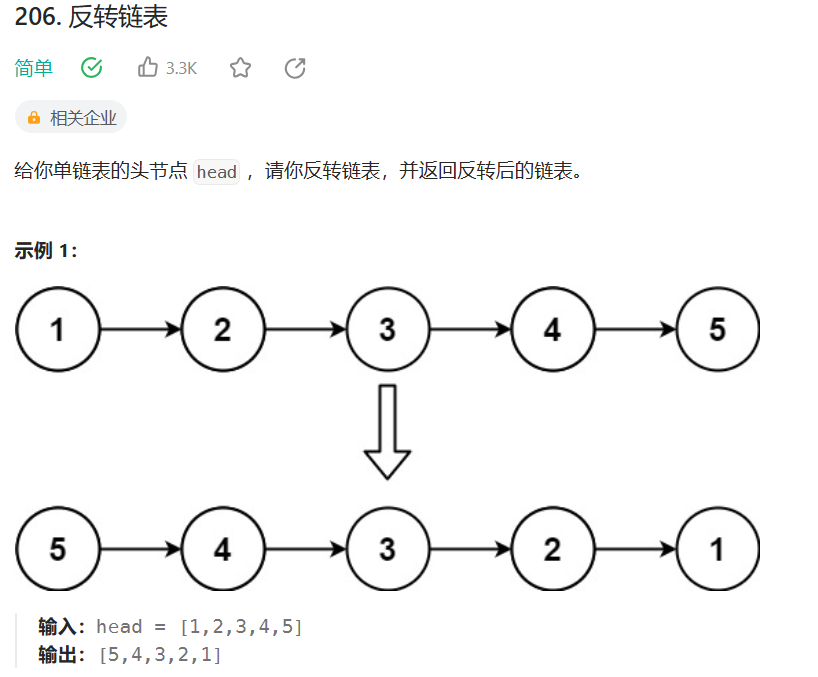
105. Construct Binary Tree from Preorder and Inorder Traversal105. Construct Binary Tree from Preorder and Inorder Traversal
题意:根据前序遍历和中序遍历来构造二叉树
我的思路
要用递归造树,要同时递归左子树和右子树,造树需要左边边界和右边边界
build函数有树的跟指针,前序的有左边边界和右边边界,中序的左边边界和右边边界
如果l>r return;因为是先序遍历,所以左子树是先序的第一个,先构造了;
不会做不会做
标答
上面标粗的部分是正确的,构造就在递归的时候构造,不用把树的根作为指针放到参数里面
之后就是搞清楚pl,pr和ir,il就可以了【做着做着居然做出来了!!】
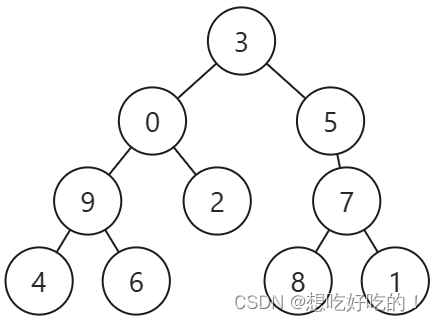
例子:前序[3,0,9,4,6,2,5,7,8,1]
中序[4,9,6,0,2,3,5,8,7,1]
显而易见,左子树的pl是pl+1;左子树的il是il;左子树的ir是pos-1;
显而易见,右子树的pr=pr;右子树的il是pos+1;右子树的ir是ir
左子树是[ il,pos-1]的长度,所以pr=pl+1+pos-1-li=pl+pos-li;
右子树是[pos+1,ir]的长度,所以pl=左子树的pr+1=pl+pos-li+1
=pr-(ir-pos-1)=pr-ir+pos+1
代码 Runtime 30 ms Beats 34.48% Memory 25.9 MB Beats 73.83%
class Solution {
public:
TreeNode*build(vector<int>& preorder, vector<int>& inorder,int pl,int pr,int il,int ir){
if(il>ir)return NULL;
TreeNode *root=new TreeNode(preorder[pl]);
int pos;//为了找到il和ir
for(int i=il;i<=ir;i++)
if(inorder[i]==preorder[pl]){pos=i;break;}
root->left=build(preorder,inorder,pl+1,pl+pos-il,il,pos-1);
root->right=build(preorder,inorder,pr-ir+pos+1,pr,pos+1,ir);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n=preorder.size()-1;
TreeNode *root=NULL;
return build(preorder,inorder,0,n,0,n);
}
};标答优化 map
题目中有这样一条preorder and inorder consist of unique values.
所以可以用map来减少中序查找的时间消耗
传递参数的时候可以省略前序序号的传递,或者说只需要一个pl就可以了,传递的时候函数参数为il和ir
代码 Runtime13 ms Beats 79.95% Memory26.3 MB Beats 58.43%
class Solution {
public:
unordered_map<int,int>mp;
int pre=0;
TreeNode* build(vector<int>& preorder,int l,int r){
if (l>r) return NULL;
int mid=preorder[pre++];
TreeNode * root=new TreeNode(mid);
int pos=mp[mid];
root->left=build(preorder,l,pos-1);
root->right=build(preorder,pos+1,r);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n=inorder.size()-1;
for(int i=0;i<=n;i++) mp[inorder[i]]=i;//中序序列的这个数字排在第几个序号
return build(preorder,0,n);
}
};114. Flatten Binary Tree to Linked List
题意:
我的思路
先序索引,但我不会写;看了答案后至少有一点是对的,就是先递归,两个递归后在做事情
标答 递归
分为4种情况:1只有左边的,2只有右边的,3都没有的,4都有的
首先是第一种情况,假设现在root是1这个结点【56当它不存在】,234按照道理都已经建好了;只需要root->right=root->left; root->left=NULL;就可以了
第二种情况,假设节点是5,6按道理都建好了,其实5放着不动就好了
第三种情况就先不管
第四种情况,假设节点是2,34按道理都建好了,首先要把右子树空出来,right=root->right; root->right=root->left;root->left=NULL; 这时候还需要处理原来在右子树上的结点。因为原先左子树上的都是处理好的链表,所以只要找到原先左子树上的最后一个节点,把这最后一个节点连上去就可以了
代码 递归 Runtime 5 ms Beats 59.24% Memory 12.7 MB Beats 30.44%
class Solution {
public:
void flatten(TreeNode* root) {
if(root==NULL)return;
flatten(root->left);
flatten(root->right);
if(root->left){
TreeNode* right=root->right;
root->right=root->left;
root->left=NULL;
while(root->right)root=root->right;
root->right=right;
}
}
};标答 循环
首先如果root是空的话就返回;如果当前指针有左指针,先将pre指向左指针指向的位置;pre来到左指正的最右边,左指针的最右边指向当前指针的右边,再把原来右指针指向左指针的位置,左指针置为空;如下图所示,总之就是一点一点挪过去

代码 Runtime 3 ms Beats 88.18% Memory12.7 MB Beats 61.31%
class Solution {
public:
void flatten(TreeNode* root) {
if(root == NULL) return;
TreeNode *curr = root;
while(curr){
if(curr->left){
TreeNode *pre = curr->left;
while(pre->right) pre = pre->right;
pre->right = curr->right;
curr->right = curr->left;
curr->left = NULL;
}
curr = curr->right;
}
}
};标答 优化
注意这里是先递归右边,相当于(我一开始想的)先到右边的尽头,之后那前一个来接上的想法【最后没写出来】
注意这里递归的顺序,学着点!!
先递归到6,这时6的右指针是prev也就是空,左指针是空,prev是6
接下来是5,5的右指针是prev也就是6,左指针是空,prev是5
接下来是4,4的右指针是prev也就是5,左指针是空,prev是4
接下来是3,3的右指针是prev也就是4,左指针是空,prev是3
……
于是就完成了
代码 Runtime 0 ms Beats 100% Memory12.7 MB Beats 30.44%
class Solution {
public:
TreeNode* prev = NULL;
void flatten(TreeNode* root) {
if(!root) return;
flatten(root->right);
flatten(root->left);
root->right = prev;
root->left = NULL;
prev = root;
}
};118. Pascal's Triangle
题意:
我的思路
用动态规划(?),第x层有x个数字,dp[x][0]=1,dp[x][x-1]=0,dp[x][i]=dp[x-1][i-1]+dp[x-1][i]
代码 Runtime 4 ms Beats 29.4% Memory 6.9 MB Beats 18.4%
class Solution {
public:
vector<vector<int>> generate(int num) {
if(num==1)return {{1}};
if(num==2)return {{1},{1,1}};
vector<vector<int>> ans={{1},{1,1}};int temp=0;
for(int x=3;x<=num;x++){//一共num层
vector<int> sol;sol.push_back(1);
for(int i=1;i<x-1;i++){
temp=ans[x-2][i-1]+ans[x-2][i];
sol.push_back(temp);
}
sol.push_back(1);
ans.push_back(sol);
}
return ans;
}
};标答 优化
简而言之,就是用一维数组代替了二维数组,实现了相加提速
代码 Runtime 0 ms Beats 100% Memory 6.7 MB Beats 78.55%
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>>ans;
ans.push_back({1});
for(int i=0;i<numRows-1;i++){
vector<int> tem=ans.back();//{1}
vector<int> v(tem.size()+1);//开空间
for(int i=0;i<=tem.size();i++){
if(i==0){
v[i]=tem[0];continue;//1
}
if(i==tem.size())//1
v[i]=tem[tem.size()-1];
else
v[i]=tem[i-1]+tem[i];
}
ans.push_back(v);
}
return ans;
}
};121. Best Time to Buy and Sell Stock
题意:给出每天袜子的价格,只能选一天买袜子,只能选一天卖袜子,求利润最大
我的思路
用vector或者deque模拟单调栈?当要弹出一个大的数字的时候,就求一下栈尾和栈顶的的差,或者双指针也可以
代码 双指针 Runtime 66 ms Beats 99.76% Memory 93.4 MB Beats 11.73%
不加取消同步在66.7%左右,感觉都差不多,都是找个最小的,然后当前的减去现在最小的,最后在"当前的"里面找最大的
class Solution {
public:
int maxProfit(vector<int>& p) {
int l=0,r=0,n=p.size();int profit=0;
for(r=1;r<n;r++){
profit=max(profit,p[r-1]-p[l]);
if(p[r]<p[l])l=r;
}
profit=max(profit,p[r-1]-p[l]);
return profit;
}
};124. Binary Tree Maximum Path Sum
题意:树上路径和最大
我的思路
学过,好像有两种做法?一种dp一种dfs大概?
下面是用dfs做的:
那就每个结点都遍历一遍,每个节点的数字就是 sum=左边的和加上右边的和,ans=max(ans, sum);返回的时候返回两条子树和最大的那个,如果和是负的那就返回0
代码 Runtime 17 ms Beats 85.76% Memory27.7 MB Beats 52.24%
class Solution {
public:
int ans=-9999;
int maxP(TreeNode* root) {
int l=0;int r=0;int sum=0;
if(root->left!=NULL) l=maxP(root->left);
if(root->right!=NULL) r=maxP(root->right);
sum=l+r+(root->val);
ans=max(ans,sum);
return max(max(l,r)+(root->val),0);
}
int maxPathSum(TreeNode* root) {
maxP(root);
return ans;
}
};128. Longest Consecutive Sequence
题意:输出最长连续序列的长度
我的思路
初步设想快排+遍历,但是他会有相同的数字;那就用map
代码 Runtime 147 ms Beats 60.73% Memory 68.8 MB Beats 26.14%
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
ios::sync_with_stdio(false);cin.tie(0);
if(nums.size()==0)return 0;
map<long long,int>mp;int maxx=1;
long long pre=-9999999999;int cnt=0;
for(int i=0;i<nums.size();i++)
mp[nums[i]]++;
for(auto q:mp){
if(cnt!=0&&q.first!=pre+1){
maxx=max(maxx,cnt); cnt=0;
}
pre=q.first;
cnt++;
}
maxx=max(maxx,cnt);
return maxx;
}
};标答 排序
我的2n比不上nlogn,好吧;其实和初步设想差不多,就是相同的数字的时候不加就可以了
首先先排序,之后
代码 Runtime 35 ms Beats 99.79% Memory43.2 MB Beats 99.65%
class Solution {
public:
int longestConsecutive(vector<int>& nums){
ios_base::sync_with_stdio(false);cin.tie(NULL);
int n=nums.size();
if(n==0)return 0;
int maxx=0;int cnt=1;
sort(nums.begin(),nums.end());
for(int i=1;i<n;i++){
if(nums[i]-nums[i-1]==1)cnt++;
else if(nums[i]!=nums[i-1]){
maxx=max(maxx,cnt);cnt=1;
}
}
maxx=max(maxx,cnt);
return maxx;
}
};131. Palindrome Partitioning
题意:给一个字符串,返回所有是回文串的子串
我的思路
初步设想的遍历+回文串判断,但是这个返回的答案很dfs
那就试试用dfs做吧;不会做不会做
但是瞄了一眼标答 还是自己写了
代码 Runtime 75 ms Beats 94.39% Memory 49.3 MB Beats 82.17%
class Solution {
public:
bool jud(string s){
int n=s.size();
for(int i=0;i<n/2;i++){
if(s[i]!=s[n-i-1])return 0;
}
return 1;
}
void dfs(vector<vector<string>> &result,vector<string> &sol,int id,string &s){
if(id==s.size()){
result.push_back(sol);return;
}
for(int len=1;len+id<=s.size();len++){
string temp=s.substr(id,len);
if(jud(temp)){
sol.push_back(temp);
dfs(result,sol,id+len,s);
sol.pop_back();
}
}
}
vector<vector<string>> partition(string s) {
if(s.size()==0)return {{}};
vector<vector<string>> result;
vector<string> sol;
dfs(result,sol,0,s);
return result;
}
};136. Single Number
题意:给一个数组,找出只出现一次的数字
我的思路
用map存一遍,在找一遍
代码 Runtime17 ms Beats 59.59% Memory20.1 MB Beats 9.40%
class Solution {
public:
int singleNumber(vector<int>& nums) {
ios::sync_with_stdio(false);cin.tie(0);
unordered_map<int,int>mp;
for(int i=0;i<nums.size();i++)
mp[nums[i]]++;
for(auto q:mp)
if(q.second==1)return q.first;
return 0;
}
};标答 位运算
首先是异或算法的一些规律

从上图就可以看到,如果是两个一样的数字,那么它就会变成0;如果是不一样的数字,那么它就会留下来
代码 Runtime11 ms Beats 92.56% Memory 17 MB Beats 33.22%
class Solution {
public:
int singleNumber(vector<int>& nums) {
int x = 0;
for(int i=0; i<nums.size(); i++)
x=x^nums[i];
return x;
}
};138. Copy List with Random Pointer
题意:复制一个一摸一样的链表
我的思路
只会链表的顺序复制,如果是随机的,那要有个map,左边是原地址,右边是现地址;
代码 Runtime 3 ms Beats 97.9% Memory11.3 MB Beats 32.3%
class Solution {
public:
Node* copyRandomList(Node* head) {
unordered_map<Node*,Node*>mp;
if(head==NULL)return NULL;
Node* root=new Node(head->val);
Node* q=root;Node* cr=NULL;mp[head]=root;
for(Node* p=head->next;p!=NULL;p=p->next){
cr=new Node(p->val);
q->next=cr;q=q->next;
mp[p]=cr;
}
q=root;
for(Node* p=head;p!=NULL;p=p->next){
Node* qv=p->random;
q->random=mp[qv];
q=q->next;
}
return root;
}
};标答 不用map的做法
如果head是空,返回空;
copy_merge函数复制顺序的链表,其中curr是原链表的当前节点,next是原链表的下一个节点,copy是专门创造新结点的指针,curr指向新生的结点,copy指向原来下一个节点;其返回结果如图所示

handle_random函数如下如所示,简单来说就是复制的结点就是原节点的next,所以容易能找到;这样就可以原来的节点的random指向哪个,复制的节点就指向那个节点的next
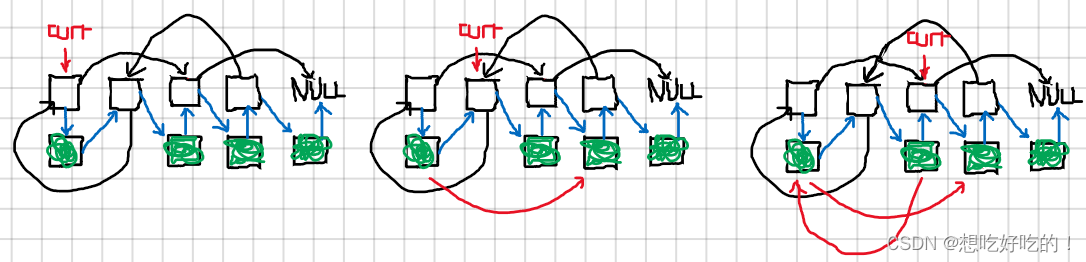
最后detach函数把复制的结点全部都串在一起,原来的结点也要指回原来的结点
代码 Runtime 7 ms Beats 73.26% Memory 11.2 MB Beats 87.73%
class Solution {
public:
void copy_merge(Node* head){
Node* curr=head; Node* next=head->next;
while(curr!=NULL){
Node* copy=new Node(curr->val);
curr->next=copy; copy->next=next;
curr=next;
if(next!=NULL) next=next->next;
}
}
void handle_random(Node* head){
Node* curr=head;
while(curr!=NULL){
if(curr->random!=NULL) curr->next->random=curr->random->next;
curr=curr->next->next;
}
}
Node* detach(Node* head){
Node* curr=head; Node* dummy=new Node(-1); Node* tail=dummy;
while(curr!=NULL){
tail->next=curr->next; tail=tail->next;
curr->next=tail->next; curr=curr->next;
}
return dummy->next;
}
Node* copyRandomList(Node* head) {
if(head==NULL) return head;
copy_merge(head); handle_random(head);
return detach(head);
}
};139. Word Break
题意:给你字典,问能不能用字典里的词拼接成字符串s
我的思路
用dfs吗?但是dfs先分成所有可能性,再用字典判断也太费时间了吧
不会做,看看答案