postgresql-通用表表达式
- 简介
- 简单 CTE
- 递归 CTE
- 案例1
- 案例2
- DML 语句与 CTE
简介
通用表表达式(Common Table Expression、CTE)是一个临时的查询结果或者临时表,可以
在其他 SELECT、INSERT、UPDATE 以及 DELETE 语句中使用。通用表表达式只在当前语句中
有效,类似于子查询。
使用 CTE 的主要好处包括:
- 提高复杂查询的可读性。CTE 可以将复杂查询模块化,组织成容易理解的结构
- 支持递归查询。CTE 通过引用自身实现递归,可以方便地处理层次结构数据和图数据。
简单 CTE
通用表表达式的定义如下:
WITH cte_name (col1, col2, ...) AS (
cte_query_definition
)
sql_statement;

PostgreSQL 中的 CTE 通常用于简化复杂的连接查询或子查询。例如:
with department_avg(department_id, avg_salary) as (
select department_id,
avg(salary) as avg_salary
from employees
group by department_id
)
select d.department_name,
da.avg_salary
from departments d
join department_avg da
on (d.department_id = da.department_id)
order by d.department_name;
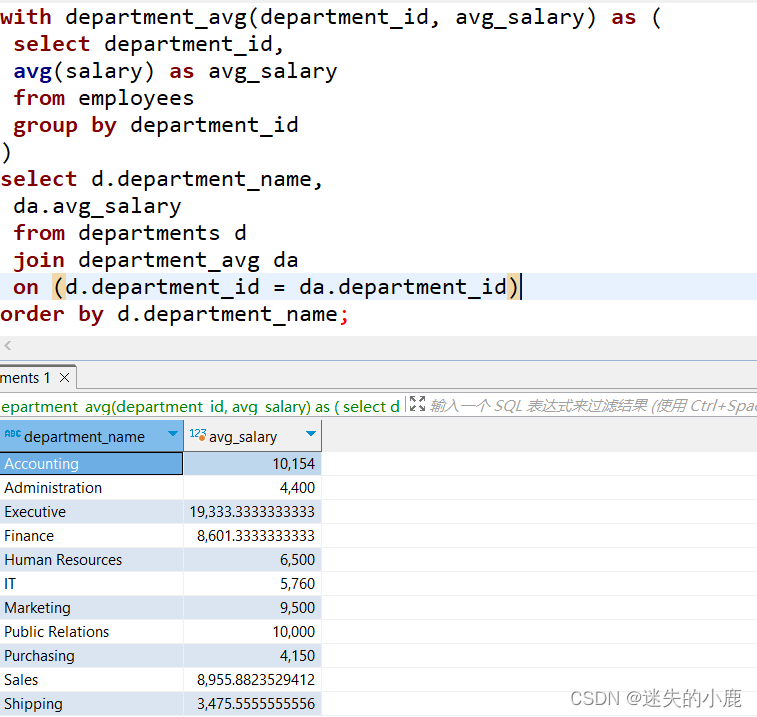
首先,我们定义了一个名为 department_avg 的 CTE,表示每个部门的平均月薪;然后和
departments 表进行连接查询。虽然用其他方式也可以实现相同的功能,但是 CTE 让代码显得更
加清晰易懂。
一个 WITH 关键字可以定义多个 CTE,而且后面的 CTE 可以引用前面的 CTE。例如:
with cte1(n) as (
select 1
),
cte2(m) as (
select n+1 from cte1
)
select *
from cte1, cte2;
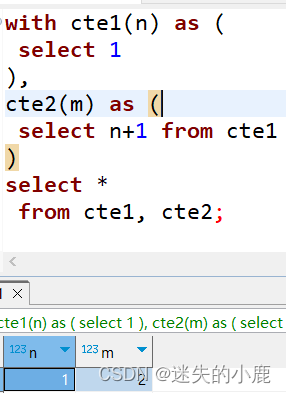
以上示例中定义了两个 CTE,其中 cte2 引用了 cte1。最后的查询使用两者进行连接查询。
递归 CTE
递归 CTE 允许在它的定义中进行自引用,理论上来说可以实现任何复杂的计算功能,最常
用的场景就是遍历层次结构的数据和图结构数据。
WITH RECURSIVE cte_name AS(
cte_query_initial -- 初始化部分
UNION [ALL]
cte_query_iterative -- 递归部分
) SELECT * FROM cte_name;
RECURSIVE 表示递归;
cte_query_initial 是初始化查询,用于创建初始结果集
cte_query_iterative 是递归部分,可以引用 cte_name;
如果递归查询无法从上一次迭代中返回更多的数据,将会终止递归并返回结果。
案例1
一个经典的递归 CTE 案例就是生成数字序列:
with recursive t(n) as (
values (1)
union all
select n+1 from t where n < 10
)
select n from t;

以上语句执行过程如下:
- 执行 CTE 中的初始化查询,生成一行数据(1)
- 第一次执行递归查询,判断 n < 10 成立,生成一行数据 2 (n+1);
- 重复执行递归查询,生成更多的数据;直到 n = 10 终止;此时临时表 t 中包含 10 条数据
- 执行主查询,返回所有的数据
如果没有指定终止条件,上面的查询将会进入死循环
案例2
递归 CTE 遍历组织结构
with recursive employee_path (employee_id, employee_name, path) as
(
select employee_id, concat(first_name, ',', last_name), concat(first_name,
',', last_name) as path
from employees
where manager_id is null
union all
select e.employee_id, concat(e.first_name, ',', e.last_name),
concat(ep.path, '->', e.first_name, ',', e.last_name)
from employee_path ep
join employees e on ep.employee_id = e.manager_id
)
select employee_name, path
from employee_path
order by employee_id;
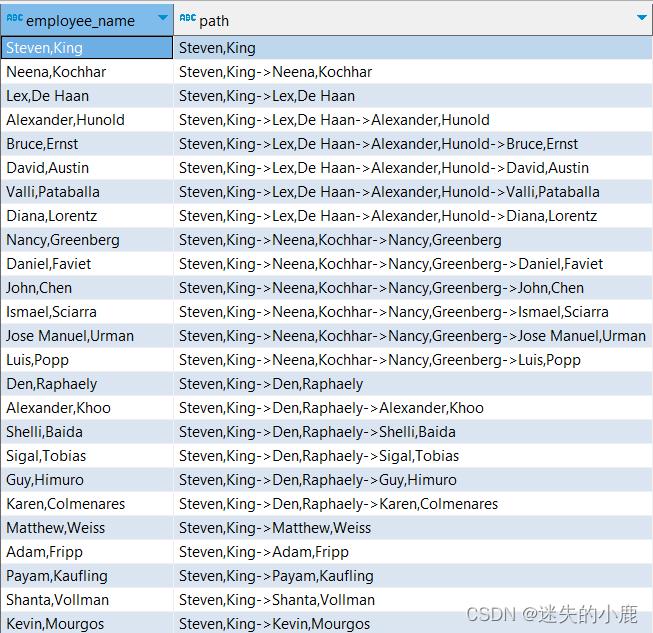
其中,初始化查询语句返回了公司最高层的领导(manager_id IS NULL),也就是
“Steven,King”;递归查询将员工表的 manager_id 与已有结果集中的 employee_id 关联,获取每个
员工的下一级员工,直到无法找到新的数据;path 字段存储了每个员工从上至下的管理路径
更多关于递归 CTE 的实际应用场景,可以参考这篇文章
DML 语句与 CTE
除了 SELECT 语句之外,INSERT、UPDATE 或者 DELETE 语句也可以与 CTE 一起使用。
我们可以在 CTE 中使用 DML 语句,也可以将 CTE 用于 DML 语句。
如果在 CTE 中使用 DML 语句,我们可以将数据修改操作影响的结果作为一个临时表,然
后在其他语句中使用。例如:
-- 创建一个员工历史表
create table employees_history
as select * from employees where 1 = 0;
with deletes as (
delete from employees
where employee_id = 206
returning *
)
insert into employees_history
select * from deletes;
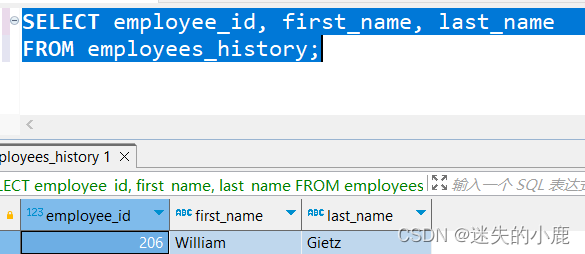
SELECT employee_id, first_name, last_name
FROM employees_history;
我们首先创建了一个记录员工历史信息的 employees_history 表;然后使用 DELETE 语句定
义了一个 CTE,RETURNING *返回了被删除的数据,构成了结果集 deletes;然后使用 INSERT
语句记录被删除的员工信息
接下来我们将该员工添加回员工表:
WITH inserts AS (
INSERT INTO employees
VALUES
(206,'William','Gietz','WGIETZ','515.123.8181','2002-06-07','AC_ACCOUNT',8800.00,NULL,205,110)
RETURNING *
)
INSERT INTO employees_history
SELECT * FROM inserts;
除了插入数据到 employees 表之外,我们还利用 CTE 在表 employees_history 中增加了一条
历史记录,现在该表中有两条数据


CTE 中的 UPDATE 语句有些不同,因为更新的数据分为更新之前的状态和更新之后的状态。
例如:
DELETE FROM employees_history;-- 清除历史记录
with updates as (
update employees
set salary = salary + 500
where employee_id = 206
returning *
)
insert into employees_history
select * from employees where employee_id = 206;
select employee_id, salary from employees_history;
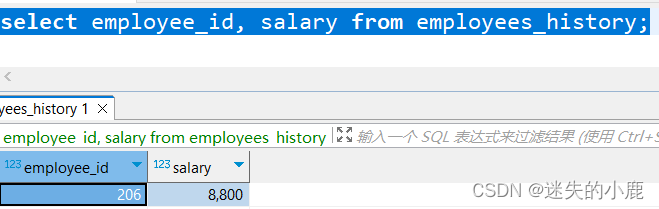
returning 在 CTE 中,UPDATE 语句修改了一个员工的月薪;但是为了记录修改之前的数据,
我们插入 employees_history 的数据仍然来自 employees 表。因为在一个语句中,所有的操作都在
一个事务中,所以主查询中的 employees 是修改之前的状态。
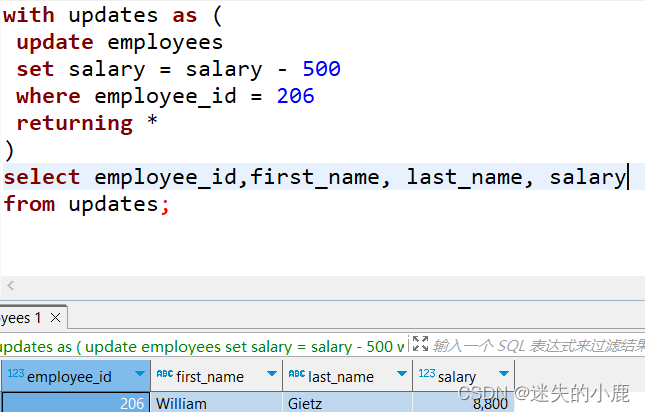
如果想要获取更新之后的数据,直接使用 updates 即可:
with updates as (
update employees
set salary = salary - 500
where employee_id = 206
returning *
)
select employee_id,first_name, last_name, salary
from updates;


![[ZenTao]源码阅读:自定义任务类型](https://img-blog.csdnimg.cn/df668dcdb6bd4744984c6c76e393a892.png)