概率论
数理统计(概念&参数估计)
文章目录
- 3.8 假设检验
- 3.8.1 提出假设
- 3.8.2 构建检验统计量
- 对均值检验
- 对方差检验
- 3.8.3 根据显著性水平确定拒绝域临界值
- 显著性水平
- 拒绝域
- 3.8.4 计算统计量,确定P值
- 3.8.5 根据临界值法决定是否拒绝原假设
- 3.8.6 三种检验
- Z检验
- T检验
- 单个样本T检验
- 非独立两样本T检验
- 两独立样本T检验
- T检验应用条件
- 卡方检验
- 3.8.7 假设检验的两类错误
- 3.8.8 假设检验在监督学习中的作用
- 3.9 数据处理
- 3.9.1 核函数
- 适用情况
- 分类
- 线性核函数
- 多项式核函数
- 高斯核函数
- 高斯核函数
- 高斯核函数可将特征映射为无穷维
- 核函数计算问题
- 3.9.2 熵
- 熵值大小意义
- 熵可用作分类效果指标
- 3.9.3 激活函数
- sigmod函数
3.8 假设检验
假设:对总体参数的数值表示 = , < , > =,<,> =,<,>
假设检验:用统计数据判断命题真伪的方式。
假设成立:模型参数是否在统计学误差允许的范围内
小概率事件原理 :在数理统计中,发生概率小于 1% 的事件被称为小概率事件,在单次实验中被认为是不可能发生的
在一次实验中小概率事件一旦发生,就有理由拒绝原假设
- “小概率事件”的概率越小,否定原假设 H 0 H_0 H0 就越有说服力
3.8.1 提出假设
原假设:对总体参数做一个尝试性的假设,该假设被称为原假设,记为 H 0 H_0 H0 ,待推翻的
备择假设:与 H 0 H_0 H0 完全相反的假设
在统计学里,命题不能被证明是正确的,只能证明其否命题是错误的
假设检验的过程就是根据样本数据来对这两个对立的假设进行检验的过程。一般来说,我们将想要推翻的假设作为原假设,而将想要检验证实的问题作为备择假设。
3.8.2 构建检验统计量
对均值检验
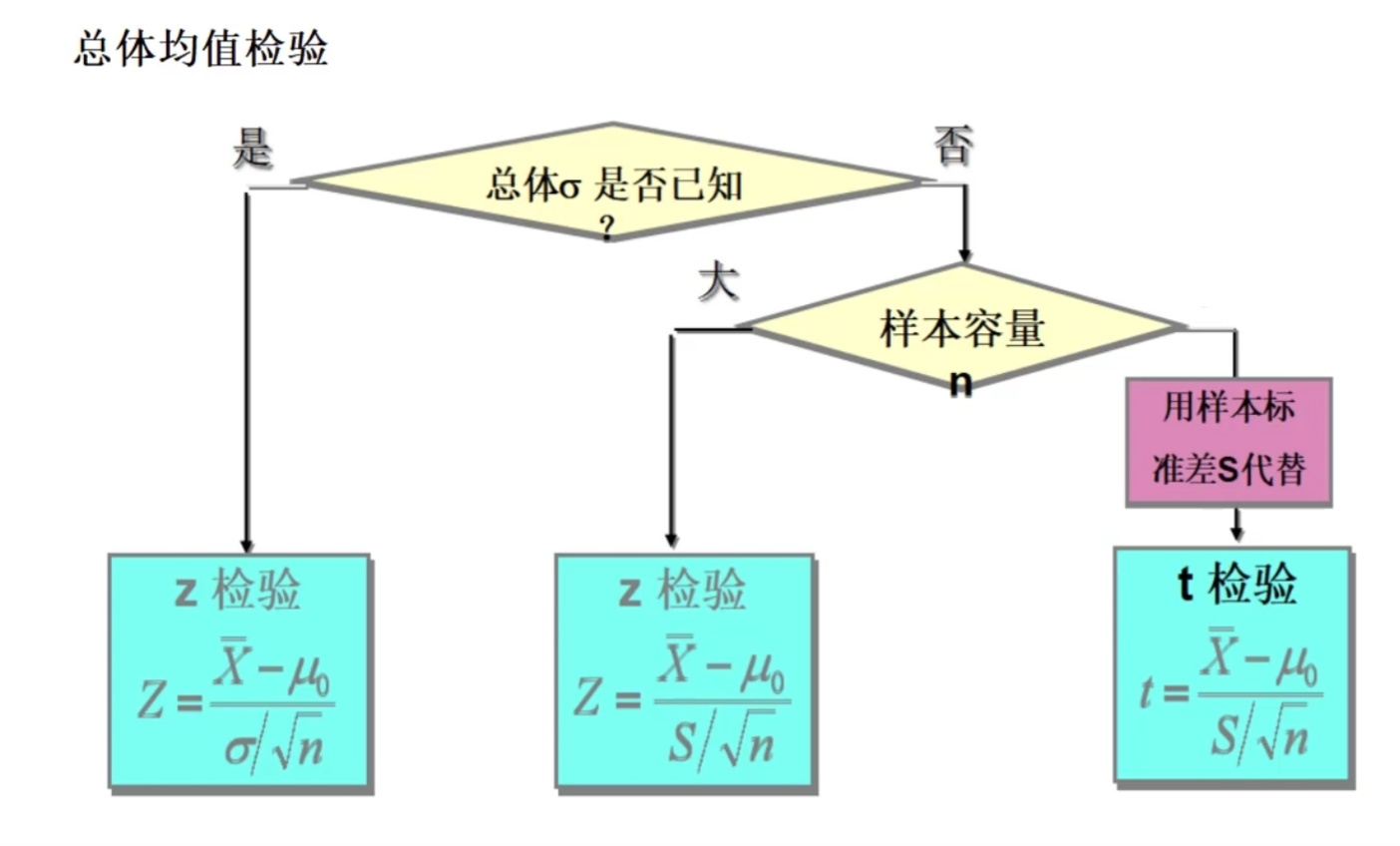
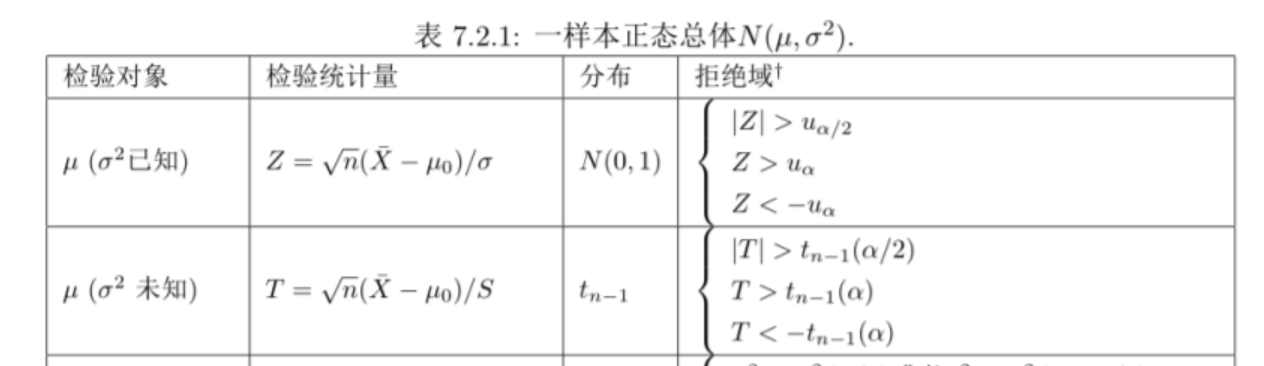
对方差检验

3.8.3 根据显著性水平确定拒绝域临界值
显著性水平
假定原假设不发生 P ( H 1 ) = α ( 0 < α < 1 ) P(H_1)=\alpha(0<\alpha<1) P(H1)=α(0<α<1) 为小概率事件,称为 检验的显著性水平
它代表了:当原假设为真时,检验统计量落在拒绝域,从而拒绝原假设的概率,也叫做第一类错误(弃真)
- 原假设为真,拒绝原假设的概率
- 估计总体参数在某一区间,可能犯错的概率
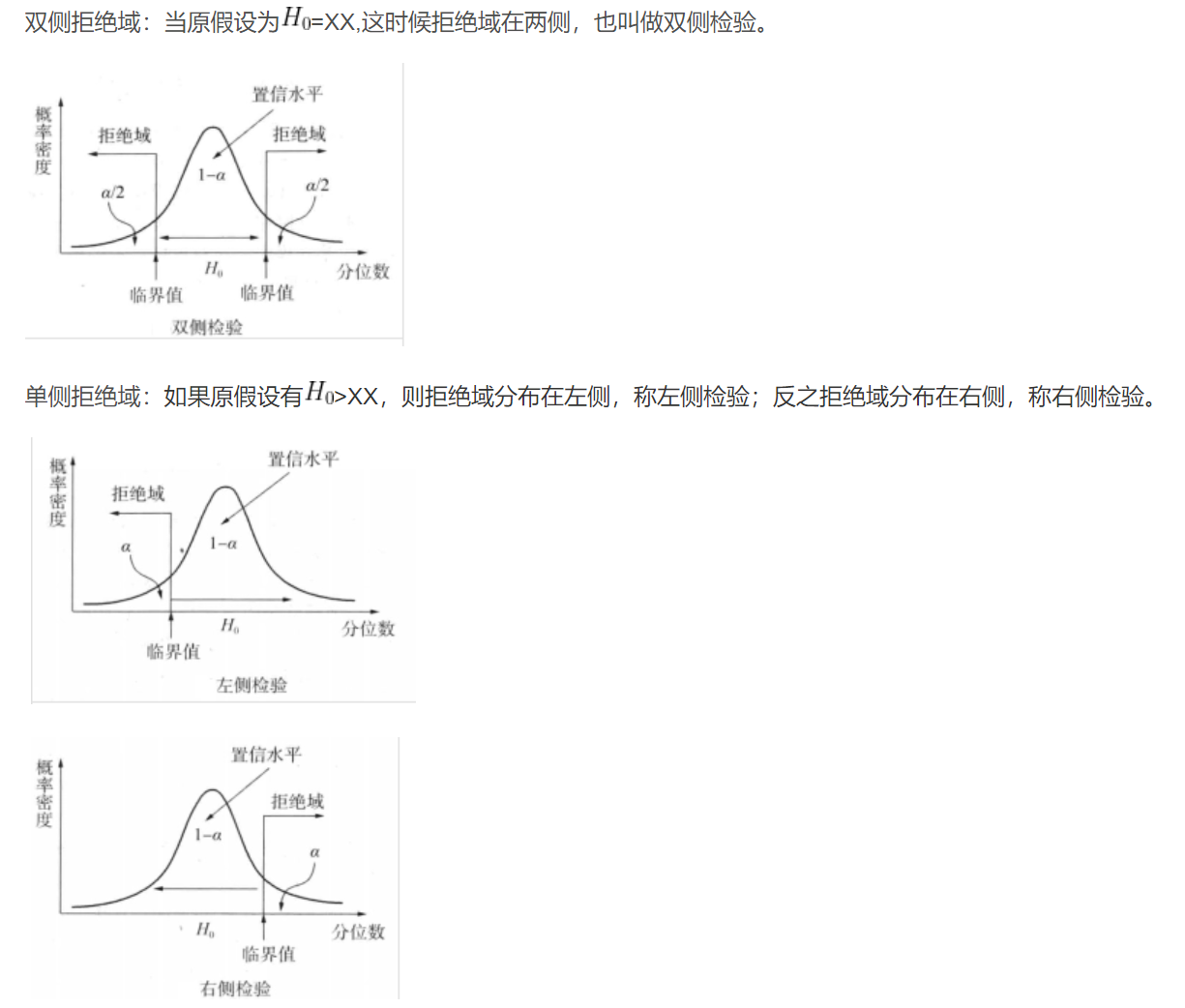
拒绝域
拒绝域面积为小概率事件概率 α \alpha α ,称为 显著性水平
- 接收域,接收域的面积为原假设发生的概率 P ( H 0 ) = 1 − α P(H_0)=1-\alpha P(H0)=1−α
检验统计量落在拒绝域中,则拒绝原假设
- 临界值 是拒绝域的边界,即使拒绝域面积为 α \alpha α (显著性水平)的值
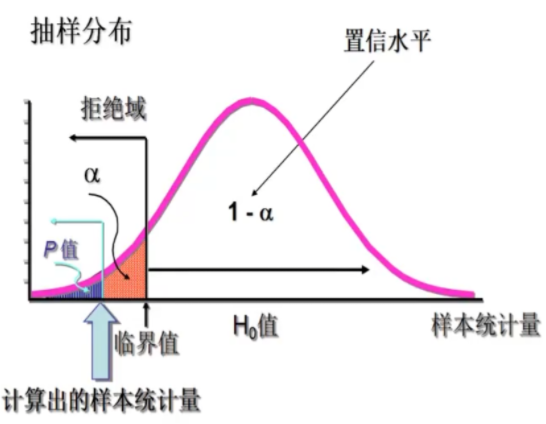
3.8.4 计算统计量,确定P值
P值 是一个概率值,如果假设为真,P值是抽样分布中大于或小于样本统计量的概率
P值越小, H 0 H_0 H0 越不可能为正确——拒绝程度越大
-
左侧检验:P值为小于检验统计量的部分
-
右侧检验:P值为大于检验统计量的部分
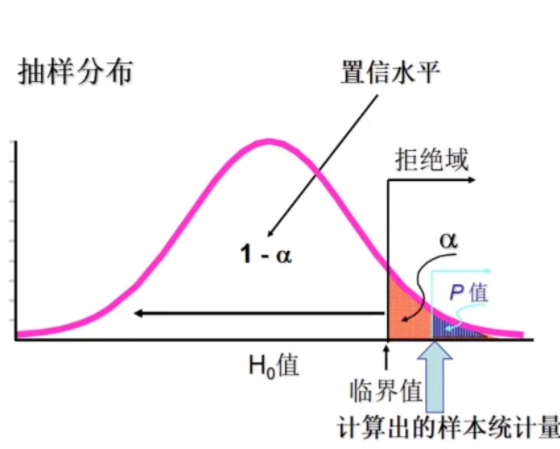
3.8.5 根据临界值法决定是否拒绝原假设
在双侧检验中,如果检验统计量 z ≤ − z α 2 z\le -z_\frac{\alpha}{2} z≤−z2α 或者 z ≥ z α 2 z\ge z_\frac{\alpha}{2} z≥z2α ,则拒绝原假设
在左侧检验中,如果检验统计量 z ≤ − z α z\le -z_\alpha z≤−zα ,则拒绝原假设
在右侧检验中,如果检验统计量 z ≥ z α z\ge z_\alpha z≥zα ,则拒绝原假设
在判断错的概率为 α \alpha α 时,认为原假设是不成立的
3.8.6 三种检验
Z检验
-
检验一个样本均值与已知的总体样本平均数(统计数据)是否有显著差异
Z = X ‾ − μ σ X ‾ = X ‾ − μ σ / n Z=\frac{\overline{X}-\mu}{\sigma_{\overline{X}}}=\frac{\overline{X}-\mu}{\sigma/ \sqrt{n}} Z=σXX−μ=σ/nX−μ
-
检验来自两组样本的均值是否有差异,进而两样本总体是否有差异
Z = ∣ X ‾ 1 − X ‾ 2 ∣ S x ‾ 1 − x ‾ 2 = ∣ X ‾ 1 − X ‾ 2 ∣ s 1 2 / n 1 + s 2 2 / n 2 Z=\frac{\vert \overline{X}_1-\overline{X}_2 \vert}{S_{\overline{x}_1-\overline{x}_2}}=\frac{\vert \overline{X}_1-\overline{X}_2\vert}{\sqrt{s_1^2/n_1+s^2_2/n_2}} Z=Sx1−x2∣X1−X2∣=s12/n1+s22/n2∣X1−X2∣
检验原理
-
标准正态分布理论
f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 → 标准化 t = ( x − μ ) σ f N ( x ) = 1 2 π σ e − t 2 2 f(x)=\frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\xrightarrow{标准化t=\frac{(x-\mu)}{\sigma}}f_N(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{t^2}{2}} f(x)=2πσ1e−2σ2(x−μ)2标准化t=σ(x−μ)fN(x)=2πσ1e−2t2
由于 σ \sigma σ 已知,故用方差代替标准差 s = σ n s=\frac{\sigma}{\sqrt{n}} s=nσ
-
当总体标准差已知,样本量较大时,用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数的差异是否显著
常用临界值
双侧: Z 0.05 / 2 = 1.96 , Z 0.01 / 2 = 2.58 Z_{0.05/2}=1.96,Z_{0.01/2}=2.58 Z0.05/2=1.96,Z0.01/2=2.58
单侧: Z 0.05 = 1.645 , Z 0.01 = 2.33 Z_{0.05}=1.645,Z_{0.01}=2.33 Z0.05=1.645,Z0.01=2.33
eg1:
假设正常人与高血压患者胆固醇含量资料如下,试比较两组血清胆固醇含量是否有差别
正常人组: n 1 = 506 , x 1 ‾ = 180.6 , s 1 = 34.2 n_1=506,\overline{x_1}=180.6,s_1=34.2 n1=506,x1=180.6,s1=34.2
高血压组:
n
2
=
142
,
x
2
‾
=
223.6
,
s
2
=
45.8
n_2=142,\overline{x_2}=223.6,s_2=45.8
n2=142,x2=223.6,s2=45.8
建立假设,确定显著性水平
H
0
:
μ
1
=
μ
2
H
1
:
μ
1
≠
μ
2
α
=
0.05
计算统计量
Z
=
∣
X
1
‾
−
X
2
‾
∣
s
1
2
/
n
1
+
s
2
2
/
n
2
=
∣
180.6
−
223.6
∣
34.
2
2
/
506
+
45.
8
2
/
142
=
10.4
确定临界值
查表
1
−
α
2
=
1
−
0.025
=
0.975
⇒
z
α
2
=
z
1
−
α
2
=
1.96
决策
z
>
z
1
−
α
2
,故拒绝
H
0
,认为有差异,接受
H
1
,认为正常人与高血压患者的胆固醇含量有差别
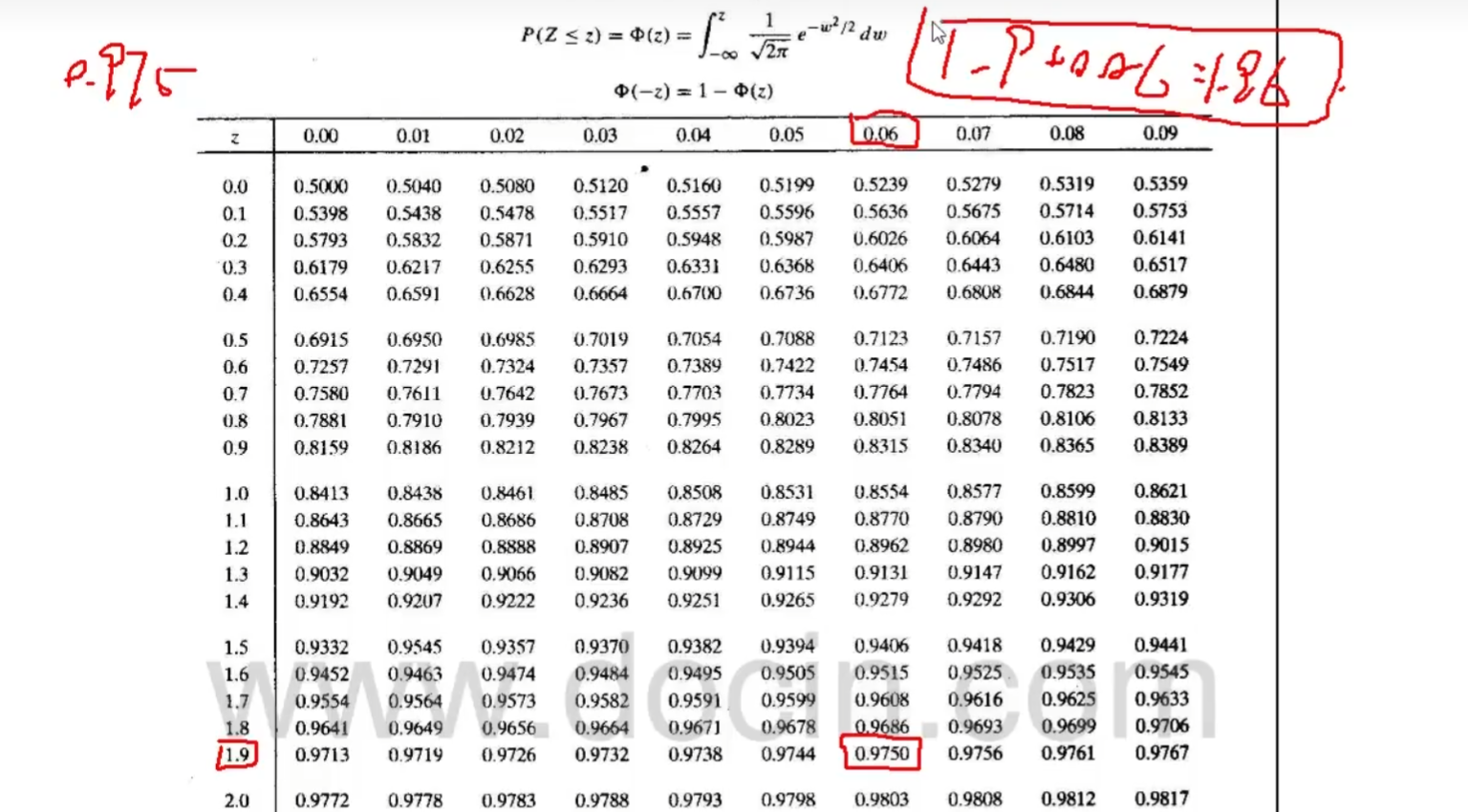
\begin{array}{r|lll} 建立假设,确定显著性水平&H_0:\mu_1=\mu_2\qquad H_1:\mu_1\neq \mu_2\qquad \alpha=0.05\\ 计算统计量&Z=\frac{\vert\overline{X_1}-\overline{X_2}\vert}{\sqrt{s_1^2/n_1+s_2^2/n_2}}=\frac{\vert180.6-223.6\vert}{\sqrt{34.2^2/506+45.8^2/142}}=10.4\\ 确定临界值&查表 1-\frac{\alpha}{2}=1-0.025=0.975\Rightarrow z_{\frac{\alpha}{2}}=z_{1-\frac{\alpha}{2}}=1.96\\ 决策&z>z_{1-\frac{\alpha}{2}},故拒绝H_0,认为有差异,接受 H_1,认为正常人与高血压患者的胆固醇含量有差别 \end{array}
建立假设,确定显著性水平计算统计量确定临界值决策H0:μ1=μ2H1:μ1=μ2α=0.05Z=s12/n1+s22/n2∣X1−X2∣=34.22/506+45.82/142∣180.6−223.6∣=10.4查表1−2α=1−0.025=0.975⇒z2α=z1−2α=1.96z>z1−2α,故拒绝H0,认为有差异,接受H1,认为正常人与高血压患者的胆固醇含量有差别
eg2:


T检验
-
单个样本T检验:比较一组数据均值与一个数值有无差异
-
配对样本均值检验(非独立两样本数均数T检验):一组数据在处理前后均值是否有差异
-
两独立样本均值T检验:两组数据均值有无差异
单个样本T检验
适用于样本均值 μ \mu μ 与已知总体均数 μ 0 \mu_0 μ0 的比较,目的是检验样本均数 μ \mu μ 与总体均数 μ 0 \mu_0 μ0 有差别
- 已知总体均数 μ 0 \mu_0 μ0 一般为标准值、理论值或经大量观察得到的较稳定的指标量
应用条件:总体标准 σ \sigma σ 未知的小样本资料,且服从正态分布

非独立两样本T检验
适用于 配对设计 计量资料均数的比较
配对设计 :将受试对象按某些特征相近的原则配成对子,每对中的两个个体随机地给予两种处理
检验原理
计算各对数据间的差值 Δ d \Delta d Δd ,将 Δ d \Delta d Δd 作为变量计算均数,假设 Δ d \Delta d Δd 服从总体均值 μ Δ d = 0 \mu_{\Delta d}=0 μΔd=0 的总体分布
t = Δ d ‾ − μ Δ d S Δ d ‾ = Δ d ‾ − 0 S Δ d ‾ = Δ d ‾ S Δ d / n t=\frac{\overline{\Delta d}-\mu_{\Delta d}}{S_{\overline{\Delta d}}}=\frac{\overline{\Delta d}-0}{S_{\overline{\Delta d}}}=\frac{\overline{\Delta d}}{S_{\Delta d}/\sqrt{n}} t=SΔdΔd−μΔd=SΔdΔd−0=SΔd/nΔd
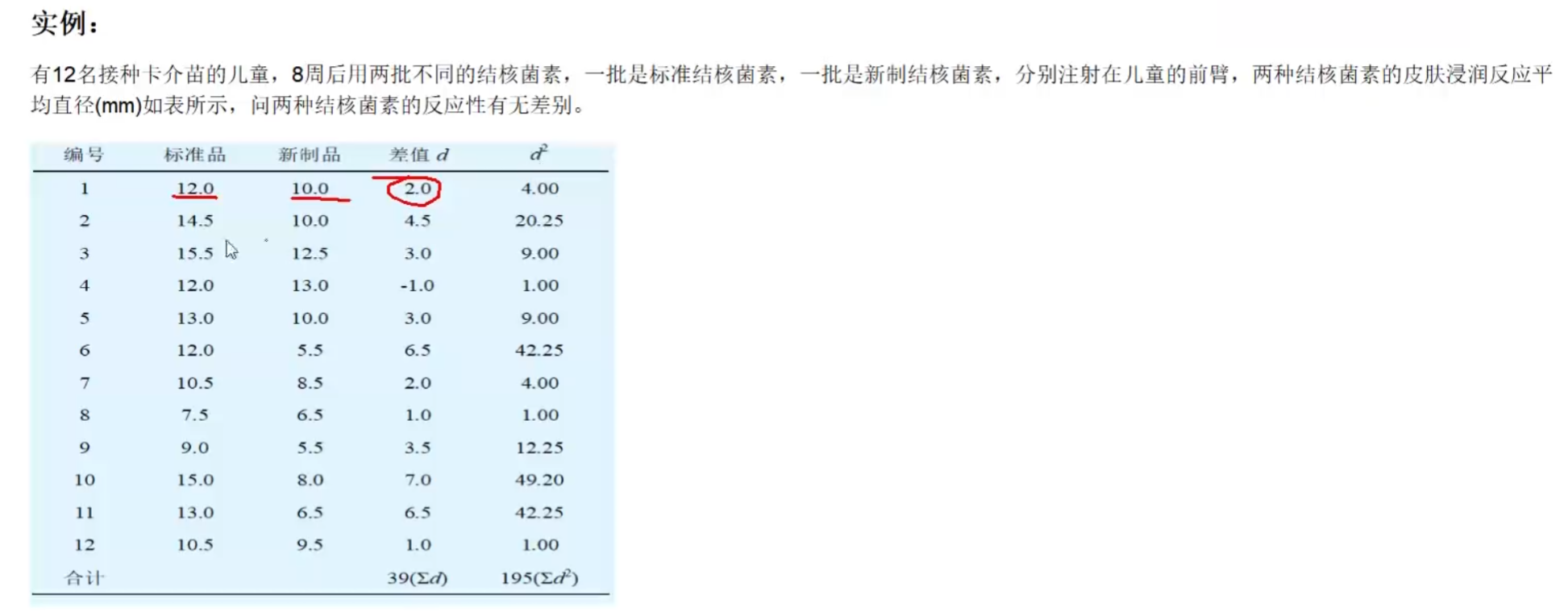
建立检验假设,确定显著性水准 H 0 : μ d = 0 H 1 : μ d ≠ 0 α = 0.05 计算检验统计量 ∑ d = 39 ∑ d 2 = 195 计算差值的标准差 S d = ∑ d 2 − ( ∑ d ) 2 n n − 1 = 195 − ( 39 ) 2 12 12 − 1 = 2.4909 计算差值的标准差 S d ‾ = S d n = 2.4909 3.464 = 0.7191 计算统计量 t = d ‾ S d ‾ = 3.25 0.7191 = 4.5195 确定临界值 自由度 v = n − 1 = 12 − 1 = 11 ,查表可得 t α 2 ( 11 ) = 2.201 决策 由于 t = 4.5195 > t α 2 ( 11 ) P < 0.05 ,拒绝 H 0 ,接收 H 1 ,结果有差别 \begin{array}{r|l} 建立检验假设,确定显著性水准&H_0:\mu_d=0\qquad H_1:\mu_d\neq 0\qquad \alpha=0.05\\ 计算检验统计量&\sum d=39\qquad \sum d^2=195\\ 计算差值的标准差&S_d=\sqrt{\frac{\sum d^2-\frac{(\sum d)^2}{n}}{n-1}}=\sqrt{\frac{195-\frac{(39)^2}{12}}{12-1}}=2.4909\\ 计算差值的标准差&S_{\overline{d}}=\frac{S_d}{\sqrt{n}}=\frac{2.4909}{3.464}=0.7191\\ 计算统计量&t=\frac{\overline{d}}{S_{\overline{d}}}=\frac{3.25}{0.7191}=4.5195\\ 确定临界值&自由度 v=n-1=12-1=11,查表可得 t_{\frac{\alpha}{2}}(11)=2.201\\ 决策&由于 t=4.5195>t_{\frac{\alpha}{2}}(11)\\ &P<0.05,拒绝H_0,接收H_1,结果有差别 \end{array} 建立检验假设,确定显著性水准计算检验统计量计算差值的标准差计算差值的标准差计算统计量确定临界值决策H0:μd=0H1:μd=0α=0.05∑d=39∑d2=195Sd=n−1∑d2−n(∑d)2=12−1195−12(39)2=2.4909Sd=nSd=3.4642.4909=0.7191t=Sdd=0.71913.25=4.5195自由度v=n−1=12−1=11,查表可得t2α(11)=2.201由于t=4.5195>t2α(11)P<0.05,拒绝H0,接收H1,结果有差别
两独立样本T检验
用于验证两样本所来自的总体均值是否相等
要求
- 两样本总体均服从正态分布
- 方差齐性: σ 1 2 = σ 2 2 \sigma_1^2=\sigma_2^2 σ12=σ22
检验原理
假设两样本总体均值 μ 1 = μ 2 \mu_1=\mu_2 μ1=μ2
t = ∣ ( X 1 ‾ − X 2 ‾ ) − ( μ 1 − μ 2 ) ∣ S X 1 ‾ − X 2 ‾ = ∣ X 1 ‾ − X 2 ‾ ∣ S X 1 ‾ − X 2 ‾ t=\frac{\vert (\overline{X_1}-\overline{X_2})-(\mu_1-\mu_2)\vert}{S_{\overline{X_1}-\overline{X_2}}}=\frac{\vert \overline{X_1}-\overline{X_2}\vert}{S_{\overline{X_1}-\overline{X_2}}} t=SX1−X2∣(X1−X2)−(μ1−μ2)∣=SX1−X2∣X1−X2∣
S X 1 ‾ − X 2 ‾ = S c 2 ( 1 n 1 + 1 n 2 ) S_{\overline{X_1}-\overline{X_2}}=\sqrt{S_c^2(\frac{1}{n_1}+\frac{1}{n_2})} SX1−X2=Sc2(n11+n21)
S c 2 = ∑ x 1 2 − ( ∑ x 1 ) 2 n 1 + ∑ x 2 2 − ( ∑ x 2 ) 2 n 2 n 1 + n 2 − 2 S_c^2=\frac{\sum x_1^2-\frac{(\sum x_1)^2}{n_1}+\sum x_2^2-\frac{(\sum x_2)^2}{n_2}}{n_1+n_2-2} Sc2=n1+n2−2∑x12−n1(∑x1)2+∑x22−n2(∑x2)2
eg

建立检验假设,确定显著性水平 H 0 : μ 1 = μ 2 H 2 : μ 1 ≠ μ 2 α = 0.05 计算统计量 由原始数据: n 1 = 12 , ∑ X 1 = 182.5 , X 1 ‾ = ∑ X 1 n 1 = 15.21 , ∑ X 1 2 = 2953.43 n 2 = 13 , ∑ X 2 = 141 , X 1 ‾ = ∑ X 2 n 2 = 10.85 , ∑ X 2 2 = 1743.16 S c = 2953.43 − 182. 5 2 12 + 1743.16 − 14 1 2 13 12 + 13 − 2 = 17.03 S X 1 ‾ − X 2 ‾ = 17.03 ( 1 12 + 1 13 ) = 1.652 t = 15.21 − 10.85 1.652 = 2.639 确定临界值 v = n 1 + n 2 − 2 = 23 , 查 t 界值表, t 0.05 / 2 ( 23 ) = 2.069 决策 由于统计量 t > t 0.05 / 2 ( 23 ) ,按 α = 0.05 的水准,拒绝 H 0 ,接受 H 1 故可以认为两种疗法不同 \begin{array}{r|l} 建立检验假设,确定显著性水平&H_0:\mu_1=\mu_2\qquad H_2:\mu_1\neq \mu_2\qquad \alpha=0.05\\ 计算统计量&由原始数据:\\ &n_1=12,\sum X_1=182.5,\overline{X_1}=\frac{\sum X_1}{n_1}=15.21,\sum X_1^2=2953.43\\ &n_2=13,\sum X_2=141,\overline{X_1}=\frac{\sum X_2}{n_2}=10.85,\sum X_2^2=1743.16\\ &S_c=\frac{2953.43-\frac{182.5^2}{12}+1743.16-\frac{141^2}{13}}{12+13-2}=17.03\\ &S_{\overline{X_1}-\overline{X_2}}=\sqrt{17.03\left(\frac{1}{12}+\frac{1}{13}\right)}=1.652\\ &t=\frac{15.21-10.85}{1.652}=2.639\\ 确定临界值&v=n_1+n_2-2=23,查t界值表,t_{0.05/2}(23)=2.069\\ 决策&由于统计量t>t_{0.05/2}(23),按\alpha=0.05的水准,拒绝H_0,接受H_1\\ &故可以认为两种疗法不同 \end{array} 建立检验假设,确定显著性水平计算统计量确定临界值决策H0:μ1=μ2H2:μ1=μ2α=0.05由原始数据:n1=12,∑X1=182.5,X1=n1∑X1=15.21,∑X12=2953.43n2=13,∑X2=141,X1=n2∑X2=10.85,∑X22=1743.16Sc=12+13−22953.43−12182.52+1743.16−131412=17.03SX1−X2=17.03(121+131)=1.652t=1.65215.21−10.85=2.639v=n1+n2−2=23,查t界值表,t0.05/2(23)=2.069由于统计量t>t0.05/2(23),按α=0.05的水准,拒绝H0,接受H1故可以认为两种疗法不同
T检验应用条件
- 两种计量数据的小样本比较
- 样本对总体有较好代表性,对比组间均衡性——随机抽样和随机分组
- 样本总体来自正态分布总体,配对T检验要求差值服从正态分布
- 大样本时使用z检验
- 两独立样本均数t检验要求方差齐性——两组总体方差相等或两样本方差间无显著性
正态性检验
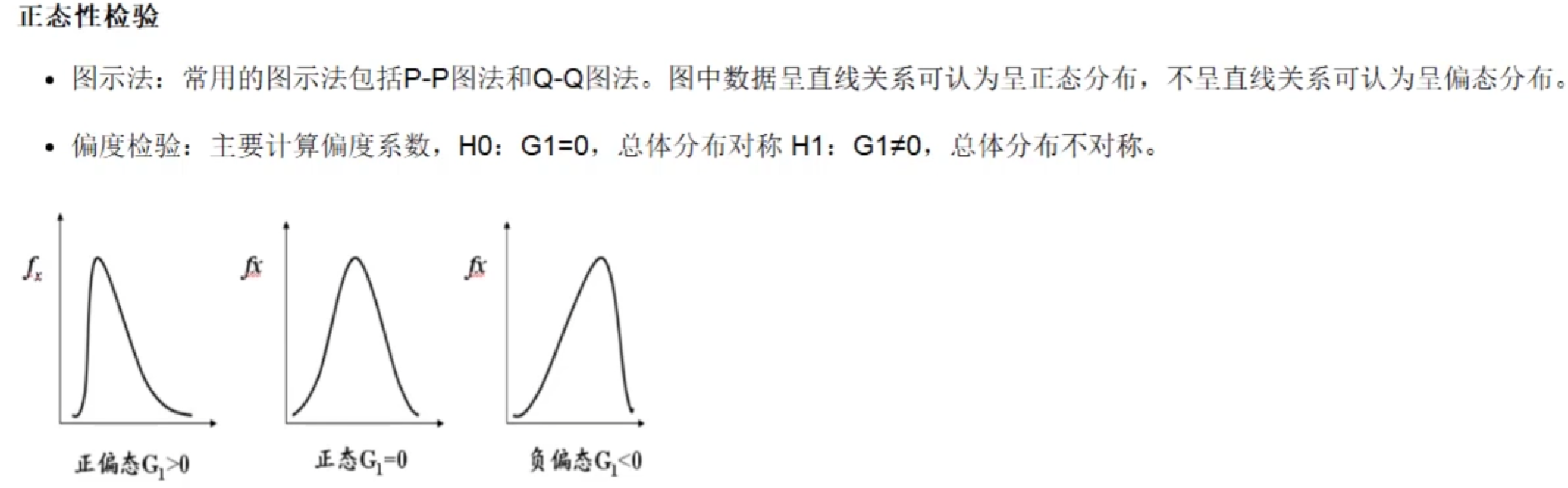
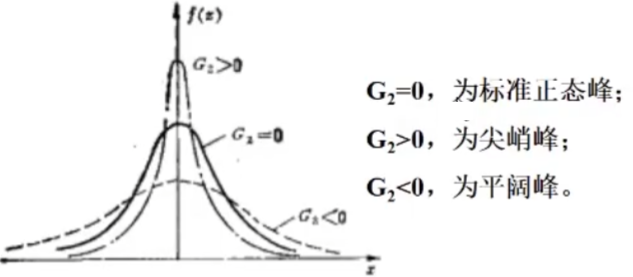
峰度检验
主要计算峰系数
H 0 : G 2 = 0 H_0:G_2=0 H0:G2=0 ,总体分布为正态峰
H 1 H_1 H1 : G 2 ≠ 0 G_2\neq 0 G2=0 ,总体分布不是正态峰
方差齐性检验
F = S 1 2 ( 较大 ) S 2 2 ( 较小 ) F=\frac{S_1^2(较大)}{S_2^2(较小)} F=S22(较小)S12(较大) , v 1 = n 1 − 1 v_1=n_1-1 v1=n1−1 , v 2 = n 2 − 1 v_2=n_2-1 v2=n2−1
式中, S 1 2 S_1^2 S12 为较大样本方差, S 2 2 S_2^2 S22 为较小样本方差,分子的自由度为 v 1 v_1 v1 ,分母的自由度为 v 2 v_2 v2 ,相应样本数分别为 n 1 , n 2 n_1,n_2 n1,n2 。
F F F 值为两个样本方差值比,如仅是抽样误差的影响,它一般不会离1太远。反之如果F值较大,两总体方差相同的可能性较小。
- F分布就是反映此概率的分布。
求得F值后,查F界值表得P值 。
-
F ≥ F α / 2 ( v 1 , v 2 ) F\ge F_{\alpha/2(v_1,v_2)} F≥Fα/2(v1,v2) ,则 P < α P<\alpha P<α ,拒绝 H 0 H_0 H0 ,可以认为两总体方差不等
-
若不拒绝 H 0 H_0 H0 ,可认为两总体方差相等
eg
X胸片上测得两组患者肺门横径右侧距 R 1 R_1 R1 值(cm),比较其方差是否齐性
肺癌患者: n 1 = 10 n_1=10 n1=10 , X 1 ‾ = 6.21 \overline{X_1}=6.21 X1=6.21 , S 1 = 1.79 S_1=1.79 S1=1.79
矽肺患者:
n
2
=
50
n_2=50
n2=50 ,
X
2
‾
=
4.34
\overline{X_2}=4.34
X2=4.34 ,
S
2
=
0.56
S_2=0.56
S2=0.56
建立假设
,
确定显著性水平
H
0
:
σ
1
2
=
σ
2
2
H
2
:
σ
1
2
≠
σ
2
2
计算
F
值
F
=
1.7
9
2
0.5
6
2
=
10.22
确定
P
值,决策
v
1
=
n
1
−
1
=
9
,
v
2
=
n
2
−
1
=
49
,
查
F
值表
,
F
0.1
/
2
(
9
,
49
)
=
2.8
得
P
<
0.05
=
α
,故拒绝
H
0
,接受
H
1
,
认为两总体方差不齐
\begin{array}{r|l} 建立假设,确定显著性水平&H_0:\sigma_1^2=\sigma_2^2\qquad H_2:\sigma_1^2\neq \sigma_2^2\\ 计算F值&F=\frac{1.79^2}{0.56^2}=10.22\\ 确定P值,决策&v_1=n_1-1=9,v_2=n_2-1=49,查F值表,F_{0.1/2}(9,49)=2.8\\ &得P<0.05=\alpha,故拒绝H_0,接受H_1,认为两总体方差不齐 \end{array}
建立假设,确定显著性水平计算F值确定P值,决策H0:σ12=σ22H2:σ12=σ22F=0.5621.792=10.22v1=n1−1=9,v2=n2−1=49,查F值表,F0.1/2(9,49)=2.8得P<0.05=α,故拒绝H0,接受H1,认为两总体方差不齐
卡方检验
-
用于检验两个率(构成比)之间差别是否有统计学意义
-
配对卡方检验检验配对计数数据的差异是否有统计学意义
基本思想
检验实际频数 A A A 和理论频数 T T T 的差别是否由抽样误差引起。
- 由样本率(样本构成比)推断总体率(构成比)
理论频数计算
一般的四格子表
B
1
B
2
合计
A
1
a
b
a
+
b
A
2
c
d
c
+
d
合计
a
+
c
b
+
d
n
=
a
+
b
+
c
+
d
\begin{array}{c|ccc} &B_1&B_2&合计\\ \hline A_1&a&b&a+b\\ A_2&c&d&c+d\\ \hline 合计&a+c&b+d&n=a+b+c+d \end{array}
A1A2合计B1aca+cB2bdb+d合计a+bc+dn=a+b+c+d
基本公式:
χ
2
=
∑
(
A
R
C
−
T
R
C
)
2
T
R
C
\chi^2=\sum\frac{(A_{RC}-T_{RC})^2}{T_{RC}}
χ2=∑TRC(ARC−TRC)2
A R C A_{RC} ARC 是位于 R R R 行 C C C 列交叉处的实际频数, T R C T_{RC} TRC 是位于 R R R 行 C C C 列交叉处的理论频数, ( A R C − T R C ) (A_{RC}-T_{RC}) (ARC−TRC) 反映实际频数与理论频数的差距,除以 T R C T_{RC} TRC 为的是考虑相对差距。所以, χ 2 \chi^2 χ2 值反映了实际频数与理论频数的吻合程度。
χ 2 = ∑ ( A − T ) 2 T = a − [ ( a + b ) ( a + c ) ] 2 n ( a + b ) ( a + c ) n + b − [ ( a + b ) ( b + d ) ] 2 n ( a + b ) ( b + d ) n + c − [ ( c + d ) ( a + c ) ] 2 n ( c + d ) ( a + c ) n + d − [ ( c + d ) ( b + d ) ] 2 n ( c + d ) ( b + d ) n = ( a d − b c ) 2 ⋅ n ( a + b ) ( c + d ) ( a + c ) ( b + d ) , v = 1 \chi^2=\sum\frac{(A-T)^2}{T}=\frac{a-\frac{\left[(a+b)(a+c)\right]^2}{n}}{\frac{(a+b)(a+c)}{n}}+\frac{b-\frac{\left[(a+b)(b+d)\right]^2}{n}}{\frac{(a+b)(b+d)}{n}}+\frac{c-\frac{\left[(c+d)(a+c)\right]^2}{n}}{\frac{(c+d)(a+c)}{n}}+\frac{d-\frac{\left[(c+d)(b+d)\right]^2}{n}}{\frac{(c+d)(b+d)}{n}}\\=\frac{(ad-bc)^2\cdot n}{(a+b)(c+d)(a+c)(b+d)},v=1 χ2=∑T(A−T)2=n(a+b)(a+c)a−n[(a+b)(a+c)]2+n(a+b)(b+d)b−n[(a+b)(b+d)]2+n(c+d)(a+c)c−n[(c+d)(a+c)]2+n(c+d)(b+d)d−n[(c+d)(b+d)]2=(a+b)(c+d)(a+c)(b+d)(ad−bc)2⋅n,v=1
若假设 H 0 : π 1 = π 2 H_0:\pi_1=\pi_2 H0:π1=π2 成立,四个格子的实际频数 A A A 与理论频数 T T T 相差不应该很大,即统计量 χ 2 \chi^2 χ2 不应该很大。如果 χ 2 \chi^2 χ2 很大,即对应的 P P P 值很小,若 P ≤ α P\le \alpha P≤α ,则反过来推断 A A A 与 T T T 相差很大,超出了抽样误差允许的范围,从而怀疑 H 0 H_0 H0 的正确性,进而拒绝 H 0 H_0 H0 ,接受 H 1 H_1 H1 ,即 π 1 ≠ π 2 \pi_1\neq \pi_2 π1=π2
χ 2 \chi^2 χ2 值的大小除了与实际频数和理论频数有关外,还与它们的行、列数有关,即自由度的大小
v = χ 2 自由度 = ( 行数 − 1 ) × ( 列数 − 1 ) v=\chi^2自由度=(行数-1)\times (列数-1) v=χ2自由度=(行数−1)×(列数−1)
eg
某药品检验所随机抽取574名成年人,研究抗生素的耐药性,问这两种人群的耐药率是否一致?
实际数据
用药史
不敏感
敏感
合计
耐药率
曾服该药
180
215
395
180
395
=
45.57
%
未服该药
73
106
179
73
179
=
40.78
%
合计
253
321
574
253
574
=
44.08
%
实际数据\\ \begin{array}{c|cccc}\\ 用药史&不敏感&敏感&合计&耐药率\\ \hline 曾服该药&180&215&395&\frac{180}{395}=45.57\%\\ 未服该药&73&106&179&\frac{73}{179}=40.78\%\\ \hline 合计&253&321&574&\frac{253}{574}=44.08\% \end{array}
实际数据用药史曾服该药未服该药合计不敏感18073253敏感215106321合计395179574耐药率395180=45.57%17973=40.78%574253=44.08%
理论耐药率为44.08%
理论数据
处理
有效
无效
合计
有效率
曾服该药
174.10
220.90
395
174.1
395
=
44.08
%
未服该药
78.90
100.10
179
78.9
179
=
44.08
%
合计
253
321
574
253
574
=
44.08
%
理论数据\\ \begin{array}{c|cccc}\\ 处理&有效&无效&合计&有效率\\ \hline 曾服该药&174.10&220.90&395&\frac{174.1}{395}=44.08\%\\ 未服该药&78.90&100.10&179&\frac{78.9}{179}=44.08\%\\ \hline 合计&253&321&574&\frac{253}{574}=44.08\% \end{array}
理论数据处理曾服该药未服该药合计有效174.1078.90253无效220.90100.10321合计395179574有效率395174.1=44.08%17978.9=44.08%574253=44.08%
-
建立假设,并确定显著性水平
H 0 H_0 H0 :两种人群对该抗生素的耐药性相同,即 π 1 = π 2 \pi_1=\pi_2 π1=π2 (两总体率相等)
H 1 H_1 H1 :两种人群对该抗生素的耐药性不同,即 π 1 ≠ π 2 \pi_1\neq \pi_2 π1=π2 (两总体率不相等)
α = 0.05 \alpha=0.05 α=0.05
-
计算统计量
χ 2 = ( 180 − 174.1 ) 2 174.10 + ( 215 − 220.9 ) 2 220.9 + ⋯ = 23.12 \chi^2=\frac{(180-174.1)^2}{174.10}+\frac{(215-220.9)^2}{220.9}+\cdots=23.12 χ2=174.10(180−174.1)2+220.9(215−220.9)2+⋯=23.12
-
决策
查表确定P值, P > 0.05 P>0.05 P>0.05 ,得出结论,按0.05水平,不拒绝 H 0 H_0 H0 ,可以认为两组人群对该抗生素的耐药率的差异无统计学意义
3.8.7 假设检验的两类错误
第一类错误(弃真错误)
- 原假设为真时拒绝原假设
- 第一类错误的概率为 α \alpha α
第二类错误(取伪错误)
- 原假设为假时接收原假设
- 第二类错误的概率为 β \beta β
第一类错误出现原因
只抽了一个样本,而个别的样本可能是特殊的。不管抽样多么符合科学抽样的要求,都有很多中构成样本的可能性,即会有很多样本平均数。由于小概率事件的出现,我们把本来真实的原假设拒绝了。
第二类错误出现的原因
统计检验的逻辑犯了从结论推断前提的错误。命题B是由命题A经演绎推论出来的( A → B A\rightarrow B A→B) 。如果A是真的,且我们从A到B的演绎推论如果是正确的,那么B可能是真实的。
相反,如果B是真实的,就不能得出A必定是真实的结论。这就是出现第二类错误的原因。
3.8.8 假设检验在监督学习中的作用
监督学习算法的任务就是在假设空间中搜索能够针对特定问题做出良好预测的假设。
- 学习器通过对测试数据集的学习得到具有普适性的模型,这个模型适用于不属于测试集的新样本的能力被称为泛化能力
- 泛化能力越强,学习器越好
假设检验的作用在于根据学习器在测试集上的性能推断其泛化能力的强弱,并确定所得到的结论的精确程度。
假设检验中的假设是对学习器的泛化错误率的推断,依据是在测试集上的测试错误率
泛化误差:
- 偏差(bias):算法预测值与真实结果之间的偏离程度,刻画模型的欠拟合性
- 方差(vartance):数据的扰动对预测性能的影响,刻画模型的过拟合性
- 噪音(noise):当前学习任务上能够达到的最小泛化误差,刻画任务本身难度
方差与偏差难以同时优化——欠拟合与过拟合之间的矛盾
3.9 数据处理
3.9.1 核函数
适用情况
数据维度较小,通过不同维度指标生成新的维度
如:
{ 二维:低维不可分情况 ↓ 高维:线性可分 \left\{\begin{aligned}&二维:低维不可分情况\\&\downarrow\\&高维:线性可分\end{aligned}\right. ⎩ ⎨ ⎧二维:低维不可分情况↓高维:线性可分
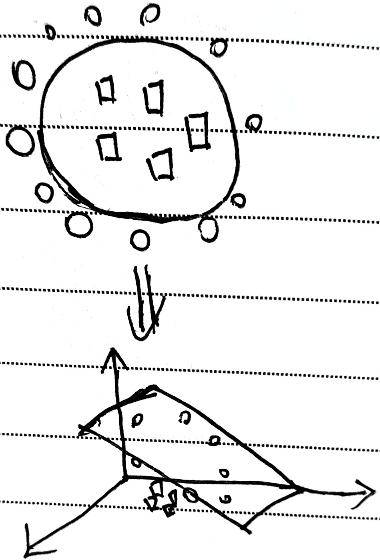
但会导致计算量的增加,需要考虑是否可计算问题
分类
线性核函数
K ( X i , X j ) = X j T X i K(X_i,X_j)=X_j^TX_i K(Xi,Xj)=XjTXi 对数据不做任何变化
适用于:特征丰富,数据量已经很大,实时问题
多项式核函数
( ζ + γ X T X ′ ) Q , γ > 0 (\zeta+\gamma X^TX')^Q,\gamma >0 (ζ+γXTX′)Q,γ>0
- γ \gamma γ :内积放缩比例
- ζ \zeta ζ :常数项
- Q Q Q :多项式阶数,复杂程度
2次常见: ( 1 + γ X T X ′ ) 2 (1+\gamma X^TX')^2 (1+γXTX′)2
高斯核函数
一维: f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x)=2πσ1e−2σ2(x−μ)2

二维: f ( x , y ) = 1 2 π σ x σ y e − 1 2 [ ( x − μ x 2 ) + ( x − μ y 2 ) σ x 2 ] f(x,y)=\frac{1}{2\pi\sigma_x\sigma_y}e^{-\frac{1}{2}\left[\frac{(x-\mu_x^2)+(x-\mu_y^2)}{\sigma_x^2}\right]} f(x,y)=2πσxσy1e−21[σx2(x−μx2)+(x−μy2)]

高斯核函数
K ( X , Y ) = e − ∥ X − Y ∥ 2 2 σ 2 K(X,Y)=e^{-\frac{\Vert X-Y\Vert^2}{2\sigma^2}} K(X,Y)=e−2σ2∥X−Y∥2
- 用两个样本点间的距离度量 生成(表征) 差异性/相似程度
高斯核函数可将特征映射为无穷维
x
x
x 与
x
′
x'
x′ 为两个不同维度的取值
K
(
X
,
X
′
)
=
e
−
(
X
−
X
′
)
2
=
e
−
X
2
e
−
X
′
2
e
−
2
(
X
,
X
′
)
=
T
a
l
o
r
e
−
X
2
e
−
X
′
2
∑
i
=
0
∞
(
2
X
T
X
′
)
i
i
!
=
e
−
X
2
e
−
X
′
2
∑
i
=
1
∞
2
i
i
!
2
i
i
!
X
T
i
X
′
i
=
∑
i
=
0
∞
[
2
i
i
!
X
i
e
−
X
2
]
⋅
[
2
i
i
!
X
′
i
e
−
X
′
2
]
=
Φ
(
X
T
)
Φ
(
X
′
)
\begin{aligned} K(X,X')&=e^{-(X-X')^2}=e^{-X^2}e^{-X'^2}e^{-2(X,X')}\xlongequal{Talor}e^{-X^2}e^{-X'2}\sum_{i=0}^\infty \frac{(2X^TX')^i}{i!}\\ &=e^{-X^2}e^{-X'^2}\sum_{i=1}^\infty \sqrt{\frac{2^i}{i!}}\sqrt{\frac{2^i}{i!}}X^{Ti}X'^i=\sum\limits_{i=0}^\infty \left[\sqrt{\frac{2^i}{i!}}X^ie^{-X^2}\right]\cdot\left[\sqrt{\frac{2^i}{i!}}X'^ie^{-X'^2}\right]\\ &=\Phi(X^T)\Phi(X') \end{aligned}
K(X,X′)=e−(X−X′)2=e−X2e−X′2e−2(X,X′)Talore−X2e−X′2i=0∑∞i!(2XTX′)i=e−X2e−X′2i=1∑∞i!2ii!2iXTiX′i=i=0∑∞[i!2iXie−X2]⋅[i!2iX′ie−X′2]=Φ(XT)Φ(X′)
Φ
(
X
)
=
e
−
X
2
(
1
,
2
X
,
2
X
2
,
⋯
)
\Phi(X)=e^{-X^2}(1,\sqrt{2}X,\sqrt{2}X^2,\cdots)
Φ(X)=e−X2(1,2X,2X2,⋯)
Φ ( X ′ ) = e − X ′ 2 ( 1 , 2 X ′ , 2 X ′ 2 , ⋯ ) \Phi(X')=e^{-X'^2}(1,\sqrt{2}X',\sqrt{2}X'^2,\cdots) Φ(X′)=e−X′2(1,2X′,2X′2,⋯)
eg:
X i = ( x i 1 , x i 2 , ⋯ , x i p ) X_i=\left(x_{i1},x_{i2},\cdots,x_{ip}\right) Xi=(xi1,xi2,⋯,xip)
- F 1 F_1 F1 : K ( X i , X 1 ) K(X_i,X_1) K(Xi,X1)
- F 2 F_2 F2 : K ( X i , X 2 ) K(X_i,X_2) K(Xi,X2)
- ⋮ \vdots ⋮
- F n F_n Fn: K ( X i , X n ) K(X_i,X_n) K(Xi,Xn)
X i = ( x i 1 , x i 2 , ⋯ , x i p , F 1 , ⋯ , F n ) X_i=\left(x_{i1},x_{i2},\cdots,x_{ip},F_1,\cdots,F_n\right) Xi=(xi1,xi2,⋯,xip,F1,⋯,Fn)
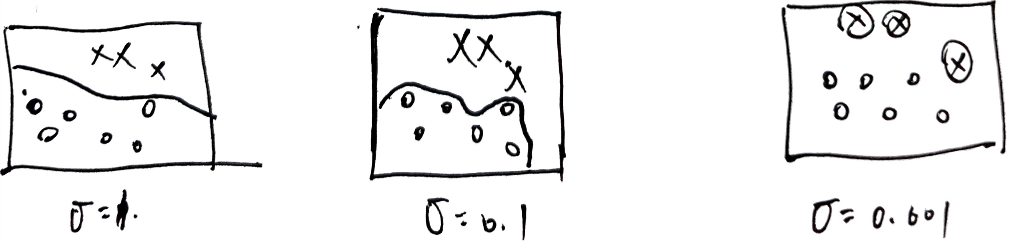
高斯分布对参数敏感
σ \sigma σ 越小, K ( X , X ′ ) K(X,X') K(X,X′) 越大,特征的区分度越大,但过拟合程度越大,稳定性越大
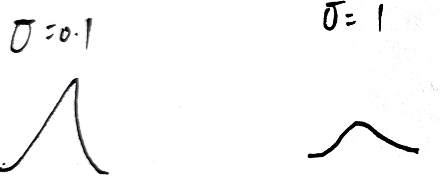
当样本点之间相似度高,需调小 σ \sigma σ ,使区分度更加明显
核函数计算问题
由于核函数使计算量增大,需要解决
将 低维映射到高维,计算高维结果 ⇒ 转变为 计算低维结果,再映射为高维结果 将 \quad低维映射到高维,计算高维结果\xRightarrow{转变为} 计算低维结果,再映射为高维结果 将低维映射到高维,计算高维结果转变为计算低维结果,再映射为高维结果
X = ( x 1 , x 2 , x 3 ) X=\left(x_1,x_2,x_3\right) X=(x1,x2,x3) , Y = ( y 1 , y 2 , y 3 ) Y=\left(y_1,y_2,y_3\right) Y=(y1,y2,y3) ,若三维空间线性不可分
假设通过
f
(
X
)
=
(
x
1
x
1
,
⋯
,
x
1
x
3
,
x
2
x
1
,
⋯
,
x
2
x
3
,
x
3
x
1
,
⋯
,
x
3
x
3
)
f(X)=(x_1x_1,\cdots,x_1x_3,x_2x_1,\cdots,x_2x_3,x_3x_1,\cdots,x_3x_3)
f(X)=(x1x1,⋯,x1x3,x2x1,⋯,x2x3,x3x1,⋯,x3x3) ,
f
(
Y
)
=
(
y
1
y
1
,
⋯
,
y
1
y
3
,
y
2
y
1
,
⋯
,
y
2
y
3
,
y
3
y
1
,
⋯
,
y
3
y
3
)
f(Y)=(y_1y_1,\cdots,y_1y_3,y_2y_1,\cdots,y_2y_3,y_3y_1,\cdots,y_3y_3)
f(Y)=(y1y1,⋯,y1y3,y2y1,⋯,y2y3,y3y1,⋯,y3y3) 变为九维空间
<
f
(
X
)
,
f
(
Y
)
>
=
f
T
(
Y
)
⋅
f
(
X
)
=
∑
i
=
1
n
∑
j
=
1
n
(
x
i
x
j
)
⋅
(
y
i
y
j
)
\left<f(X),f(Y)\right>=f^T(Y)\cdot f(X)=\sum\limits_{i=1}^n\sum\limits_{j=1}^n(x_ix_j)\cdot(y_iy_j)
⟨f(X),f(Y)⟩=fT(Y)⋅f(X)=i=1∑nj=1∑n(xixj)⋅(yiyj)
时间复杂度为
O
(
n
2
)
O(n^2)
O(n2)
K
(
X
,
Y
)
=
(
<
X
,
Y
>
)
2
=
(
∑
i
=
1
n
x
i
y
i
)
2
K(X,Y)=(\left<X,Y\right>)^2=\left(\sum\limits_{i=1}^nx_iy_i\right)^2
K(X,Y)=(⟨X,Y⟩)2=(i=1∑nxiyi)2
时间复杂度为
O
(
n
)
O(n)
O(n)
3.9.2 熵
反映物体内部混乱程度(一个事件发生的不确定性)
H ( X ) = − ∑ x ∈ χ P ( x ) l o g P ( x ) H(X)=-\sum\limits_{x\in \chi}P(x)logP(x) H(X)=−x∈χ∑P(x)logP(x)
熵值大小意义
事件越多, P ( 事 件 i ) P(事件_i) P(事件i) 越小,系统结果的不确定性越多(熵值)
由 0 ≤ P ( x ) ≤ 1 0\le P(x)\le 1 0≤P(x)≤1 , log P ( x ) < 0 \log P(x)<0 logP(x)<0 , − log P ( x ) = ∣ P ( x ) ∣ -\log P(x)=\vert P(x)\vert −logP(x)=∣P(x)∣
若系统由很多小概率事件组成,则 ∑ ∣ log P ( x ) ∣ \sum \vert \log P(x) \vert ∑∣logP(x)∣ 会很大,可表示系统不确定性大
熵可用作分类效果指标
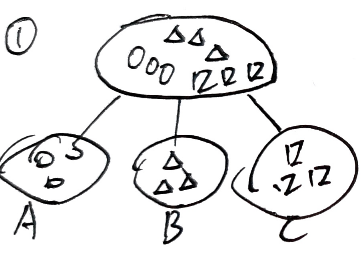
P ( A ∘ ) = 1 , P ( B ∘ ) = 0 , P ( C ∘ ) = 0 P(A_\circ)=1,P(B_\circ)=0,P(C_\circ)=0 P(A∘)=1,P(B∘)=0,P(C∘)=0
P ( A △ ) = 0 , P ( B △ ) = 1 , P ( C △ ) = 0 P(A_\triangle)=0,P(B_\triangle)=1,P(C_\triangle)=0 P(A△)=0,P(B△)=1,P(C△)=0
P ( A □ ) = 0 , P ( B □ ) = 0 , P ( C □ ) = 1 P(A_\square)=0,P(B_\square)=0,P(C_\square)=1 P(A□)=0,P(B□)=0,P(C□)=1
H ( A ) = − ∑ P ( A i ) l o g P ( A i ) = 0 H(A)=-\sum P(A_i)log P(A_i)=0 H(A)=−∑P(Ai)logP(Ai)=0 , H ( B ) = H ( C ) = 0 H(B)=H(C)=0 H(B)=H(C)=0
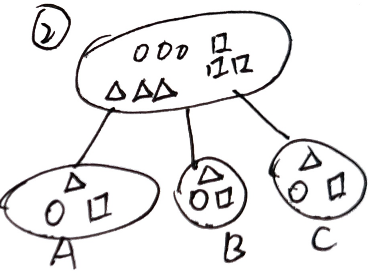
P ( A ∘ ) = 1 3 , P ( B ∘ ) = 1 3 , P ( C ∘ ) = 1 3 P(A_\circ)=\frac{1}{3},P(B_\circ)=\frac{1}{3},P(C_\circ)=\frac{1}{3} P(A∘)=31,P(B∘)=31,P(C∘)=31
P ( A △ ) = 1 3 , P ( B △ ) = 1 3 , P ( c △ ) = 1 3 P(A_\triangle)=\frac{1}{3},P(B_\triangle)=\frac{1}{3},P(c_\triangle)=\frac{1}{3} P(A△)=31,P(B△)=31,P(c△)=31
P ( A □ ) = 1 3 , P ( B □ ) = 1 3 , P ( C □ ) = 1 3 P(A_\square)=\frac{1}{3},P(B_\square)=\frac{1}{3},P(C_\square)=\frac{1}{3} P(A□)=31,P(B□)=31,P(C□)=31
H ( A ) = − ∑ P ( A i ) l o g P ( A i ) = 3 ( − 1 3 l o g 1 3 ) = l o g 3 = H ( B ) = H ( C ) H(A)=-\sum P(A_i)log P(A_i)=3\left(-\frac{1}{3}log\frac{1}{3}\right)=log3=H(B)=H(C) H(A)=−∑P(Ai)logP(Ai)=3(−31log31)=log3=H(B)=H(C)
综合来看, H ( ② ) > H ( ① ) H(②)>H(①) H(②)>H(①) ,①的熵小,分类效果好
3.9.3 激活函数
非线性函数
sigmod函数
将数据压缩到 [ 0 , 1 ] [0,1] [0,1]

分类问题:将各类别输出变换为概率值
问题
-
杀死梯度
边缘情况,梯度为0
-
非原点中心对称
只有正值,导致梯度为正或全为负,会产生阶梯式情况(收敛较慢)