Pytorch 给我们提供了一个方法,方便我们加载数据,我们可以使用这个框架,去加载我们的数据。看下伪代码:
# ================================================================== #
# Input pipeline for custom dataset #
# ================================================================== #
# You should build your custom dataset as below.
class CustomDataset(torch.utils.data.Dataset):
def __init__(self):
# TODO
# 1. Initialize file paths or a list of file names.
pass
def __getitem__(self, index):
# TODO
# 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open).
# 2. Preprocess the data (e.g. torchvision.Transform).
# 3. Return a data pair (e.g. image and label).
pass
def __len__(self):
# You should change 0 to the total size of your dataset.
return 0
# You can then use the prebuilt data loader.
custom_dataset = CustomDataset()
train_loader = torch.utils.data.DataLoader(dataset=custom_dataset,
batch_size=64,
shuffle=True)
__getitem__:返回一个样本__len__:返回样本的数量
首先先创建一个文件夹,将图片放在同一个文件夹下。
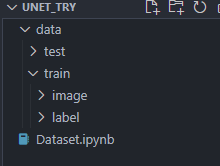
导入库文件
import torch
import torchvision.datasets
from torch.utils.data import Dataset
import os
from PIL import Image
import numpy as np
import torchvision.transforms as transforms
图片数据预处理
预处理在机器学习和深度学习中起着重要的作用,它包括对输入数据进行一系列的变换和标准化操作。以下是为什么需要预处理的一些常见原因:
- 数据归一化/标准化:预处理过程中的归一化/标准化步骤有助于将数据的范围缩放到一个可接受的范围,以便更好地适应模型的训练。这有助于提高模型的收敛速度,并可以避免梯度消失或爆炸的问题。
- 数据增强:通过应用一系列的图像变换,如旋转、裁剪、平移、翻转等,可以扩增训练数据集,从而增加模型的泛化能力。数据增强可以减轻过拟合问题,并提高模型对多样性数据的鲁棒性。
- 数据格式转换:预处理可以将数据从原始格式(如图像文件、文本文件等)转换为模型所需的张量格式。例如,在计算机视觉任务中,图像通常被转换为张量,并进行通道重新排列、大小调整等操作。
- 噪声去除和数据清洗:预处理过程也可以用于去除数据中的噪声、异常值或无效样本。这有助于提高数据质量,并减少对模型的负面影响。
来自chatGPT
# 预处理
transform = transforms.Compose([ # 使用 Compose 可以将这些操作串联在一起
transforms.Resize((224,224)), # 调整图片大小
transforms.ToTensor(), # 将图片转换为Tensor对象,方便作为神经网络的输入
transforms.Normalize( (0.1307, ), (0.3081, )) # 对图片进行归一化
])
定义Dataset类
__init__
__init__里面是初始化方法,例如传入图片的路径,或者要不要选择预处理等。
# 初始化:指定路径,是否进行预处理等
def __init__(self, path, transform = None) -> None:
super().__init__()
# os.listdir : 会将data下面的image中所有的文件读取,放在imgs里面
img_path = os.path.join(path, "image/") # 进行拼接 得到 data/train/image/
imgs = os.listdir(img_path)
# 取出path下所有的文件
self.imgs = [os.path.join(img_path, img) for img in imgs]
self.transforms = transform # 图像预处理
__getitem__
__getitem__用于返回一个样本,返回之前做的处理数据的操作,也在__getitem__里面。
def __getitem__(self, index): # 读取图片
img_path = self.imgs[index] # 图片路径
label_path = img_path.replace("image", "label") # 得到label文件夹下数据
label = Image.open(label_path)
data = Image.open(img_path)
if self.transforms: # 图片预处理
data = self.transforms(data)
return data, label # tuple类型
__len__
__len__返回样本个数(图片路径的个数)
def __len__(self):
return len(self.imgs)
测试
全部代码
import torch
import torchvision.datasets
from torch.utils.data import Dataset
import os
from PIL import Image
import numpy as np
import torchvision.transforms as transforms
# 预处理
data_transform = transforms.Compose([ # 使用 Compose 可以将这些操作串联在一起
transforms.Resize((224,224)), # 调整图片大小
transforms.ToTensor(), # 将图片转换为Tensor对象,方便作为神经网络的输入
transforms.Normalize( (0.1307, ), (0.3081, )) # 对图片进行归一化
])
class Data(Dataset):
# 初始化:指定路径,是否进行预处理等
def __init__(self, path, transform = None) -> None:
super().__init__()
# os.listdir : 会将data下面的image中所有的文件读取,放在imgs里面
img_path = os.path.join(path, "image/") # 进行拼接 得到 data/train/image/
imgs = os.listdir(img_path)
# 取出path下所有的文件
self.imgs = [os.path.join(img_path, img) for img in imgs]
self.transforms = transform # 图像预处理
def __getitem__(self, index): # 读取图片
img_path = self.imgs[index] # 图片路径
label_path = img_path.replace("image", "label") # 得到label文件夹下数据
label = Image.open(label_path)
data = Image.open(img_path)
if self.transforms: # 图片预处理
data = self.transforms(data)
label = self.transforms(label)
return data, label # tuple类型
def __len__(self):
return len(self.imgs)
# ts1 = Data('data/train/', transform=data_transform)
# print(type(ts1[0]))
# print(ts1[0])
# print(len(ts1))
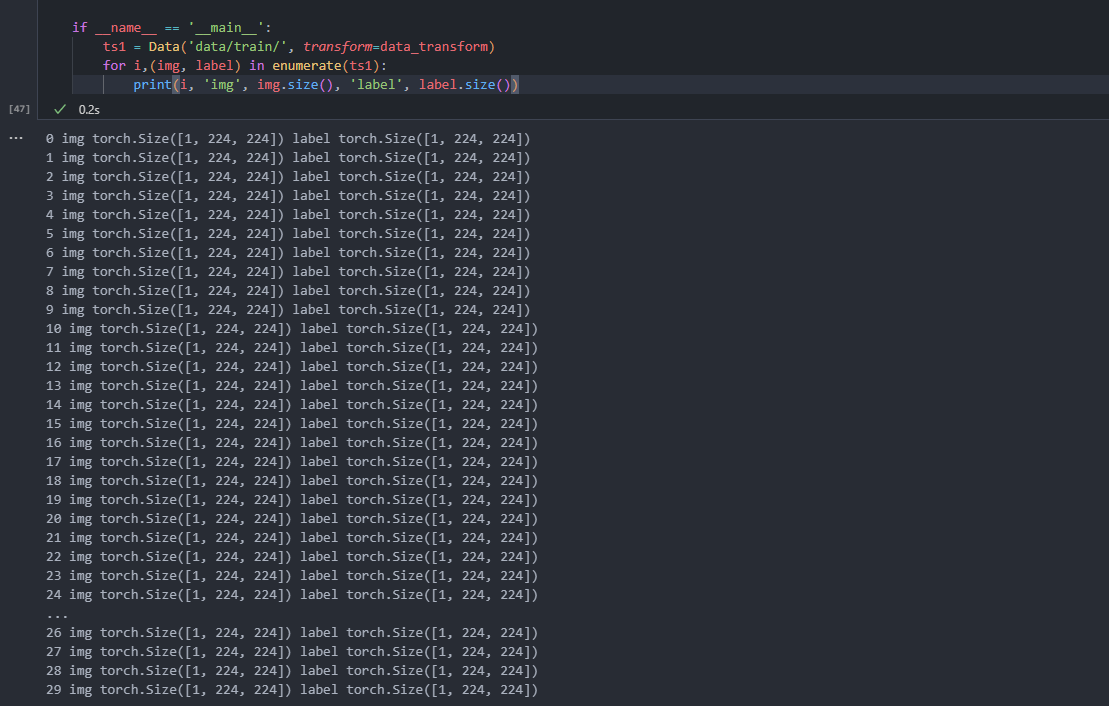
if __name__ == '__main__':
ts1 = Data('data/train/', transform=data_transform)
for i,(img, label) in enumerate(ts1):
print(i, 'img', img.size(), 'label', label.size())
关于pytorch的数据处理-数据加载Dataset_datasets pytorch_Henry_zhangs的博客-CSDN博客
Pytorch深度学习实战教程(三):UNet模型训练,深度解析! - 知乎 (zhihu.com)



![[Android 四大组件] --- Service](https://img-blog.csdnimg.cn/41da1b8e98d4441e8ca1df33a4de640d.png)