16个可配置的16KB内存,每个PMU总共有256KB。
接下来搜索剩余的架构空间,选择每个PCU的级数、每级寄存器、输入和输出。在我们的编程模型中,外部控制器的并行化在硬件上对应于内部控制器的复制。这意味着可以假设,在特定应用中,外循环的并行化不会改变其理想的PCU参数,而只是改变所需PCU数量。因此,我们用现实的并行化因素固定每个基准测试,并确定如何在最大限度提高有效计算能力的同时最小化总PCU面积。请注意,必须允许改变所需PCU的数量,因为这些参数直接影响到虚拟PCU需要多少物理PCU。考虑到最小化PCU设计,我们可以在给定总芯片面积预算的条件下创建具有最大性能的Plasticine架构。
我们使用模型驱动的蛮力搜索来调整不同应用中的每个架构参数。为了推动这一搜索,我们通过将基准测试归一化的面积开销作为有效PCU面积的成本指标。当调整某个参数时,对其数值进行扫描,对于每个建议值,扫过剩余空间,找到可能的最小PCU面积( )。然后,根据其最小值( )将这些面积归一化,并将每个可能的参数值的开销报告为 。单个PCU面积被建模为其控制盒、FU、流水线寄存器、输入FIFO和输出网络的面积之和。一组给定设计参数所需的PCU总数是使用第3.6节中概述的映射程序计算出来的。
我们在研究中发现,调优过程中参数的排序对最终的架构设计影响不大。为了简单起见,我们基于一种可能的排序进行搜索,但任何排序出来的最终参数值都是一样的。
我们首先检查每个物理PCU的阶段数所定义的空间,所有其他参数都不受限制。图7a显示了在4到16级之间扫频后的估计面积开销。在这里,我们看到对于大多数基准测试来说,每个PCU的理想级数是5或6。在这些基准测试中,每个模式的计算量相当小,允许模式被映射到单个PCU上。在PCU内,至少需要5个阶段来实现完整的跨通道还原树。在BlackScholes中,核心计算流水线有大约80个阶段,这已经足够长了,每个PCU的阶段对平均FU利用率的影响很小。在TPCHQ6中,核心计算有16个阶段,这意味着额外开销在8和16个阶段(即使不包括计算)是最小的。我们选择每个PCU的6个阶段作为所有基准测试的平衡架构,这种选择意味着像TPCHQ6这样运算量相对较小、不被平均分割为6份的应用将不能充分利用PCU分区,但这是在同质单元上进行分区的一个不可避免的结果。
我们接下来确定每个FU的寄存器数量。我们再次扫过参数空间,将级数固定为6,但对其他参数不作限制。从图7b中可以发现大多数应用的理想寄存器数量在4到6之间,直接对应于每个PCU流水线阶段中任何给定点的最大活跃值数量。低于4个寄存器,PCU就会受到给定时间内所能容纳的活跃值数量的限制,从而导致不相干的分区。在每个FU超过8个寄存器时,相对于PCU的总面积,未使用寄存器的成本变得很明显。因此我们选择每个FU有6个寄存器。
按照同样的程序,我们确定标量输入和输出的数量。标量逻辑相对便宜,但是,像寄存器一样,缺乏可用的标量输入或输出会导致逻辑被分割到许多PCU中,未利用的逻辑会产生大量开销。因此,我们在图7(c,d)中看到,每个基准测试都有一些所需的最低数量的输入和输出,在这之后增加任何一个都没有什么影响。我们选择了6个标量输入和5个标量输出,因为这在所有基准测试中都能使面积开销最小。
最后,我们以同样的方式对每个PCU的矢量输入和输出进行调整。矢量与标量是分开调整的,因为两者在PCU之间使用不同的互连路径,在PCU内部使用不同的寄存器。请注意,矢量输入与输入FIFO有关,占了PCU面积的很大一部分。因此,我们希望尽可能减少矢量输入。然而,如图7e所示,由于在PCU之间分割的限制,BlackScholes和GDA被限制为至少有3个矢量输入。图7f显示,矢量输出相对便宜,对所需的设计面积影响很小。因此,我们选择每个PCU有3个矢量输入和3个矢量输出。
我们还以类似方法选择了表3给出的PMU参数。请注意,PMU的矢量输入和输出的数量大致对应于缓存盘的读、写和数据总线。因为编译器总是将内存读取的结果映射到矢量总线,因此PMU目前从不使用标量输出。
在这个调优过程之后,有了一个调优的PCU和PMU设计。基于对每个基准测试的研究,我们选择16×8个单元,还试验了多种比例的PMU和PCU。最终我们选择1:1的PMU、PCU比例。而较大比率(例如2:1的PMU、PCU比例)在某些基准测试上提高了单位利用率,但能效较低。
4. 评估
本节我们基于商用Stratix V FPGA评估Plasticine的性能和功耗效率,将Plasticine架构的运行时间和功耗与来自机器学习、数据分析和图形处理领域的基准测试、有效的FPGA实现进行比较。在成熟工具链的支持下,FPGA被广泛使用,使得我们有可能在真实硬件上获得性能数据。
4.1. 基准测试(Benchmarks)
我们围绕两种架构的各种属性开发了一组基准测试,比如密集数据处理和依赖性数据的内存访问。我们使用真实应用指导基准测试的设计,以确保Plasticine能够做有用的工作。表4提供了应用程序的简要介绍。
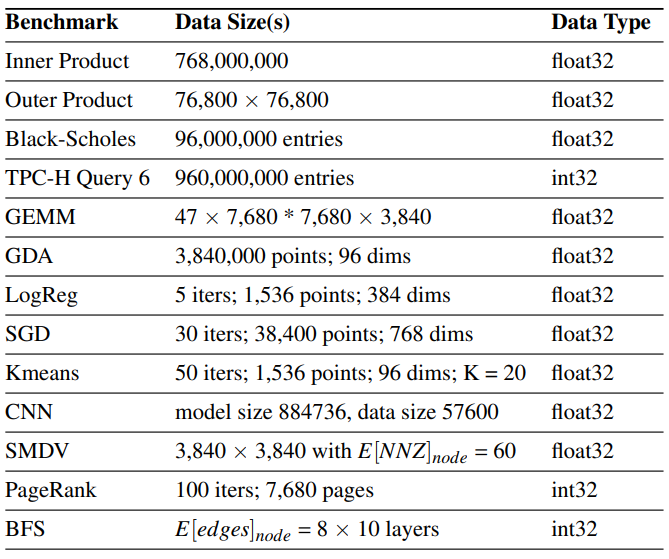
在密集应用中,内积(inner product) 、外积(outer product) 和GEMM(单精度通用矩阵乘法, single precision general matrix multiplication)是基本的线性代数操作,是许多算法的核心。TPC-H Query 6提供了简单的过滤还原功能,展示了数据库查询功能。Black-Scholes是一种计算量很大的金融算法,具有极深的流水线。高斯判别分析(GDA, Gaussian Discriminant Analysis) 和随机梯度下降(SGD, Stochastic Gradient Descent) 是常见的机器学习算法,涉及相对复杂的内存访问,表现出许多并行化的选择。K-means聚类通过迭代计算k个最佳聚类中心点将一组输入点分组。K-means使用密集的HashReduce计算下一次迭代的中心点。卷积神经网络(CNN, Convolutional Neural Network) 是用于图像分类的重要机器学习内核。CNN涉及多层计算,其中每一层都涉及对输入特征图执行若干个三维卷积操作。
稀疏应用涉及对内存中依赖性数据的访问和非确定性计算。稀疏矩阵-密集向量(SMDV, Sparse matrix-dense vector) 乘法是许多稀疏迭代方法和优化算法中使用的另一个基本线性代数内核。PageRank是一种流行的图算法,涉及片外稀疏数据收集,以迭代更新页面排名。广度优先搜索(BFS, BreadthFirst Search) 是另一种图算法,执行与数据相关的、基于边界的遍历,并使用数据散布来存储每个节点的信息。
我们用Delite硬件定义语言(DHDL, Delite Hardware Definition Language)实现这些基准测试,这是一种基于并行模式的专门语言,用于为空间架构(spatial architecture)编写应用程序[20]。在DHDL中,应用程序被指定为可并行的数据流流水线的层次结构。以前的工作[36]表明,DHDL可以从并行模式中自动生成,并可用于生成FPGA的高效硬件加速器设计[20]。
4.2. Plasticine设计
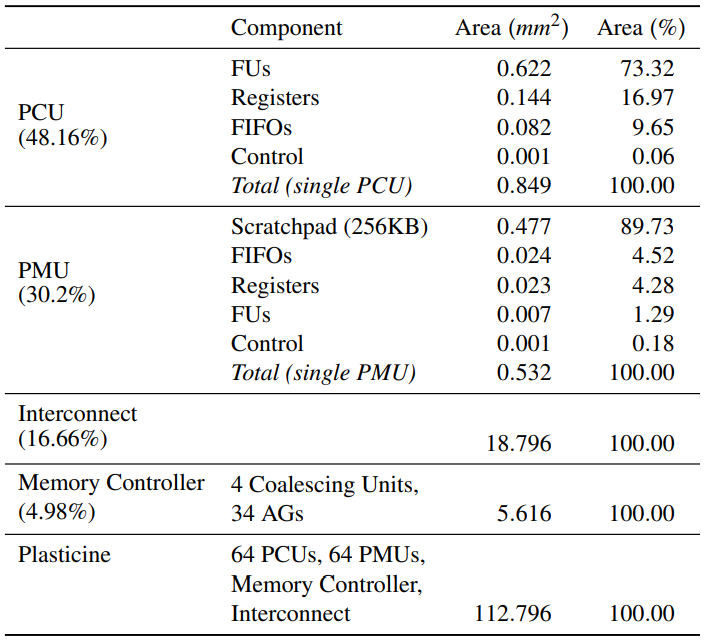
我们基于Chisel[2]使用表3所列选定参数实现Plasticine架构。该架构被组织成16×8的单元阵列,PMU与PCU的比例为1:1,使用Synopsys设计编译器(Synopsys Design Compiler)与28nm技术库进行综合。设计中的关键路径已被优化为1GHz时钟频率,芯片总面积的估算是在综合之后得到的,通过带有28nm库的Synopsys内存编译器(Synopsys Memory Compiler)获得本地scratchpad和FIFO的尺寸。我们使用Synopsys PrimeTime和RTL跟踪器对单个PCU、PMU和AG的功率进行分析,整个芯片的静态功率和所使用单元的动态功率都包括在总功率中。表5提供了Plasticine的组件面积细分,面积为112.77 。最终的Plasticine架构具有12.3个单精度TFLOPS峰值浮点性能和16MB的总片上scratchpad容量。
使用Synopsys VCS和DRAMSim2[39]进行精确周期模拟,测量芯片外内存访问时间,得到了Plasticine的执行时间。我们配置DRAMSim2模拟具有4个DDR3-1600通道的内存系统,给出51.2 GB/s的理论峰值带宽。
通过修改DHDL编译器,使用第3.6节中介绍的过程为Plasticine生成静态配置,每个基准测试被编译为一个Plasticine配置,用于对模拟器编程。Plasticine总运行时间在数据复制到加速器主内存后开始计算,当加速器执行完成时结束(即在将数据复制回主机之前)。
4.3. Plasticine设计开销
我们首先研究Plasticine架构中设计决定的面积开销。每个决定都被隔离开来,并根据一个理想化的架构进行评估。这些架构被归一化,以便在1GHz的时钟和固定的本地存储器大小下,确保每个基准测试的性能与它在最终的Plasticine架构上的性能相同。这些设计决定(表6的a-e列)允许每个基准测试有任意数量的PCU和PMU,这样做是为了解耦特定架构对具体决定和应用的影响。
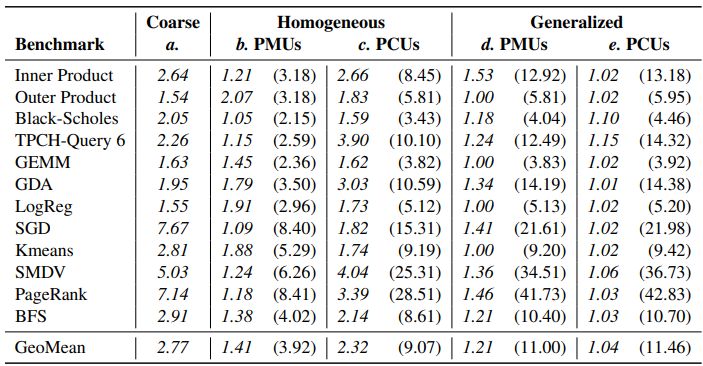
我们首先评估了将一个应用划分为粗粒度PCU和PMU的成本。在这里,我们将特定于基准ASIC设计的预计面积与具有异构(heterogeneous) PCU和PMU的理想Plasticine架构进行比较。对于给定基准,ASIC面积被估算为其计算和存储资源的面积之和。每个资源的面积都是用Synopsys DC来描述的。Plasticine架构具有第3节中描述的所有特征,包括配置逻辑、可配置的堆叠存储器和可静态配置的ALU。表6的a列显示了这种异构架构的预计成本与特定基准芯片设计的预计面积的关系。相对于ASIC设计,可重配单元的面积开销平均约为2.8倍。这是Plasticine的可重配性的基本开销,主要集中在使内存控制器可配置和将计算逻辑从固定操作转换为可重配FU。
虽然使用异构单元是利用面积的理想选择,但产生了一个难以解决的映射问题,而且不能在不同应用中通用。在表6的b列中,显示了从异构架构到仍然具有异构PCU但具有单一同构PMU设计的架构的成本。我们仍然允许这个PMU设计对每个基准来说是唯一的,但是在基准测试中,根据程序需要的最大scratchpad来确定PMU的大小。迁移到统一PMU的平均开销是1.4倍,对于内存大小急剧变化的应用程序,开销特别大。例如,OuterProduct对大小为N的向量tile和大小为 的输出tile使用本地存储器。在ASIC设计中,关于目标应用的静态知识允许将每个本地存储器专门化为所需大小和芯片数量,从而节省大量SRAM面积。在Plasticine中,我们选择了统一大小的存储器单元,从而简化映射,并提高特定应用可被路由的可能性。
c列显示了进一步限制PCU的开销,使其也是同质的,但在不同基准上仍有差异。这里的开销对于像PageRank这样有大量顺序循环的应用来说特别高。所有模式的主体都被映射到PCU中,但是由于每个PCU被固定为16个通道,顺序循环中的大部分通道以及大部分面积都没有被使用,导致开销高达8.4倍。同样,像TPCHQ6这样的计算流水线长度变化很大的应用,往往对同质PCU内的阶段利用不足。
我们接下来展示在所有应用中选择一组PMU参数后的面积开销。如第3.7节所述,这将所有基准中的scratchpad的总大小设定为每个256KB。虽然这种本地内存容量对GEMM和OuterProduct[33]等应用的性能至关重要,但其他应用的本地内存要求要小得多。从d列可以看出,这种未利用的SRAM容量的平均芯片面积开销为1.2倍。
e列列出了使用第3.7节中得到的数值在不同应用中通用化PCU的结果。在这里,我们看到剩余的开销与同质化单元的成本相比是很小的,对于BlackScholes来说,平均只有5%,最高为15%。这表明,不同应用中PCU需求的大部分变化已经被单个应用中的各种循环所代表,这反过来又使跨应用的计算通用化变得相对便宜。
综上所述,我们估计,与具有相同性能的特定应用芯片设计相比,我们的同质化、通用化、基于单元的架构的平均面积开销为3.9倍到42.8倍。当然,这种开销根据基准的本地内存和计算要求而有很大不同。虽然最终固定尺寸的Plasticine架构的PCU和PMU利用率(后来在表7中显示)往往低于100%,但我们不认为这本身是面积开销。相反,Plasticine架构被认为是一个"足够大"的结构,可以用来实现e列中列出的理想架构,剩余的单元资源可以用门控时钟优化。
4.4. FPGA设计
我们接下来比较Plasticine与FPGA的性能和功率。我们使用DHDL编译器来生成VHDL,然后使用Altera的综合工具为FPGA生成位流。我们在Altera 28nm Stratix V FPGA上运行每个合成的基准,通过PCIe与主机CPU控制器连接。该FPGA有一个150 MHz的结构时钟,一个400 MHz的存储器控制器时钟,以及48 GB的专用片外DDR3-800 DRAM,有6个通道,峰值带宽为37.5 GB/s。FPGA的执行时间为运行20次的平均值。与Plasticine一样,计时在数据从主机拷贝到FPGA的专用DRAM完成后开始,在FPGA执行完成后结束。我们还使用Altera的PowerPlay工具在基准放置和布线后获得了每个基准测试的FPGA功率估计。
4.5. Plasticine和FPGA比较
表7显示了在我们的一系列基准测试中,相对于Stratix V FPGA的Plasticine的利用率、功率、性能和每瓦性能。表格显示,与FPGA相比,Plasticine实现了更高的能源效率。表7显示了每个基准测试在两个平台上的资源利用率,接下来我们将讨论各个基准测试结果。
内积和TPC-H Query 6都分别实现了1.4倍的速度提升。这两个基准测试都是内存带宽约束,大量数据从DRAM中通过数据通路流出来,而计算量较小。因此,性能差异对应于各自平台上可实现的主内存带宽差异。Plasticine上的功耗也与FPGA相当,大部分PCU和一半PMU都没有使用,因此触发了功耗门控。
外积也是有带宽限制的,但有部分临时局部性,因此可以从更大的tile尺寸中受益。FPGA受限于可以实例化的具有多端口的大型存储器数量,这反过来又限制了可利用的内循环并行性以及潜在的计算与DRAM通信之间的并行处理。对堆叠的、有缓冲的scratchpad的本地支持使Plasticine能够更好利用SIMD和流水线并行性,从而实现6.7倍的速度提升。
Black-Scholes通过浮点操作流水线从DRAM中传输若干浮点阵列。每次访问DRAM时的大量浮点运算使其在大多数架构上受计算限制。虽然Black-Scholes的深度流水线性质使其成为FPGA加速的理想候选者,但FPGA在其主存储器带宽饱和之前就已经耗尽了实例化计算资源的空间。另一方面,Plasticine具有更高的浮点单元容量。在Plasticine上的BlackScholes可以被充分并行化,以至于受限于内存。从表7中可以看到,使用65%的PCU,Black-Scholes最大限度利用了DRAM带宽,实现了5.1倍的加速。
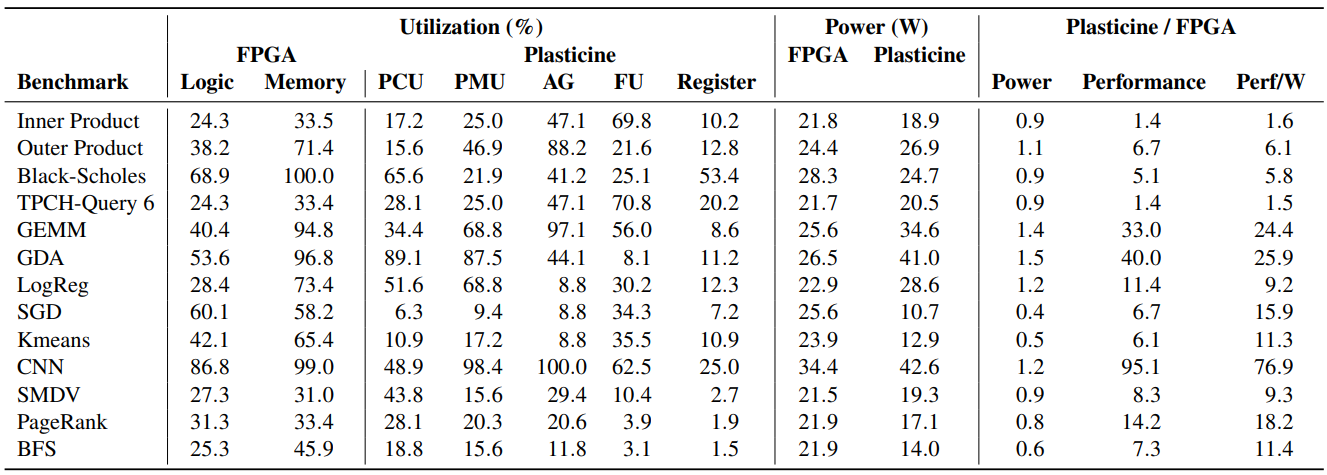
GEMM和GDA是计算受限的,具有充分的时间和空间局部性。在Plasticine上,GEMM实现了33.0倍的速度提升,GDA也有类似表现,速度提高了40.0倍。Plasticine可以通过将更大的tile加载到堆叠scratchpad来利用更多的局部性,并通过将scratchpad配置为双缓冲区来隐藏DRAM的通信延迟。在FPGA上,创建堆叠的双缓冲tile会在计算资源耗尽之前耗尽BRAM资源,从而限制了计算吞吐量。在目前GEMM与Plasticine的映射中,PCU通过在其数据路径中连续执行流水线内积,对两块tile进行乘法。并行性是在PCU内部跨通道实现的,在多个tile被并行处理的情况下,跨PCU也是如此。通过并行处理更多的输入tile,可以实现更多的并行性。因此,在目前的方案中,GEMM的性能受限于AG的数量,因为需要更多的AG来加载多个输入tile。此外,由于每个PCU都执行内积,不属于还原网络的FU就没有得到充分利用。更加复杂的映射方案,以及对PCU内阶段间FU通信的更多硬件支持,可以进一步提高计算利用率,从而提高性能[31]。
CNN是另一个计算密集型基准测试,在这种情况下,Plasticine的性能优于FPGA,提升达95.1倍。Plasticine的性能是由于更高的计算密度以及支持内核权重局部化和PMU部分结果局部化的能力。为了有效利用CNN中的滑动窗口重用,scratchpad被配置为行缓冲区,以避免不必要的DRAM重加载。每个PCU通过从一个PMU中读取内核权重并产生输出特征图到另一个PMU中来执行单一三维卷积。PCU中的FU之间的移位网络使数据在滑动窗口中得到重用,并在流水线寄存器中积累部分和,从而最大限度减少了scratchpad的读写。CNN目前被映射到Plasticine上,因此每个PCU需要2个PMU,一个用于保存内核权重,另一个用于存储输出特征图。由于Plasticine被配置为1:1的PCU:PMU比例,使得PCU的利用率上限为49.0%,而PMU和AG的利用率却达到了最大化。使用更多的PMU共享进行更优化的映射可以克服这个限制。
LogReg是一个计算量很大的基准测试,它使用大tile来捕捉局部性。并行性在外循环层面通过并行处理多个tile得到利用,在内循环层面则使用PCU内的SIMD通道。目前,编译器只在单个PCU的SIMD通道内利用内循环的并行性,而不在多个PCU之间分割内循环。通过以比FPGA更快的时钟速率并行处理更多的输入tile,Plasticine实现了11.4倍的速度提升。
SGD和K-means具有有顺外循环和可并行的内循环。这些应用固有的顺序性导致在Plasticine上的速度分别提高了6.7倍和6.1倍,这主要是由于Plasticine的时钟频率更高。然而,由于Plasticine只需要几个PCU来利用有限的并行性,大部分未使用的资源可以通过功耗门控,使每瓦性能分别提高39.8倍和12.3倍。
SMDV、PageRank和BFS在Plasticine上分别实现了8.3倍、14.2倍和7.3倍的速度提升。这些稀疏基准测试的性能受限于DDR随机访问DRAM的带宽。SMDV和PageRank只执行稀疏负载(gather),而BFS在每次迭代中执行gather和scatter,scatter和gather引擎是在FPGA上使用软逻辑实现的。这些基准测试的外循环被并行化,以产生多个并行的稀疏内存请求流,使得地址聚合后未处理的内存请求数量最大化。基准测试中使用的FPGA平台的随机访问DRAM带宽是有限的,所有通道都作为一个宽的DRAM通道以"ganged"模式运行。具有多个独立DRAM通道的FPGA平台在理论上可以比我们的FPGA基线在稀疏应用中表现得更好。然而,scatter-gather单元仍然必须在软逻辑中实现。scatter-gather单元需要大量本地存储器,但是本地存储器(BRAM)往往是FPGA上的关键资源,从而限制了未完成的存储器请求的数量和地址聚合的功效。此外,FPGA结构时钟通常比DRAM时钟慢,在利用随机访问带宽方面造成了另一个瓶颈。像Plasticine中的聚合单元这样的专用硬件允许以更有效的方式使用DRAM带宽。
总之,Plasticine可以最大限度提高内积和TPC-H Q6等流式应用的DRAM带宽利用率,并维持深度流水线数据通路的计算吞吐量,使Black-Scholes等应用受到内存约束。Plasticine为GEMM、GDA、CNN、LogReg、SGD和K-means等应用提供PMU和PCU间网络的数据局部化和通信模式。最后,通过支持大量具有地址聚合功能的未决内存请求,DRAM带宽被有效用于SMDV、Pagerank和BFS中的scatter和gather操作。
5. 相关工作
表2介绍了高效执行并行模式所需的关键体系架构特性,接下来我们讨论与这些特性相关的重要工作。
可重配scratchpad: 先前提出的几种可重配架构缺乏对可重配分布式scrachpad存储器的支持。如果不能使用支持并行模式所需的不同存储和缓冲策略重新配置片上内存系统,内存就会成为许多工作负载的瓶颈。
例如,ADRES[25]、DySER[17]、Garp[6]和Tartan[26]将可重配架构与CPU紧密结合,通过与主机CPU共享高速缓存层访问主内存。ADRES和DySER将可重配架构紧密整合到处理器流水线的执行阶段,因此依赖处理器的加载/存储单元进行内存访问。ADRES由功能单元网络、带有寄存器文件的可重配组件和共享多端口寄存器文件组成。DySER是一个可重配阵列,具有静态配置的互连,旨在以流水线方式执行最内层的循环体。然而,不支持带有后沿(back-edge)或反馈路径的数据流图,这使得执行诸如Fold和嵌套并行模式成为挑战。Garp由一个MIPS CPU核心和一个类似FPGA的协处理器组成。协处理器的位级静态互连产生了与传统FPGA相同的重配置开销,限制了计算密度。Piperench[16]由功能单元(FSU)的"stripes"流水线序列组成,每个stripe之间有一个字级crossbar,每个功能单元都有对应的寄存器文件,用来保存临时结果。Tartan由一个RISC核心和一个异步、粗粒度的可重配网络(RF, reconfigurable fabric)组成。RF架构是分层的,最顶层有一个动态互连,内部有一个静态互连,最内层的RF核心架构是按照Piperench[16]的模式设计的。
可重配数据通路: 具有可重配功能单元的架构的能耗较少,不会产生传统指令流水线的开销(如指令获取、解码和寄存器文件访问),这些开销约占CPU数据通路能耗的40%[18],约占GPU总动态能耗的30%[24]。此外,在GPU中使用可重配数据通路代替传统指令流水线,可以减少约57%的能耗[43]。Raw微处理器[42]是平铺式架构(tiled architecture),每个tile由一个单发有序处理器(single-issue in-order processor)、一个浮点单元、一个数据缓存和一个软件管理的指令缓存组成。tile使用流水线、字级静态和动态网络与最近的邻居通信。Plasticine不会产生上述动态网络和通用处理器的开销,基于硬件管理的缓存来代替可重配scratchpad,可以降低功耗和面积效率,有利于通用性。
密集数据通路和层次化流水线: Plasticine的分层架构,具有密集的流水线SIMD功能单元和分散的控制,能够在PCU内处理大量数据通信,并有效利用应用程序中的粗粒度流水线并行性。相反,在架构中缺乏对嵌套流水线分层支持的架构,基于全局互连交换大多数结果,从而使得互连成为带宽、功率或面积的瓶颈。例如,RaPiD[12]是由ALU、寄存器和存储器组成的一维阵列,对静态和动态控制有硬件支持。随后一个名为Mosaic[13]的研究项目包括一个静态混合互连,以及在多个互连配置之间切换的硬件支持。RaPiD的线性流水线强制执行僵硬的控制流,从而难以利用嵌套的并行性。HRL[14]将粗粒度和细粒度的逻辑块与混合静态互连相结合,虽然集中式scratchpad可以实现一些片上缓冲,但该架构主要是为内存密集型应用设计的,几乎没有局部性和嵌套并行性。Triggered[30]是由静态互连中的ALU和寄存器的粗粒度处理元件(PE, processing element)组成的架构。每个PE包含一个调度器和一个谓词寄存器(predicate register),通过触发器和特定动作执行数据流。Plasticine中使用的控制流机制与Triggered指令有一些相似之处。虽然这种架构可以灵活利用嵌套的并行性和局部性,但由于缺乏层次结构,增加了全局互连上的通信,可能会造成瓶颈,并降低数据路径的计算密度。
6. 结论
我们在本文中介绍了Plasticine,这是一种新型可重配架构,用于有效执行由并行模式组成的稀疏和密集应用程序。我们确定了处理稀疏和密集算法所需的关键计算模式,并介绍了粗粒度模式和内存计算单元,能够以流水线化、矢量化的方式执行并行模式。这些单元在我们的编程模型中利用了分层并行性、局部性和内存访问模式的信息。然后,我们基于设计空间探索指导Plasticine架构的设计,并创建了完整的软硬件堆栈,将应用程序映射为中间表示,然后在Plasticine上执行。实验证明,在113 的面积预算下,与类似工艺技术的FPGA相比,Plasticine的性能提高了95倍,每瓦性能提高了77倍。
致谢
感谢Tony Wu对本文的协助,并感谢审稿人的建议。这项工作得到了DARPA合同Air Force FA8750-12-2-0335; 陆军合同FA8750-14-2-0240和FA8750-12-20335; NSF资助CCF-1111943和IIS1247701的支持。本文包含的观点和结论是作者的观点和结论,不代表DARPA或美国政府的官方政策或认可。
参考文献
[1] Joshua Auerbach, David F. Bacon, Perry Cheng, and Rodric Rabbah. 2010. Lime: A Java-compatible and Synthesizable Language for Heterogeneous Architectures. In Proceedings of the ACM International Conference on Object Oriented Programming Systems Languages and Applications (OOPSLA). 89–108. https://doi.org/10.1145/1869459.1869469
[2] Jonathan. Bachrach, Huy Vo, Brian Richards, Yunsup Lee, Andrew Waterman, Rimas Avizienis, John Wawrzynek, and Krste Asanovic. 2012. Chisel: Constructing hardware in a Scala embedded language. In Design Automation Conference (DAC), 2012 49th ACM/EDAC/IEEE. 1212–1221.
[3] David Bacon, Rodric Rabbah, and Sunil Shukla. 2013. FPGA Programming for the Masses. Queue 11, 2, Article 40 (Feb. 2013), 13 pages. https://doi.org/10.1145/2436696.2443836
[4] Ivo Bolsens. 2006. Programming Modern FPGAs, International Forum on Embedded Multiprocessor SoC, Keynote,. http://www.xilinx.com/univ/mpsoc2006keynote.pdf.
[5] Benton. Highsmith Calhoun, Joseph F. Ryan, Sudhanshu Khanna, Mateja Putic, and John Lach. 2010. Flexible Circuits and Architectures for Ultralow Power. Proc. IEEE 98, 2 (Feb 2010), 267–282. https://doi.org/10.1109/JPROC.2009.2037211
[6] Timothy J. Callahan, John R. Hauser, and John Wawrzynek. 2000. The Garp architecture and C compiler. Computer 33, 4 (Apr 2000), 62–69. https://doi.org/10.1109/2.839323
[7] Jared Casper and Kunle Olukotun. 2014. Hardware Acceleration of Database Operations. In Proceedings of the 2014 ACM/SIGDA International Symposium on Fieldprogrammable Gate Arrays (FPGA ’14). ACM, New York, NY, USA, 151–160. https://doi.org/10.1145/2554688.2554787
[8] Bryan Catanzaro, Michael Garland, and Kurt Keutzer. 2011. Copperhead: compiling an embedded data parallel language. In Proceedings of the 16th ACM symposium on Principles and practice of parallel programming (PPoPP). ACM, New York, NY, USA, 47–56. https://doi.org/10.1145/1941553.1941562
[9] Yunji Chen, Tao Luo, Shaoli Liu, Shijin Zhang, Liqiang He, Jia Wang, Ling Li, Tianshi Chen, Zhiwei Xu, Ninghui Sun, and Olivier Temam. 2014. DaDianNao: A MachineLearning Supercomputer. In 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture. 609–622. https://doi.org/10.1109/MICRO.2014.58
[10] Yu-Hsin Chen, Tushar Krishna, Joel Emer, and Vivienne Sze. 2016. 14.5 Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. In 2016 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 262–263.
[11] Eric S. Chung, John D. Davis, and Jaewon Lee. 2013. LINQits: Big Data on Little Clients. In Proceedings of the 40th Annual International Symposium on Computer Architecture (ISCA ’13). ACM, New York, NY, USA, 261–272. https://doi.org/10.1145/2485922.2485945
[12] Darren C. Cronquist, Chris Fisher, Miguel Figueroa, Paul Franklin, and Carl Ebeling. 1999. Architecture design of reconfigurable pipelined datapaths. In Advanced Research in VLSI, 1999. Proceedings. 20th Anniversary Conference on. 23–40. https://doi.org/10.1109/ARVLSI.1999.756035
[13] Brian Van Essen, Aaron Wood, Allan Carroll, Stephen Friedman, Robin Panda, Benjamin Ylvisaker, Carl Ebeling, and Scott Hauck. 2009. Static versus scheduled interconnect in Coarse-Grained Reconfigurable Arrays. In 2009 International Conference on Field Programmable Logic and Applications. 268–275. https://doi.org/10.1109/FPL.2009.5272293
[14] Mingyu Gao and Christos Kozyrakis. 2016. HRL: Efficient and flexible reconfigurable logic for near-data processing. In 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA). 126–137. https://doi.org/10.1109/HPCA.2016.7446059
[15] Nithin George, HyoukJoong Lee, David Novo, Tiark Rompf, Kevin J. Brown, Arvind K. Sujeeth, Martin Odersky, Kunle Olukotun, and Paolo Ienne. 2014. Hardware system synthesis from Domain-Specific Languages. In Field Programmable Logic and Applications (FPL), 2014 24th International Conference on. 1–8. https://doi.org/10.1109/FPL.2014.6927454
[16] Seth Copen Goldstein, Herman Schmit, Matthew Moe, Mihai Budiu, Srihari Cadambi, R. Reed Taylor, and Ronald Laufer. 1999. PipeRench: A Co/Processor for Streaming Multimedia Acceleration. In Proceedings of the 26th Annual International Symposium on Computer Architecture (ISCA ’99). IEEE Computer Society, Washington, DC, USA, 28–39. https://doi.org/10.1145/300979.300982
[17] Venkatraman. Govindaraju, Chen-Han Ho, Tony Nowatzki, Jatin Chhugani, Nadathur Satish, Karthikeyan Sankaralingam, and Changkyu Kim. 2012. DySER: Unifying Functionality and Parallelism Specialization for Energy-Efficient Computing. IEEE Micro 32, 5 (Sept 2012), 38–51. https://doi.org/10.1109/MM.2012.51
[18] Rehan Hameed, Wajahat Qadeer, Megan Wachs, Omid Azizi, Alex Solomatnikov, Benjamin C. Lee, Stephen Richardson, Christos Kozyrakis, and Mark Horowitz. 2010. Understanding Sources of Inefficiency in General-purpose Chips. In Proceedings of the 37th Annual International Symposium on Computer Architecture (ISCA ’10). ACM, New York, NY, USA, 37–47. https://doi.org/10.1145/1815961.1815968
[19] Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A Horowitz, and William J Dally. 2016. EIE: efficient inference engine on compressed deep neural network. arXiv preprint arXiv:1602.01528 (2016).
[20] David Koeplinger, Raghu Prabhakar, Yaqi Zhang, Christina Delimitrou, Christos Kozyrakis, and Kunle Olukotun. 2016. Automatic Generation of Efficient Accelerators for Reconfigurable Hardware. In International Symposium in Computer Architecture.
[21] Ian Kuon and Jonathan Rose. 2007. Measuring the Gap Between FPGAs and ASICs. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 26, 2 (Feb 2007), 203–215. https://doi.org/10.1109/TCAD.2006.884574
[22] Ian Kuon, Russell Tessier, and Jonathan Rose. 2008. FPGA Architecture: Survey and Challenges. Found. Trends Electron. Des. Autom. 2, 2 (Feb. 2008), 135–253. https://doi.org/10.1561/1000000005
[23] HyoukJoong Lee, Kevin J. Brown, Arvind K. Sujeeth, Tiark Rompf, and Kunle Olukotun. 2014. Locality-Aware Mapping of Nested Parallel Patterns on GPUs. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture (IEEE Micro).
[24] Jingwen Leng, Tayler Hetherington, Ahmed ElTantawy, Syed Gilani, Nam Sung Kim, Tor M. Aamodt, and Vijay Janapa Reddi. 2013. GPUWattch: Enabling Energy Optimizations in GPGPUs. In Proceedings of the 40th Annual International Symposium on Computer Architecture (ISCA ’13). ACM, New York, NY, USA, 487–498. https://doi.org/10.1145/2485922.2485964
[25] Bingfeng Mei, Serge Vernalde, Diederik Verkest, Hugo De Man, and Rudy Lauwereins. 2003. ADRES: An Architecture with Tightly Coupled VLIW Processor and CoarseGrained Reconfigurable Matrix. Springer Berlin Heidelberg, Berlin, Heidelberg, 61–70. https://doi.org/10.1007/978-3-540-45234-8_7
[26] Mahim Mishra, Timothy J. Callahan, Tiberiu Chelcea, Girish Venkataramani, Seth C. Goldstein, and Mihai Budiu. 2006. Tartan: Evaluating Spatial Computation for Whole Program Execution. In Proceedings of the 12th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS XII). ACM, New York, NY, USA, 163–174. https://doi.org/10.1145/1168857.1168878
[27] M. Odersky. 2011. Scala. http://www.scala-lang.org. (2011).
[28] Jian Ouyang, Shiding Lin, Wei Qi, Yong Wang, Bo Yu, and Song Jiang. 2014. SDA: Software-Defined Accelerator for LargeScale DNN Systems (Hot Chips 26).
[29] Kalin Ovtcharov, Olatunji Ruwase, Joo-Young Kim, Jeremy Fowers, Karin Strauss, and Eric S. Chung. 2015. Accelerating Deep Convolutional Neural Networks Using Specialized Hardware. Technical Report. Microsoft Research. http://research-srv.microsoft.com/pubs/240715/CNN%20Whitepaper.pdf
[30] Angshuman Parashar, Michael Pellauer, Michael Adler, Bushra Ahsan, Neal Crago, Daniel Lustig, Vladimir Pavlov, Antonia Zhai, Mohit Gambhir, Aamer Jaleel, Randy Allmon, Rachid Rayess, Stephen Maresh, and Joel Emer. 2013. Triggered Instructions: A Control Paradigm for Spatially-programmed Architectures. In Proceedings of the 40th Annual International Symposium on Computer Architecture (ISCA ’13). ACM, New York, NY, USA, 142–153. https://doi.org/10.1145/2485922.2485935
[31] Ardavan Pedram, Andreas Gerstlauer, and Robert van de Geijn. 2012. On the Efficiency of Register File versus Broadcast Interconnect for Collective Communications in DataParallel Hardware Accelerators. In Proceedings of the 2012 IEEE 24th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD). 19–26. https://doi.org/10.1109/SBAC-PAD.2012.35
[32] Ardavan Pedram, Stephen Richardson, Sameh Galal, Shahar Kvatinsky, and Mark Horowitz. 2017. Dark memory and accelerator-rich system optimization in the dark silicon era. IEEE Design & Test 34, 2 (2017), 39–50.
[33] Ardavan Pedram, Robert van de Geijn, and Andreas Gerstlauer. 2012. Codesign Tradeoffs for High-Performance, Low-Power Linear Algebra Architectures. IEEE Transactions on Computers, Special Issue on Power efficient computing 61, 12 (2012), 1724–1736.
[34] Simon Peyton Jones [editor], John Hughes [editor], Lennart Augustsson, Dave Barton, Brian Boutel, Warren Burton, Simon Fraser, Joseph Fasel, Kevin Hammond, Ralf Hinze, Paul Hudak, Thomas Johnsson, Mark Jones, John Launchbury, Erik Meijer, John Peterson, Alastair Reid, Colin Runciman, and Philip Wadler. 1999. Haskell 98 — A Nonstrict, Purely Functional Language. Available from http://www.haskell.org/definition/.(feb 1999).
[35] Kara K. W. Poon, Steven J. E. Wilton, and Andy Yan. 2005. A Detailed Power Model for Field-programmable Gate Arrays. ACM Trans. Des. Autom. Electron. Syst. 10, 2 (April 2005), 279–302. https://doi.org/10.1145/1059876.1059881
[36] Raghu Prabhakar, David Koeplinger, Kevin J. Brown, HyoukJoong Lee, Christopher De Sa, Christos Kozyrakis, and Kunle Olukotun. 2016. Generating Configurable Hardware from Parallel Patterns. In Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’16). ACM, New York, NY, USA, 651–665. https://doi.org/10.1145/2872362.2872415
[37] Andrew Putnam, Adrian M. Caulfield, Eric S. Chung, Derek Chiou, Kypros Constantinides, John Demme, Hadi Esmaeilzadeh, Jeremy Fowers, Gopi Prashanth Gopal, Jan Gray, Michael Haselman, Scott Hauck, Stephen Heil, Amir Hormati, Joo-Young Kim, Sitaram Lanka, James Larus, Eric Peterson, Simon Pope, Aaron Smith, Jason Thong, Phillip Yi Xiao, and Doug Burger. 2014. A Reconfigurable Fabric for Accelerating Large-scale Datacenter Services. In Proceeding of the 41st Annual International Symposium on Computer Architecuture (ISCA ’14). IEEE Press, Piscataway, NJ, USA, 13–24. http://dl.acm.org/citation.cfm?id=2665671.2665678
[38] Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. 2013. Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI ’13). ACM, New York, NY, USA, 519–530. https://doi.org/10.1145/2491956.2462176
[39] Paul Rosenfeld, Elliott Cooper-Balis, and Bruce Jacob. 2011. DRAMSim2: A Cycle Accurate Memory System Simulator. IEEE Computer Architecture Letters 10, 1 (Jan 2011), 16–19. https://doi.org/10.1109/L-CA.2011.4
[40] Arvind K. Sujeeth, Kevin J. Brown, HyoukJoong Lee, Tiark Rompf, Hassan Chafi, Martin Odersky, and Kunle Olukotun. 2014. Delite: A Compiler Architecture for Performance-Oriented Embedded Domain-Specific Languages. In TECS’14: ACM Transactions on Embedded Computing Systems.
[41] Arvind K. Sujeeth, Tiark Rompf, Kevin J. Brown, HyoukJoong Lee, Hassan Chafi, Victoria Popic, Michael Wu, Aleksander Prokopec, Vojin Jovanovic, Martin Odersky, and Kunle Olukotun. 2013. Composition and Reuse with Compiled Domain-Specific Languages. In European Conference on Object Oriented Programming (ECOOP).
[42] Michael Bedford Taylor, Jason Kim, Jason Miller, David Wentzlaff, Fae Ghodrat, Ben Greenwald, Henry Hoffman, Paul Johnson, Jae-Wook Lee, Walter Lee, Albert Ma, Arvind Saraf, Mark Seneski, Nathan Shnidman, Volker Strumpen, Matt Frank, Saman Amarasinghe, and Anant Agarwal. 2002. The Raw Microprocessor: A Computational Fabric for Software Circuits and General-Purpose Programs. IEEE Micro 22, 2 (March 2002), 25–35. https://doi.org/10.1109/MM.2002.997877
[43] Dani Voitsechov and Yoav Etsion. 2014. Single-graph Multiple Flows: Energy Efficient Design Alternative for GPGPUs. In Proceeding of the 41st Annual International Symposium on Computer Architecuture (ISCA ’14). IEEE Press, Piscataway, NJ, USA, 205–216. http://dl.acm.org/citation.cfm?id=2665671.2665703
[44] Lisa Wu, Andrea Lottarini, Timothy K. Paine, Martha A. Kim, and Kenneth A. Ross. 2014. Q100: The Architecture and Design of a Database Processing Unit. In Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’14). ACM, New York, NY, USA, 255–268. https://doi.org/10.1145/2541940.2541961
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
本文由 mdnice 多平台发布