ACmix
论文地址:On the Integration of Self-Attention and Convolution
ACmix探讨了卷积和自注意力这两种强大技术之间的关系,并将两者整合在一起,同时享有双份好处,并显著降低计算开销,可助力现有主干涨点,如Swin、ResNet等。
卷积和自注意力是表示学习的两种强大技术,它们通常被认为是两种彼此不同的同行方法。在本文中,我们表明它们之间存在很强的潜在关系,从某种意义上说,这两种范式的大量计算实际上是通过相同的操作完成的。
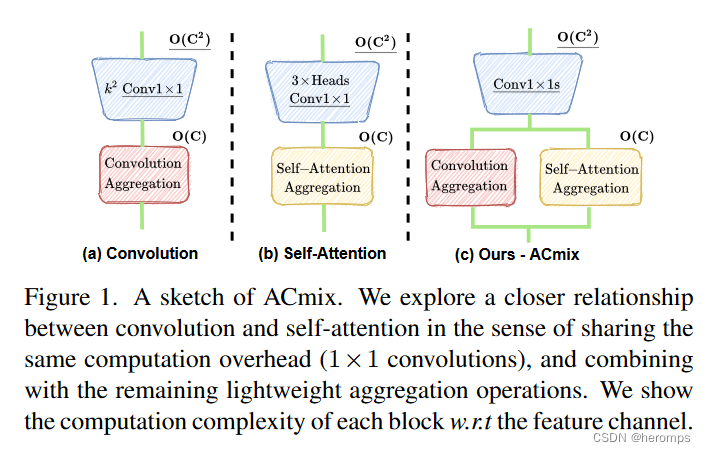
具体来说,我们首先证明内核大小为 k × k 的传统卷积可以分解为
k
2
k^2
k2 个单独的 1 × 1 卷积,然后进行移位和求和操作。将 self-attention 模块中query、key和value的映射解释为多个 1x1 卷积,最后将 self-attention 模块中query、key和value的映射解释为多个 1x1 卷积,然后计算注意力权重和值的聚合。
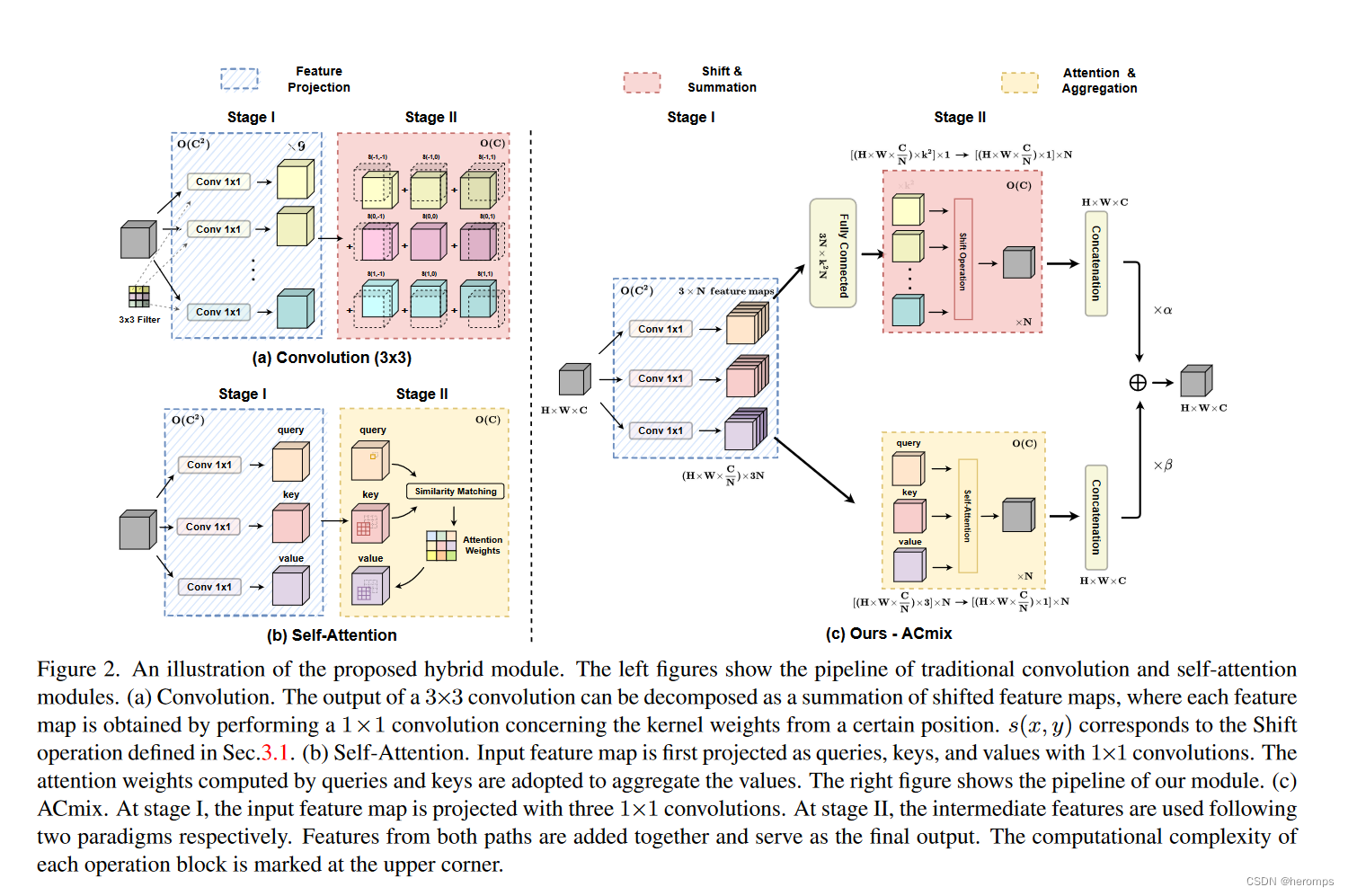
因此,两个模块的第一阶段包括相似的操作。更重要的是,与第二阶段相比,第一阶段贡献了主要的计算复杂度(通道大小的平方)。
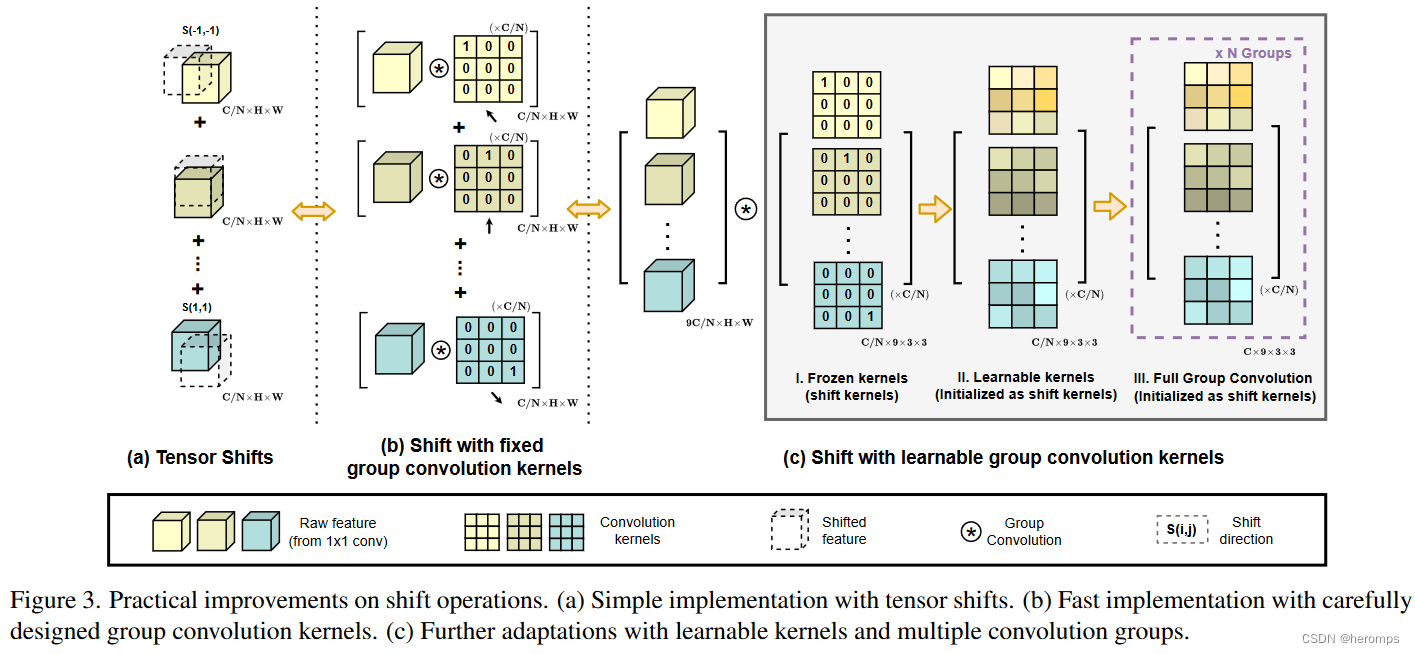
这种观察自然会导致这两个看似不同的范式的优雅整合,即一个混合模型(ACmix),它同时享有自注意力和卷积的好处,同时与纯卷积或自注意力对应物相比具有最小的计算开销。
算法实现的细节可阅读原论文笑话理解













YOLOv5添加ACmix
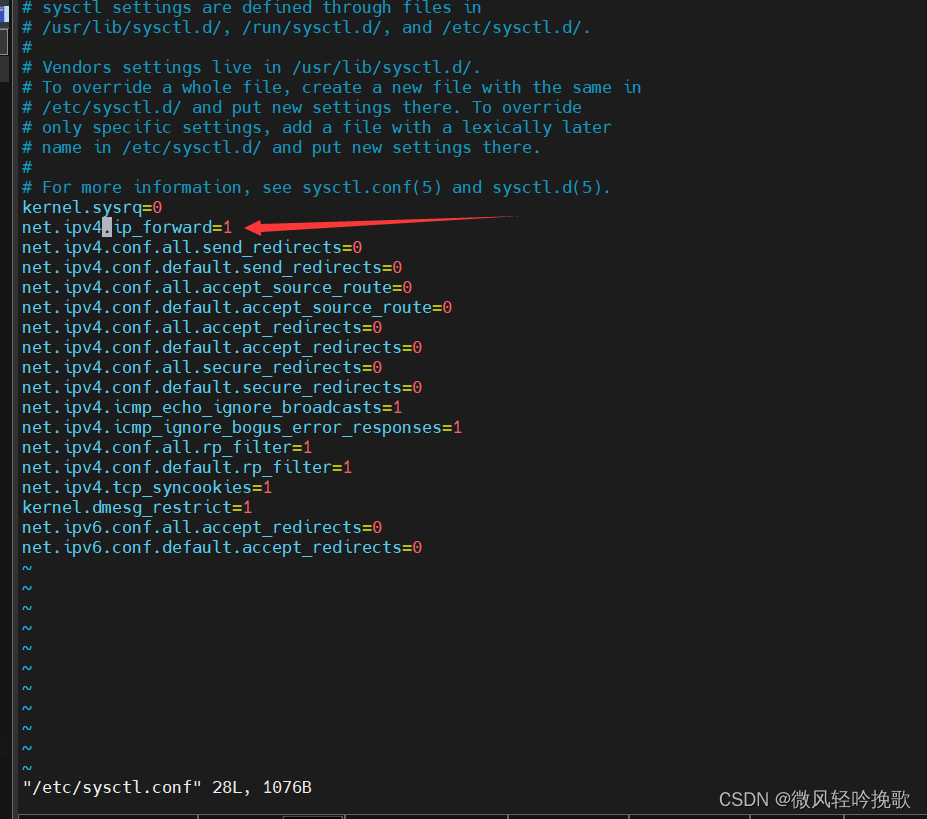
修改yolov5s.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 8 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v7.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, ACmix, [1024]], # 9
[-1, 1, SPPF, [1024, 5]],
]
# YOLOv5 v7.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], #11
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # 13
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [256, 1, 1]], # 15
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # 17
[-1, 3, C3, [256, False]], #(P3/8-small)
[-1, 1, Conv, [256, 3, 2]],# 19
[[-1, 14], 1, Concat, [1]],
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # 23
[-1, 3, C3, [1024, False]], # (P5/32-large)
# [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
[ [ 18, 21, 24 ], 1, Decoupled_Detect, [ nc, anchors ] ], # Detect(P3, P4, P5)
]
添加ACmix模块
在common.py中添加ACmix,代码如下:
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w) * scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
修改yolo.py
在parse_model函数中找到模块加载相关的,并添加ACmix模块。
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, CTR3,
BottleneckCSP, C3, C3SPP, C3Ghost, ACmix, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
运行
修改完成就可以运行了。