背景:实际开发中遇到一个需求,就是需要将hive表中的数据同步到es集群中,之前没有做过,查看一些帖子,发现有一种方案挺不错的,记录一下。
我的电脑环境如下
| 软件名称 | 版本 | |
|---|---|---|
| Hadoop | 3.3.0 | |
| hive | 3.1.3 | |
| jdk | 1.8 | |
| Elasticsearch | 7.10.2 | |
| kibana | 7.10.2 | |
| logstash | 7.10.2 | |
| ES-Hadoop | 7.10.2 |
ES-Hadoop的引入
hadoop、hive和es的关系如下图,中间有一个组件叫做ES-Hadoop,是连接Hadoop和es的桥梁,es的官网上提供了这个组件,解决Hadoop和es之间的数据同步问题。
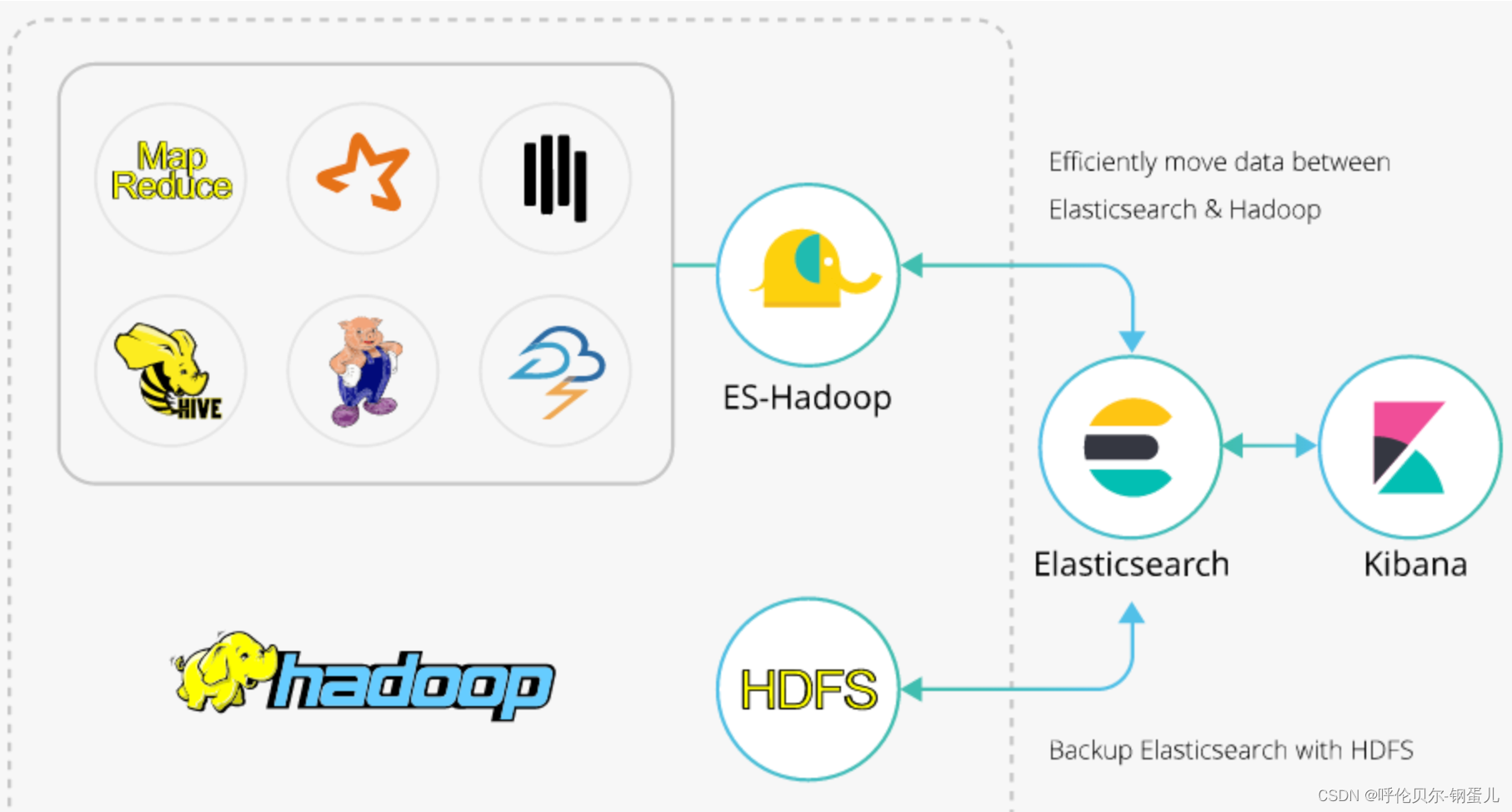
下面说一下数据同步的具体步骤
第一步:去es的官网上下载ES-Hadoop组件
注意:ES-Hadoop 的版本需要和es的版本是一致的
官网下载地址:es的官网链接-点我
在输入框中输入es-hadoop,在version版本处找到和你es相同的版本即可
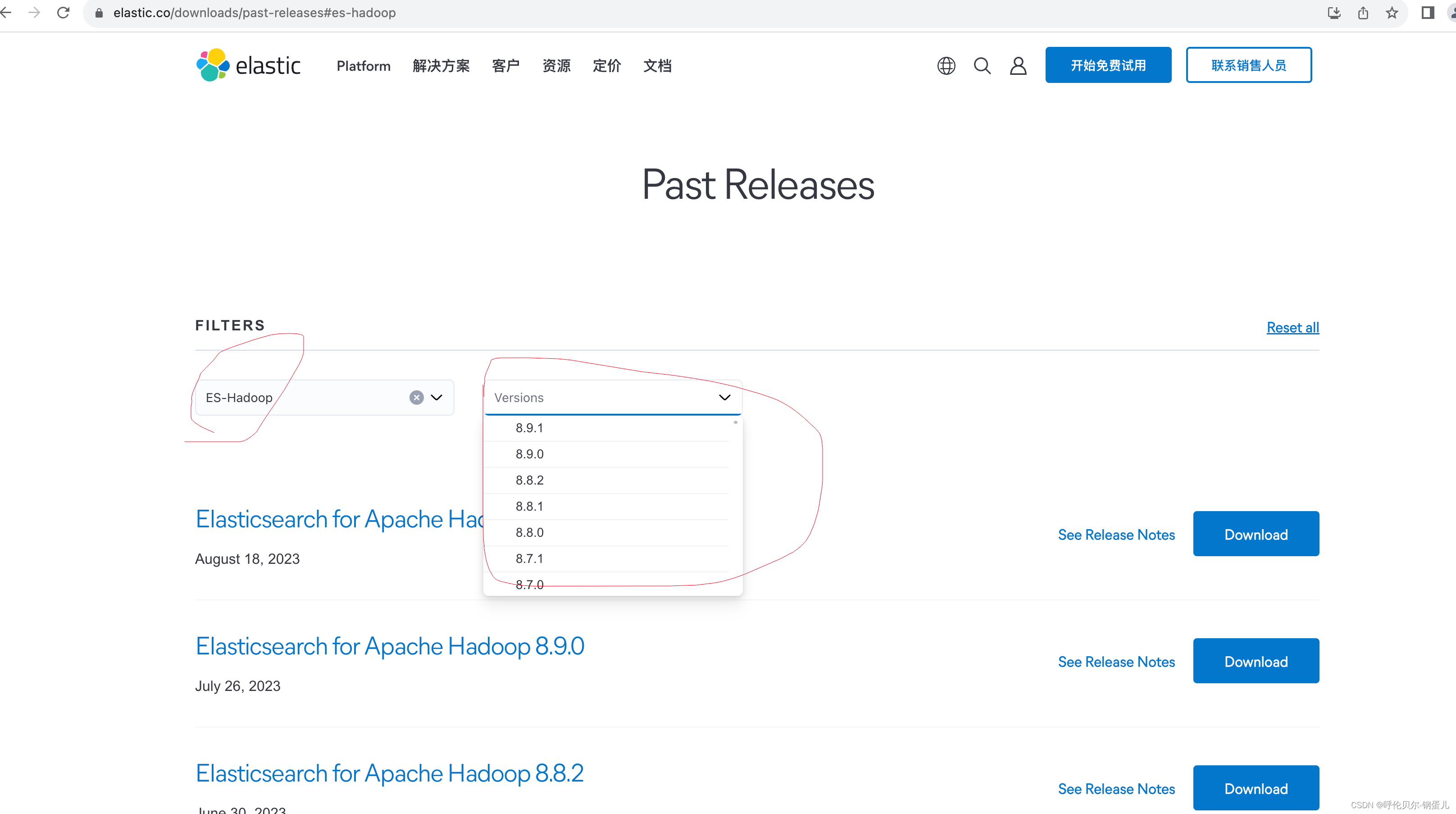
第二步:上传这个安装包到集群上,解压完成后将其中的jar包上传到HDFS上你新建的目录
命令如下;
hadoop fs -put elasticsearch-hadoop-7.10.2.jar /user/hive/warehouse/es_hadoop/
第三步:将这个jar包添加到hive中
在hive的终端下输入如下命令
add jar hdfs:///user/hive/warehouse/es_hadoop/elasticsearch-hadoop-7.10.2.jar;
第四步:在hive中创建临时表,作为测试用
创建一个hive中的表,并且添加上测试数据
CREATE EXTERNAL TABLE `hive_test`(
`name` string,
`age` int,
`hight` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://master:9000/user/hive/warehouse/pdata_dynamic.db/hive_test';
添加数据,展示如下
hive> select * from hive_test;
OK
吴占喜 30 175
令狐冲 50 180
任我行 60 160
第五步:创建hive到es的映射表
CREATE EXTERNAL TABLE `es_hadoop_cluster`(
`name` string COMMENT 'from deserializer',
`age` string COMMENT 'from deserializer',
`hight` string COMMENT 'from deserializer')
ROW FORMAT SERDE
'org.elasticsearch.hadoop.hive.EsSerDe'
STORED BY
'org.elasticsearch.hadoop.hive.EsStorageHandler'
WITH SERDEPROPERTIES (
'serialization.format'='1')
LOCATION
'hdfs://master:9000/user/hive/warehouse/pdata_dynamic.db/es_hadoop_cluster'
TBLPROPERTIES (
'bucketing_version'='2',
'es.batch.write.retry.count'='6',
'es.batch.write.retry.wait'='60s',
'es.index.auto.create'='TRUE',
'es.index.number_of_replicas'='0',
'es.index.refresh_interval'='-1',
'es.mapping.name'='name:name,age:age,hight:hight',
'es.nodes'='172.16.27.133:9200',
'es.nodes.wan.only'='TRUE',
'es.resource'='hive_to_es/_doc');
映射表的参数说明
| 参数 | 参数 | 参数说明 |
|---|---|---|
| bucketing_version | 2 | |
| es.batch.write.retry.count | 6 | |
| es.batch.write.retry.wait | 60s | |
| es.index.auto.create | TRUE | 通过Hadoop组件向Elasticsearch集群写入数据,是否自动创建不存在的index: true:自动创建 ; false:不会自动创建 |
| es.index.number_of_replicas | 0 | |
| es.index.refresh_interval | -1 | |
| es.mapping.name | 7.10.2 | hive和es集群字段映射 |
| es.nodes | 指定Elasticsearch实例的访问地址,建议使用内网地址。 | |
| es.nodes.wan.only | TRUE | 开启Elasticsearch集群在云上使用虚拟IP进行连接,是否进行节点嗅探: true:设置 ;false:不设置 |
| es.resource | 7.10.2 | es集群中索引名称 |
| es.nodes.discovery | TRUE | 是否禁用节点发现:true:禁用 ;false:不禁用 |
| es.input.use.sliced.partitions | TRUE | 是否使用slice分区: true:使用。设置为true,可能会导致索引在预读阶段的时间明显变长,有时会远远超出查询数据所耗费的时间。建议设置为false,以提高查询效率; false:不使用。 |
| es.read.metadata | FALSE | 操作Elasticsearch字段涉及到_id之类的内部字段,请开启此属性。 |
第六步:写同步SQL测试一下
同步SQL
insert into es_hadoop_cluster select * from hive_test;
结果报错了,nice,正好演示一下这个错误怎么解决
报错信息中有一行:Caused by: java.lang.ClassNotFoundException: org.elasticsearch.hadoop.hive.EsHiveInputFormat
报错原因:在hive中执行add jar xxx 这个命令,只在当前窗口下有效
解决方案:1.每次执行insert into的时候,执行下面的添加jar包的命令
add jar hdfs:///user/hive/warehouse/es_hadoop/elasticsearch-hadoop-7.10.2.jar;
2.将这个jar包作为永久的函数加载进来(后面在补充再补充一下)
Query ID = root_20230830041146_d125a01c-4174-48a5-8b9c-a15b41d27403
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1693326922484_0004, Tracking URL = http://master:8088/proxy/application_1693326922484_0004/
Kill Command = /root/soft/hadoop/hadoop-3.3.0//bin/mapred job -kill job_1693326922484_0004
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
2023-08-30 04:11:51,842 Stage-2 map = 0%, reduce = 0%
2023-08-30 04:12:45,532 Stage-2 map = 100%, reduce = 0%
Ended Job = job_1693326922484_0004 with errors
0 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.exec.Task - Ended Job = job_1693326922484_0004 with errors
Error during job, obtaining debugging information...
1 [Thread-33] ERROR org.apache.hadoop.hive.ql.exec.Task - Error during job, obtaining debugging information...
Examining task ID: task_1693326922484_0004_m_000000 (and more) from job job_1693326922484_0004
3 [Thread-34] ERROR org.apache.hadoop.hive.ql.exec.Task - Examining task ID: task_1693326922484_0004_m_000000 (and more) from job job_1693326922484_0004
Task with the most failures(4):
-----
Task ID:
task_1693326922484_0004_m_000000
URL:
http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0004&tipid=task_1693326922484_0004_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: Failed to load plan: hdfs://master:9000/tmp/hive/root/582efbca-df6e-4f87-b4a4-5a5f03667fd9/hive_2023-08-30_04-11-47_010_5312656494742717839-1/-mr-10002/ae1cf98b-a157-4266-92b3-7d618b411f00/map.xml
at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:502)
at org.apache.hadoop.hive.ql.exec.Utilities.getMapWork(Utilities.java:335)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.init(HiveInputFormat.java:435)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:881)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:874)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getRecordReader(CombineHiveInputFormat.java:716)
at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.<init>(MapTask.java:175)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:444)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
Caused by: org.apache.hive.com.esotericsoftware.kryo.KryoException: Unable to find class: org.elasticsearch.hadoop.hive.EsHiveInputFormat
Serialization trace:
inputFileFormatClass (org.apache.hadoop.hive.ql.plan.TableDesc)
tableInfo (org.apache.hadoop.hive.ql.plan.FileSinkDesc)
conf (org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator)
childOperators (org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator)
childOperators (org.apache.hadoop.hive.ql.exec.TableScanOperator)
aliasToWork (org.apache.hadoop.hive.ql.plan.MapWork)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:156)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readClass(DefaultClassResolver.java:133)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClass(Kryo.java:670)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClass(SerializationUtilities.java:185)
at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:326)
at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:314)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObjectOrNull(Kryo.java:759)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObjectOrNull(SerializationUtilities.java:203)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:132)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:161)
at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:39)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:686)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:210)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializeObjectByKryo(SerializationUtilities.java:729)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:613)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:590)
at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:463)
... 13 more
Caused by: java.lang.ClassNotFoundException: org.elasticsearch.hadoop.hive.EsHiveInputFormat
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:154)
... 60 more
98 [Thread-33] ERROR org.apache.hadoop.hive.ql.exec.Task -
Task with the most failures(4):
-----
Task ID:
task_1693326922484_0004_m_000000
URL:
http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0004&tipid=task_1693326922484_0004_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: Failed to load plan: hdfs://master:9000/tmp/hive/root/582efbca-df6e-4f87-b4a4-5a5f03667fd9/hive_2023-08-30_04-11-47_010_5312656494742717839-1/-mr-10002/ae1cf98b-a157-4266-92b3-7d618b411f00/map.xml
at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:502)
at org.apache.hadoop.hive.ql.exec.Utilities.getMapWork(Utilities.java:335)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.init(HiveInputFormat.java:435)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:881)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:874)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getRecordReader(CombineHiveInputFormat.java:716)
at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.<init>(MapTask.java:175)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:444)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
Caused by: org.apache.hive.com.esotericsoftware.kryo.KryoException: Unable to find class: org.elasticsearch.hadoop.hive.EsHiveInputFormat
Serialization trace:
inputFileFormatClass (org.apache.hadoop.hive.ql.plan.TableDesc)
tableInfo (org.apache.hadoop.hive.ql.plan.FileSinkDesc)
conf (org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator)
childOperators (org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator)
childOperators (org.apache.hadoop.hive.ql.exec.TableScanOperator)
aliasToWork (org.apache.hadoop.hive.ql.plan.MapWork)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:156)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readClass(DefaultClassResolver.java:133)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClass(Kryo.java:670)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClass(SerializationUtilities.java:185)
at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:326)
at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:314)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObjectOrNull(Kryo.java:759)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObjectOrNull(SerializationUtilities.java:203)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:132)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:161)
at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:39)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:686)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:210)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializeObjectByKryo(SerializationUtilities.java:729)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:613)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:590)
at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:463)
... 13 more
Caused by: java.lang.ClassNotFoundException: org.elasticsearch.hadoop.hive.EsHiveInputFormat
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:154)
... 60 more
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
106 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.Driver - FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
将jar包添加进来又报错了,very nice,正好在演示一下这个错误,😄
报错如下所示
报错原因分析:仔细看这行Error: java.lang.ClassNotFoundException: org.apache.commons.httpclient.HttpConnectionManager,原因是缺少httpclient.的jar包导致的
解决方案:将httpclient.的jar包像上面的es-hadoop的jar包一样导入即可
hive> insert into es_hadoop_cluster select * from hive_test;
Query ID = root_20230830041906_20c85a80-072a-4023-b5ab-8b532e5db092
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1693326922484_0005, Tracking URL = http://master:8088/proxy/application_1693326922484_0005/
Kill Command = /root/soft/hadoop/hadoop-3.3.0//bin/mapred job -kill job_1693326922484_0005
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
2023-08-30 04:19:15,561 Stage-2 map = 0%, reduce = 0%
2023-08-30 04:19:34,095 Stage-2 map = 100%, reduce = 0%
Ended Job = job_1693326922484_0005 with errors
408543 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.exec.Task - Ended Job = job_1693326922484_0005 with errors
Error during job, obtaining debugging information...
408543 [Thread-57] ERROR org.apache.hadoop.hive.ql.exec.Task - Error during job, obtaining debugging information...
Examining task ID: task_1693326922484_0005_m_000000 (and more) from job job_1693326922484_0005
408547 [Thread-58] ERROR org.apache.hadoop.hive.ql.exec.Task - Examining task ID: task_1693326922484_0005_m_000000 (and more) from job job_1693326922484_0005
Task with the most failures(4):
-----
Task ID:
task_1693326922484_0005_m_000000
URL:
http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0005&tipid=task_1693326922484_0005_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.ClassNotFoundException: org.apache.commons.httpclient.HttpConnectionManager
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at org.elasticsearch.hadoop.rest.commonshttp.CommonsHttpTransportFactory.create(CommonsHttpTransportFactory.java:40)
at org.elasticsearch.hadoop.rest.NetworkClient.selectNextNode(NetworkClient.java:99)
at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:82)
at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:58)
at org.elasticsearch.hadoop.rest.RestClient.<init>(RestClient.java:101)
at org.elasticsearch.hadoop.rest.RestService.createWriter(RestService.java:620)
at org.elasticsearch.hadoop.mr.EsOutputFormat$EsRecordWriter.init(EsOutputFormat.java:175)
at org.elasticsearch.hadoop.hive.EsHiveOutputFormat$EsHiveRecordWriter.write(EsHiveOutputFormat.java:59)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.process(FileSinkOperator.java:987)
at org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator.process(VectorFileSinkOperator.java:111)
at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)
at org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator.process(VectorSelectOperator.java:158)
at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)
at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:125)
at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.closeOp(VectorMapOperator.java:990)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:733)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.close(ExecMapper.java:193)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapRunner.run(ExecMapRunner.java:37)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:465)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
408555 [Thread-57] ERROR org.apache.hadoop.hive.ql.exec.Task -
Task with the most failures(4):
-----
Task ID:
task_1693326922484_0005_m_000000
URL:
http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0005&tipid=task_1693326922484_0005_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.ClassNotFoundException: org.apache.commons.httpclient.HttpConnectionManager
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at org.elasticsearch.hadoop.rest.commonshttp.CommonsHttpTransportFactory.create(CommonsHttpTransportFactory.java:40)
at org.elasticsearch.hadoop.rest.NetworkClient.selectNextNode(NetworkClient.java:99)
at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:82)
at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:58)
at org.elasticsearch.hadoop.rest.RestClient.<init>(RestClient.java:101)
at org.elasticsearch.hadoop.rest.RestService.createWriter(RestService.java:620)
at org.elasticsearch.hadoop.mr.EsOutputFormat$EsRecordWriter.init(EsOutputFormat.java:175)
at org.elasticsearch.hadoop.hive.EsHiveOutputFormat$EsHiveRecordWriter.write(EsHiveOutputFormat.java:59)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.process(FileSinkOperator.java:987)
at org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator.process(VectorFileSinkOperator.java:111)
at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)
at org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator.process(VectorSelectOperator.java:158)
at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)
at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:125)
at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.closeOp(VectorMapOperator.java:990)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:733)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.close(ExecMapper.java:193)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapRunner.run(ExecMapRunner.java:37)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:465)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
408563 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.Driver - FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
在hive的终端下,添加上httpclient的jar包,然后重新执行insert语句
命令如下;
add jar hdfs:///user/hive/warehouse/es_hadoop/commons-httpclient-3.1.jar;
执行成功喽,😄
hive> insert into es_hadoop_cluster select * from hive_test;
Query ID = root_20230830043006_1cf3a042-e5e4-4bec-8cee-49e670ac9b49
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1693326922484_0006, Tracking URL = http://master:8088/proxy/application_1693326922484_0006/
Kill Command = /root/soft/hadoop/hadoop-3.3.0//bin/mapred job -kill job_1693326922484_0006
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
2023-08-30 04:30:17,504 Stage-2 map = 0%, reduce = 0%
2023-08-30 04:30:21,633 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 0.79 sec
MapReduce Total cumulative CPU time: 790 msec
Ended Job = job_1693326922484_0006
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Cumulative CPU: 0.79 sec HDFS Read: 6234 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 790 msec
OK
Time taken: 16.482 seconds
第七步:查询一下映射表,并去es集群上查询数据是否同步成功了
1.查询映射表
nice,又报错了,报错如下;
报错原因分析:我之前做的时候,将解压的所有包都放在hive的lib目录下了,现在看来,只需要一个即可,将其余的都删除
解决方案:删除多余的jar包在hive的lib的目录下
hive> select * from es_hadoop_cluster;
OK
Exception in thread "main" java.lang.ExceptionInInitializerError
at org.elasticsearch.hadoop.rest.RestService.findPartitions(RestService.java:216)
at org.elasticsearch.hadoop.mr.EsInputFormat.getSplits(EsInputFormat.java:414)
at org.elasticsearch.hadoop.hive.EsHiveInputFormat.getSplits(EsHiveInputFormat.java:115)
at org.elasticsearch.hadoop.hive.EsHiveInputFormat.getSplits(EsHiveInputFormat.java:51)
at org.apache.hadoop.hive.ql.exec.FetchOperator.generateWrappedSplits(FetchOperator.java:425)
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextSplits(FetchOperator.java:395)
at org.apache.hadoop.hive.ql.exec.FetchOperator.getRecordReader(FetchOperator.java:314)
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:540)
at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:509)
at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:146)
at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:2691)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:229)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:259)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:188)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:402)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Caused by: java.lang.RuntimeException: Multiple ES-Hadoop versions detected in the classpath; please use only one
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-hive-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-mr-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-pig-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-spark-20_2.11-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-storm-7.17.6.jar
删除掉多余的jar包,然后在执行一次insert 语句,再进行查询,显示如下,在hive中查询是没有问题了
hive> select * from es_hadoop_cluster ;
OK
吴占喜 30 175
令狐冲 50 180
任我行 60 160
吴占喜 30 175
令狐冲 50 180
任我行 60 160
2.在es集群上去进行查询
根据映射表中创建时的索引,进行查询,数据正常展示出来了,nice
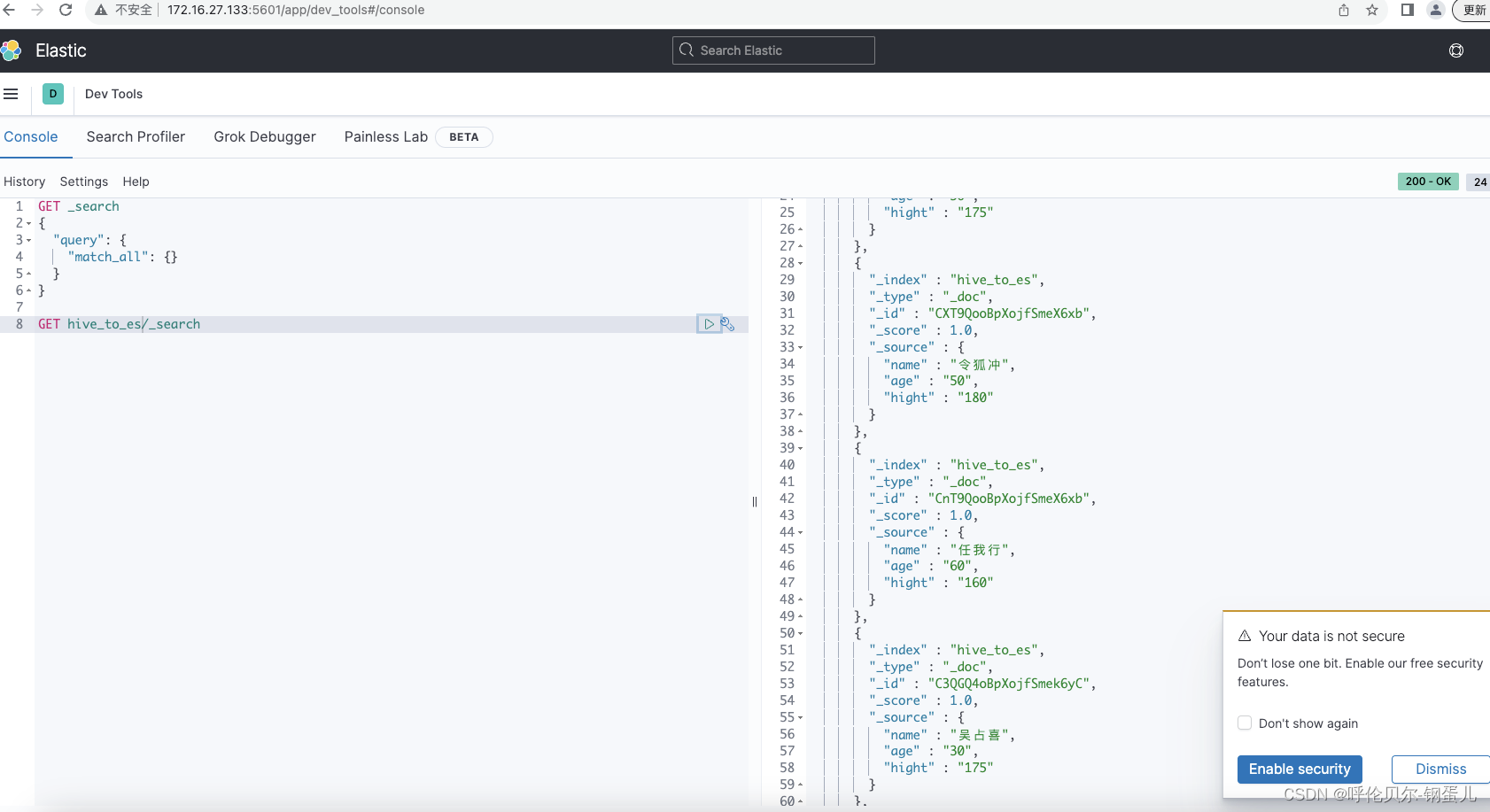
开心,😄,有问题欢迎留言交流