1 前言
随着得物业务规模的不断增加,推荐业务也越来越复杂,对推荐系统也提出了更高的要求。我们于2022年下半年启动了DGraph的研发,DGraph是一个C++项目,目标是打造一个高效易用的推荐引擎。推荐场景的特点是表多、数据更新频繁、单次查询会涉及多张表。了解这些特点,对于推荐引擎的设计非常重要。通过阅读本文,希望能对大家了解推荐引擎有一定帮助。为什么叫DGraph?因为推荐场景主要是用x2i(KVV)表推荐为主,而x2i数据是图(Graph)的边,所以我们给得物的推荐引擎取名DGraph。
2 正文
2.1 整体架构
DGraph可以划分为索引层&服务层。索引层实现了索引的增删改查。服务层则包含Graph算子框架、对外服务、Query解析、输出编码、排序框架等偏业务的模块。
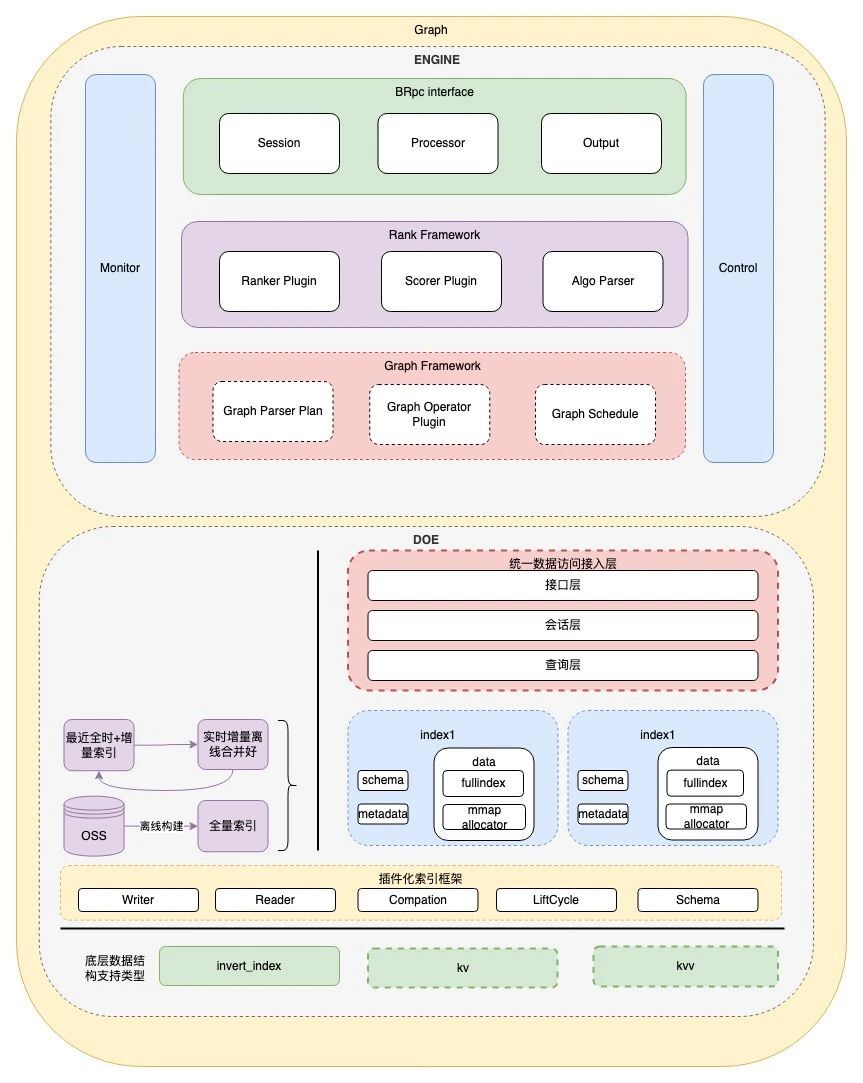
图1
2.2 索引框架
在DGraph里面参考图1,索引的管理被抽象成5个模块:Reader 索引查询、Writer 索引写入、Compaction 增量全量合并、LifeCycle 索引生命周期管理、Schema 索引配置信息。
不同类型的索引只需要实现上面的5个类即可,不同类型的索引只需要关注索引本身的实现方式,而不需要关心索引的管理问题,通过这种模式,索引管理模块实现了索引的抽象管理,如果业务需要,可以快速在DGraph面加入一种新的索引。
DGraph数据的管理都是按表(table)进行的(图2),复杂的索引会使用到DGraph的内存分配器D-Allocator,比如KVV/KV的增量部分 & 倒排索引 & 向量索引等。在DGraph所有数据更新都是DUMP(耗时)->索引构建(耗时)->引擎更新(图3),索引平台会根据DGraph引擎的内存情况自动选择在线更新还是分批重启更新。这种方式让DGraph引擎的索引更新速度&服务的稳定性得到了很大的提升。
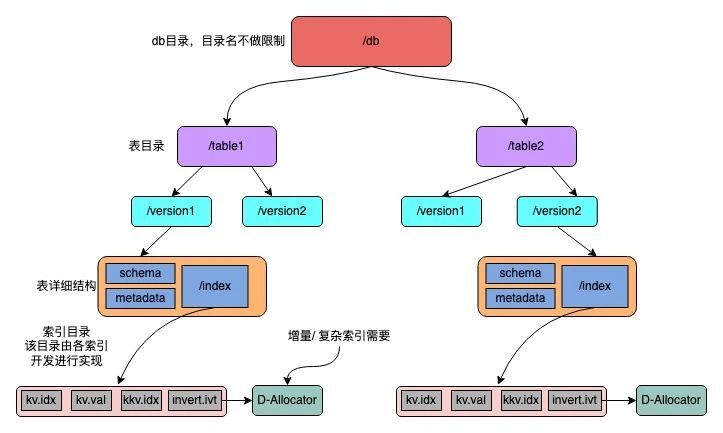
图2
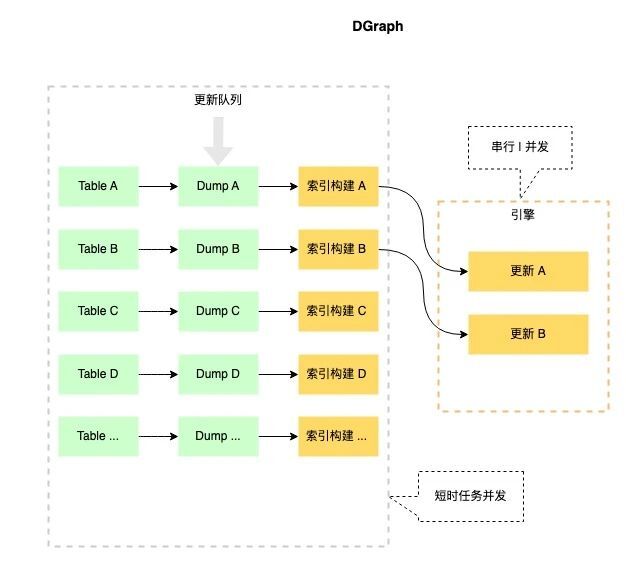
图3
2.3 索引
数据一致性
相比订单、交易等对于数据一致性要求非常严格的场景。在搜推场景,数据不需要严格的一致性,只需要最终一致性。若一个集群有N个引擎,通过增量向集群写入一条数据,每个引擎是独立更新这条数据的,因为是独立的,所以有些机器会更新快一点,有些机器会更新慢一点,这个时间尺度在毫秒级附近,理论上在某一时刻,不同引擎上的数据是不一致的,但这对业务影响不大,因为最终这些数据会保持一致。
最终一致性这个特性非常重要,因为实现严格的一致性很复杂,2PC&3PC等操作在分布式场景下,代价很高。所以事情就变得简单了很多,引擎的读写模型只需要满足最终一致性即可。这可以让我们的系统,更偏向于提供更高的读性能。这个前提也是DGraph目前很多设计的根因。
读写模型
推荐场景需要支持在线服务更新数据,因此引擎有读也有写,所以它也存在读写问题。另外引擎还需要对索引的空间进行管理,类似于JAVA系统里面JVM的内存管理工作,不过引擎做的简单很多。读写问题常见的解决方案是数据加锁。数据库和大部分业务代码里面都可以这么做,这些场景加锁是解决读写问题最靠谱的选择。但是在推荐引擎里面,对于读取的性能要求非常高,核心数据的访问如果引入锁,会让引擎的查询性能受到很大的限制。
推荐引擎是一个读多写少的场景,因此我们在技术路线上选择的是无锁数据结构RCU。RCU在很多软件系统里面有应用,比如Linux 内核里面的kfifo。大部分RCU的实现都是基于硬件提供的CAS机制,支持无锁下的单写单读、单写多读、多写单读等。DGraph选择的是单写多读+延迟释放类型的无锁机制。效率上比基于CAS机制的RCU结构好一点,因为CAS虽然无锁,但是CAS会锁CPU缓存总线,这在一定程度上会影响CPU的吞吐率。
如果简单描述DGraph的索引结构,可以理解为实现了RcuDoc(正排)、RcuRoaringBitMap(倒排)、RcuList、RcuArray、RcuList、RcuHashMap等。用推荐场景可推池来举一个例子,可推池表的存储结构可以抽象成RcuHashMap<Key, RcuDoc> table。这里用RcuList来举例子,可以用来理解DGraph的RCU机制。其中MEMORY_BARRIER是为了禁止编译器对代码重排,防止乱序执行。
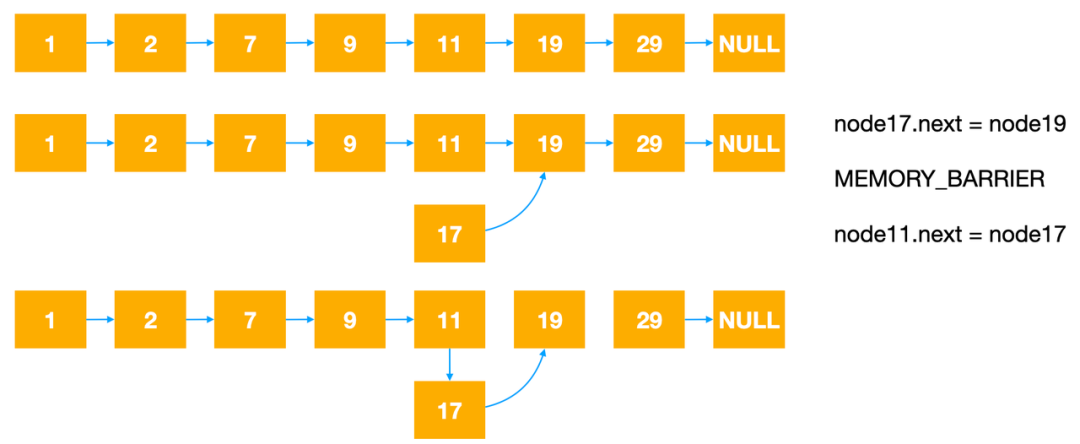
图4
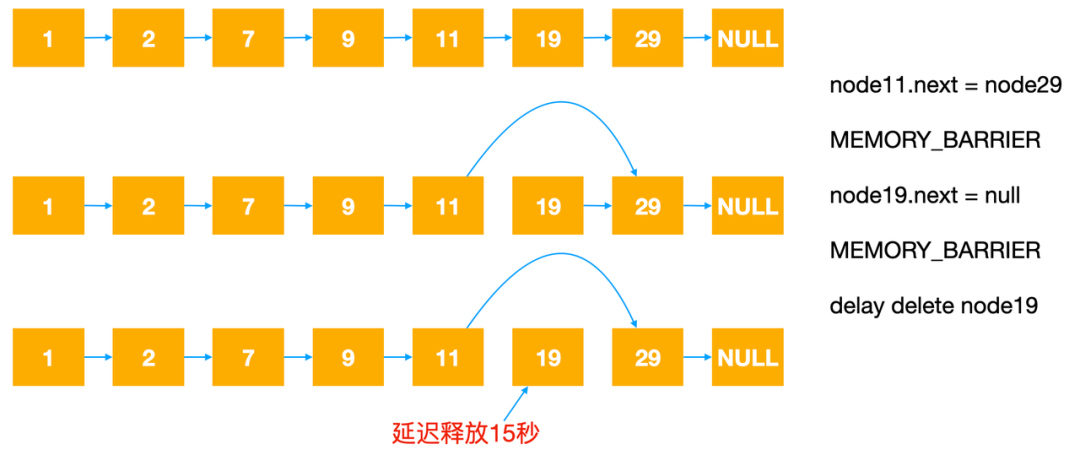
图5
图5是删除的例子,简单讲一下,在RcuList里面,删除一个元素的时候,比如Node19,因为删除期间可能有其他线程在访问数据,所以对List的操作和常规的操作有些不同,首先将Node11的Next节点指向Node29,保证后面进来的线程不会访问Node19,然后把Node19的Next指向Null,因为这个时候可能还有线程在访问Node19,因此我们不能立即把Node19删除,而是把Node19放入删除队列,延迟15秒之后再删除,另外删除的动作不是主动的,而是由下一个需要申请内存的操作触发,因此删除是延时且Lazy的。
数据持久化
在DGraph里面我们构建了一个内存分配器D-Allocator(每个索引只能申请一个/可选),用于存储增量或者倒排索引等复杂数据结构。采用了类似TcMalloc按大小分类的管理模式。D-Allocator利用Linux系统的mmap方法每次从固定的空间申请128M ~ 1GB大小,然后再按块划分&组织。由系统的文件同步机制保证数据的持久化。目前64位x86 CPU实际寻址空间只有48位,而在Linux下有效的地址区间是 0x00000000 00000000 ~ 0x00007FFF FFFFFFFF 和 0xFFFF8000 00000000 ~ 0xFFFFFFFF FFFFFFFF 两个地址区间。而每个地址区间都有128TB的地址空间可以使用,所以总共是256TB的可用空间。在Linux下,堆的增长方向是从下往上,栈的增长方向是从上往下,为了尽可能保证系统运行的安全性,我们把0x0000 1000 0000 0000 到 0x0000 6fff ffff ffff分配给索引空间,一共96TB,每个内存分配器可以最大使用100GB空间。为了方便管理,我们引入了表keyID,用于固定地址寻址,表地址 = 0x0000 1000 0000 0000 + keyId * 100GB, 引擎管理平台会统一管理每个集群的keyId,偶数位分配给表,奇数位保留作为表切换时使用。keyId 0 - 600 分配给集群独享表,keyId 600-960分配给全局表。因此单个集群可以最多加载300个独享表+最多180共享表(备注:不是所有表都需要D-Allocator,目前没有增量的KVV/KV表不受这个规则限制)。
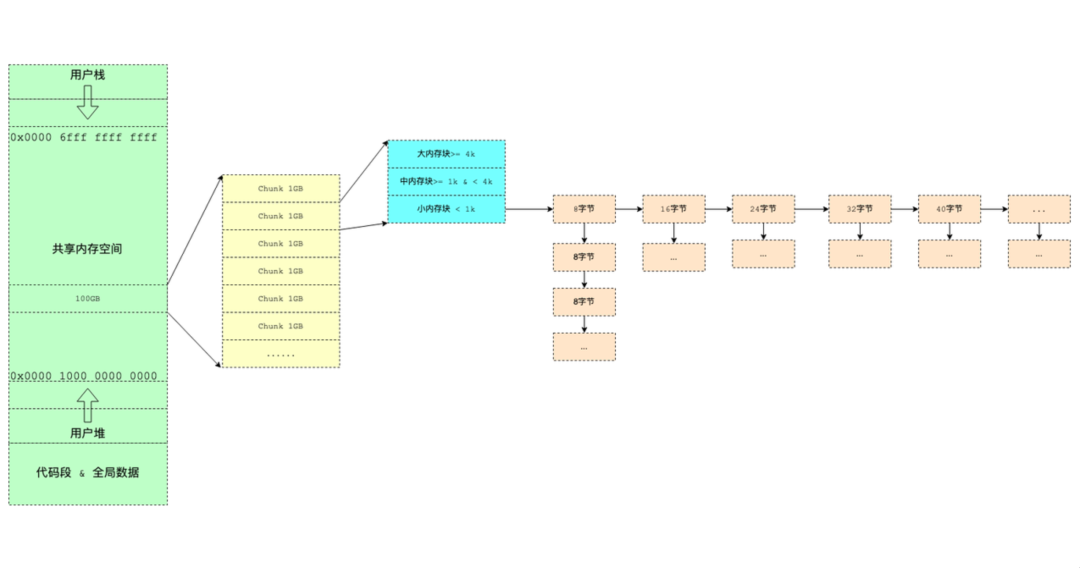
图6
KV/KVV索引KV -> Map<Key, Object> 、 KVV -> Map<Key, List<Object>>。推荐引擎绝大部分表都是KVV索引,数据更新特点是,定期批量更新 & 大部分表没有实时增量。针对这些业务特性,DGraph设计了内存紧凑型KV\KVV索引(图7)。这里简单讲一下DenseHashMap的实现,传统的HashMap是ArrayList+List或者ArrayList+红黑树的结构。DGraph的DenseHashMap,采用的ArrayList(Hash)+ArrayList(有序)方式,在ArrayList(Hash)任意桶区域,存储的是当前桶的首个KVPair信息,以及当前桶Hash冲突的个数,冲突数据地址偏移量,存储在另外一个ArrayList(有序)地址空间上(Hash冲突后可以在这块区域用二分查找快速定位数据)。这种结构有非常好的缓存命中率,因为它在内存空间是连续的。但是它也是有缺点的,不能修改,全量写入也非常复杂。首先我们要把数据加载到一个普通的HashMap,然后计算每个Hash桶上面元素的个数,知道了桶的数量和每个桶下面的元素个数,遍历HashMap,把数据固化成DenseHash。KV/KVV的增量部分则是由RcuHashMap + RcuDoc基于D-Allocator(图6)实现。
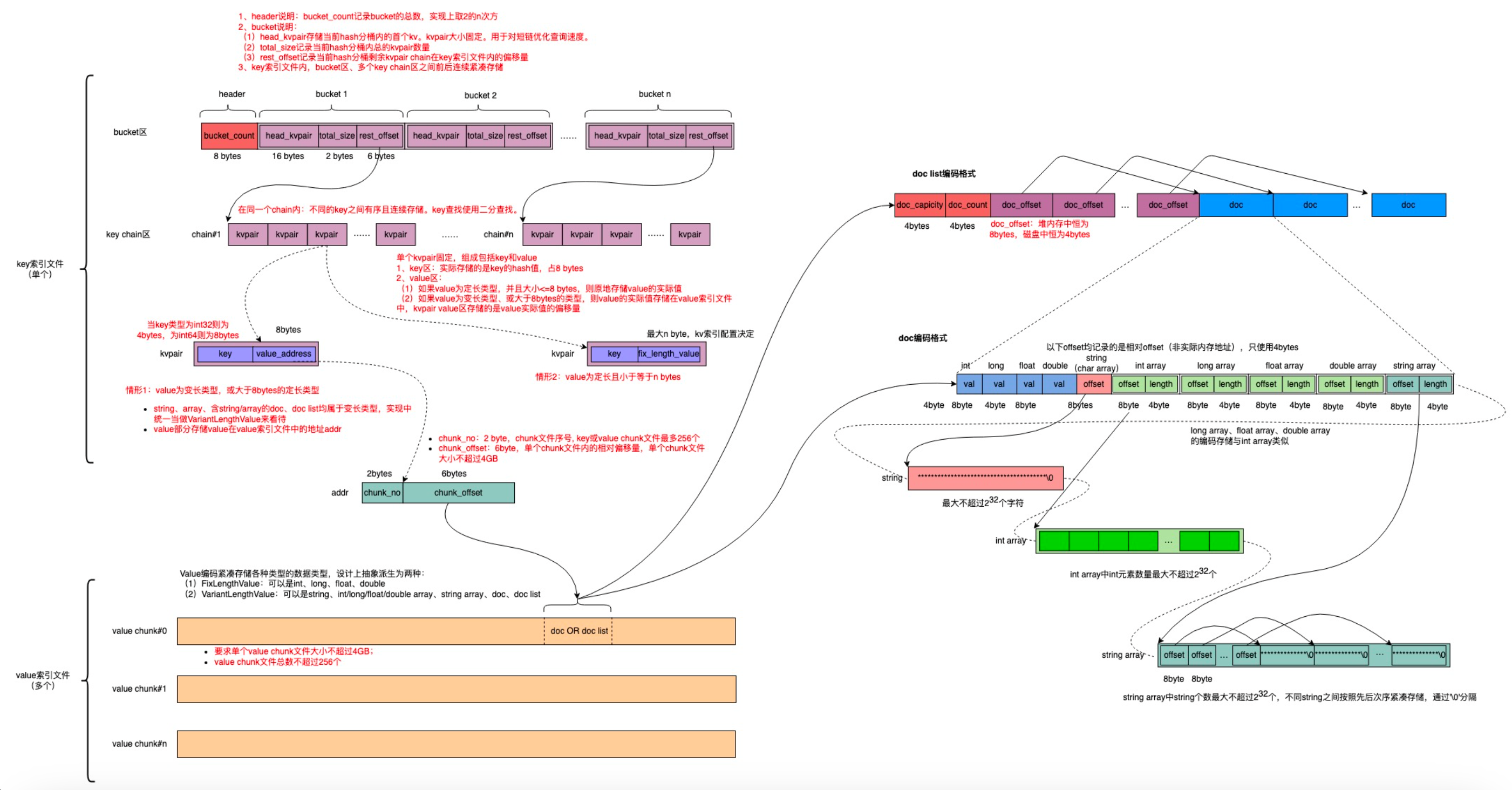
图7
Invert索引
基于开源RoaringBitmap实现的RCU版本(基于D-Allocator实现)。RoaringBitmap 将一个文档ID(uint32)分为高位和低位,高16位的ID用来建一级索引,低16位的ID用来构建二级索引(原文称之为Container),在二级索引中,因为2^16=65536,一个short占用空间16bit,65536刚好可以存储4096个short,因此当分段内文档数量少于等于4096是,用short数组存储文档,当分段内的文档数量大于4096时则转为Bitmap存储,最多可以存储65536个文档。这种设计对于稀疏倒排&密集倒排在存储空间利用率&计算性能上都表现优异。

图8
Embedding索引
基于开源的Kmeans聚类。Kmeans聚类后,引擎会以每个中心向量(centroids)为基点,构建倒排,倒排的数据结构也是RoaringBitmap,同一个聚簇的向量都回插入同一个RoaringBitmap里面。这样的好处是,可以在向量检索中包含普通文本索引,比如你可以在向量召回的基础上限制商品的tile必须要包含椰子、男鞋、红色等文本信息。
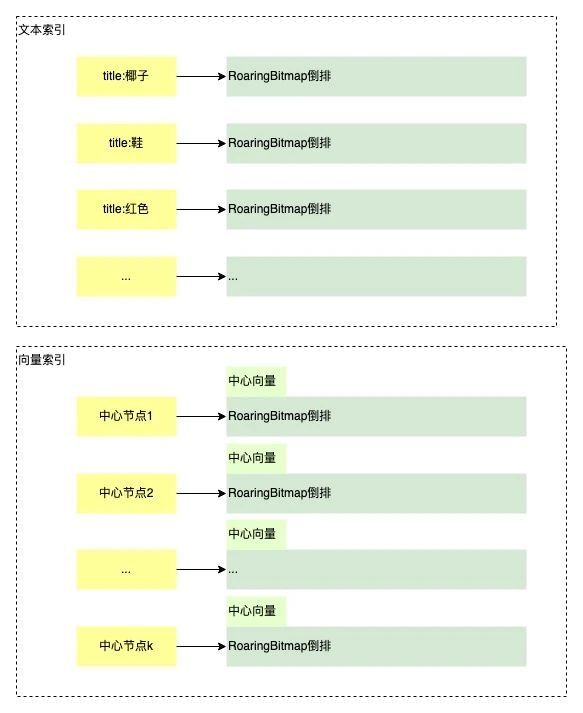
图9
2.4 算子调度框架
推荐存储引擎最开始只提供了简单的数据查询&数据补全功能,由于扩招回需要,后期又引入了算子框架,初步提供了基本的多算子融合调度能力(Merge/LeftJoin/Query),可以将多次引擎查询合并为单次查询,降低召回RT, 提升召回能力。老的框架有很多问题:1)只提供了JAVA API接入,API可解释性比较差,用户接入上存在一定困难。2)算子调度框架效率偏低,采用OMP+阶段策略调度,对服务器硬件资源利用率偏低,部分场景集群CPU超过20%后99线95线即开始恶化。3)Graph运行时中间数据采用行式存储,在空间利用率和运算开销上效率低,导致部分业务在迁移算子框架后RT反而比之前高。4)缺少调试 & 性能分析手段。
DGraph后期针对这些问题我们做了很多改进:1)引入了Graph存储,用于可以通过传入GraphID访问一个图,配合引擎管理平台的DAG展示&构图能力,降低图的使用门槛。2)开发了全新的调度框架:节点驱动+线程粘性调度。3)算子中间结果存取等计算开销比较大的环节,通过引入了列存储,虚拟列等有效的降低了运行时开销。上线后在平均RT和99线RT都取得了不错的结果。
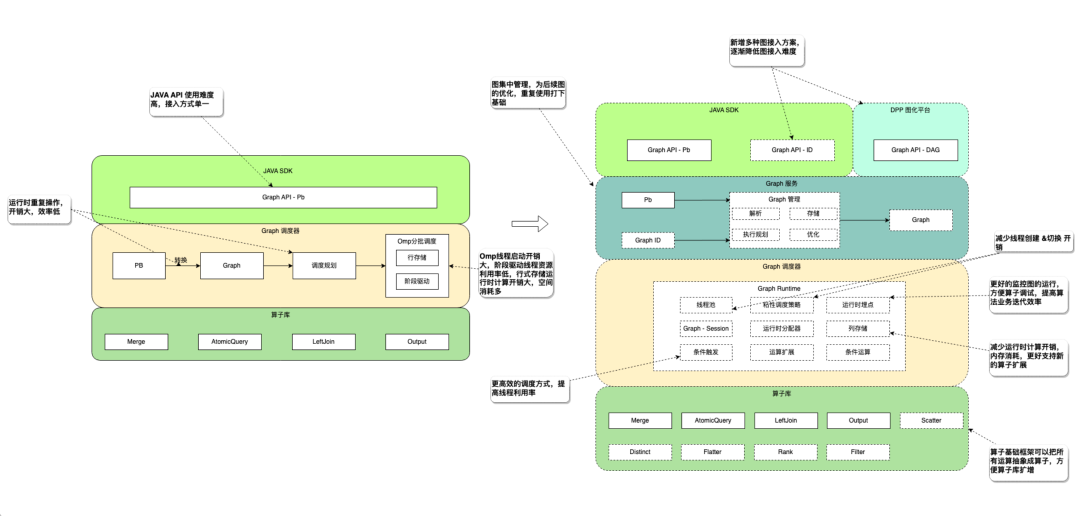
图10
3 后记
DGraph是得物在推荐业务上一次非常成功的探索,并在算法指标、稳定性、机器成本等多方面取得了收益。搜推场景是互联网中算力开销特别大的场景之一,数据更新频繁,日常业务迭代复杂,因此对系统的挑战非常高。在DGraph的研发过程中,我们投入了非常多的精力在系统的稳定性 & 易用性上面,积累了很多些经验,简单总结下:1)平台侧需要做好数据的校验,数据的增删的改是搜推场景最容易引发事故的源头。2)提供灵活的API,类SQL或者DAG都可以,在C++内部做业务开发是非常危险的。3)索引必须是二进制结构并且采用mmap方式加载,这样即使发生崩溃的情况,系统可以在短时间快速恢复,日常调试重启等操作也会很快。
*文/寻风
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!