目录
一、创建数据库
1.1库界面方式
1.2SQL命令方式
二、修改数据库
2.1库界面方式
2.2SQL命令方式
三、删除数据库
3.1库界面方式
3.2SQL命令方式
四、附加和分离数据库
4.1附加和分离数据库概述
4.2作用
4.3附加和分离数据库方法
4.4示例
一、创建数据库
1.1库界面方式
在库界面选择数据库,然后右键选择【新建数据库】;
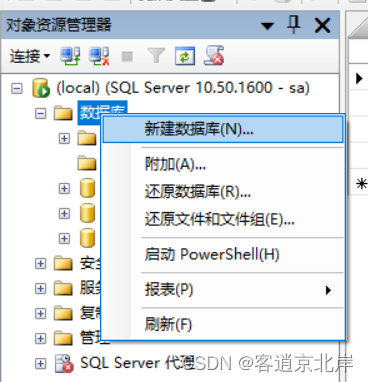
输入新建库的名字【test1】,其他都默认即可。

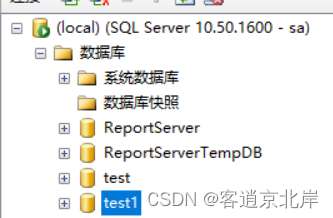
左侧状态栏刷新查看:
1.2SQL命令方式
正常情况下使用SQL命令方式创建数据库的时候,需要注意查看下主库中是否已经存在想要创建的数据库名字,如果发现存在该库时应提前删除后再创建,比如我要创建一个名为【mm】的数据库,简单方法就是查看左侧状态栏是否有【mm】数据库,有则手动删除,删除数据库的方法下面会讲。
查看结果库中有【mm】:

使用SQL命令查询方式如下:
--判断数据库文件是否存在,如果存在就删除
--其中exits是判断()语句是否返回值,如果有就返回true,否则就是false
IF EXISTS(SELECT 1 FROM sys.databases WHERE name='mm')
BEGIN
ALTER DATABASE [mm] SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE [mm];
END
执行命令行后刷新状态栏查看【mm】已删除:

使用SQL命令方式创建一个名字为【TEST2】的数据库,同时明确指定TEST2的数据文件和日志文件所存储的路径和大小等信息,如下所示:
CREATE DATABASE TEST2 --创建数据库TEST2
ON --如果是on primary 则表示是定义在主文件组上的文件
(
NAME='TEST2_DATA', --逻辑名称
FILENAME='E:\sqlsevertest\TEST2_DATA.MDF', --物理名称
SIZE=5MB, --初始大小为5MB
MAXSIZE=UNLIMITED, --最大限制为无限大
FILEGROWTH=10% --主数据文件增长幅度为10%
)
LOG ON
(
NAME='TEST2_LOG', --逻辑名称
FILENAME='E:\sqlsevertest\TEST2_LOG.LDF', --物理名称
SIZE=5MB, --初始大小为5MB
MAXSIZE=50MB, --最大限制是50MB
FILEGROWTH=1MB --事务日志增长幅度为1MB
)
GO
左侧状态栏刷新查看:

二、修改数据库
2.1库界面方式
在库界面左侧找到建立的数据库,比如【test1】,然后右键找到【属性】;

单击【属性】,在弹出窗口中选择【文件】,打开即可对数据库进行修改;

从此位置可以知道该库文件所在的位置以及所有者是谁,可以更改自动增长的数值。
2.2SQL命令方式
使用ALTER DATABASE命令对数据库可进行以下修改:
- 改变数据文件的大小和增长方式
- 改变日志文件的大小和增长方式
- 增加或删除数据文件
- 增加或删除日志文件
- 增加或删除文件组
语法格式如下:
ALTER DATABASE database_name
{ ADD FILE <filespec>[,…n][ TO FILEGROUP filegroup_name ] /*在文件组中增加数据文件*/
| ADD LOG FILE <filespec>[,…n] /*增加日志文件*/
| REMOVE FILE logical_file_name /*删除数据文件*/
| ADD FILEGROUP filegroup_name /*增加文件组*/
| REMOVE FILEGROUP filegroup_name /*删除文件组*/
| MODIFY FILE <filespec> /*更改文件属性*/
| MODIFY NAME = new_dbname /*数据库更名*/
| MODIFY FILEGROUP filegroup_name {filegroup_property | NAME = new_filegroup_name }
| SET <optionspec> [ ,...n ] [ WITH <termination> ] /*设置数据库属性*/
| COLLATE < collation_name > /*指定数据库排序规则*/
}
GO
举例如下:
已经创建了数据库【TEST2】,只有一个主数据文件,其逻辑文件名为TEST2_DATA,大小为5MB,最大为50MB,增长方式为按10%增长。即:

①假如修改数据库TEST2现有数据文件的属性,将主数据文件的最大大小改为100MB,增长方式改为按每次5MB增长,命令如下:
ALTER DATABASE TEST2
MODIFY FILE
(
NAME = TEST2_DATA, --这里是逻辑名
MAXSIZE = 100MB, --将主数据文件的最大大小改为100MB
FILEGROWTH = 5MB --将主数据文件的增长方式改为按5MB增长
)
GO
查看更改结果:

②为数据库TEST2添加文件组FGROUP,并为此文件组添加两个大小均为10MB的数据文件,命令如下:
ALTER DATABASE TEST2
ADD FILEGROUP FGROUP --新增文件组的名字
GO
ALTER DATABASE TEST2
ADD FILE
(
NAME = 'TEST2_DATA2',
FILENAME = 'E:\sqlsevertest\TEST2_DATA2.ndf',
SIZE = 10MB,
MAXSIZE = 30MB,
FILEGROWTH = 5MB
),
(
NAME = 'TEST2_DATA3',
FILENAME = 'E:\sqlsevertest\TEST2_DATA3.ndf',
SIZE = 10MB,
MAXSIZE = 30MB,
FILEGROWTH = 5MB
)
TO FILEGROUP FGROUP --添加到指定文件组
GO
查看文件路径如图所示即创建成功:

③从数据库中删除文件组,将②中添加到TEST2数据库中的文件组FGROUP删除,命令如下:
--先删除文件组中的文件
ALTER DATABASE TEST2
REMOVE FILE TEST2_DATA2
GO
ALTER DATABASE TEST2
REMOVE FILE TEST2_DATA3
GO
--再删除文件组
ALTER DATABASE TEST2
REMOVE FILEGROUP FGROUP
GO
查看文件路径如下图所示,即删除成功:

④为数据库TEST2添加一个日志文件,命令如下:
ALTER DATABASE TEST2
ADD LOG FILE
(
NAME = 'TEST2_LOG2',
FILENAME = 'E:\sqlsevertest\TEST2_LOG2.ldf',
SIZE = 5MB,
MAXSIZE = 10MB,
FILEGROWTH = 1MB
)
GO
查看文件途径如下所示即添加成功:
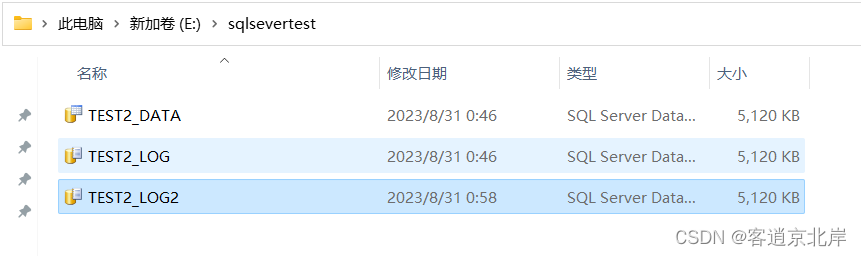
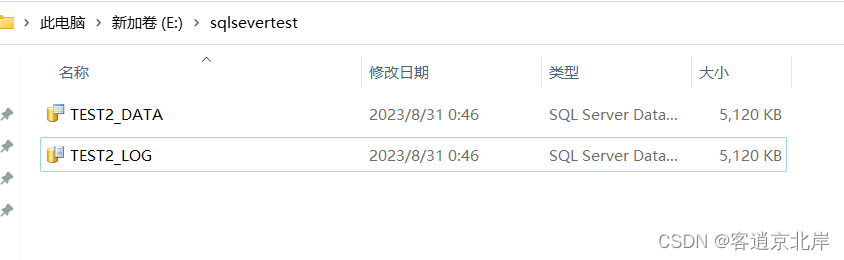
⑤从数据库TEST2中删除一个日志文件,将日志文件TEST2_LOG2删除,命令如下:
ALTER DATABASE TEST2
REMOVE FILE TEST2_LOG2
GO
查看文件路径如下所示即删除成功:
⑥将数据库TEST2的名改为JUST_TEST2,命令如下:
注意:
进行此操作时必须保证该数据库不被其他任何用户使用。
ALTER DATABASE TEST2
MODIFY NAME = JUST_TEST2
GO
执行命令后,刷新左侧状态栏查看,如下所示即修改成功:

三、删除数据库
3.1库界面方式
选择需要删除的数据库,然后在其上右键选择【删除】,

在弹出窗口中选择确定即可删除当前数据库;

3.2SQL命令方式
删除数据库使用DROP DATABASE 。。。命令,语法如下:
DROP DATABASE database_name[,…n][;]
GO
比如删除数据库test1,
DROP DATABASE test1
GO
刷线状态栏查看结果已删除成功:
四、附加和分离数据库
4.1附加和分离数据库概述
在SQL Server中,附加和分离数据库是用于管理数据库的两种操作。
-
附加数据库的目的:
附加数据库用于将已经存在的数据库文件(数据文件和日志文件)连接到SQL Server实例,并使其可用于查询和操作。附加数据库的主要作用是将现有的数据库文件加入到SQL Server的数据库列表中。通过附加数据库,可以将数据库从一个环境迁移到另一个环境,或者在不同的SQL Server实例之间共享数据库。 -
分离数据库的目的:
分离数据库用于从SQL Server实例中移除数据库,但保留数据库文件本身。通过分离数据库,可以将数据库从SQL Server实例中分离,而不会删除数据库文件。分离数据库的主要作用是在需要进行一些数据库维护操作或将数据库移动到其他服务器时,暂时从服务器中移除数据库,而不删除它。这可以使数据库在分离期间保持无法访问和修改的状态。
4.2作用
附加和分离数据库提供了方便的方式来管理数据库,并支持数据库的迁移、备份和恢复,以及将数据库从一个环境或服务器移动到另一个环境或服务器。
4.3附加和分离数据库方法
在SQL Server中,附加和分离数据库有以下方法:
4.3.1通过 SQL Server Management Studio (SSMS) 进行附加和分离。
- 附加数据库:在SSMS中,右键点击"数据库",选择"附加",浏览并选择要附加的数据库文件,点击"确定"。
- 分离数据库:在SSMS中,右键点击要分离的数据库,选择"任务",然后选择"分离"。
4.3.2使用 T-SQL 命令进行附加和分离。
- 附加数据库:
CREATE DATABASE [数据库名称] ON
(FILENAME = '数据库文件路径\DataFileName.mdf'),
(FILENAME = '数据库日志文件路径\LogFileName.ldf')
FOR ATTACH;- 分离数据库:
EXEC sp_detach_db N'数据库名称', N'false';4.3.3使用 PowerShell 进行附加和分离
- 附加数据库
$server = New-Object Microsoft.SqlServer.Management.Smo.Server "服务器名称"
$db = New-Object Microsoft.SqlServer.Management.Smo.Database $server, "数据库名称"
$db.Attach("$数据库文件路径\DataFileName.mdf",$数据库日志文件路径\LogFileName.ldf")- 分离数据库:
$server = New-Object Microsoft.SqlServer.Management.Smo.Server "服务器名称"
$db = $server.Databases["数据库名称"]
$db.DatabaseOptions.UserAccess = [Microsoft.SqlServer.Management.Smo.DatabaseUserAccess]::Single
$db.Alter(TSqlModel.DatabaseOptionsModification.Detach)注意:
这些方法可能有些差异,需要根据使用的SQL Server版本和工具选择合适的方法。
4.4示例
以下是使用T-SQL语句进行SQL Server附加和分离数据库的示例:
- 附加数据库:
USE [master]; --使用主数据库 -- 创建一个数据库 CREATE DATABASE [TestDB] ON (FILENAME = 'C:\TestDB\TestDB.mdf'), (FILENAME = 'C:\TestDB\TestDB_Log.ldf') FOR ATTACH;
请确保提供正确的数据库文件路径和文件名。
- CREATE DATABASE [TestDB]:创建一个名为TestDB的数据库。
- ON:指定要将数据库文件和日志文件放置的位置。
- FILENAME = 'C:\TestDB\TestDB.mdf':指定数据库的主要数据文件(TestDB.mdf)的路径和文件名。
- FILENAME = 'C:\TestDB\TestDB_Log.ldf':指定数据库的事务日志文件(TestDB_Log.ldf)的路径和文件名。
- FOR ATTACH:将创建的数据库附加到SQL Server实例中。这意味着数据库可以被查询和操作。
需要注意的是,在运行该语句之前,确保数据库文件(TestDB.mdf和TestDB_Log.ldf)已经存在,并且指定的文件路径是正确的。
- 分离数据库:
USE [master];
-- 分离数据库
EXEC sp_detach_db 'TestDB', 'true';这将分离名为"TestDB"的数据库。第二个参数设置为'true'表示不保存分离状态的元数据信息。
注意:
这些示例假设数据库文件和日志文件已经存在,并且通过提供正确的路径和文件名进行附加和分离操作。确保在执行任何重要数据操作之前创建数据库备份或做好必要的预防措施。