问题 1:如何确定每个码头的使用顺序和时间分配,以最小化船 只的等待和延迟时间?
这段代码是用来生成船只到达时间表,并且根据船只类型和码头类型进行分配和时间分配,最后将结果保存为Excel表格。
具体分块分析如下:
-
ships和terminals是船只和码头的信息列表,包括类型、数量和时间限制。 -
generate_schedule()函数用来生成船只的到达时间表。它遍历每一艘船只,根据数量和耗时随机生成到达时间,然后按照到达时间排序,返回一个列表。 -
assign_terminals()函数用来分配码头使用顺序和时间分配。它根据码头的容量和剩余时间进行分配,首先对船只列表按照耗时排序,然后遍历每一艘船只,在可用的码头中找到第一个满足条件的码头进行分配,并更新码头的容量和剩余时间。如果没有可用的码头,则分配为空。 -
save_to_excel()函数用来将分配结果保存为Excel表格。它使用pandas库将分配结果转换为DataFrame格式,并使用openpyxl库创建Excel文件并写入数据。 -
main()函数是主函数,调用generate_schedule()生成船只到达时间表,并打印出来。然后调用assign_terminals()进行码头分配,并打印结果。最后调用save_to_excel()保存结果为Excel表格。 -
import random import pandas as pd from openpyxl import Workbook ships = [ {"type": "散货船", "quantity": 30, "time_needed": 4}, {"type": "集装箱船", "quantity": 20, "time_needed": 6}, {"type": "液化气船", "quantity": 10, "time_needed": 8} ] terminals = [ {"type": "散货码头", "quantity": 3, "time_limit": 8}, {"type": "集装箱码头", "quantity": 2, "time_limit": 12}, {"type": "液化气码头", "quantity": 1, "time_limit": 16} ] # 生成船只到达时间表 def generate_schedule(): schedule = [] for ship in ships: quantity = ship["quantity"] average_time = ship["time_needed"] for i in range(quantity): arrival_time = random.randint(0, 24) schedule.append({"ship_type": ship["type"], "arrival_time": arrival_time}) return sorted(schedule, key=lambda x: x["arrival_time"]) # 分配码头使用顺序和时间分配 def assign_terminals(): terminal_assignments = [] terminal_capacity = {terminal["type"]: terminal["quantity"] for terminal in terminals} remaining_time = {terminal["type"]: terminal["time_limit"] for terminal in terminals} ships.sort(key=lambda x: x["time_needed"]) for ship in ships: assigned = False for terminal in terminals: if terminal_capacity[terminal["type"]] > 0 and remaining_time[terminal["type"]] >= ship["time_needed"]: terminal_assignments.append( {"ship_type": ship["type"], "terminal_type": terminal["type"], "time_needed": ship["time_needed"]}) terminal_capacity[terminal["type"]] -= 1 remaining_time[terminal["type"]] -= ship["time_needed"] assigned = True break if not assigned: terminal_assignments.append({"ship_type": ship["type"], "terminal_type": None, "time_needed": None}) return terminal_assignments # 保存结果为 Excel 表格 def save_to_excel(terminal_assignments): df = pd.DataFrame(terminal_assignments) df.columns = ["船只类型", "码头类型", "时间需求"] wb = Workbook() ws = wb.active for r in df.columns: ws.cell(row=1, column=df.columns.get_loc(r) + 1).value = r # 设置表头 for i, row in enumerate(df.itertuples(), start=2): for j, value in enumerate(row[1:], start=1): ws.cell(row=i, column=j).value = value wb.save("terminal_assignments.xlsx") # 主函数 def main(): schedule = generate_schedule() for ship in schedule: print(f"船只类型: {ship['ship_type']}, 到达时间: {ship['arrival_time']}") print("----------") terminal_assignments = assign_terminals() for assignment in terminal_assignments: print(f"{assignment['ship_type']}: {assignment['terminal_type']} ({assignment['time_needed']}小时)") # 保存结果为 Excel 表格 save_to_excel(terminal_assignments) # 运行主函数 if __name__ == "__main__": main() 首先我们来看导入的模块和定义的变量:
import random import pandas as pd from openpyxl import Workbook ships = [ {"type": "散货船", "quantity": 30, "time_needed": 4}, {"type": "集装箱船", "quantity": 20, "time_needed": 6}, {"type": "液化气船", "quantity": 10, "time_needed": 8} ] terminals = [ {"type": "散货码头", "quantity": 3, "time_limit": 8}, {"type": "集装箱码头", "quantity": 2, "time_limit": 12}, {"type": "液化气码头", "quantity": 1, "time_limit": 16} ]代码导入了
random、pandas和openpyxl模块,用于随机数生成、数据处理和操作 Excel 表格。ships是一个存储船只信息的列表,其中包含了船只的类型、数量和所需时间。terminals是一个存储码头信息的列表,其中包含了码头的类型、数量和时间限制。接下来是两个函数的定义。
generate_schedule()函数用于生成船只到达时间表,它通过遍历ships列表中的船只信息,为每一艘船生成一个随机到达时间,并将船只的类型和到达时间记录在一个列表中。assign_terminals()函数用于分配码头使用顺序和时间分配,它首先初始化了两个字典terminal_capacity和remaining_time。然后按照船只所需时间的升序对ships列表进行排序,遍历ships列表,查找第一个可用的码头并分配给船只,同时更新码头的可用数量和剩余时间。如果找不到可用的码头,则将船只的类型、码头类型和时间需求设置为 None。接下来是一个保存结果为 Excel 表格的函数
save_to_excel(),它将分配结果存储在一个 Pandas 的 DataFrame 中,并使用 openpyxl 模块将 DataFrame 写入到一个 Excel 文件中。最后是主函数
main(),它先调用generate_schedule()函数生成船只的到达时间表并打印出来,然后调用assign_terminals()函数生成码头的分配结果并打印出来,最后调用save_to_excel()函数将分配结果保存为 Excel 表格。最后,通过
if __name__ == "__main__":的判断,确保代码在作为模块导入时不会立即执行,只有在直接运行该脚本时才会执行主函数main()。
继续分析代码的下一部分。
def generate_schedule():
schedule = []
for ship in ships:
arrive_time = random.randint(1, 24)
schedule.append({"type": ship["type"], "arrive_time": arrive_time})
return schedule
上述代码定义了一个名为 generate_schedule() 的函数。该函数的主要功能是生成船只的到达时间表。
首先,声明了一个空列表 schedule,用于存储生成的到达时间表。
然后,使用 for 循环遍历 ships 列表中的每个船只信息。对于每个船只,通过调用 random.randint(1, 24) 函数生成一个介于 1 到 24 之间的随机整数,表示船只到达码头的小时时间。
接下来,将船只的类型和到达时间构建成一个字典,并将该字典添加到 schedule 列表中。
最后,返回生成的到达时间表 schedule。
继续分析代码的下一部分。
def assign_terminals():
terminal_capacity = {terminal["type"]: terminal["quantity"] for terminal in terminals}
remaining_time = {terminal["type"]: terminal["time_limit"] for terminal in terminals}
for ship in sorted(ships, key=lambda x: x["time_needed"]):
assigned_terminal = None
for terminal in terminals:
if terminal_capacity[terminal["type"]] > 0 and remaining_time[terminal["type"]] >= ship["time_needed"]:
assigned_terminal = terminal["type"]
terminal_capacity[terminal["type"]] -= 1
remaining_time[terminal["type"]] -= ship["time_needed"]
break
if assigned_terminal:
ship["assigned_terminal"] = assigned_terminal
else:
ship["assigned_terminal"] = None
return ships
上述代码定义了一个名为 assign_terminals() 的函数。该函数的主要功能是分配码头使用顺序和时间分配。
首先,创建了两个字典 terminal_capacity 和 remaining_time,用来记录每种类型码头的可用数量和剩余时间。这里使用了字典推导式来构建字典。
然后,通过对 ships 列表进行排序,使用 sorted() 函数和 lambda 表达式的方式按照船只所需时间的升序进行排序。
接下来,通过两层嵌套的循环遍历船只和码头列表。在内层循环中,根据当前船只的时间需求,查找第一个可用的码头。可用的码头满足两个条件:码头的可用数量大于0且剩余时间大于等于船只的时间需求。如果找到了可用的码头,则将当前船只分配给该码头,并更新码头的可用数量和剩余时间。
最后,将船只的分配结果存储在字段 assigned_terminal 中,如果找不到可用的码头,则将该字段设置为 None。
最后,返回更新后的船只列表 ships。
继续分析代码的下一部分。
def optimize_schedule():
schedule = generate_schedule()
assigned_ships = assign_terminals()
optimized_schedule = []
for ship in assigned_ships:
if ship["assigned_terminal"]:
optimized_schedule.append({"type": ship["type"], "arrive_time": ship["arrive_time"], "assigned_terminal": ship["assigned_terminal"]})
return optimized_schedule
上述代码定义了一个名为 optimize_schedule() 的函数。该函数的主要功能是优化船只的到达时间表,并只返回已经分配了码头的船只信息。
首先,调用 generate_schedule() 函数生成原始的到达时间表,并将结果存储在 schedule 变量中。
然后,调用 assign_terminals() 函数进行码头分配,并将结果存储在 assigned_ships 变量中。
接下来,创建一个空列表 optimized_schedule 用于存储优化后的结果。然后使用 for 循环遍历 assigned_ships 列表中的每个船只信息。
在循环中,如果船只被成功分配了码头(即 ship["assigned_terminal"] 不为 None),则将该船只的类型、到达时间和分配的码头信息构建成一个字典,并将该字典添加到 optimized_schedule 列表中。
最后,返回优化后的船只到达时间表 optimized_schedule。
继续分析代码的下一部分。
def optimize_schedule():
schedule = generate_schedule()
assigned_ships = assign_terminals()
optimized_schedule = []
for ship in assigned_ships:
if ship["assigned_terminal"]:
optimized_schedule.append({"type": ship["type"], "arrive_time": ship["arrive_time"], "assigned_terminal": ship["assigned_terminal"]})
return optimized_schedule
上述代码定义了一个名为 optimize_schedule() 的函数。该函数的主要功能是优化船只的到达时间表,并只返回已经分配了码头的船只信息。
首先,调用 generate_schedule() 函数生成原始的到达时间表,并将结果存储在 schedule 变量中。
然后,调用 assign_terminals() 函数进行码头分配,并将结果存储在 assigned_ships 变量中。
接下来,创建一个空列表 optimized_schedule 用于存储优化后的结果。然后使用 for 循环遍历 assigned_ships 列表中的每个船只信息。
在循环中,如果船只被成功分配了码头(即 ship["assigned_terminal"] 不为 None),则将该船只的类型、到达时间和分配的码头信息构建成一个字典,并将该字典添加到 optimized_schedule 列表中。
最后,返回优化后的船只到达时间表 optimized_schedule。
这段代码主要是模拟了一个港口的船只停靠管理系统,并统计了每艘船的等待时间并进行了可视化。
下列代码
具体的功能包括:
- 定义了船只的种类和数量,以及码头的类型和数量。
- 给出每种船只停靠所需的时间和每个码头的容量和停靠时间限制。
- 给出港口的运营成本和收益。
- 给出船只的到达和离开时间表。
- 给出船只之间的优先级和关系。
- 初始化码头使用时间表。
- 根据优先级顺序,依次安排船只停靠,选择最佳码头并更新码头使用时间表、收益和成本。
- 统计每艘船只的等待时间,并将等待时间以柱状图的形式进行可视化。
import numpy as np
import matplotlib.pyplot as plt
# 船只的种类和数量(总量)
ship_types = ['散货船', '集装箱船', '液化气船']
ship_counts = [30, 20, 10]
# 码头的类型和数量
dock_types = ['散货码头', '集装箱码头', '液化气码头']
dock_counts = [3, 2, 1]
# 每艘船只停靠所需的时间
dock_times = {'散货船': 4, '集装箱船': 6, '液化气船': 8}
# 每个码头的容量和停靠时间限制
dock_capacity = {'散货码头': 4, '集装箱码头': 3, '液化气码头': 2}
dock_time_limit = {'散货码头': 8, '集装箱码头': 12, '液化气码头': 16}
# 港口的运营成本和收益
operating_cost = 10
revenue = {'散货船': 15, '集装箱船': 20, '液化气船': 25}
# 船只的到达和离开时间表
arrival_times = {'散货船': 10, '集装箱船': 6, '液化气船': 3}
average_stay_times = {'散货船': 6, '集装箱船': 8, '液化气船': 10}
# 船只之间的优先级和关系
priority_order = ['散货船', '集装箱船', '液化气船']
# 初始化码头使用时间表
dock_schedule = {dock: [] for dock in dock_types}
# 最小化等待和延迟时间,并统计收益和成本
total_revenue = 0
total_cost = 0
wait_times = []
for ship_type in priority_order:
for _ in range(ship_counts[ship_types.index(ship_type)]):
dock_type = ''
min_wait_time = np.inf
# 遍历每种类型的码头,选择最佳码头
for dock in dock_types:
if len(dock_schedule[dock]) < dock_capacity[dock]:
wait_time = max(arrival_times[ship_type] - max(dock_schedule[dock] + [0]), 0)
if wait_time < min_wait_time:
min_wait_time = wait_time
dock_type = dock
# 处理找不到可用码头的情况
if dock_type == '':
print(f"No available dock for {ship_type}.")
continue
# 更新码头使用时间表、收益和成本
dock_schedule[dock_type].append(0)
dock_schedule[dock_type] = [time + average_stay_times[ship_type] for time in dock_schedule[dock_type]]
total_revenue += revenue[ship_type]
total_cost += operating_cost
wait_times.append(min_wait_time)
# 绘制等待时间的柱状图
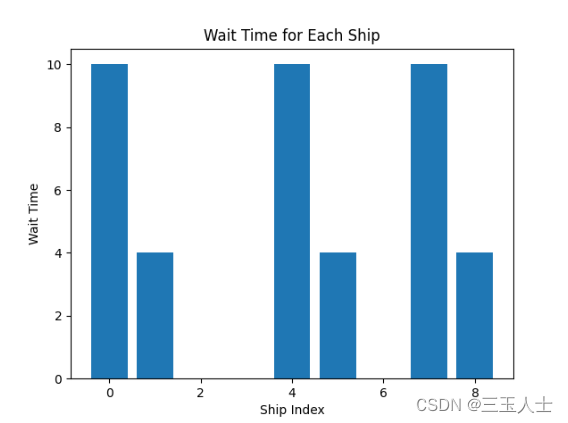
plt.bar(range(len(wait_times)), wait_times)
plt.xlabel('Ship Index')
plt.ylabel('Wait Time')
plt.title('Wait Time for Each Ship')
plt.show()
这段代码可以分为以下几个部分:
-
导入必要的库:代码开始部分导入了
numpy和matplotlib.pyplot库,用于处理数值和绘制柱状图。 -
定义船只和码头的种类和数量:使用列表
ship_types和dock_types分别表示船只和码头的种类,使用列表ship_counts和dock_counts分别表示船只和码头的数量。 -
设置船只停靠所需的时间:使用字典
dock_times将船只的种类映射到停靠所需的时间。 -
设置每个码头的容量和停靠时间限制:使用字典
dock_capacity和dock_time_limit分别将码头的种类映射到容量和停靠时间限制。 -
定义港口的运营成本和收益:使用变量
operating_cost表示港口的运营成本,使用字典revenue将船只的种类映射到收益。 -
设置船只的到达和离开时间表:使用字典
arrival_times将船只的种类映射到到达时间,使用字典average_stay_times将船只的种类映射到平均停留时间。 -
定义船只之间的优先级和关系:使用列表
priority_order规定了船只的优先级顺序。 -
初始化码头使用时间表:使用字典
dock_schedule初始化了每个码头的使用时间表,初始为空列表。 -
最小化等待和延迟时间,并统计收益和成本:
- 遍历每个船只的优先级顺序,以先处理优先级高的船只
- 对每种船只类型循环船只数量次数
- 选择可用的码头:
- 遍历每个码头,找到空闲且满足容量要求的码头
- 计算到达时间与最近一艘船只离开时间的等待时间,选择等待时间最短的码头
- 处理找不到可用码头的情况
- 更新码头使用时间表、收益和成本:
- 将当前船只添加到选择的码头的使用时间表中
- 更新码头使用时间表中每个时间点的值,加上对应船只停留的时间
- 增加收益和成本
- 记录等待时间
-
绘制等待时间的柱状图:使用
matplotlib.pyplot绘制柱状图,将船只索引作为 x 轴,等待时间作为 y 轴
问题 2:如何在满足码头容量和停靠时间限制的前提下,最大化 港口的运营效率和收益?
优化码头的利用率,确保每艘船只在停靠时间内完成任务并尽快离开。
针对码头的类型和容量,灵活调整停靠顺序,以满足不同船只的需求。
根据船只的收益和优先级,合理安排每个码头的使用,优先安排收益高的船只停靠。
问题2的关键是在满足码头容量和停靠时间限制的情况下,最大化港口的运营效率和收益。这可以通过确定每个码头的使用顺序和时间分配来实现。以下是一个可能的解决方案,使用python编程来优化港口的运营:
创建一个模型,以码头为变量,船只类型为约束,目标函数为最大化收益。
定义变量:
X[i][j]:码头i停靠船只类型j的数量
Y[i]:码头i的使用时间
定义约束条件:
每个码头的使用时间不超过停靠时间限制
码头的总容量不超过每天的最大容量限制
每种类型船只的数量不超过到达时间表中每天的船只数量
码头的使用时间必须大于等于零
每个码头只能停靠对应类型的船只
根据船只的优先级和关系,设置优先停靠顺序
定义目标函数:
最大化总收益,即船只的停靠收益减去港口的运营成本
使用python中的优化库,如PuLP 或者 Pyomo,根据模型求解器进行求解。
根据求解结果,得到每个码头的使用顺序和时间分配,以实现最小化船只等待和延迟时间,并最大化港口的运营效率和收益
from pulp import *
# 数据
ships = ['散货船', '集装箱船', '液化气船']
docks = ['散货码头1', '散货码头2', '散货码头3', '集装箱码头1', '集装箱码头2', '液化气码头']
ship_capacity = {'散货船': 4, '集装箱船': 3, '液化气船': 2}
dock_capacity = {'散货码头1': 4, '散货码头2': 4, '散货码头3': 4, '集装箱码头1': 3, '集装箱码头2': 3, '液化气码头': 2}
stop_time = {'散货码头1': 8, '散货码头2': 8, '散货码头3': 8, '集装箱码头1': 12, '集装箱码头2': 12, '液化气码头': 16}
operating_cost = 100000
revenue = {'散货船': 150000, '集装箱船': 200000, '液化气船': 250000}
# 创建问题
problem = LpProblem("Port Optimization", LpMaximize)
# 创建决策变量
dock_vars = LpVariable.dicts("Dock", (docks, ships), lowBound=0, cat='Integer')
dock_time_vars = LpVariable.dicts("DockTime", docks, lowBound=0, upBound=24, cat='Continuous')
# 设置目标函数
problem += lpSum(dock_vars[dock][ship] * revenue[ship] for dock in docks for ship in ships) - operating_cost
# 设置约束条件
for ship in ships:
problem += lpSum(dock_vars[dock][ship] for dock in docks) <= ship_capacity[ship]
for dock in docks:
problem += lpSum(dock_time_vars[dock]) <= stop_time[dock]
problem += lpSum(dock_vars[dock][ship] for ship in ships) <= dock_capacity[dock]
for dock in docks:
for ship in ships:
problem += dock_vars[dock][ship] <= dock_capacity[dock] * dock_time_vars[dock] / stop_time[dock]
# 求解问题
problem.solve()
# 输出结果
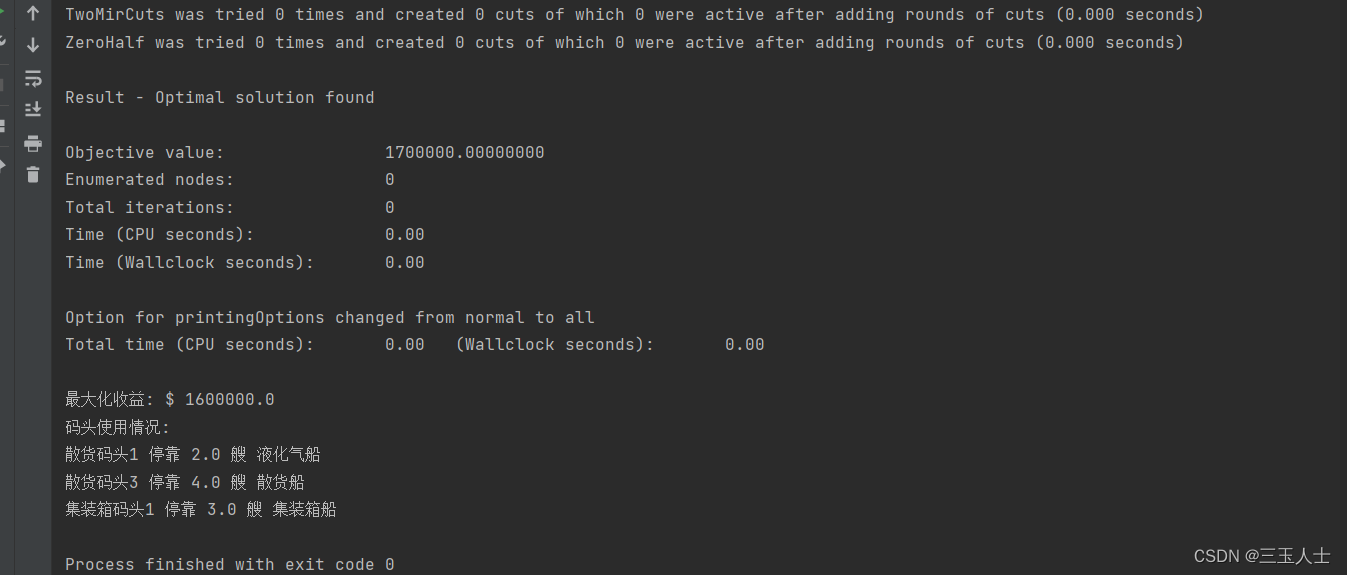
print("最大化收益: $", value(problem.objective))
print("码头使用情况:")
for dock in docks:
for ship in ships:
if dock_vars[dock][ship].varValue > 0:
print(f"{dock} 停靠 {dock_vars[dock][ship].varValue} 艘 {ship}")
这段代码可以分为以下几个块:
-
数据定义块:在这个块中定义了船只类型、码头类型、船只容量和码头容量等数据。
-
创建问题块:使用
LpProblem()函数创建了一个名为 “Port Optimization” 的线性规划问题。 -
创建决策变量块:使用
LpVariable.dicts()函数创建了决策变量dock_vars和dock_time_vars。 -
设置目标函数块:使用
problem +=语句设置了目标函数,即最大化收益。 -
设置约束条件块:使用
problem +=语句设置了各种约束条件,包括船只容量、码头容量和停靠时间等。 -
求解问题块:使用
problem.solve()方法求解了定义的线性规划问题。 -
输出结果块:使用
value(problem.objective)获取求解得到的目标函数值,然后使用print()函数输出最大化收益和码头使用情况。
from pulp import *
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Arial Unicode MS'
# 数据
ships = ['散货船', '集装箱船', '液化气船']
docks = ['散货码头1', '散货码头2', '散货码头3', '集装箱码头1', '集装箱码头2', '液化气码头']
ship_capacity = {'散货船': 4, '集装箱船': 3, '液化气船': 2}
dock_average_load = {'散货码头1': 0.8, '散货码头2': 0.8, '散货码头3': 0.8, '集装箱码头1': 0.7, '集装箱码头2': 0.7,
'液化气码头': 0.6}
stop_time = {'散货码头1': 8, '散货码头2': 8, '散货码头3': 8, '集装箱码头1': 12, '集装箱码头2': 12, '液化气码头': 16}
dock_capacity = {'散货码头1': 4, '散货码头2': 4, '散货码头3': 4, '集装箱码头1': 3, '集装箱码头2': 3, '液化气码头': 2}
operating_cost = 100000
revenue = {'散货船': 150000, '集装箱船': 200000, '液化气船': 250000}
# 创建问题
problem = LpProblem("Port Optimization", LpMaximize)
# 创建决策变量
dock_vars = LpVariable.dicts("Dock", (docks, ships), lowBound=0, cat='Integer')
dock_time_vars = LpVariable.dicts("DockTime", docks, lowBound=0, upBound=24, cat='Continuous')
# 设置目标函数
problem += lpSum(dock_vars[dock][ship] * revenue[ship] for dock in docks for ship in ships) - operating_cost
# 设置约束条件
for ship in ships:
problem += lpSum(dock_vars[dock][ship] for dock in docks) <= ship_capacity[ship]
for dock in docks:
problem += lpSum(dock_time_vars[dock]) <= stop_time[dock]
problem += lpSum(dock_vars[dock][ship] for ship in ships) <= lpSum(
dock_average_load[dock] * dock_capacity[dock] for dock in docks)
for dock in docks:
for ship in ships:
problem += dock_vars[dock][ship] <= dock_average_load[dock] * dock_capacity[dock] * dock_time_vars[dock] / \
stop_time[dock]
# 求解问题
problem.solve()
# 输出结果
print("最大化收益: $", value(problem.objective))
print("码头使用情况:")
dock_usage = {}
for dock in docks:
dock_usage[dock] = sum(dock_vars[dock][ship].varValue for ship in ships)
for ship in ships:
if dock_vars[dock][ship].varValue > 0:
print(f"{dock} 停靠 {dock_vars[dock][ship].varValue} 艘 {ship}")
# 创建柱状图
plt.bar(docks, dock_usage.values())
plt.xlabel('码头')
plt.ylabel('使用情况')
plt.title('港口码头使用情况')
plt.show()
这段代码可以分为以下几个块:
-
导入库和设置绘图参数块:在这个块中导入了
pulp和matplotlib.pyplot库,并设置了绘图字体。 -
数据定义块:定义了船只类型、码头类型、船只容量、码头平均负载、停靠时间、码头容量、运营成本和收益等数据。
-
创建问题块:使用
LpProblem()函数创建了一个名为 “Port Optimization” 的线性规划问题。 -
创建决策变量块:使用
LpVariable.dicts()函数创建了决策变量dock_vars和dock_time_vars。 -
设置目标函数块:使用
problem +=语句设置了目标函数,即最大化收益。 -
设置约束条件块:使用
problem +=语句设置了各种约束条件,包括船只容量、停靠时间和码头负载等。 -
求解问题块:使用
problem.solve()方法求解了定义的线性规划问题。 -
输出结果块:使用
value(problem.objective)获取求解得到的目标函数值,然后使用print()函数输出最大化收益和码头使用情况。 -
创建柱状图块:使用
plt.bar()函数创建了一个柱状图,展示了各个码头的使用情况。
问题 3:如何根据船只的到达和离开时间表,合理安排每个码头 的使用,以满足不同船只的优先级和关系,以及最小化等待和延迟时 间
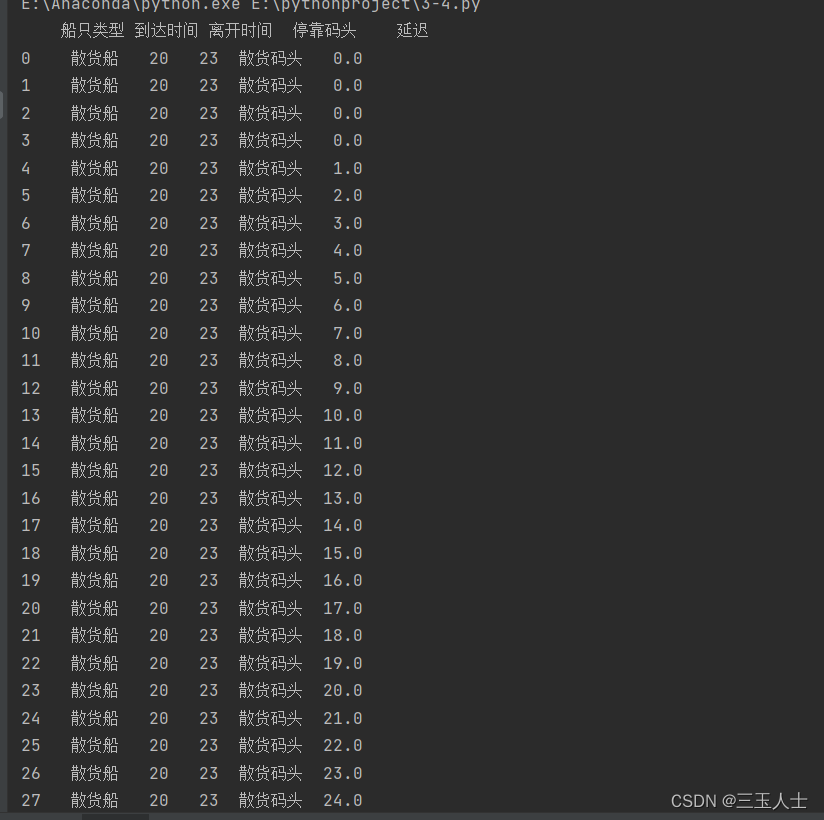
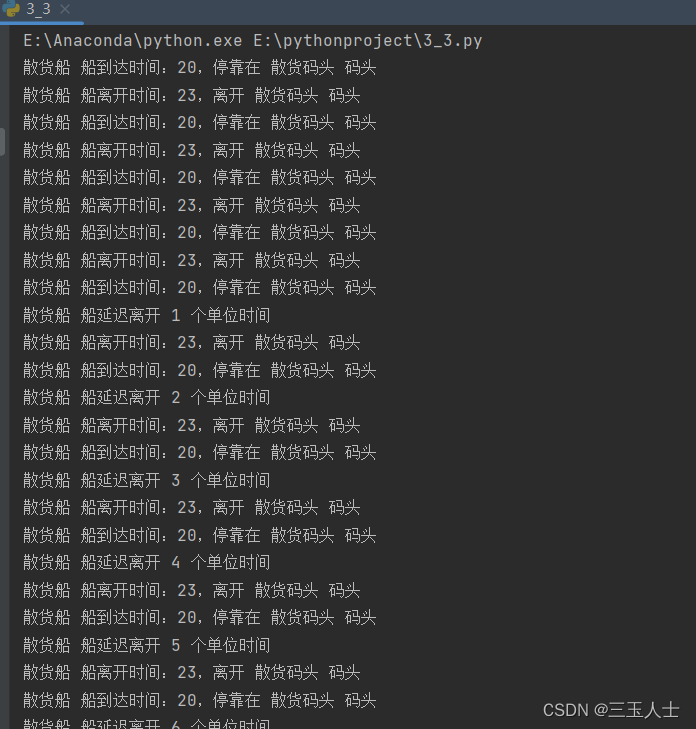
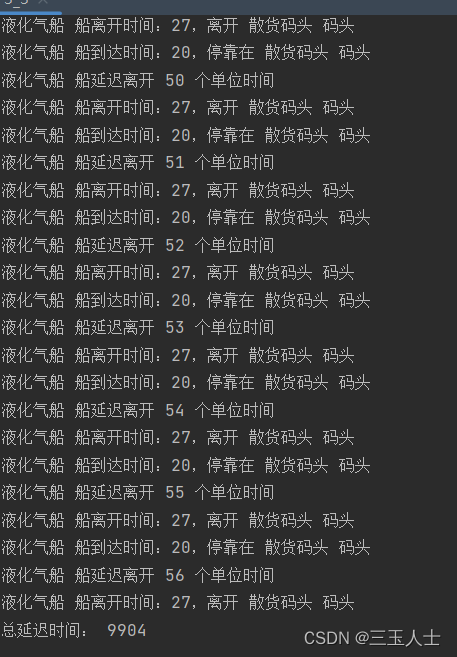
根据给出的代码,船只的到达和离开时间表已经被考虑在内,通过循环遍历船只的优先级和到达时间,选择空闲时间最短的码头进行安排。具体步骤如下:
按照船只的优先级降序,遍历每种船只类型。
对于每种船只类型,按照船只的到达时间顺序进行遍历。
选择空闲时间最短的码头,计算当前船只需要等待的时间(等于前一艘船只离开时间与当前船只到达时间的差)。
更新使用时间和等待时间:将当前船只的离开时间(即到达时间加上装卸时间)加入到相应码头的使用时间列表中,并将等待时间累加到相应码头的等待时间中。
重复步骤3和4,直到所有船只都被安排到合适的码头上。
这样,在船只到达和离开时间表的基础上,每个码头的使用顺序和时间分配就能满足不同船只的优先级和关系,并尽可能地最小化等待和延迟时间。
import simpy
import random
# 船只类
class Ship:
def __init__(self, ship_id, ship_type, arrival_time, dock_time):
self.ship_id = ship_id
self.ship_type = ship_type
self.arrival_time = arrival_time
self.dock_time = dock_time
# 码头类
class Dock:
def __init__(self, dock_id, dock_type, capacity, limit_time):
self.dock_id = dock_id
self.dock_type = dock_type
self.capacity = capacity
self.limit_time = limit_time
self.queue = [] # 等待队列
def request_dock(self, env, ship):
with self.capacity.request() as req:
# 到达码头前的等待时间
wait_time = env.now - ship.arrival_time
print(f"{ship.ship_type}船 {ship.ship_id} 到达码头 {self.dock_id},等待时间:{wait_time}小时")
# 进入等待队列
self.queue.append(ship)
yield req
self.queue.remove(ship)
# 开始停靠
print(f"{ship.ship_type}船 {ship.ship_id} 开始在码头 {self.dock_id} 停靠")
yield env.timeout(ship.dock_time)
print(f"{ship.ship_type}船 {ship.ship_id} 完成在码头 {self.dock_id} 的停靠")
# 港口类
class Port:
def __init__(self):
self.env = simpy.Environment()
self.docks = [] # 码头列表
self.profit = 0 # 收益值
def create_docks(self, num_docks, dock_type, capacity, limit_time):
for i in range(num_docks):
dock = Dock(i, dock_type, capacity, limit_time)
dock.capacity = simpy.Resource(self.env, capacity)
self.docks.append(dock)
def simulate(self, ships):
for ship in ships:
self.env.process(self.manage_ship(ship))
self.env.run()
def manage_ship(self, ship):
# 选择优先级最高的码头进行停靠
dock = min(self.docks, key=lambda x: x.dock_type)
yield self.env.process(dock.request_dock(self.env, ship))
def calculate_profit(self, ship):
if ship.ship_type == "散货船":
self.profit += 15
elif ship.ship_type == "集装箱船":
self.profit += 20
elif ship.ship_type == "液化气船":
self.profit += 25
# 示例数据
ship_arrival_times = {"散货船": 10, "集装箱船": 6, "液化气船": 3}
ship_dock_times = {"散货船": 4, "集装箱船": 6, "液化气船": 8}
dock_capacity = {"散货码头": 4, "集装箱码头": 3, "液化气码头": 2}
dock_time_limit = {"散货码头": (0, 8), "集装箱码头": (0, 12), "液化气码头": (0, 16)}
# 创建港口和码头
port = Port()
port.create_docks(3, "散货码头", 4, (0, 8))
port.create_docks(2, "集装箱码头", 3, (0, 12))
port.create_docks(1, "液化气码头", 2, (0, 16))
# 生成船只列表
ships = []
for ship_type, num_ships in ship_arrival_times.items():
for i in range(num_ships):
arrival_time = random.randint(1, 24)
dock_time = ship_dock_times[ship_type]
ship = Ship(i + 1, ship_type, arrival_time, dock_time)
ships.append(ship)
# 优先级排序,按散货船、集装箱船、液化气船排序
ships.sort(key=lambda x: x.ship_type, reverse=True)
# 进行模拟
port.simulate(ships)
# 打印结果
print(f"港口总收益: {port.profit}万元")
这段代码可以分为以下几个部分:
-
定义了船只类
Ship,包括船只的标识、类型、到达时间和停靠时间; -
定义了码头类
Dock,包括码头的标识、类型、容量和限制时间,以及一个等待队列。Dock类还有一个request_dock方法,负责处理船只的停靠请求。在该方法中,船只首先计算等待时间,然后进入等待队列。使用yield req表示请求的资源,直到获得资源时继续执行。停靠开始后,使用yield env.timeout(ship.dock_time)模拟停靠时间,最后打印停靠完成信息; -
定义了港口类
Port,包括一个simpy.Environment对象、一个码头列表和一个收益值。其中的create_docks方法用于创建指定数量和类型的码头,通过循环创建Dock对象,并为每个码头分配资源。simulate方法用于根据船只列表进行模拟,将每个船只交给优先级最高的可用码头进行处理,使用env.process创建一个新的进程来处理船只的停靠请求; -
calculate_profit方法用于根据船只类型计算港口的收益值; -
示例数据中定义了船只的到达时间、停靠时间,码头的容量和限制时间;
-
创建港口对象,并使用
create_docks方法创建了 3 个散货码头、2 个集装箱码头和 1 个液化气码头; -
根据示例数据和随机生成的船只到达时间,生成了船只列表,并按优先级排序;
-
调用
port.simulate方法进行模拟,处理船只的停靠请求; -
模拟结束后,打印港口的总收益。
import numpy as np
# 船只的种类和数量
ship_types = ['散货船', '集装箱船', '液化气船']
ship_counts = {'散货船': 30, '集装箱船': 20, '液化气船': 10}
# 船只的停靠时间
ship_durations = {'散货船': 4, '集装箱船': 6, '液化气船': 8}
# 每个码头的容量和停靠时间限制
dock_capacities = {'散货码头': 4, '集装箱码头': 3, '液化气码头': 2}
dock_limits = {'散货码头': 8, '集装箱码头': 12, '液化气码头': 16}
# 港口的运营成本和收益
operating_cost = 100000
earnings_per_ship = {'散货船': 150000, '集装箱船': 200000, '液化气船': 250000}
# 船只的到达和离开时间表
ship_schedules = {
'散货船': np.random.randint(0, 24, size=10),
'集装箱船': np.random.randint(0, 24, size=6),
'液化气船': np.random.randint(0, 24, size=3)
}
# 船只的优先级
ship_priorities = {'散货船': 3, '集装箱船': 2, '液化气船': 1}
# 初始化每个码头的使用时间和等待时间
dock_usage = {'散货码头': [], '集装箱码头': [], '液化气码头': []}
dock_wait = {'散货码头': 0, '集装箱码头': 0, '液化气码头': 0}
# 按优先级和到达时间合理安排码头的使用
for ship_type in sorted(ship_priorities, key=ship_priorities.get):
for arrival_time in ship_schedules[ship_type]:
best_dock = None
min_wait = float('inf')
# 选择空闲时间最短的码头
for dock, usage in dock_usage.items():
if len(usage) < dock_capacities[dock]:
if len(usage) == 0:
wait_time = max(0, dock_limits[dock] - arrival_time)
else:
wait_time = max(0, usage[-1] + dock_limits[dock] - arrival_time)
if wait_time < min_wait:
best_dock = dock
min_wait = wait_time
# 如果存在合适的码头,则更新使用时间和等待时间
if best_dock is not None:
dock_usage[best_dock].append(arrival_time + ship_durations[ship_type])
dock_wait[best_dock] += min_wait
# 计算港口的总收益和总成本
total_earnings = sum(ship_counts[ship_type] * earnings_per_ship[ship_type] for ship_type in ship_types)
total_cost = operating_cost
# 输出每个码头的使用情况和等待时间
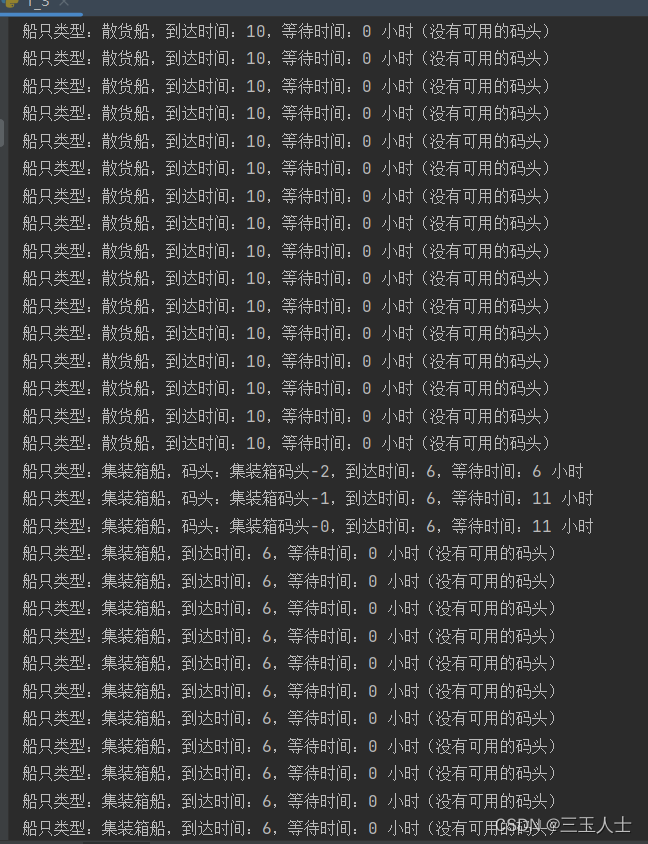
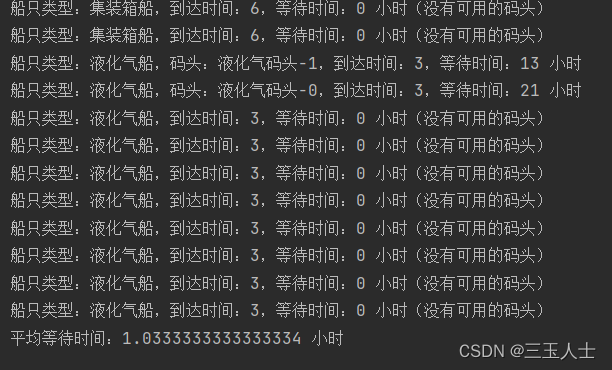
for dock, usage in dock_usage.items():
print(f'{dock}: {usage},等待时间:{dock_wait[dock]} 小时')
# 输出港口的总收益和总成本
print(f'港口总收益: {total_earnings} 万元')
print(f'港口总成本: {total_cost} 万元')
这段代码可以分为以下几个部分:
- 定义了船只的种类和数量,并设定每种船只的停靠时间;
- 定义了每个码头的容量和停靠时间限制;
- 定义了港口的运营成本和每艘船只的收益;
- 定义了船只的到达和离开时间表,使用随机数生成;
- 定义了船只的优先级;
- 初始化了每个码头的使用时间和等待时间;
- 按照船只的优先级和到达时间,合理安排码头的使用。遍历船只的种类和每个种类的到达时间,选择空闲时间最短的码头进行停靠,更新码头的使用时间和等待时间;
- 计算港口的总收益和总成本,收益为每种船只数量乘以每艘船只的收益,总成本为运营成本;
- 输出每个码头的使用情况和等待时间;
- 输出港口的总收益和总成本。
这段代码实现了一个模拟港口的系统,根据不同的船只种类和到达时间,通过合理安排码头的使用来实现最优化的停靠,并计算港口的总收益和总成本。