从谷歌浏览器的开发工具进入
选择图片右键点击检查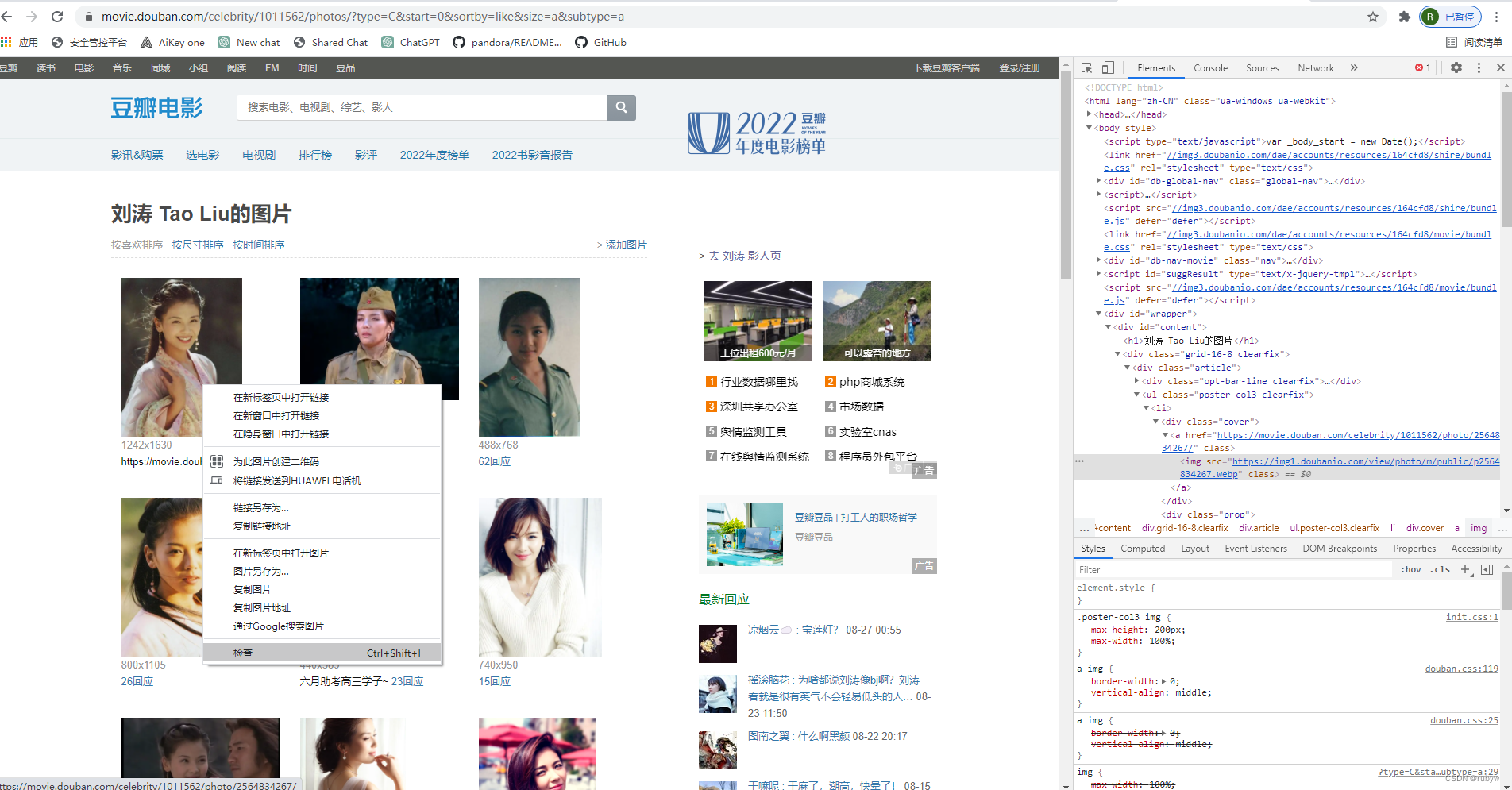

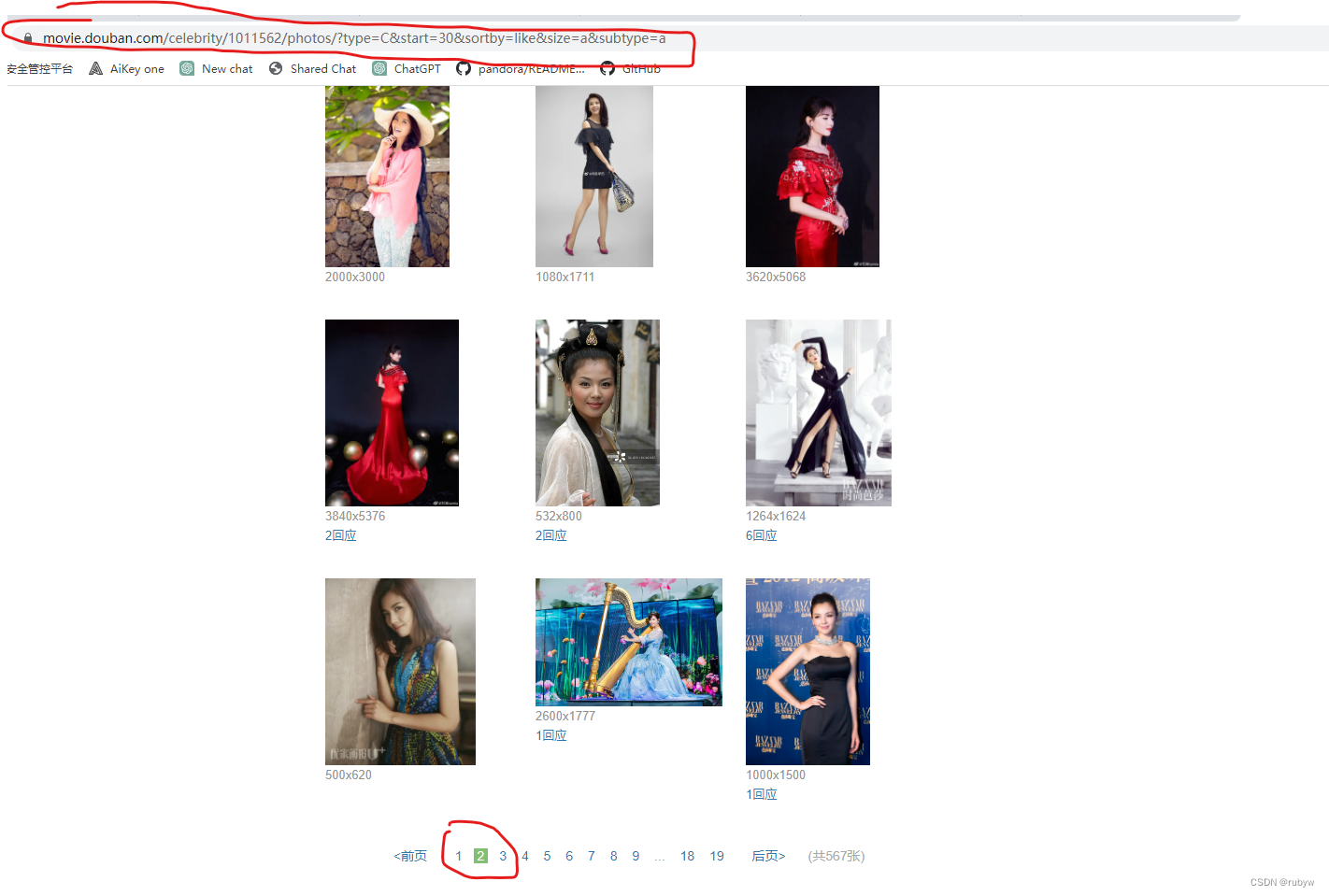
翻页之后发现网址变化的只有start数值,每次变化值为30
Python代码
import requests
from bs4 import BeautifulSoup
import time
import os
# 豆瓣影人图片
url = 'https://movie.douban.com/celebrity/1011562/photos/'
res = requests.get(url=url, headers="").text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
print(picture_list)
# https://movie.douban.com/celebrity/1011562/photos/?type=C&start=30&sortby=like&size=a&subtype=a
def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_list
# XPath://*[@id="content"]/div/div[1]/ul/li[1]/div[1]/a/img
def download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url=url, headers="").text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)
fire()
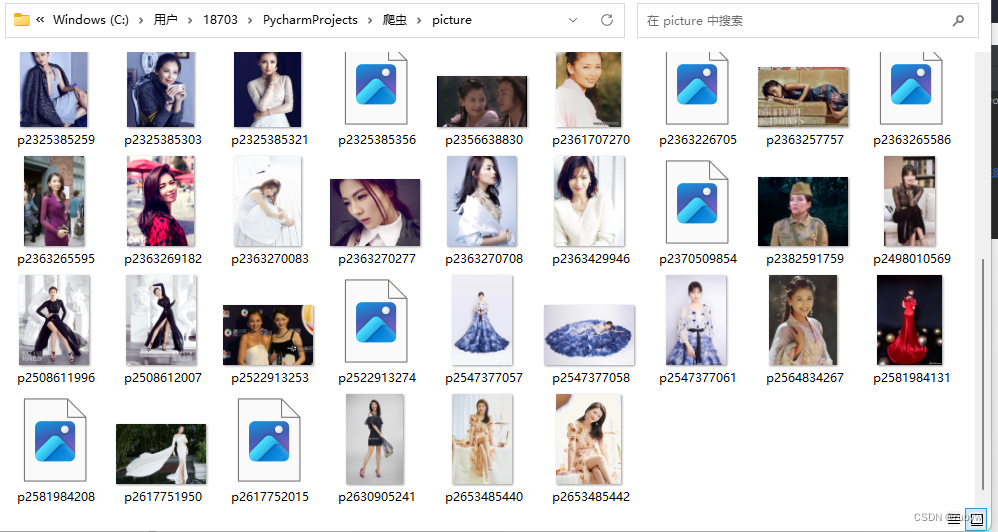
把爬取的图片全部放到新建的文件夹中存放