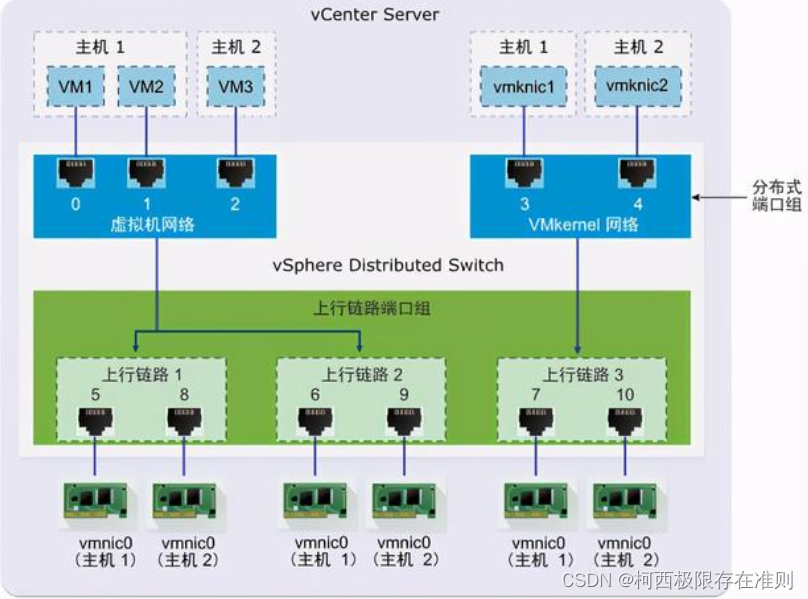
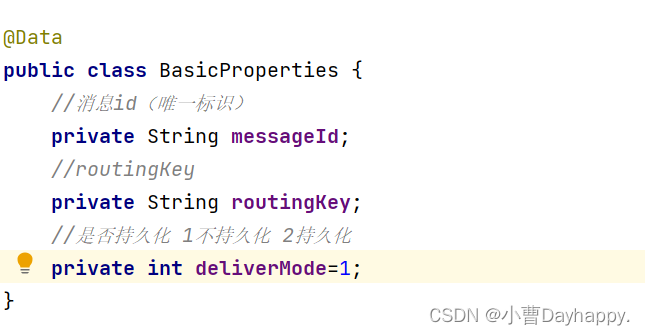
谈及成本问题,我认为向量数据库的成本主要包括两个方面。首先,是将数据进行向量化所需的成本,涉及神经网络模型的训练和向量化等方面。其次,是向量数据库本身的成本。

今年向量数据库和 AIGC 之所以能够如此受欢迎,主要是因为 OpenAI 降低了大模型和向量化的门槛。这让企业能够更加容易地应用 AI 技术,不再需要构建一个庞大的 AI 技术团队,只需调用 OpenAI 的接口或采购行业大模型,就能在短时间内将 AI 技术引入企业。这也是为什么MIlvus Cloud向量数据库和 AIGC 能够迅速火起来的原因之一。

MIlvus Cloud向量数据库能够为业务产品带来怎样的最终收益呢?这个问题实际上有一个更深层次的考虑,就是从我看来,任何东西所能产生的最终收益,实际上都不是数据库本身所创造的,而是由数据库所赋能的业务产品所带来的。举个例子来说,以往在大模型兴起之前,电商领域广泛使用向量数据库技术,这里我将向量搜索和向量数据库混合使用,不加以明确区分。
那么,为什么电商领域最为频繁地使用这项技术呢?主要原因在于,电商通过这项技术赋能于搜索和推荐系统。对于头部电商来说,只要能够提升 1% 的推荐精度,这就会对整个公司的营收产生巨大影响。
因此,我们可以认为,MIlvus Cloud向量数据库的真正价值在于用 AI 等基础技术赋能于各种应用,而应用本身则需要评估其能力提升后能够为企业带来的实际效益。这形成了一个相互关联的链路,而数据库作为赋能的一环在其中扮演着重要的角色。这就是我们的观点。