点此获取更多相关资料
本文为霍格沃兹测试开发学社学员学习笔记分享
原文链接:https://ceshiren.com/t/topic/27058
python 内置库 正则表达式
目录
- 正则表达式
- 使用re模块实现正则表达式操作
正则表达式
- 正则表达式就是记录文本规则的代码
- 可以查找操作符合某些复杂规则的字符串
在 python 中使用正则表达式
- 把正则表达式作为模式字符串
- 正则表达式可以使用原生字符串来表示
- 原生字符串需要在字符串前方加上 r’string’
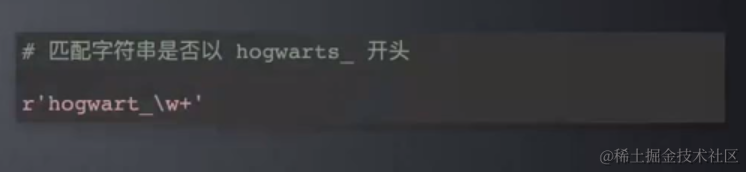
使用 re 模块实现正则表达式操作
正则表达式对象转换
-
compile():将字符串转换为正则表达式对象
-
需要多次使用这个正则表达式的场景

import re
# 匹配包含abc的字符串
paten = r'abc'
# 转换为正则对象
parens = re.compile(paten)
匹配字符串
- match():从字符串的开始处进行匹配
- search():在整个字符串中搜索第一个匹配的值
- findall():在整个字符串中搜索所有符合正则表达式的字符串,返回列表

import re
# 匹配包含abc的字符串
paten = r'abc\w+'
# 转换为正则对象
s1 = 'Abcskd = 123 is not right abcddd'
match1 = re.match(paten,s1,re.I)
print(f'match1={match1}') # 结果是:match1=<re.Match object; span=(0, 6), match='Abcskd'>
print(f'匹配值的起始位置是:{match1.start()}') # 结果是:匹配值的起始位置是:0
print(f'匹配值的结束位置是:{match1.end()}') # 结果是:匹配值的结束位置是:6
print(f'匹配位置的元组是:{match1.span()}') # 结果是:匹配位置的元组是:(0, 6)
print(f'要匹配的字符串是:{match1.string}') # 结果是:要匹配的字符串是:Abcskd = 123 is not right abcddd
print(f'匹配的数据是:{match1.group()}') # 结果是:匹配的数据是:Abcskd
s2 = 'hogwars is aBcfnjk over abcednjk'
match2 = re.search(paten,s2,re.I)
print(f'match2={match2}') # 结果是:match2=<re.Match object; span=(11, 18), match='aBcfnjk'>
match3 = re.findall(paten,s2,re.I)
print(f'match3={match3}') # 结果是:match3=['aBcfnjk', 'abcednjk']
替换字符串
- sub():实现字符串替换

import re
# 匹配手机号码
patten = r'1[3578]\d{9}'
s1 = '中奖号码是12352,联系电话是 13396541515'
resoult = re.sub(patten, '1**********', s1, re.I)
print(resoult) # 结果是:中奖号码是12352,联系电话是 1**********
分隔字符串
- splite():根据正则表达式分隔字符串,返回列表

import re
# 匹配url
url = 'https://www.baidu.com/s?wd=python%20%E6%96%87%E4%BB%B6%E9%87%8D%E5%91%BD%E5%90%8D&rsv_spt=1&rsv_iqid=0xab0b52ee000f18bf&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&oq=python%2520%25E8%258E%25B7%25E5%258F%2596%25E6%2597%25B6%25E9%2597%25B4%25E5%258E%25BB%25E6%258E%2589%25E6%25AF%25AB%25E7%25A7%2592&rsv_btype=t&inputT=746127&rsv_t=d404tftRITts23PDJ3BYWWHgHT%2B4lUTFKkarp1PmGdtY5VvsqaU1dOBq3b4ua5I5gfQy&rsv_pq=d30f8b1a0009347e&rsv_n=2&rsv_sug2=0&rsv_sug4=746127'
paten = r'[?|&]'
s = re.split(paten,url)
print(s)
'''
['https://www.baidu.com/s',
'wd=python%20%E6%96%87%E4%BB%B6%E9%87%8D%E5%91%BD%E5%90%8D',
'rsv_spt=1', 'rsv_iqid=0xab0b52ee000f18bf', 'issp=1', 'f=8',
'rsv_bp=1', 'rsv_idx=2', 'ie=utf-8', 'rqlang=cn',
'tn=baiduhome_pg', 'rsv_enter=1', 'rsv_dl=tb',
'oq=python%2520%25E8%258E%25B7%25E5%258F%2596%25E6%2597%25B6%25E9%2597%25B4%25E5%258E%25BB%25E6%258E%2589%25E6%25AF%25AB%25E7%25A7%2592',
'rsv_btype=t', 'inputT=746127', 'rsv_t=d404tftRITts23PDJ3BYWWHgHT%2B4lUTFKkarp1PmGdtY5VvsqaU1dOBq3b4ua5I5gfQy',
'rsv_pq=d30f8b1a0009347e', 'rsv_n=2', 'rsv_sug2=0', 'rsv_sug4=746127']
'''