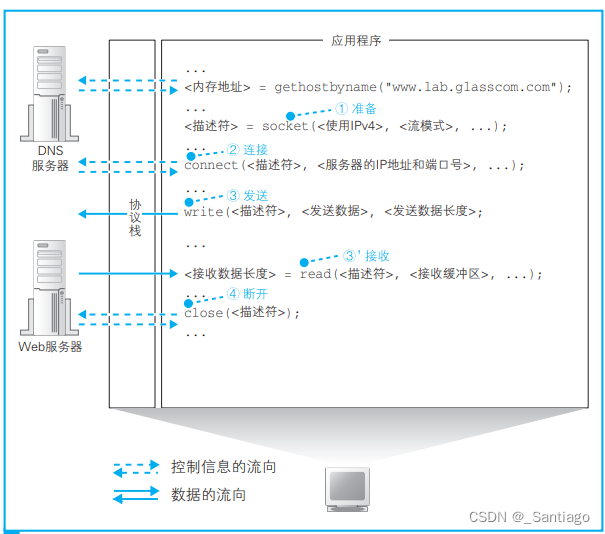
import pandas as pd
data1=pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx")
data2=pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx")
data3=pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx")
data4=pd.read_excel("C://Users//JJH//Desktop//E//附件_四季度.xlsx")
data1
| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | |
|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 729278 | 物业 | 3030100102 | 2019/3/31 22:45:00 | 50.9 | 50.9 | 0.0 |
| 729279 | 物业 | 3030100102 | 2019/3/31 23:00:00 | 50.9 | 50.9 | 0.0 |
| 729280 | 物业 | 3030100102 | 2019/3/31 23:15:00 | 50.9 | 50.9 | 0.0 |
| 729281 | 物业 | 3030100102 | 2019/3/31 23:30:00 | 50.9 | 50.9 | 0.0 |
| 729282 | 物业 | 3030100102 | 2019/3/31 23:45:00 | 50.9 | 50.9 | 0.0 |
729283 rows × 6 columns
data1.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data2.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data3.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data4.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
import numpy as np
# 合并数据
data1['季度'] = pd.Series(["一季度" for i in range(len(data1.index))])
data2['季度'] = pd.Series(["二季度" for i in range(len(data2.index))])
data3['季度'] = pd.Series(["三季度" for i in range(len(data3.index))])
data4['季度'] = pd.Series(["四季度" for i in range(len(data4.index))])
data1
| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | 季度 | |
|---|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 729278 | 物业 | 3030100102 | 2019/3/31 22:45:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729279 | 物业 | 3030100102 | 2019/3/31 23:00:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729280 | 物业 | 3030100102 | 2019/3/31 23:15:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729281 | 物业 | 3030100102 | 2019/3/31 23:30:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729282 | 物业 | 3030100102 | 2019/3/31 23:45:00 | 50.9 | 50.9 | 0.0 | 一季度 |
729283 rows × 7 columns
data = data1.append([data2,data3,data4],ignore_index=True) # 添加合并
data
C:\Users\JJH\AppData\Local\Temp\ipykernel_31264\4019438690.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
data = data1.append([data2,data3,data4],ignore_index=True) # 添加合并
| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | 季度 | |
|---|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3086783 | 消防 | 3620303200 | 2019/12/31 22:45:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086784 | 消防 | 3620303200 | 2019/12/31 23:00:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086785 | 消防 | 3620303200 | 2019/12/31 23:15:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086786 | 消防 | 3620303200 | 2019/12/31 23:30:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086787 | 消防 | 3620303200 | 2019/12/31 23:45:00 | 22.0 | 22.0 | 0.0 | 四季度 |
3086788 rows × 7 columns
x=data[['水表名','用量','采集时间']]
x
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 0 | 司法鉴定中心 | 0.0 | 2019/1/1 00:15:00 |
| 1 | 司法鉴定中心 | 0.0 | 2019/1/1 00:30:00 |
| 2 | 司法鉴定中心 | 0.0 | 2019/1/1 00:45:00 |
| 3 | 司法鉴定中心 | 0.0 | 2019/1/1 01:00:00 |
| 4 | 司法鉴定中心 | 0.0 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
3086788 rows × 3 columns
x1=x[x['水表名']=='消防']
x1
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 1500912 | 消防 | 0.0 | 2019/4/22 12:15:00 |
| 1500913 | 消防 | 0.0 | 2019/4/22 12:30:00 |
| 1500914 | 消防 | 0.0 | 2019/4/22 12:45:00 |
| 1500915 | 消防 | 0.0 | 2019/4/22 13:00:00 |
| 1500916 | 消防 | 0.0 | 2019/4/22 13:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
23984 rows × 3 columns
import matplotlib.pyplot as plt
print(len(x1))
23984
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签
x = range(23984)
# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x1['采集时间'],x1['用量'],color='black',linewidth=0.5)
plt.show()

x=data[['水表名','用量','采集时间']]
x
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 0 | 司法鉴定中心 | 0.0 | 2019/1/1 00:15:00 |
| 1 | 司法鉴定中心 | 0.0 | 2019/1/1 00:30:00 |
| 2 | 司法鉴定中心 | 0.0 | 2019/1/1 00:45:00 |
| 3 | 司法鉴定中心 | 0.0 | 2019/1/1 01:00:00 |
| 4 | 司法鉴定中心 | 0.0 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
3086788 rows × 3 columns
x2=x[x['水表名']=='XXX第一学生宿舍']
x2
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 220372 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 |
| 220373 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 |
| 220374 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 |
| 220375 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 |
| 220376 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2533541 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 |
| 2533542 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 |
| 2533543 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 |
| 2533544 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 |
| 2533545 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签
# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x2) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x2['采集时间'],x2['用量'],color='black',linewidth=0.5)
plt.show()

x=data[['水表名','用量','采集时间']]
x3=x[x['水表名']=='留学生楼(新)']
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签
# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x3) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x3['采集时间'],x3['用量'],color='black',linewidth=0.3)
plt.show()

x=data[['水表名','用量','采集时间']]
x4=x[x['水表名']=='XXX教学大楼总表']
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签
# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x4) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x4['采集时间'],x4['用量'],color='black',linewidth=0.3)
plt.show()

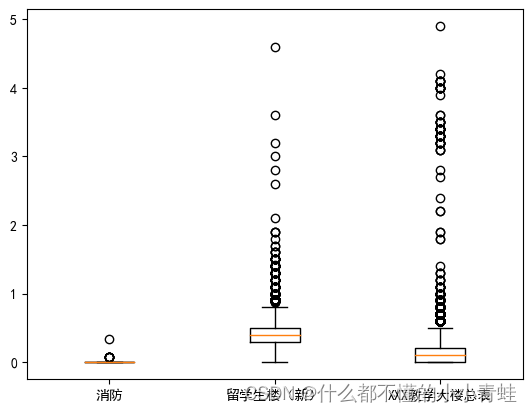
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定字体为SimHei
labels = ['消防', '留学生楼(新)', 'XXX教学大楼总表']
plt.boxplot([x1['用量'],x3['用量'],x4['用量']])
plt.xticks(range(1, 4), labels)
# 显示图形
plt.show()
x5=x[x['水表名']=='XXX第四学生宿舍']
x5
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 246289 | XXX第四学生宿舍 | 0.4 | 2019/1/1 00:15:00 |
| 246290 | XXX第四学生宿舍 | 0.4 | 2019/1/1 00:30:00 |
| 246291 | XXX第四学生宿舍 | 0.4 | 2019/1/1 00:45:00 |
| 246292 | XXX第四学生宿舍 | 0.4 | 2019/1/1 01:00:00 |
| 246293 | XXX第四学生宿舍 | 0.4 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2560037 | XXX第四学生宿舍 | 0.7 | 2019/12/31 22:45:00 |
| 2560038 | XXX第四学生宿舍 | 0.6 | 2019/12/31 23:00:00 |
| 2560039 | XXX第四学生宿舍 | 0.6 | 2019/12/31 23:15:00 |
| 2560040 | XXX第四学生宿舍 | 0.5 | 2019/12/31 23:30:00 |
| 2560041 | XXX第四学生宿舍 | 1.2 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
x6=x[x['水表名']=='茶园+']
x6
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 611260 | 茶园+ | 0.0 | 2019/1/3 16:15:00 |
| 611261 | 茶园+ | 0.0 | 2019/1/3 16:30:00 |
| 611262 | 茶园+ | 0.0 | 2019/1/3 16:45:00 |
| 611263 | 茶园+ | 0.0 | 2019/1/3 17:00:00 |
| 611264 | 茶园+ | 0.0 | 2019/1/3 17:15:00 |
| ... | ... | ... | ... |
| 2945006 | 茶园+ | 0.0 | 2019/12/31 22:45:00 |
| 2945007 | 茶园+ | 0.0 | 2019/12/31 23:00:00 |
| 2945008 | 茶园+ | 0.0 | 2019/12/31 23:15:00 |
| 2945009 | 茶园+ | 0.0 | 2019/12/31 23:30:00 |
| 2945010 | 茶园+ | 0.0 | 2019/12/31 23:45:00 |
34249 rows × 3 columns
x7=x[x['水表名']=='XXX4舍热泵热水舍']
x7
| 水表名 | 用量 | 采集时间 |
|---|
x21=x[x['水表名']=='XXX第一学生宿舍']
x21
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 220372 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 |
| 220373 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 |
| 220374 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 |
| 220375 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 |
| 220376 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2533541 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 |
| 2533542 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 |
| 2533543 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 |
| 2533544 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 |
| 2533545 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
x22=x[x['水表名']=='XXX第二学生宿舍']
x22
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 229011 | XXX第二学生宿舍 | 0.9 | 2019/1/1 00:15:00 |
| 229012 | XXX第二学生宿舍 | 0.7 | 2019/1/1 00:30:00 |
| 229013 | XXX第二学生宿舍 | 0.8 | 2019/1/1 00:45:00 |
| 229014 | XXX第二学生宿舍 | 0.7 | 2019/1/1 01:00:00 |
| 229015 | XXX第二学生宿舍 | 0.1 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2542373 | XXX第二学生宿舍 | 0.1 | 2019/12/31 22:45:00 |
| 2542374 | XXX第二学生宿舍 | 0.1 | 2019/12/31 23:00:00 |
| 2542375 | XXX第二学生宿舍 | 0.2 | 2019/12/31 23:15:00 |
| 2542376 | XXX第二学生宿舍 | 0.1 | 2019/12/31 23:30:00 |
| 2542377 | XXX第二学生宿舍 | 0.1 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
x21.set_index('采集时间', inplace=True)
x22.set_index('采集时间', inplace=True)
print(x21['用量'].dtypes,x21['水表名'])
print(x22['用量'].dtypes,x22['水表名'])
x_sum = x21.add(x22, fill_value=0)
# 打印结果
x_sum
float64 采集时间
2019/1/1 00:15:00 XXX第一学生宿舍
2019/1/1 00:30:00 XXX第一学生宿舍
2019/1/1 00:45:00 XXX第一学生宿舍
2019/1/1 01:00:00 XXX第一学生宿舍
2019/1/1 01:15:00 XXX第一学生宿舍
...
2019/12/31 22:45:00 XXX第一学生宿舍
2019/12/31 23:00:00 XXX第一学生宿舍
2019/12/31 23:15:00 XXX第一学生宿舍
2019/12/31 23:30:00 XXX第一学生宿舍
2019/12/31 23:45:00 XXX第一学生宿舍
Name: 水表名, Length: 35039, dtype: object
float64 采集时间
2019/1/1 00:15:00 XXX第二学生宿舍
2019/1/1 00:30:00 XXX第二学生宿舍
2019/1/1 00:45:00 XXX第二学生宿舍
2019/1/1 01:00:00 XXX第二学生宿舍
2019/1/1 01:15:00 XXX第二学生宿舍
...
2019/12/31 22:45:00 XXX第二学生宿舍
2019/12/31 23:00:00 XXX第二学生宿舍
2019/12/31 23:15:00 XXX第二学生宿舍
2019/12/31 23:30:00 XXX第二学生宿舍
2019/12/31 23:45:00 XXX第二学生宿舍
Name: 水表名, Length: 35039, dtype: object
| 水表名 | 用量 | |
|---|---|---|
| 采集时间 | ||
| 2019/1/1 00:15:00 | XXX第一学生宿舍XXX第二学生宿舍 | 1.02 |
| 2019/1/1 00:30:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.82 |
| 2019/1/1 00:45:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.92 |
| 2019/1/1 01:00:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.82 |
| 2019/1/1 01:15:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.22 |
| ... | ... | ... |
| 2019/12/31 22:45:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.50 |
| 2019/12/31 23:00:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.50 |
| 2019/12/31 23:15:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.70 |
| 2019/12/31 23:30:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.60 |
| 2019/12/31 23:45:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.60 |
35039 rows × 2 columns
x26=x[x['水表名']=='茶园+']
x26
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 611260 | 茶园+ | 0.0 | 2019/1/3 16:15:00 |
| 611261 | 茶园+ | 0.0 | 2019/1/3 16:30:00 |
| 611262 | 茶园+ | 0.0 | 2019/1/3 16:45:00 |
| 611263 | 茶园+ | 0.0 | 2019/1/3 17:00:00 |
| 611264 | 茶园+ | 0.0 | 2019/1/3 17:15:00 |
| ... | ... | ... | ... |
| 2945006 | 茶园+ | 0.0 | 2019/12/31 22:45:00 |
| 2945007 | 茶园+ | 0.0 | 2019/12/31 23:00:00 |
| 2945008 | 茶园+ | 0.0 | 2019/12/31 23:15:00 |
| 2945009 | 茶园+ | 0.0 | 2019/12/31 23:30:00 |
| 2945010 | 茶园+ | 0.0 | 2019/12/31 23:45:00 |
34249 rows × 3 columns
x21=x[x['水表名']=='XXX第一学生宿舍']
x21
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 220372 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 |
| 220373 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 |
| 220374 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 |
| 220375 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 |
| 220376 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2533541 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 |
| 2533542 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 |
| 2533543 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 |
| 2533544 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 |
| 2533545 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
df_merged = pd.merge(x21, x26, on='采集时间', how='inner')
df_merged
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | |
|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:15:00 | 茶园+ | 0.0 |
| 1 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:30:00 | 茶园+ | 0.0 |
| 2 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:45:00 | 茶园+ | 0.0 |
| 3 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:00:00 | 茶园+ | 0.0 |
| 4 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:15:00 | 茶园+ | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 34244 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 |
| 34245 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 |
| 34246 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 |
| 34247 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 |
| 34248 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 |
34249 rows × 5 columns
df_merged['总用水量'] = df_merged['用量_x'] + df_merged['用量_y']
df_merged
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | 总用水量 | |
|---|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:15:00 | 茶园+ | 0.0 | 0.22 |
| 1 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:30:00 | 茶园+ | 0.0 | 0.22 |
| 2 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:45:00 | 茶园+ | 0.0 | 0.22 |
| 3 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:00:00 | 茶园+ | 0.0 | 0.22 |
| 4 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:15:00 | 茶园+ | 0.0 | 0.22 |
| ... | ... | ... | ... | ... | ... | ... |
| 34244 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 | 0.40 |
| 34245 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 | 0.40 |
| 34246 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 | 0.50 |
| 34247 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 | 0.50 |
| 34248 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 | 0.50 |
34249 rows × 6 columns
df_merged1 = pd.merge(x21, x26, on='采集时间', how='outer')
df_merged1
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | |
|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 | NaN | NaN |
| 1 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 | NaN | NaN |
| 2 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 | NaN | NaN |
| 3 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 | NaN | NaN |
| 4 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 | NaN | NaN |
| ... | ... | ... | ... | ... | ... |
| 35034 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 |
| 35035 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 |
| 35036 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 |
| 35037 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 |
| 35038 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 |
35039 rows × 5 columns
df_merged1['用量_y'] = df_merged1['用量_y'].replace(np.nan, 0)
df_merged1
# df_merged1['总用水量'] = df_merged1['用量_x'] + df_merged1['用量_y']
# df_merged1
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | 总用水量 | |
|---|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 | NaN | 0.0 | 0.12 |
| 1 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 | NaN | 0.0 | 0.12 |
| 2 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 | NaN | 0.0 | 0.12 |
| 3 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 | NaN | 0.0 | 0.12 |
| 4 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 | NaN | 0.0 | 0.12 |
| ... | ... | ... | ... | ... | ... | ... |
| 35034 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 | 0.40 |
| 35035 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 | 0.40 |
| 35036 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 | 0.50 |
| 35037 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 | 0.50 |
| 35038 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 | 0.50 |
35039 rows × 6 columns
df_merged1['总用水量'] = df_merged1['用量_x'] + df_merged1['用量_y']
df_merged1
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | 总用水量 | |
|---|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 | NaN | 0.0 | 0.12 |
| 1 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 | NaN | 0.0 | 0.12 |
| 2 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 | NaN | 0.0 | 0.12 |
| 3 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 | NaN | 0.0 | 0.12 |
| 4 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 | NaN | 0.0 | 0.12 |
| ... | ... | ... | ... | ... | ... | ... |
| 35034 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 | 0.40 |
| 35035 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 | 0.40 |
| 35036 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 | 0.50 |
| 35037 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 | 0.50 |
| 35038 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 | 0.50 |
35039 rows × 6 columns