嗨害大家好鸭! 我是小熊猫鸭~
大家是不是在写毕业论文的时候
需要参考某一段的内容
要用到复制粘贴,但是吧,某文库就需要付费,
就老难受了…
我们今天就来解决这个"老难受"
环境使用:
python 3.8
pycharm
模块使用
requests >>> 数据请求模块 pip install requests
docx >>> 文档保存 pip install python-docx
re 内置模块 不需要安装
一个小细节
文字识别:
1. 注册一个百度云API账号
2. 创建应用 并且去免费领取资源
3. 在技术文档里面 Access Token获取
4. 调用API接口做文字识别
本次地址

这里我没打前缀,不过审…自己打吧

模块安装问题:
- 如果安装python第三方模块:
- win + R 输入 cmd 点击确定,
- 输入安装命令 pip install 模块名 (pip install requests) 回车
- 在pycharm中点击Terminal(终端) 输入安装命令
-
安装失败原因:
-
失败一: pip 不是内部命令
解决方法: 设置环境变量 -
失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换
镜像源整理:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:https://pypi.hustunique.com/
山东理工大学:https://pypi.sdutlinux.org/
豆瓣:https://pypi.douban.com/simple/
例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好 或者你pycharm里面python解释器没有设置好
一. 分析数据来源
找文档数据内容, 是在哪个url里面生成的
- 通过开发者工具进行抓包分析
1. 打开开发者工具: F12 / 鼠标右键点击检查选择network
2. 刷新网页: 让本网页数据内容重新加载一遍
如果你是非VIP账号, 看数据, 图片形式 —> 把数据<图片> 获取下来 —> 做文字识别
3. 分析文库数据内容, 图片所在地址
源码、资料点击此处
二. 代码实现步骤
1. 发送请求, 模拟浏览器对于url地址发送请求

请求参数
data = {#python学习交流:660193417###
'docId': docId,
'query': name,
'recPositions': ''
}
请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/'
}
发送请求
response = requests.get(url=url, params=data, headers=headers)
# <Response [200]> 响应对象, 200 表示请求成功
print(response)
2. 获取数据, 获取服务器返回响应数据
response.json() 获取响应json字典数据, 但是返回数据必须是完整json数据格式 花括号 {}
response.text 获取响应文本数据, 返回字符串 任何时候都可以, 但是基本获取网页源代码的时候
response.content 获取响应二进制数据, 返回字节 保存图片/音频/视频/特定格式文件

3. 解析数据, 提取图片链接地址
定义文件名 整型
num = 1
# for循环遍历, 把列表里面元素一个一个提取出来
for index in response.json()['data']['relateDoc']:
# index 字典呀
pic = index['pic']
print(pic)
4. 保存数据, 把图片内容保存到本地文件夹
发送请求 + 获取数据 二进制数据内容
# img_content = requests.get(url=pic, headers=headers).content
# # 'img\\'<文件夹名字> + str(num)<文件名> + '.jpg'<文件后缀> mode='wb' 保存方式, 二进制保存
# # str(num) 强制转换成 字符串
# # '图片\\' 相对路径, 相对于你代码的路径 你代码在那个地方, 那个代码所在地方图片文件夹
# with open('图片\\' + str(num) + '.jpg', mode='wb') as f:
# # 写入数据 保存数据 把图片二进制数据保存
# f.write(img_content)
# # 每次循环 + 1
# print(num)
# num += 1
5. 做文字识别, 识别文字内容

进行文字识别

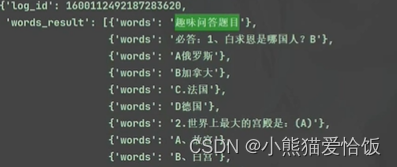
遍历一下

6.保存文档
# # 读取文件夹里面所有图片内容
# content_list = []
# files = os.listdir('img\\')
# for file in files:
# filename = 'img\\' + file
# words = get_content(file=filename)
# print(words)
# content_list.append(words)
#
# # 保存word文档里面
# doc = Document()
# # 添加第一段文档内容
# content = '\n'.join(content_list)
# doc.save('data.docx')
今天的文章就是这样啦~
我是小熊猫,咱下篇文章再见啦(✿◡‿◡)


![[附源码]Python计算机毕业设计Django绿色生活交流社区网站](https://img-blog.csdnimg.cn/3f401f852a494489b7e215a0bbd0b97b.png)