Ding Jiaxiong【2022-12-16】
Gitee仓库:https://gitee.com/DingJiaxiong/machine-learning-study.git
文章目录
- 导入numpy
- 认识数组
- 数组的更多信息
- 创建基本数组
- 添加、删除和排序元素
- 数组的形状和大小
- 重塑数组
- 将一维数组转换为二维数组【即如何向数组中添加新轴】
- 索引和切片
- 从现有数据创建数组
- 基础数组操作
- 广播
- 一些更有用的数组操作
- 创建矩阵
- 生成随机数
- 获取唯一值和计数
- 转置和重塑矩阵
- 数组反转
- 重塑和展平多维数组
- 获取帮助【自力更生】
- 使用数学公式
- 保存和加载Numpy对象
- 导入和导出CSV
- 使用Matplotlib绘制数组
导入numpy
import numpy as np
认识数组
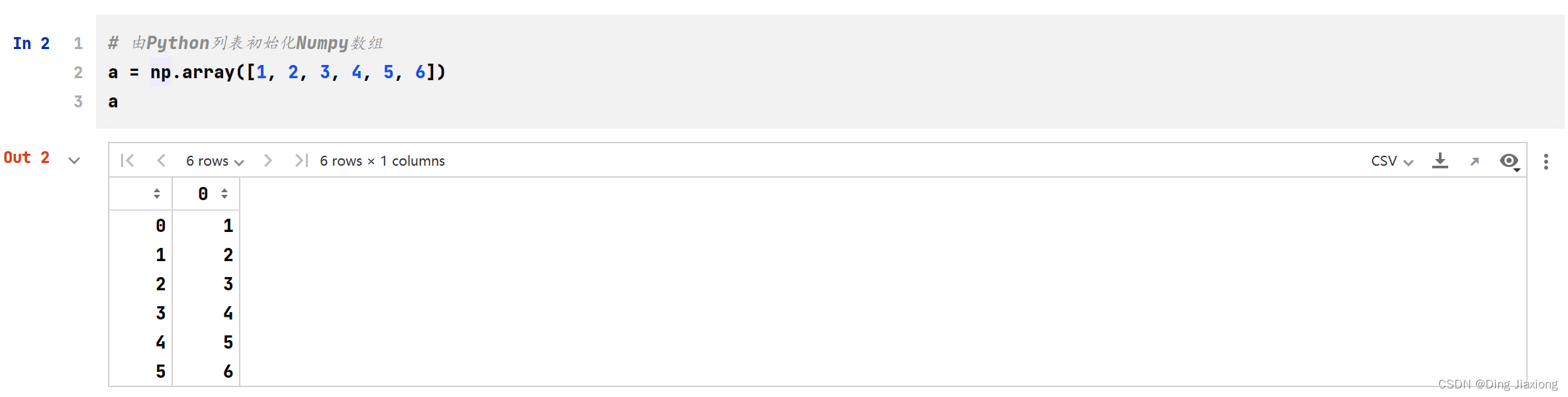
# 由Python列表初始化Numpy数组
a = np.array([1, 2, 3, 4, 5, 6])
a
## 二维数组
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
a

# 访问数组数据
print(a[0]) ## 打印“第一行”

数组的更多信息
在 NumPy 中,维度称为轴。这意味着,如果有一个如下所示的 2维 数组:
[[0., 0., 0.],
[1., 1., 1.]]

这个数组有2个轴,第一个轴的长度为2,第二个轴的长度为3
创建基本数组
要创建一个 NumPy 数组,可以使用函数 np.array().
a = np.array([1, 2, 3])
a

创建一个填充 0 的数组:
np.zeros(2)

或者一个填充 1 的数组:
np.ones(2)

empty 创建一个数组,其初始内容是随机的,并且取决于内存的状态。
np.empty(2)

创建包含一系列元素的数组:
np.arange(4)
array([0, 1, 2, 3])
包含一系列均匀间隔数据的数组。
np.arange(2, 9, 2) # 从2 到 9 ,不包含9,步长为2
array([2, 4, 6, 8])
使用 np.linspace() 创建一个数组,其值在指定的时间间隔内线性分布:
np.linspace(0, 10, num=5) # 这个就包含后面那个数
array([ 0. , 2.5, 5. , 7.5, 10. ])
指定数据类型
默认数据类型为浮点型 (np.float64),但可以使用 dtype 关键字显式指定所需的数据类型。
x = np.ones(2, dtype=np.int64)
x
array([1, 1], dtype=int64)
x.dtype
dtype('int64')
添加、删除和排序元素
使用 np.sort() 对元素进行排序很简单。可以在调用函数时指定轴、种类和顺序。
arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
arr
array([2, 1, 5, 3, 7, 4, 6, 8])
使用以下命令快速按升序对数字进行排序:
np.sort(arr)
array([1, 2, 3, 4, 5, 6, 7, 8])
如果从这些数组开始:
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
你可以用 np.concatenate() 连接它们.
np.concatenate((a, b))
array([1, 2, 3, 4, 5, 6, 7, 8])
或者,如果从这些数组开始:
x = np.array([[1, 2], [3, 4]])
x
array([[1, 2],
[3, 4]])
y = np.array([[5, 6]])
y
array([[5, 6]])
可以将它们与以下内容连接起来:
np.concatenate((x, y), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
数组的形状和大小
创建一个数组:
array_example = np.array([[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0, 1, 2, 3],
[4, 5, 6, 7]]])
数组的维数
array_example.ndim
3
数组中元素的总数
array_example.size # 3 x 2 x 4 = 24
24
数组的形状
array_example.shape
(3, 2, 4)
重塑数组
使用 arr.reshape() 将为数组提供新形状,而无需更改数据。
a = np.arange(6)
a
array([0, 1, 2, 3, 4, 5])
使用 reshape() 来重塑数组。
b = a.reshape(3, 2)
b
array([[0, 1],
[2, 3],
[4, 5]])
使用 np.reshape,可以指定一些可选参数:
np.reshape(a, newshape=(1, 6), order='C')
array([[0, 1, 2, 3, 4, 5]])
a 是要重塑的数组。
newshape形状是您想要的新形状。
order:C 表示使用类似 C 的索引顺序读取/写入元素,F 表示使用类似 Fortran 的索引顺序读取/写入元素,A 表示如果 a 在内存中是 Fortran 连续的,则以类似 Fortran 的索引顺序读取/写入元素,否则类似 C 的顺序
将一维数组转换为二维数组【即如何向数组中添加新轴】
可以使用 np.newaxis 和 np.expand_dims 来增加现有数组的维度。
使用 np.newaxis 在使用一次时,数组的维度将增加一维。 即一维变二维, 二维变三维…
a = np.array([1, 2, 3, 4, 5, 6])
a.shape
(6,)
使用 np.newaxis 添加新轴:
a2 = a[np.newaxis, :]
a2
array([[1, 2, 3, 4, 5, 6]])
a2.shape
(1, 6)
a
array([1, 2, 3, 4, 5, 6])
可以使用 np.newaxis 显式转换具有行向量或列向量的一维数组。例如,可以通过沿第一维插入轴将一维数组转换为行向量:
row_vector = a[np.newaxis, :]
row_vector.shape
(1, 6)
row_vector
array([[1, 2, 3, 4, 5, 6]])
对于列向量,可以沿第二个维度插入轴:
col_vector = a[:, np.newaxis]
col_vector.shape
(6, 1)
col_vector
array([[1],
[2],
[3],
[4],
[5],
[6]])
还可以通过在指定位置插入新轴来扩展数组
a = np.array([1, 2, 3, 4, 5, 6])
a.shape
(6,)
使用np.expand_dims在索引位置 1 处添加轴,如下所示:
b = np.expand_dims(a, axis=1)
b
array([[1],
[2],
[3],
[4],
[5],
[6]])
b.shape
(6, 1)
使用以下命令在索引位置 0 处添加轴:
c = np.expand_dims(a, axis=0)
c.shape
(1, 6)
索引和切片
可以像对 Python 列表进行切片一样对 NumPy 数组进行索引和切片。
data = np.array([1, 2, 3])
data
array([1, 2, 3])
data[1]
2
data[0:2]
array([1, 2])
data[1:]
array([2, 3])
data[-2:]
array([2, 3])
如果想从数组中选择满足某些条件的值,使用 NumPy 很简单。
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
a
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
打印数组中小于 5 的所有值。
print(a[a < 5])
[1 2 3 4]
选择等于或大于 5 的数字,并使用该条件为数组编制索引。
five_up = (a > 5)
print(a[five_up])
[ 6 7 8 9 10 11 12]
选择可被 2 整除的元素:
divisible_by_2 = a[a % 2 == 0]
divisible_by_2
array([ 2, 4, 6, 8, 10, 12])
使用 & 和 | 运算符选择满足两个条件的元素:
c = a[(a > 2) & (a < 11)]
c
array([ 3, 4, 5, 6, 7, 8, 9, 10])
使用逻辑运算符 & | 来返回布尔值,这些值指定数组中的值是否满足特定条件。
five_up = (a > 5) | (a == 5)
five_up
array([[False, False, False, False],
[ True, True, True, True],
[ True, True, True, True]])
使用 np.nonzero() 从数组中选择元素或索引。
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
a
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
使用 np.nonzero() 打印小于 5 的元素的索引:
b = np.nonzero(a < 5)
b
(array([0, 0, 0, 0], dtype=int64), array([0, 1, 2, 3], dtype=int64))
返回了一个数组元组:每个维度一个。第一个数组表示在其中找到这些值的行索引,第二个数组表示在其中找到这些值的列索引。
如果要生成元素所在的坐标列表,可以“打包”数组,循环访问坐标列表,然后打印它们
list_of_coordinates = list(zip(b[0], b[1]))
for coord in list_of_coordinates:
print(coord)
(0, 0)
(0, 1)
(0, 2)
(0, 3)
使用 np.nonzero() 打印数组中小于 5 的元素:
print(a[b])
[1 2 3 4]
如果要查找的元素在数组中不存在,则返回的索引数组将为空。
not_there = np.nonzero(a == 42)
not_there
(array([], dtype=int64), array([], dtype=int64))
从现有数据创建数组
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
a
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
从数组的某个部分创建新数组。
arr1 = a[3:8]
arr1
array([4, 5, 6, 7, 8])
还可以垂直和水平堆叠两个现有数组
a1 = np.array([[1, 1],
[2, 2]])
a2 = np.array([[3, 3],
[4, 4]])
a1
array([[1, 1],
[2, 2]])
a2
array([[3, 3],
[4, 4]])
使用 vstack 垂直堆叠它们:
np.vstack((a1, a2))
array([[1, 1],
[2, 2],
[3, 3],
[4, 4]])
用hstack水平堆叠它们:
np.hstack((a1, a2))
array([[1, 1, 3, 3],
[2, 2, 4, 4]])
可以使用 hsplit 将一个数组拆分为几个较小的数组。
x = np.arange(1, 25).reshape(2, 12)
x
array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]])
将此数组拆分为三个形状相等的数组
np.hsplit(x, 3)
[array([[ 1, 2, 3, 4],
[13, 14, 15, 16]]),
array([[ 5, 6, 7, 8],
[17, 18, 19, 20]]),
array([[ 9, 10, 11, 12],
[21, 22, 23, 24]])]
如果要在第三列和第四列之后拆分数组,
np.hsplit(x, (3, 4))
[array([[ 1, 2, 3],
[13, 14, 15]]),
array([[ 4],
[16]]),
array([[ 5, 6, 7, 8, 9, 10, 11, 12],
[17, 18, 19, 20, 21, 22, 23, 24]])]
使用 view 方法创建一个新的数组对象,该对象查看与原始数组相同的数据(浅拷贝)).
视图是一个重要的NumPy概念!NumPy 函数以及索引和切片等操作将尽可能返回视图。这样可以节省内存并且速度更快(无需复制数据)。但是,重要的是要注意这一点 - 修改视图中的数据也会修改原始数组!
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
通过对a切片创建数组b1
b1 = a[0, :]
b1
array([1, 2, 3, 4])
b1[0] = 99
b1
array([99, 2, 3, 4])
a
array([[99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
使用 copy 方法将创建数组及其数据的完整副本(深拷贝)。
b2 = a.copy()
b2
array([[99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
b2[0][0] = 10000
b2
array([[10000, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
a
array([[99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
基础数组操作
假设创建了两个数组,一个称为“data”,另一个称为“ones”
data = np.array([1, 2])
ones = np.ones(2, dtype=int)
data
array([1, 2])
ones
array([1, 1])
直接加
data + ones
array([2, 3])
当然,可以做的不仅仅是加
data - ones
array([0, 1])
data * data
array([1, 4])
data / data
array([1., 1.])
找到数组中元素的总和
a = np.array([1, 2, 3, 4])
a
array([1, 2, 3, 4])
a.sum()
10
求和的时候,指定行或列
b = np.array([[1, 1], [2, 2]])
b
array([[1, 1],
[2, 2]])
对行轴求和
b.sum(axis=0)
array([3, 3])
对列轴求和
b.sum(axis=1)
array([2, 4])
广播
有时,我们可能希望在数组和单个数字之间执行操作(也称为向量和标量之间的操作)或两个不同大小的数组之间的操作。
data = np.array([1.0, 2.0])
data
array([1., 2.])
data * 1.6
array([1.6, 3.2])
NumPy明白乘法应该发生在每个单元格上。这个概念称为广播。广播是一种允许 NumPy 对不同形状的数组执行操作的机制。
一些更有用的数组操作
NumPy还执行聚合功能。除了min值、max和sum之外,还可以轻松运行平均值来获取mean,prod 来获得将元素相乘的结果,std 来获得标准偏差等等。
data = np.array([1.0, 2.0])
data
array([1., 2.])
data.max()
2.0
data.min()
1.0
data.sum()
3.0
a = np.array([[0.45053314, 0.17296777, 0.34376245, 0.5510652],
[0.54627315, 0.05093587, 0.40067661, 0.55645993],
[0.12697628, 0.82485143, 0.26590556, 0.56917101]])
a
array([[0.45053314, 0.17296777, 0.34376245, 0.5510652 ],
[0.54627315, 0.05093587, 0.40067661, 0.55645993],
[0.12697628, 0.82485143, 0.26590556, 0.56917101]])
默认情况下,每个 NumPy 聚合函数都将返回整个数组的聚合。
a.sum()
4.8595784
a.min()
0.05093587
可以指定要在哪个轴上计算聚合函数。
a.min(axis=0) # 每一列的最小值
array([0.12697628, 0.05093587, 0.26590556, 0.5510652 ])
创建矩阵
Numpy中的二维数组我们又叫它矩阵
data = np.array([[1, 2], [3, 4], [5, 6]])
data
array([[1, 2],
[3, 4],
[5, 6]])
在操作矩阵时,索引和切片操作非常有用:
data[0, 1] # 0行1列上的元素 【这里的0和1是索引,不是第几那个概念,索引从0开始】
2
data[1:3] # 索引为1和2的行
array([[3, 4],
[5, 6]])
data[0:2, 0] # 行索引为0和1, 列索引为0
array([1, 3])
可以像聚合向量一样聚合矩阵:
data.max()
6
data.min()
1
data.sum()
21
也可以使用 axis 参数跨列或行聚合这些值。
data = np.array([[1, 2], [5, 3], [4, 6]])
data
array([[1, 2],
[5, 3],
[4, 6]])
data.max(axis=0) # 在”列方向“看
array([5, 6])
data.max(axis=1) # 在“行方向”上看
array([2, 5, 6])
如果有两个大小相同的矩阵,则可以使用算术运算符对它们进行加法和相乘。
data = np.array([[1, 2], [3, 4]])
ones = np.array([[1, 1], [1, 1]])
data
array([[1, 2],
[3, 4]])
ones
array([[1, 1],
[1, 1]])
data + ones
array([[2, 3],
[4, 5]])
可以对不同大小的矩阵执行这些算术运算,但前提是其中有一个矩阵只有一列或一行。在这种情况下,NumPy 将使用其广播规则进行操作。
data = np.array([[1, 2], [3, 4], [5, 6]])
ones_row = np.array([[1, 1]])
data
array([[1, 2],
[3, 4],
[5, 6]])
ones_row
array([[1, 1]])
data + ones_row
array([[2, 3],
[4, 5],
[6, 7]])
np.ones((4, 3, 2))
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
通常在某些情况下,我们希望 NumPy 初始化数组的值。NumPy提供了ones()和zeros()这样的函数,以及random.Generator用于生成随机数的生成器类。
np.ones(3)
array([1., 1., 1.])
np.zeros(3)
array([0., 0., 0.])
rng = np.random.default_rng()
rng.random(3)
array([0.53511988, 0.84021093, 0.42511468])
还可以使用这些来创建 2D 数组
np.ones((3, 2))
array([[1., 1.],
[1., 1.],
[1., 1.]])
np.zeros((3, 2))
array([[0., 0.],
[0., 0.],
[0., 0.]])
rng.random((3, 2))
array([[0.0082221 , 0.53379421],
[0.45228716, 0.19926061],
[0.44025569, 0.00170797]])
生成随机数
使用以下命令生成一个介于 0 和 4 之间的 2 x 4 随机整数数组:
rng.integers(5, size=(2, 4))
array([[3, 3, 0, 2],
[1, 4, 0, 1]], dtype=int64)
获取唯一值和计数
使用np.unique轻松找到数组中的唯一元素.
a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
a
array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
unique_values = np.unique(a)
unique_values
array([11, 12, 13, 14, 15, 16, 17, 18, 19, 20])
即去重
获取 NumPy 数组(数组中唯一值的第一个索引位置的数组)中唯一值的索引
unique_values, indices_list = np.unique(a, return_index=True)
indices_list
array([ 0, 2, 3, 4, 5, 6, 7, 12, 13, 14], dtype=int64)
在 np.unique() 中传递 return_counts 参数以及数组,以获取 NumPy 数组中唯一值的频率计数。
unique_values, occurrence_count = np.unique(a, return_counts=True)
occurrence_count
array([3, 2, 2, 2, 1, 1, 1, 1, 1, 1], dtype=int64)
这也适用于 2维 数组
a_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [1, 2, 3, 4]])
a_2d
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[ 1, 2, 3, 4]])
如果未传递轴参数,则 2D 数组将被展平。
unique_values = np.unique(a_2d)
unique_values
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
如果要获取唯一的行或列,请确保传递 axis 参数
“行方向”
unique_rows = np.unique(a_2d, axis=0)
unique_rows
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
若要获取唯一行、索引位置和出现次数,可以使用:
unique_rows, indices, occurrence_count = np.unique(a_2d, axis=0, return_counts=True, return_index=True)
unique_rows
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
indices
array([0, 1, 2], dtype=int64)
occurrence_count
array([2, 1, 1], dtype=int64)
转置和重塑矩阵
NumPy 数组具有属性 T,允许转置矩阵。
data = np.arange(1, 7)
data
array([1, 2, 3, 4, 5, 6])
data.reshape(2, 3)
array([[1, 2, 3],
[4, 5, 6]])
data.reshape(3, 2)
array([[1, 2],
[3, 4],
[5, 6]])
可以使用 .transpose() 根据指定的值反转或更改数组的轴。
arr = np.arange(6).reshape((2, 3))
arr
array([[0, 1, 2],
[3, 4, 5]])
用arr.transpose()转置数组.
arr.transpose()
array([[0, 3],
[1, 4],
[2, 5]])
也可以使用 arr.T:
arr.T
array([[0, 3],
[1, 4],
[2, 5]])
数组反转
NumPy 的 np.flip() 函数允许沿轴翻转或反转数组的内容。
【反转一维数组】
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
arr
array([1, 2, 3, 4, 5, 6, 7, 8])
reversed_arr = np.flip(arr)
print(reversed_arr)
[8 7 6 5 4 3 2 1]
【反转二维数组】
arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
arr_2d
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
reversed_arr = np.flip(arr_2d)
reversed_arr
array([[12, 11, 10, 9],
[ 8, 7, 6, 5],
[ 4, 3, 2, 1]])
只反转行
reversed_arr_rows = np.flip(arr_2d, axis=0)
reversed_arr_rows
array([[ 9, 10, 11, 12],
[ 5, 6, 7, 8],
[ 1, 2, 3, 4]])
只反转列
reversed_arr_columns = np.flip(arr_2d, axis=1)
reversed_arr_columns
array([[ 4, 3, 2, 1],
[ 8, 7, 6, 5],
[12, 11, 10, 9]])
还可以仅反转一列或一行的内容。
arr_2d[1] = np.flip(arr_2d[1])
arr_2d
array([[ 1, 2, 3, 4],
[ 8, 7, 6, 5],
[ 9, 10, 11, 12]])
还可以反转索引位置 1(第二列)处的列:
arr_2d[:, 1] = np.flip(arr_2d[:, 1])
arr_2d
array([[ 1, 10, 3, 4],
[ 8, 7, 6, 5],
[ 9, 2, 11, 12]])
重塑和展平多维数组
有两种流行的方法来展平数组:.flatten() 和 .ravel()两者之间的主要区别在于,使用 ravel() 创建的新数组实际上是对父数组的引用(即“视图”)。这意味着对新数组的任何更改也会影响父数组。由于 ravel 不会创建副本,因此它的内存效率很高。
x = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
x
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
使用flatten将数组展平为一维数组。
x.flatten()
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
使用flatten时,对新数组的更改不会更改父数组。
a1 = x.flatten()
a1[0] = 999
x
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
a1
array([999, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
但是当使用 ravel 时,对新数组所做的更改将影响父数组。
a2 = x.ravel()
a2[0] = 88
x
array([[88, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
a2
array([88, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
获取帮助【自力更生】
当涉及到数据科学生态系统时,Python和NumPy是在考虑用户的情况下构建的。最好的例子之一是对文档的内置访问。每个对象都包含对字符串的引用,该字符串称为文档字符串。在大多数情况下,此文档字符串包含对象的快速简洁摘要以及如何使用它。Python 有一个内置的 help() 函数,可以帮助你访问这些信息。这意味着几乎任何时候都需要更多信息,都可以使用 help() 快速找到所需的信息。
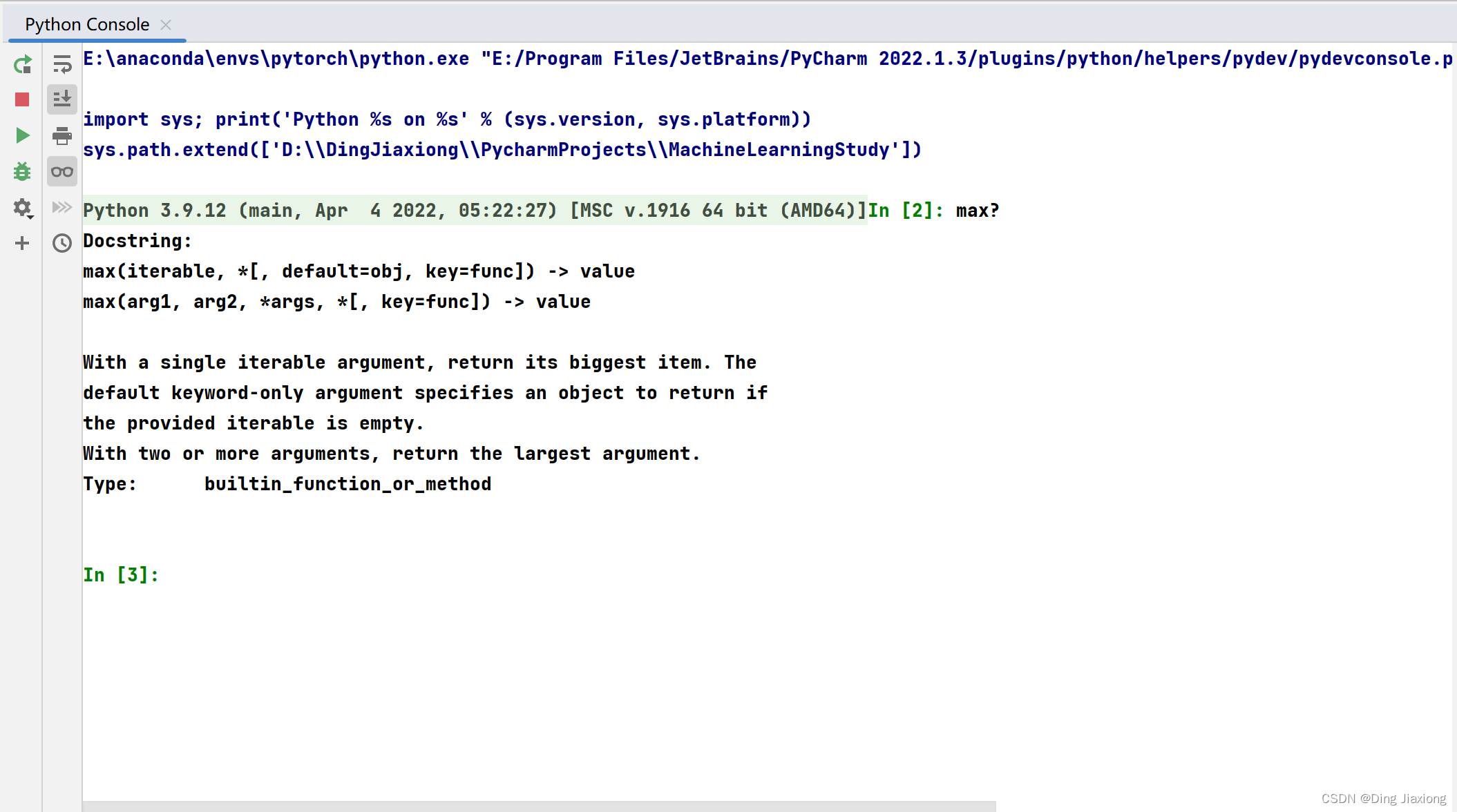
help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
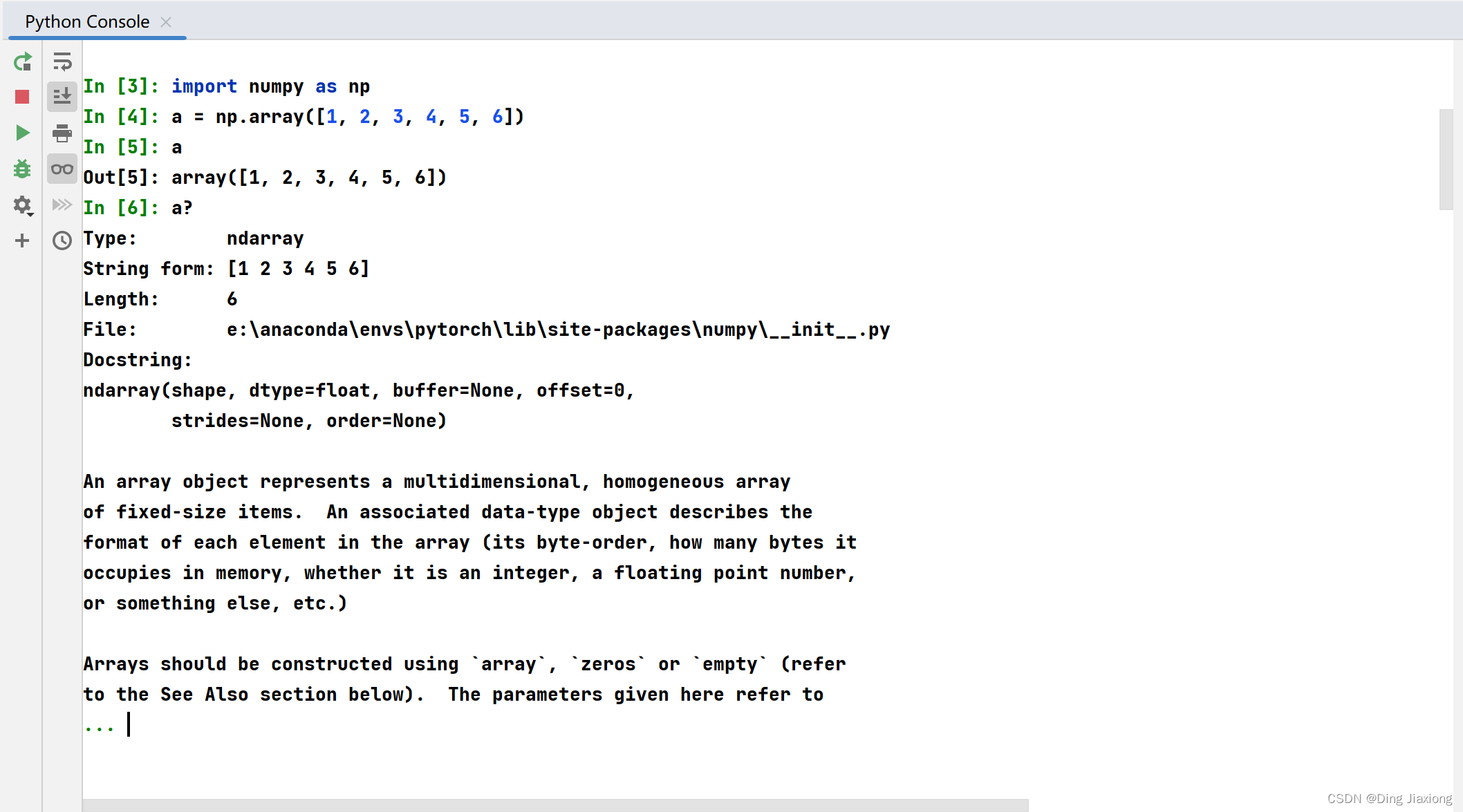
由于访问其他信息非常有用,因此 IPython 使用 ? 字符作为访问本文档以及其他相关信息的简写。IPython是多种语言的交互式计算的命令外壳。
我们还可以将此表示法用于对象方法和对象本身。
a = np.array([1, 2, 3, 4, 5, 6])
a
这也适用于创建的函数和其他对象
def double(a):
'''返回a * 2'''
return a * 2
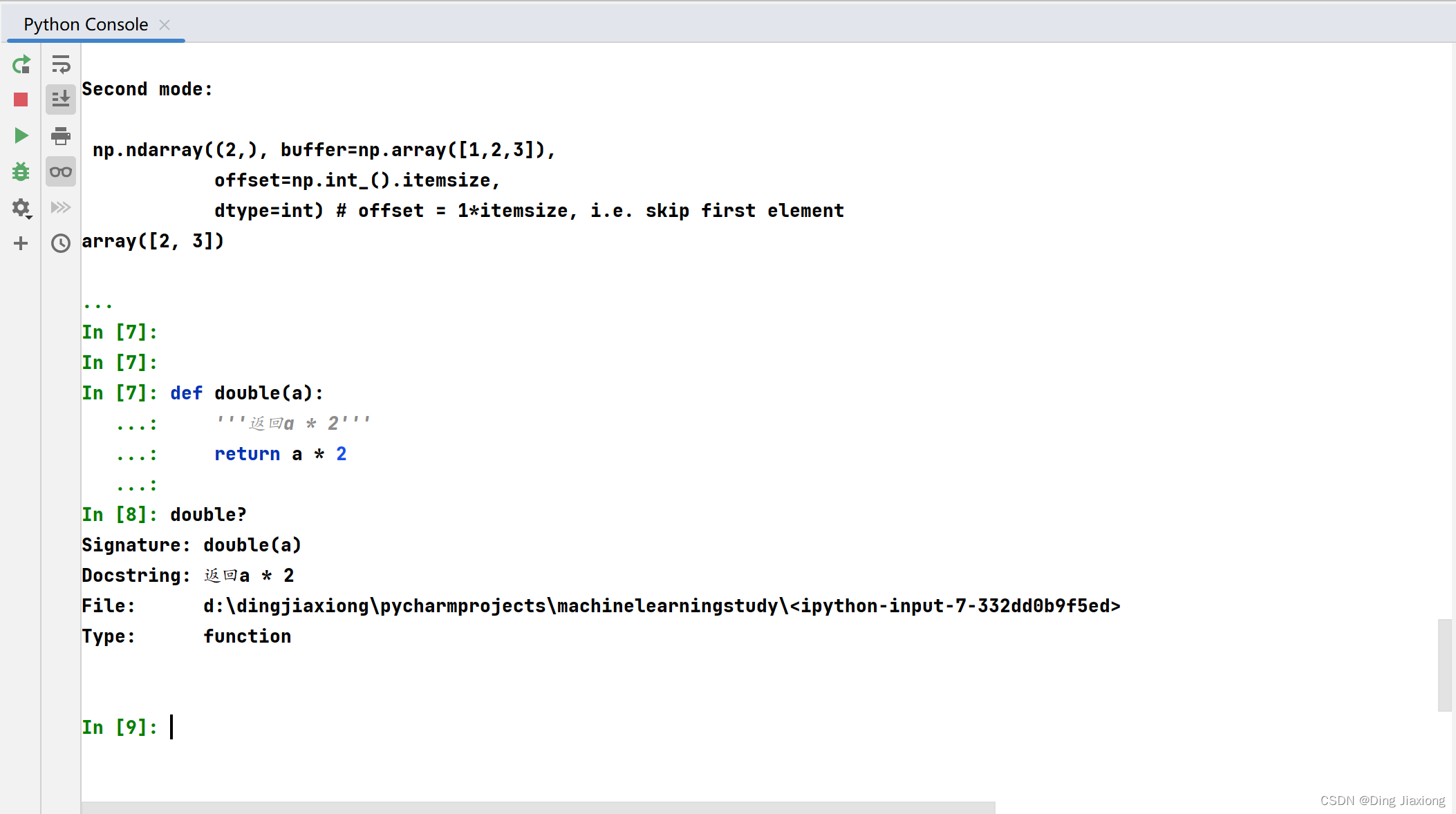
使用双问号 (??) 可以访问源代码。
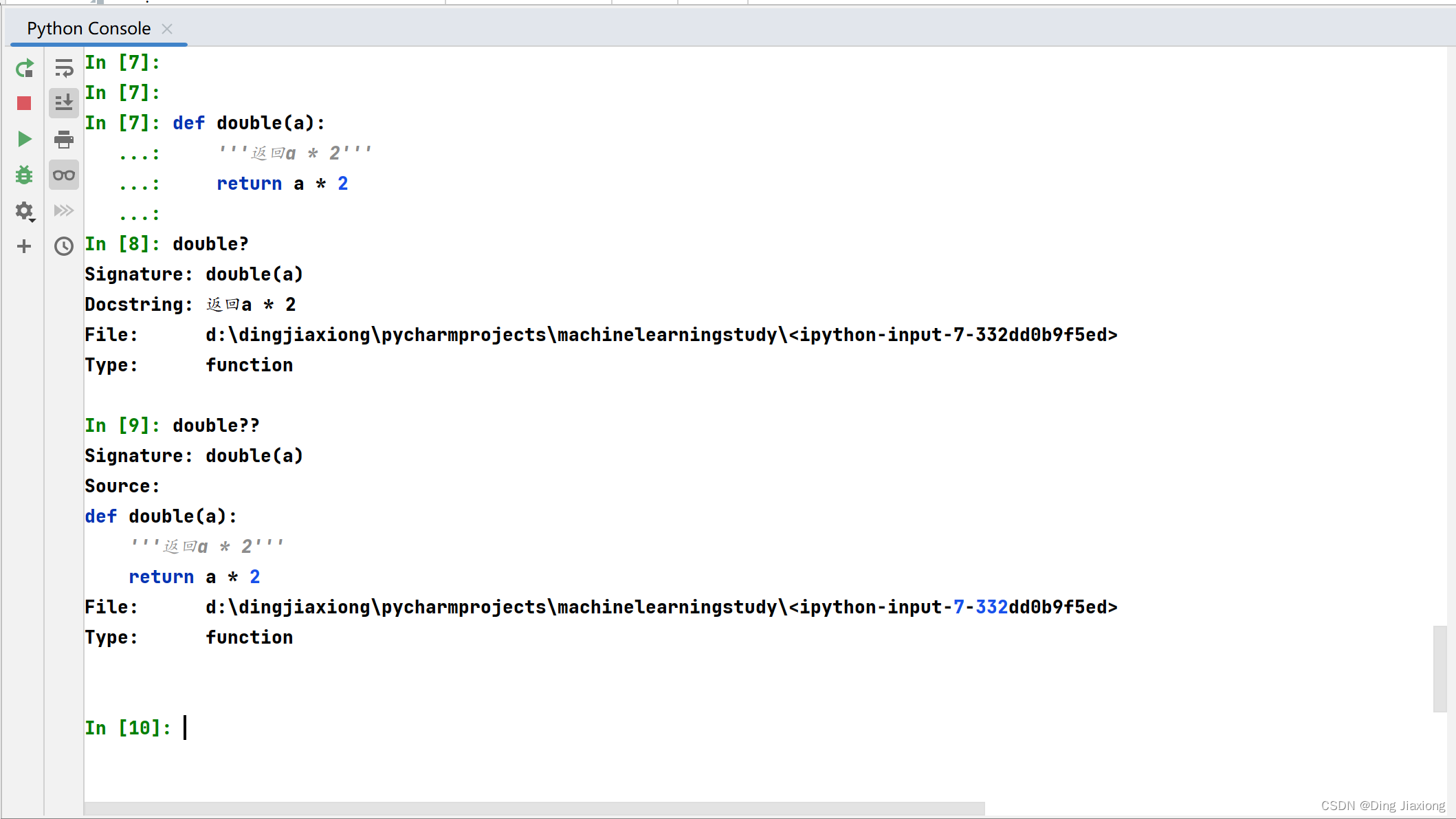
如果所讨论的对象是用 Python 以外的语言编译的,使用 ? 将返回与 ?? 你会发现这在许多内置对象和类型中,例如:
使用数学公式
均方误差公式
MeanSquareError = 1 n ∑ i = 1 n ( Y − prediction i − Y i ) 2 \text { MeanSquareError }=\frac{1}{n} \sum_{i=1}^n\left(Y_{-} \text {prediction }_i-Y_i\right)^2 MeanSquareError =n1i=1∑n(Y−prediction i−Yi)2
在 NumPy 中实现此公式既简单又直接:
error = (1 / n) * np.sum(np.square(predictions - lables))
保存和加载Numpy对象
在某些时候,我们可能会希望将数组保存到磁盘并重新加载它们,而无需重新运行代码。
.npy和.npz文件存储重建ndarray所需的数据,形状,dtype和其他信息,即使文件位于另一台具有不同体系结构的计算机上,也可以正确检索数组
a = np.array([1, 2, 3, 4, 5, 6])
a
array([1, 2, 3, 4, 5, 6])
通过以下方式将其另存为“文件名.npy”:
np.save('arraya', a)
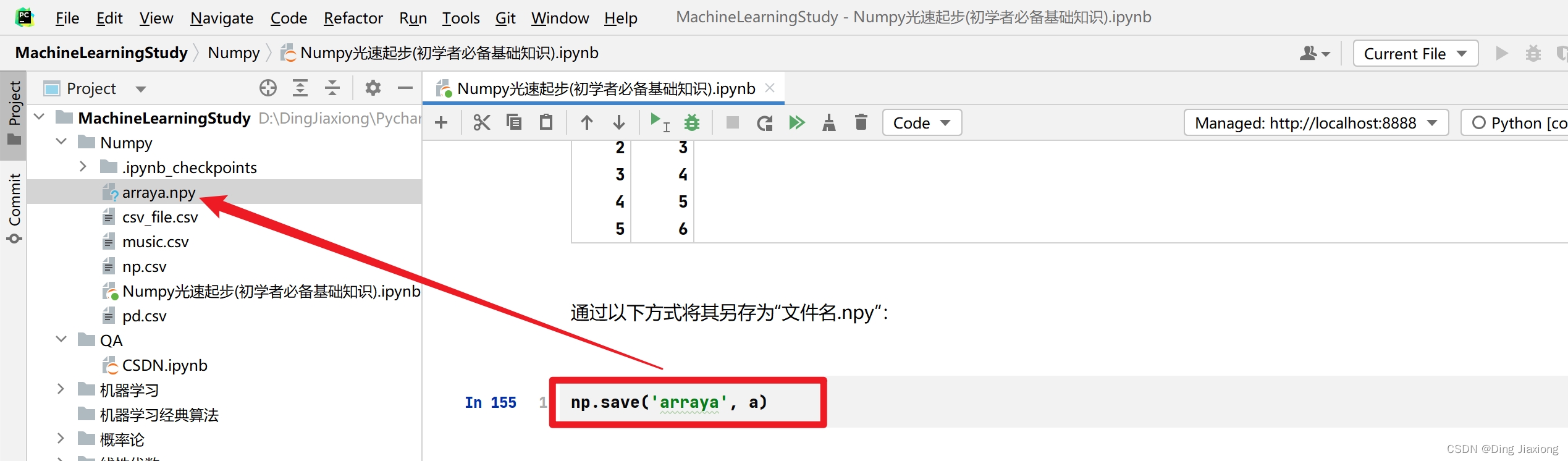
可以使用 np.load() 来重建数组。
b = np.load('arraya.npy')
b
array([1, 2, 3, 4, 5, 6])
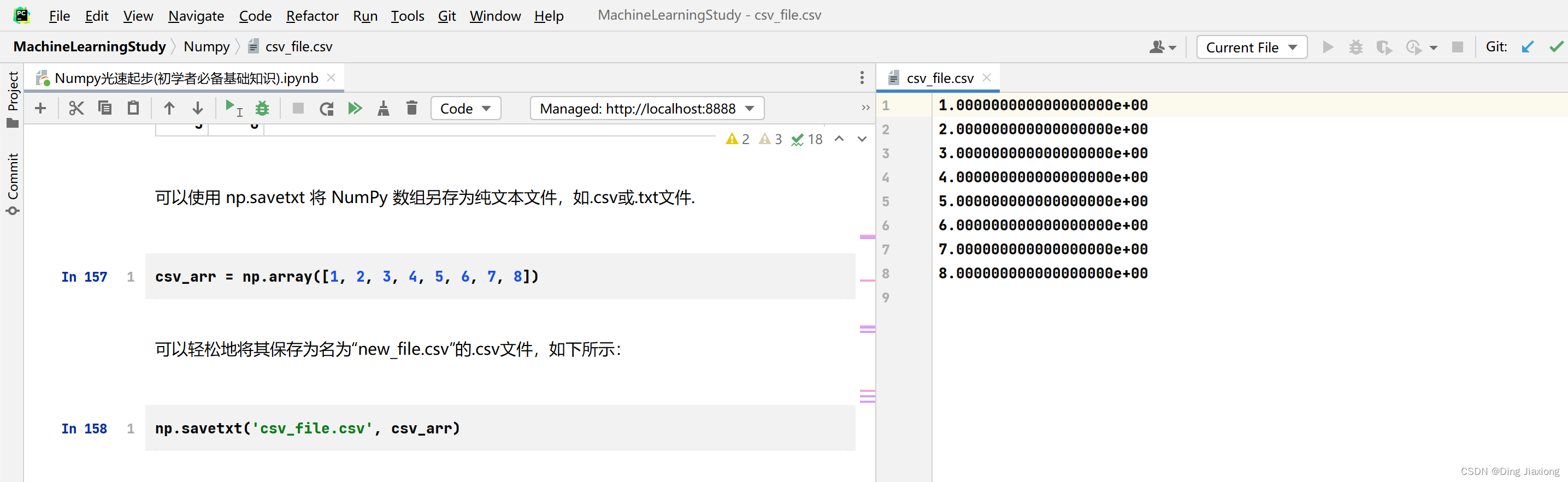
可以使用 np.savetxt 将 NumPy 数组另存为纯文本文件,如.csv或.txt文件.
csv_arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
可以轻松地将其保存为名为“new_file.csv”的.csv文件,如下所示:
np.savetxt('csv_file.csv', csv_arr)
可以使用 loadtxt() 快速轻松地加载保存的文本文件:
np.loadtxt("csv_file.csv")
array([1., 2., 3., 4., 5., 6., 7., 8.])
虽然文本文件可以更容易共享,但 .npy 和 .npz 文件更小,读取速度更快。
导入和导出CSV
在包含现有信息的 CSV 中阅读很简单。最好和最简单的方法是使用pandas
import pandas as pd
x = pd.read_csv("music.csv", header=0).values
print(x)
[['Billie Holiday' 'Jazz' 1300000 27000000]
['Jimmie Hendrix' 'Rock' 2700000 70000000]
['Miles Davis' 'Jazz' 1500000 48000000]
['SIA' 'Pop' 2000000 74000000]]
x = pd.read_csv("music.csv", usecols=['Artist', 'Plays']).values
print(x)
[['Billie Holiday' 27000000]
['Jimmie Hendrix' 70000000]
['Miles Davis' 48000000]
['SIA' 74000000]]
使用 Pandas 导出数组也很简单。
a = np.array([[-2.58289208, 0.43014843, -1.24082018, 1.59572603],
[0.99027828, 1.17150989, 0.94125714, -0.14692469],
[0.76989341, 0.81299683, -0.95068423, 0.11769564],
[0.20484034, 0.34784527, 1.96979195, 0.51992837]])
df = pd.DataFrame(a)
print(df)
0 1 2 3
0 -2.582892 0.430148 -1.240820 1.595726
1 0.990278 1.171510 0.941257 -0.146925
2 0.769893 0.812997 -0.950684 0.117696
3 0.204840 0.347845 1.969792 0.519928
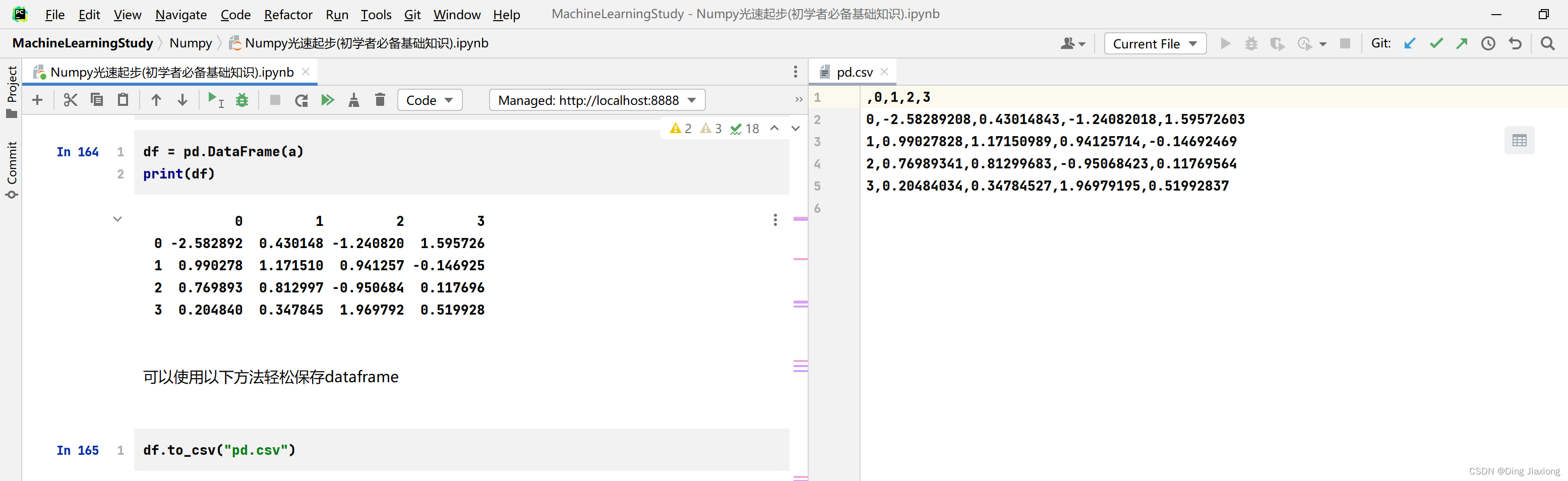
可以使用以下方法轻松保存dataframe
df.to_csv("pd.csv")
使用以下方法读取 CSV:
data = pd.read_csv("pd.csv")
data
| Unnamed: 0 | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|
| 0 | 0 | -2.582892 | 0.430148 | -1.240820 | 1.595726 |
| 1 | 1 | 0.990278 | 1.171510 | 0.941257 | -0.146925 |
| 2 | 2 | 0.769893 | 0.812997 | -0.950684 | 0.117696 |
| 3 | 3 | 0.204840 | 0.347845 | 1.969792 | 0.519928 |
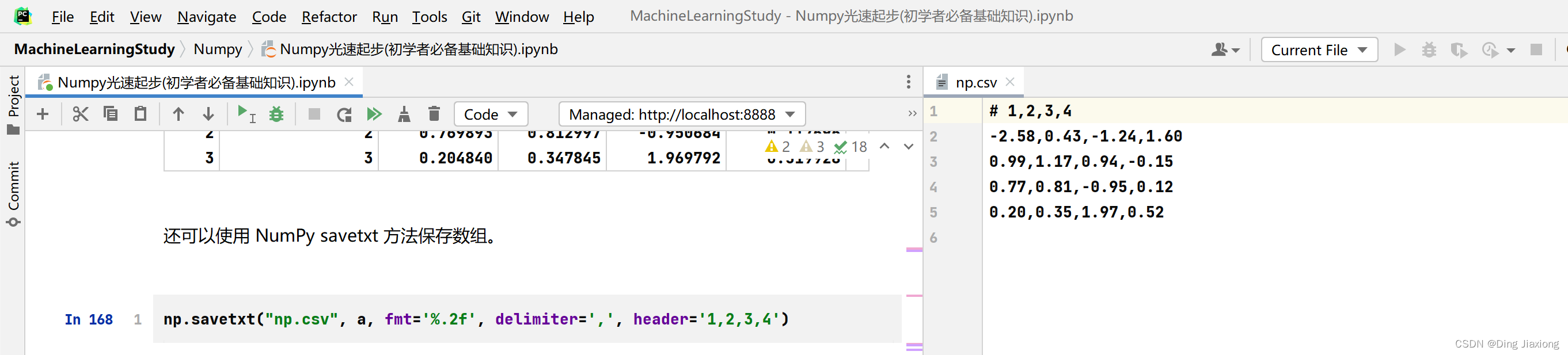
还可以使用 NumPy savetxt 方法保存数组。
np.savetxt("np.csv", a, fmt='%.2f', delimiter=',', header='1,2,3,4')
使用Matplotlib绘制数组
a = np.array([2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
a
array([ 2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
import matplotlib.pyplot as plt
plt.plot(a)


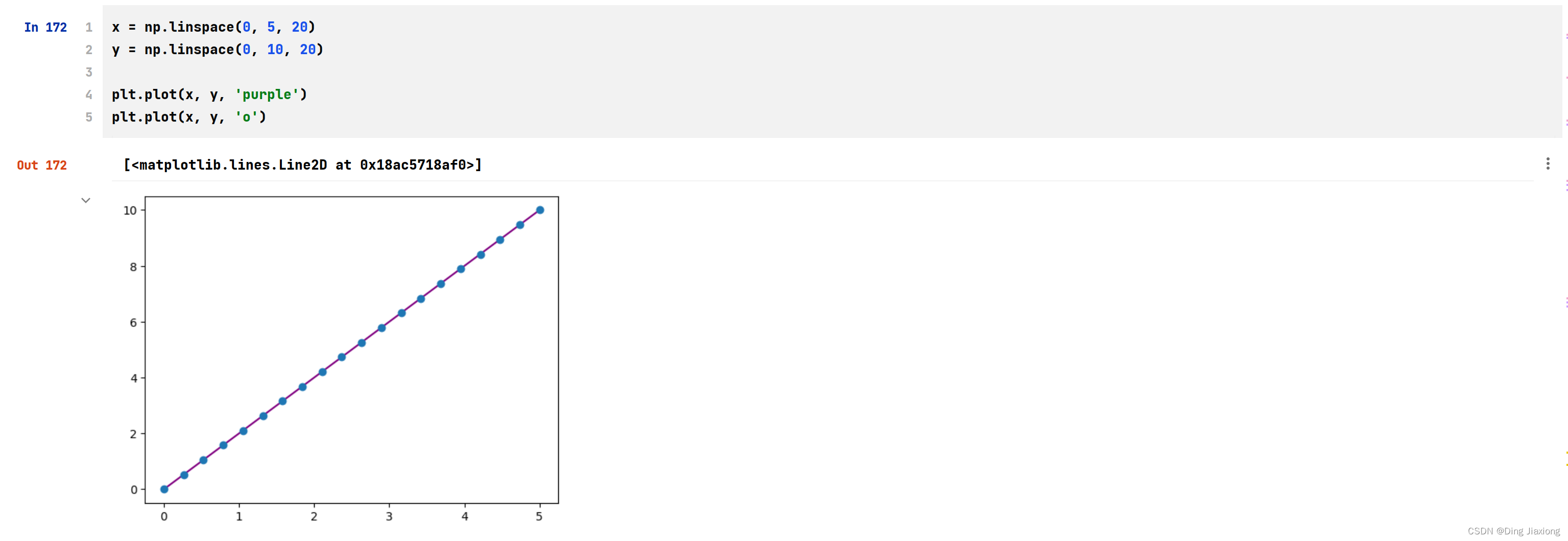
可以像这样绘制一维数组:
x = np.linspace(0, 5, 20)
y = np.linspace(0, 10, 20)
plt.plot(x, y, 'purple')
plt.plot(x, y, 'o')

使用Matplotlib,可以访问大量的可视化选项。
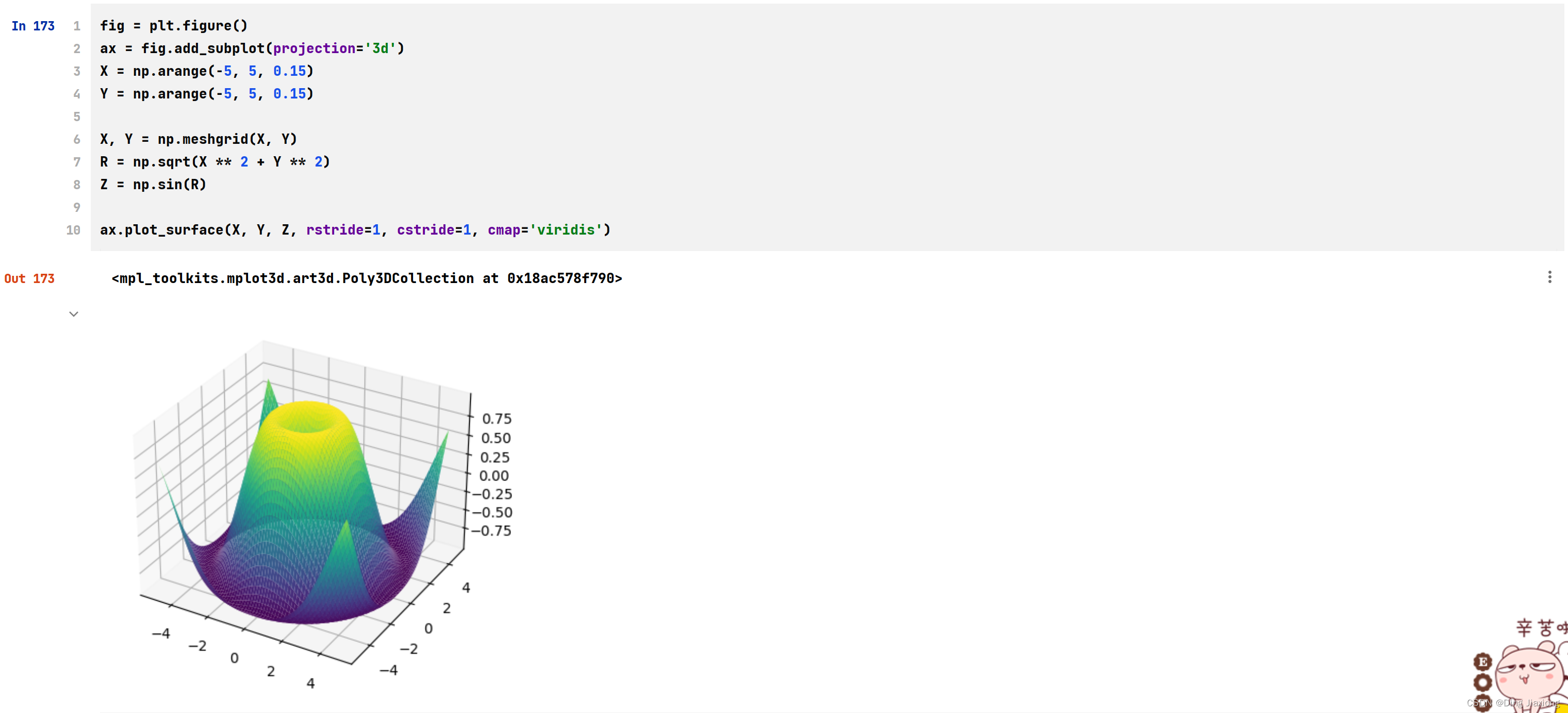
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
X = np.arange(-5, 5, 0.15)
Y = np.arange(-5, 5, 0.15)
X, Y = np.meshgrid(X, Y)
R = np.sqrt(X ** 2 + Y ** 2)
Z = np.sin(R)
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis')