全流程,训练语义分割数据集
- 数据标注
- json转mask
- 运行源码MMSegmentation
- 模型选择运行部分
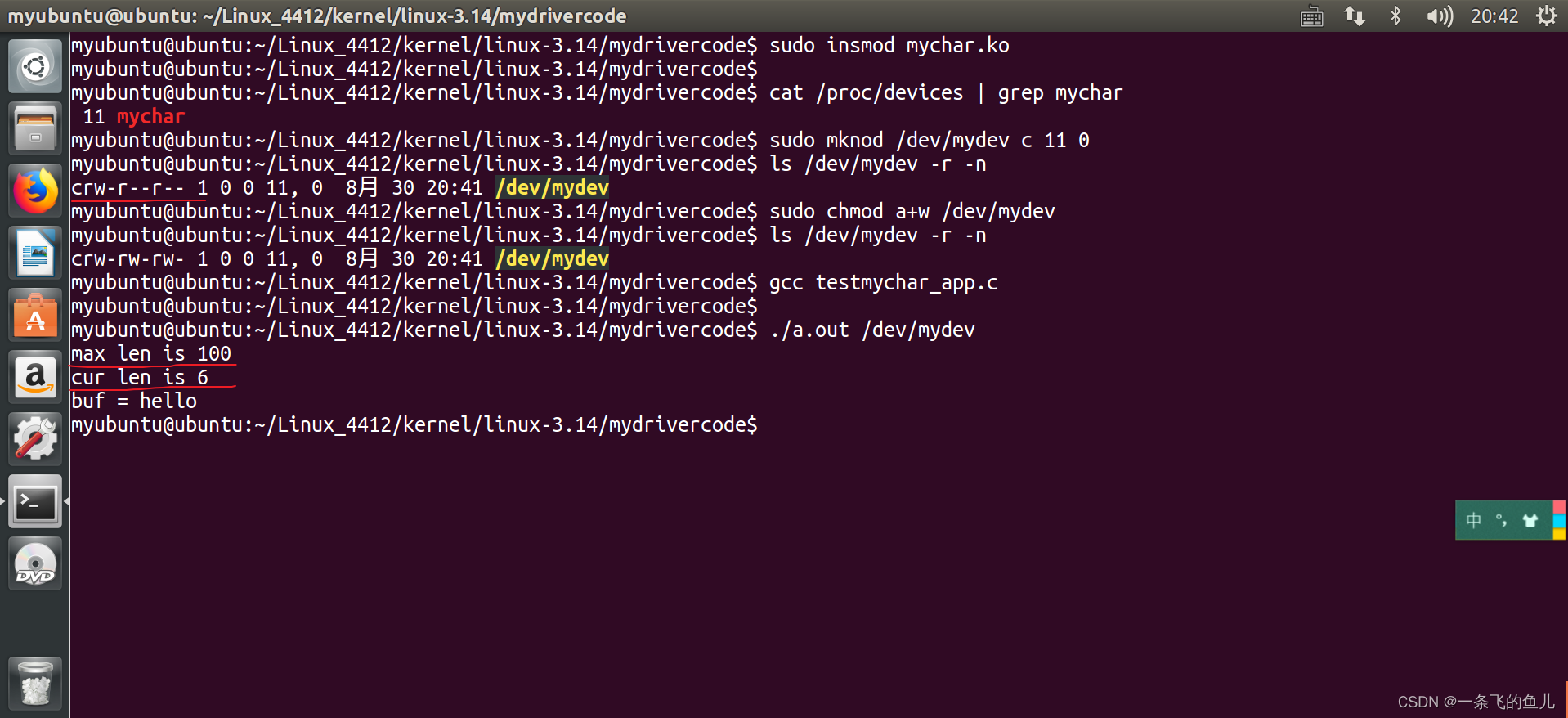
数据标注
# 安装
pip install labelme
# 启动labelme
labelme
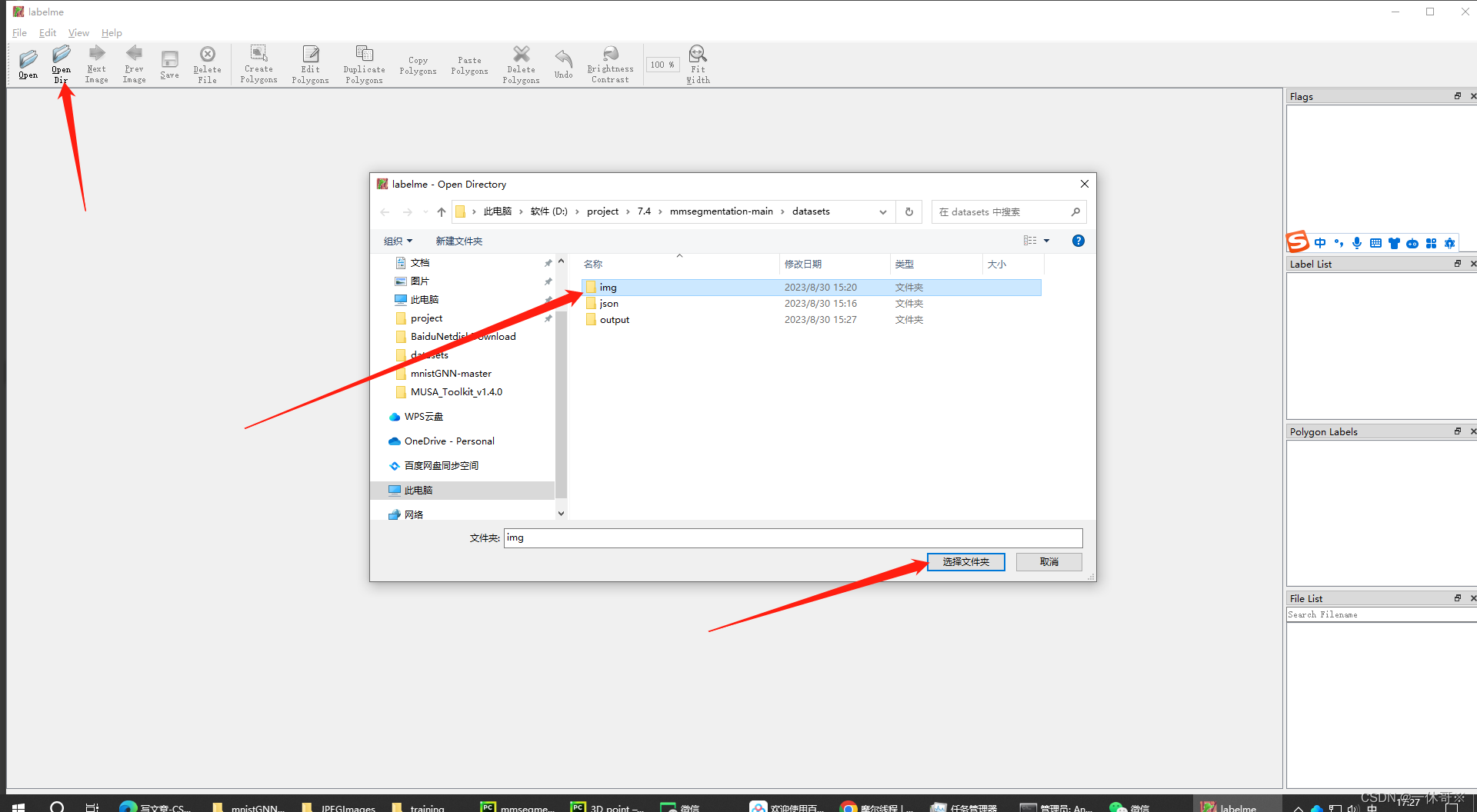
然后 ctrl +N 开启多边形标注即可,命名类为person
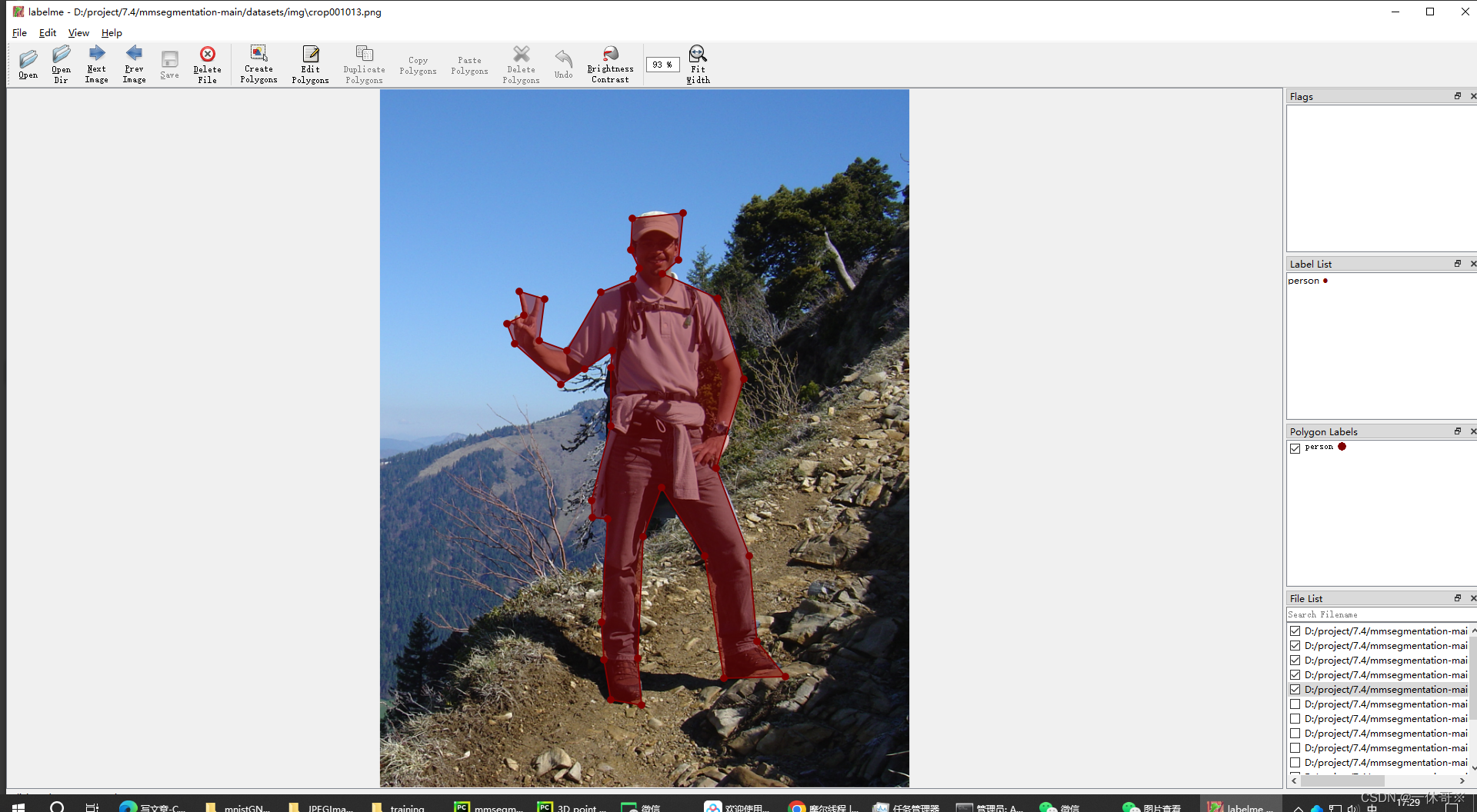
之后会保存到同目录下json文件:
json转mask
下载labelme代码里的转换代码:
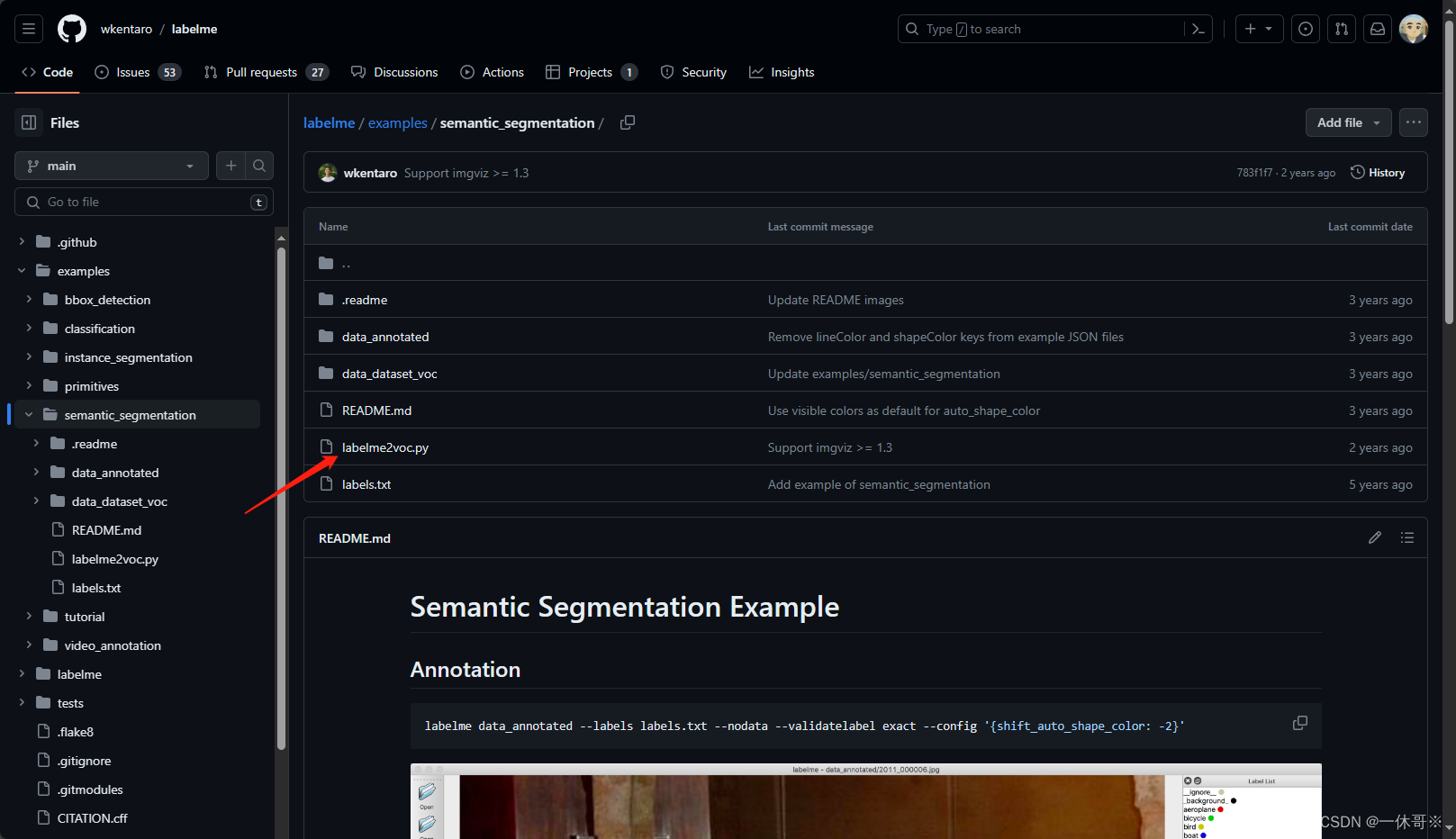
labels里存储的如下形式

运行指令
python labelme2voc.py ./img output labels.txt
生成如下
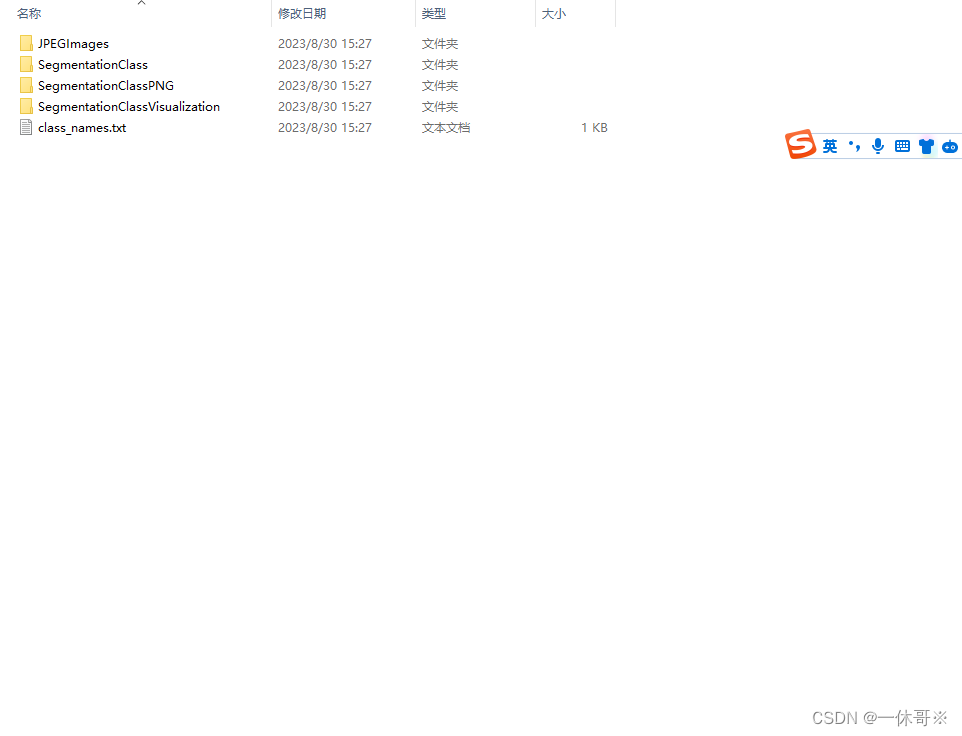
运行源码MMSegmentation
mmseg/datasets里生成一个my_data.py文件,这个文件存储的是类别信息和seg颜色
需要多加一个backbone
# Copyright (c) OpenMMLab. All rights reserved.
from mmseg.registry import DATASETS
from .basesegdataset import BaseSegDataset
@DATASETS.register_module()
class mydata(BaseSegDataset):
"""Cityscapes dataset.
The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
"""
METAINFO = dict(
classes=('backbone','person'),
palette=[[128, 64, 128], [244, 35, 232]])
def __init__(self,
img_suffix='.jpg',
seg_map_suffix='.png',
reduce_zero_label=True,
**kwargs) -> None:
super().__init__(
img_suffix=img_suffix,
seg_map_suffix=seg_map_suffix,
reduce_zero_label=reduce_zero_label,
**kwargs)
mmseg/utils/class_names.py文件里添加:不加backbone也不报错,这里没加,最好加上另外,seg颜色要与上面文件一致
def mydata_classes():
"""shengteng class names for external use."""
return [
'person'
]
def mydata_palette():
return [[244, 35, 232]]
mmseg/datasets/init.py中加引入,
from .my_data import mydata
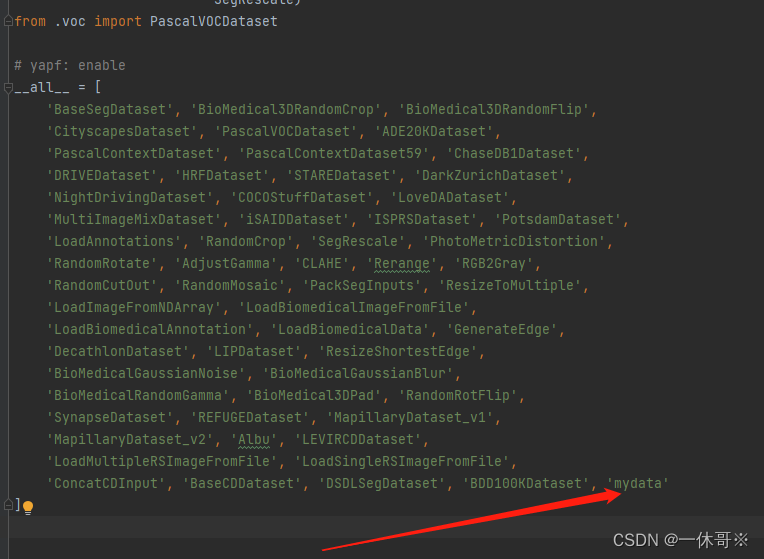
configs/base/datasets文件下新建一个my_data.py文件:
这个就是一个读取数据的文件了,包含数据地址、type和加载增加等方式
# dataset settings
dataset_type = 'mydata' #改
data_root = 'data/my_dataset' #改
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', reduce_zero_label=True),
dict(
type='RandomResize',
scale=(2048, 512),
ratio_range=(0.5, 2.0),
keep_ratio=True),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='PackSegInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=(2048, 512), keep_ratio=True),
# add loading annotation after ``Resize`` because ground truth
# does not need to do resize data transform
dict(type='LoadAnnotations', reduce_zero_label=True),
dict(type='PackSegInputs')
]
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
tta_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(
type='TestTimeAug',
transforms=[
[
dict(type='Resize', scale_factor=r, keep_ratio=True)
for r in img_ratios
],
[
dict(type='RandomFlip', prob=0., direction='horizontal'),
dict(type='RandomFlip', prob=1., direction='horizontal')
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
])
]
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='InfiniteSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='images/training', seg_map_path='annotations/training'), #改
pipeline=train_pipeline))
val_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='images/validation', #改
seg_map_path='annotations/validation'), #改
pipeline=test_pipeline))
test_dataloader = val_dataloader
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
test_evaluator = val_evaluator
模型选择运行部分
我选择的是configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py,主要是修改继承的数据部分
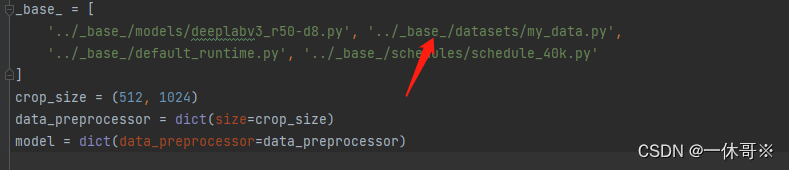
运行
每次修改配置文件,最好是运行一遍python setup.py install
python setup.py install
python ./tools/train.py ./configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py