🔥🔥 欢迎来到小林的博客!!
🛰️博客主页:✈️林 子
🛰️博客专栏:✈️ Linux
🛰️社区 :✈️ 进步学堂
🛰️欢迎关注:👍点赞🙌收藏✍️留言
目录
- 用户级缓冲区
- 缓冲区的验证
- 缓冲区的继承
用户级缓冲区
实际上我们的C语言库函数,例如 printf,fprintf,puts 等。会把数据先写入C语言缓冲区,也就是用户级缓冲区。而不是直接写入系统内核缓冲区,如何验证呢? 我们先来看一份代码。
这份代码我们用的是C语言的fprintf 往 文件log.txt里写入hello。
#include<stdio.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
close(1);
FILE* f = fopen("./log.txt","w");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
return 0;
}
我们可以发现,会把hello输入进文件log.txt中 。
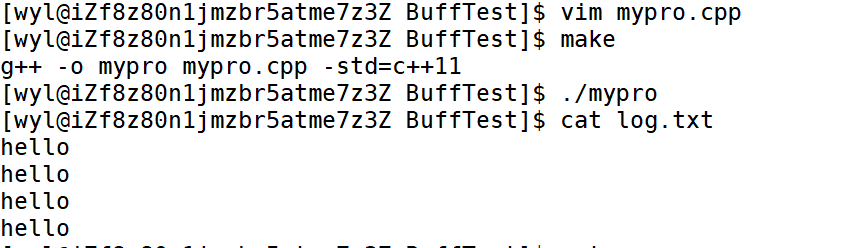
那么我们在输入之后把 f的文件描述符关掉呢?
#include<stdio.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
close(1);
FILE* f = fopen("./log.txt","w");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
close(f->_fileno);
return 0;
}
我们就会惊奇的发现,log.txt 就不会被写入。

为什么会这样呢?主要是因为fprintf/printf/puts 等C语言库函数会先把内容放进C语言的缓冲区。或者说是用户层缓冲区,而用户级缓冲区的刷新策略是不一样的。
显示器刷新策略:行刷新,带/n 自动刷新
磁盘刷新策略: 缓冲区满了才刷新
而我们上面的代码是往磁盘文件写入,所以只有缓冲区满了,或者进程结束时自动刷新。而程序要在return之后在会结束,我们在return之前我们把该文件关闭了。那么最后刷新的时候进程就找不到对应的描述文件符。
当然,我们也可以在关闭之前手动fflush刷新一下。在关闭文件描述符之前刷新
#include<stdio.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
close(1);
FILE* f = fopen("./log.txt","w");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fflush(f);
close(f->_fileno);
return 0;
}
我们依然可以把内容写进文件。
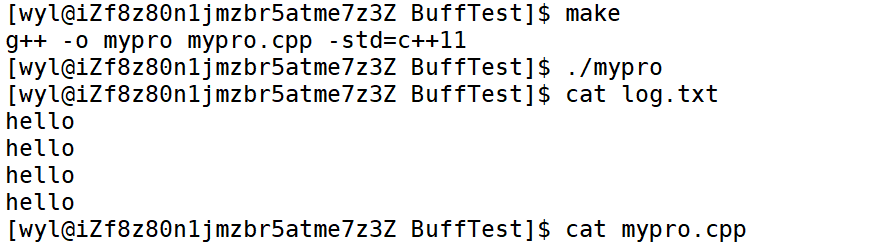
缓冲区的验证
以上是我们的C语言缓冲区的验证,那么write/read等系统调用函数会经过C语言缓冲区吗?我们可以验证一下
#include<stdio.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
close(1);
FILE* f = fopen("./log.txt","w");
write(f->_fileno,"write\n",6);
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
fprintf(f,"hello\n");
close(f->_fileno);
return 0;
}
然后我们会发现, write是可以正常写入,而fprintf的内容不能写入。

这说明了什么?这说明write不经过C语言缓冲区,而是直接写入系统内核缓冲区!因为write/read等函数是系统调用接口。 这也反向验证了 fprintf等一系列C语言库函数是先写入C语言缓冲区!然后根据刷新策略再刷新到系统缓冲区,再由系统缓冲区刷新到外设上。而C语言库函数的职能就是把字符串刷新到C语言缓冲区!!
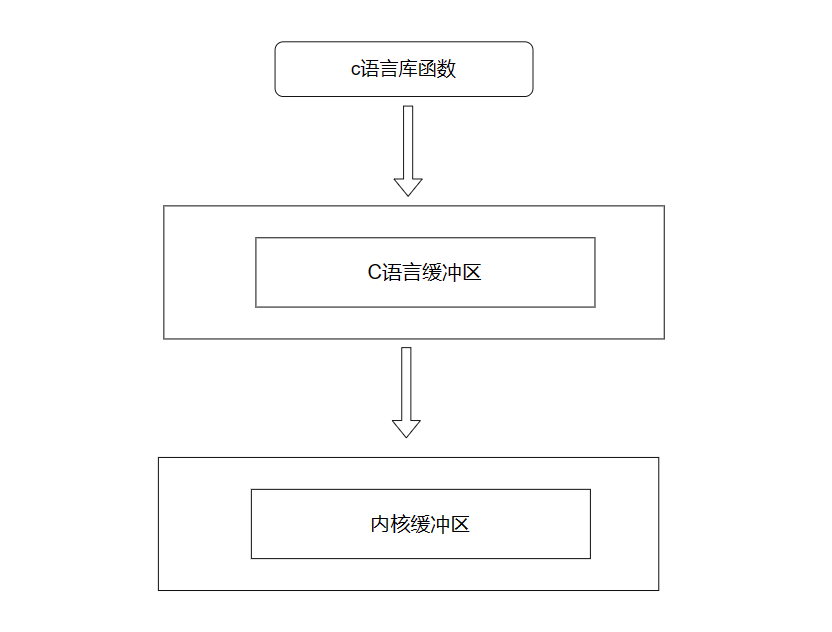
缓冲区的继承
那么子进程会继承父进程的缓冲区吗? 我们先看看下面这段代码。
#include<stdio.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
//close(1);
write(1,"write\n",6);
fprintf(stdout,"hello\n");
fprintf(stdout,"hello\n");
fprintf(stdout,"hello\n");
fprintf(stdout,"hello\n");
fork();
return 0;
}
然后我们运行发现每条语句都打印了一次

这没有问题,那么我们把它写入到文件呢?
#include<stdio.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
close(1);
int fd = open("./log.txt",O_CREAT | O_WRONLY,0664);
write(fd,"write\n",6);
fprintf(stdout,"hello\n");
fprintf(stdout,"hello\n");
fprintf(stdout,"hello\n");
fprintf(stdout,"hello\n");
fork();
return 0;
}
然后我们运行看看结果。
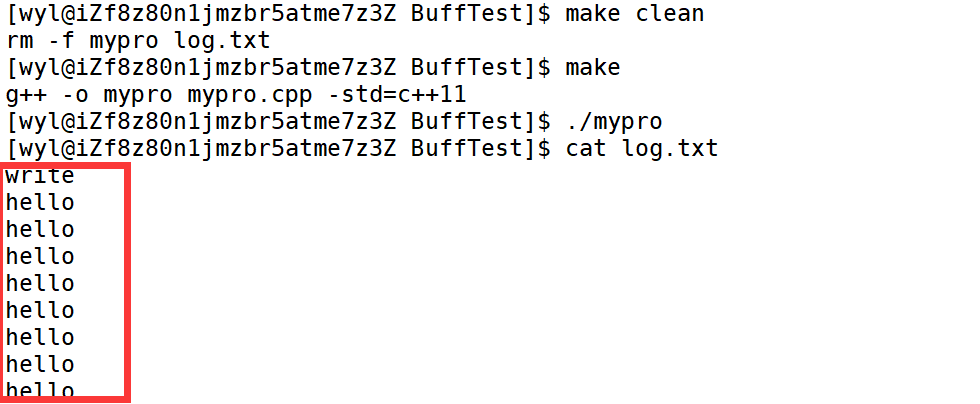
我们可以惊奇的发现,C语言库函数的内容被打印了2次! 而系统调用的内容只被打印了一次。
这说明了什么?这说明了子进程是可以继承父进程的缓冲区的。 为什么第一次打印到显示器每条语句只打印一次,而写进文件 C语言库函数写入却写入俩次? 这是因为显示器和磁盘刷新策略不同!!! 显示器是行刷新,而我们每个字符串后面加了个\n,所以刷新到C语言缓冲区后立马就被刷新到了系统缓冲区。但是磁盘的刷新策略是缓冲区满了才刷新,所以在创建子进程后。父进程的用户级缓冲区还没有被刷新,所以子进程就把这些内容继承下来了。而程序结束时会自动刷新缓冲区,所以父子进程的缓冲区都被刷新了,就出现了缓冲区内写入2次的结果。
这也更加验证了C库函数不是直接往系统缓冲区写入的,否则绝对不会出现写入俩次的情况!!








![java八股文面试[数据库]——MySql聚簇索引和非聚簇索引索引区别](https://img-blog.csdnimg.cn/img_convert/7fb4dad9bb8a7391ef84b07cf667ef4a.png)