小白视角:一文读懂3TS腾讯事务处理验证系统的基础知识
- 一、解读结果图
- 1.1 异常测试用例
- 1.2 事务的隔离级别
- (1)SQL标准隔离级别
- (2)快照隔离(Snapshot Isolation,简称 SI)
- (3)Serializable Snapshot Isolation,简称 SSI
- 1.3 测试结果
- 二、工具
- 2.1 cmake
- 2.2 ODBC
- 2.3 PostgreSQL
- 三、并发控制算法
- 3.1 两段封锁技术(2PL)
- 3.2 多版本并发控制技术(MVCC)
最近参与了3TS开源项目的学习中,作为小白一时之间不知道如何入手分析结果,看了不少文章资料和教程及书籍到最后终于理解,于是想写一篇文章来帮助那些和我一样的小白,那个大佬不都是从小白开始成长起来的呢?戒骄戒躁,砥砺前行,加油,顶峰见!
隔离性要保证数据和事务的相对隔离,管理多个并发读写请求(事务)过来时的执行顺序,隔离级别的选择是一场数据的可靠性与性能之间的权衡。
什么是事务?
事务就是一系列操作组成,比如A给B转了1万,A存款减少1万和B存款增加1万的两个操作组合就是一个事务;
事务有四大特性:(原子性,隔离性,持久性的目的都是为了要做到一致性)
- 原子性(Atomicity):事务要么都执行成功(commit)要么都失败(rollback)。
- 隔离性(Isolation):事务之间互不干扰。隔离级别(Isolation level)是重点稍后讲
- 持久性(Durability):事务一旦提交永久保存。
- 一致性(Consistency):事务执行前后数据状态合法,即完整性约束不被破坏。
事务具体的实现有两种,一种是基于锁的协议,一种是基于时间戳的,现在主流的实现就是基于时间戳的方式的一种,就是MVCC机制;
什么是异常?
在ACID的保护下,数据库中控制不同的事务并发执行(提高系统的效率)有时会因为隔离不足产生不一致的情况导致异常。
事务是并发控制的前提条件。并发控制就是控制不同的事务并发执行,提高系统的效率。事务并发执行时隔离不足会导致异常
一、解读结果图
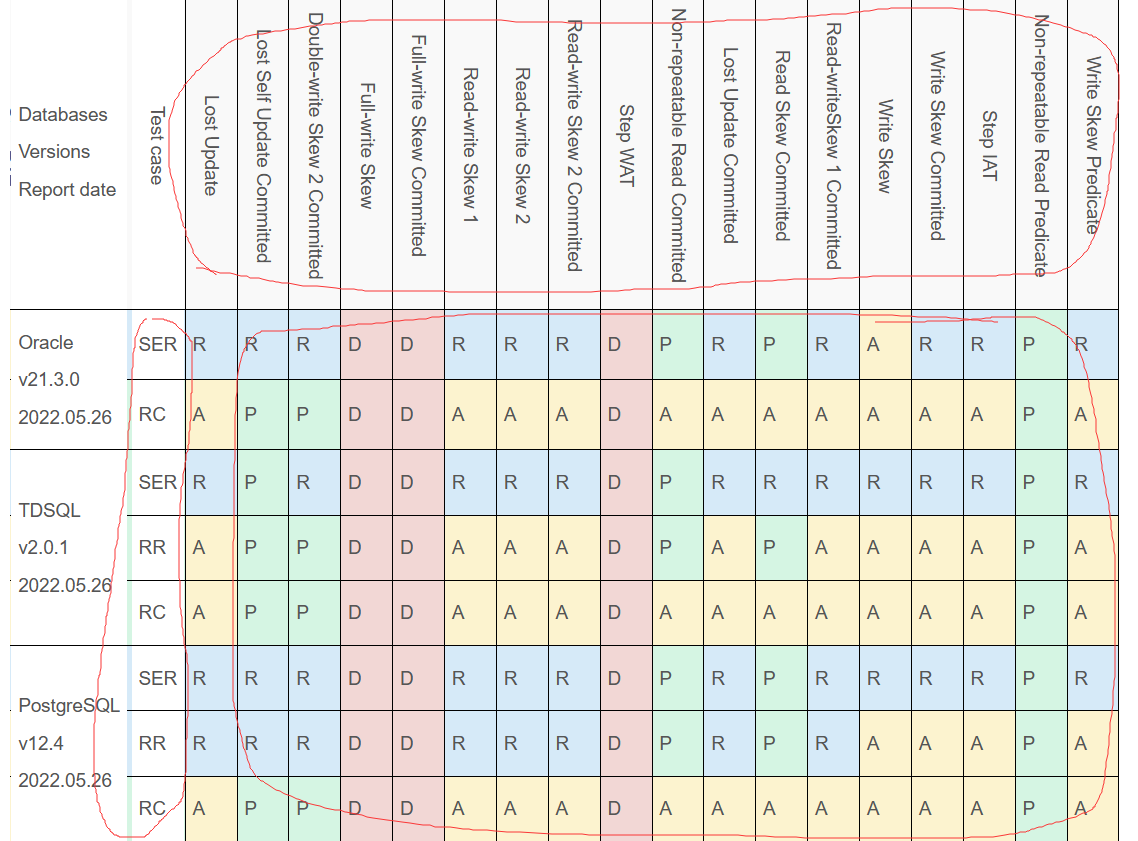
1.1 异常测试用例
先说x轴(异常测试用例),平时熟知SQL标准定义的异常如下:
1、脏写(Dirty Write):还未提交的事务写了另一个未提交事务所写过的数据,称为脏写
2、脏读(Dirty Read):事务a读取了还未commit事务b的写数据,后来事务b回滚了,那么读到的就是脏数据
3、不可重复读(Non-Repeatable Read):事务A读取一个值,但是没有对它进行任何修改,另一个并发事务B修改了这个值并且提交了,事务A再去读,发现已经不是自己第一次读到的值了,是B修改后的值,就是不可重复读。
ps:一般数据库使用MVCC,在事务的第一条语句开始时生成Read View,事务之后的所有读取,都是基于同一个Read View,以此避免不可重复读问题。
4、幻读(Phantom):事务A查询一个范围的值,另一个并发事务B往这个范围中插入了数据并提交,然后事务A再查询相同范围,发现多了一条记录,或者某条记录被别的事务删除,事务A发现少了一条记录。
ps:不可重复读面向的是“同一条记录”,而幻读面向的是“同一个范围”。MVCC虽然使用快照的方式解决了不可重复读,但是还是不能避免幻读,幻读需要通过范围锁解决
一致性模型Coo可以关联所有的数据异常,具体的说是定义了一个偏序对(POP)图,任何调度计划都可以用pop图的状态表示,最后通过pop生命周期检查异常,如果表示的pop图存在循环,则存在调度,存在数据异常,如果不存在则满足一致性。
回到我们这里,用生命周期的状态来表示和定义的异常被分为三类,分别是RAT、WAT、IAT,对应结果表中的33个异常测试用例。
1.2 事务的隔离级别
结果图中的y轴也就是事务的隔离级别(英文简写一下子没反应过来)
数据库的事务具体的实现有两种,一种是基于锁的协议,一种是基于时间戳的,现在主流的实现就是基于时间戳的方式的一种,就是熟悉的MVCC机制;
PostgreSQL 中采用的是MVCC(多版本并发控制技术)不会出现脏读。对Pg来说,读未提交和读已提交相同。
MySQL InnoDB 引擎的可重复读隔离级别(默认隔离级),根据不同的查询方式,分别提出了避免幻读的方案:
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读。
但是MySQL 可重复读隔离级别并没有彻底解决幻读,只是很大程度上避免了幻读现象的发生
(1)SQL标准隔离级别
为了解决数据库中并发操作所带来的数据异常,数据库系统使用不同的隔离级别来杜绝异常的发生,在SQL标准里定义了四种隔离级别,每一种级别都规定一个事务中的修改,哪些是事务之间可见的,哪些是不可见的。级别越低的隔离级别可以执行越高的并发,但同时实现复杂度以及开销也越大。
| 隔离级别 | 解释 | 可能导致的异常 |
|---|---|---|
| 读未提交(Read Uncommitted,简称RU) | 一个事务还没提交时,它做的变更就能被别的事务看到。 | 脏读(Dirty Read)、不可重复读(Unrepeatable Read)、 |
| 读已提交(Read Committed,简称RC) | 一个事务提交(commit)之后,它做的变更才会被其他事务看到。 | 不可重复读(Unrepeatable Read)、幻读(Phantom Read) |
| 可重复读(Read Repeatable,简称RR) | 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。 | 幻读(Phantom Read) |
| 串行(xíng)化(Serializable,简称SER) | 在MySQL中同一时刻只允许单个事务执行,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。 |
(2)快照隔离(Snapshot Isolation,简称 SI)
SQL 标准定义的的这四个隔离级别,只适用于基于锁的事务并发控制,后来有人写了一篇论文提到了一种新的隔离级别 —— SI,它不会出现脏读、不可重复度和幻读三种读异常,并且读操作不会被阻塞。大部分应用场景下,SI可以很好地运行,但是依然没有达到可串行化的隔离级别,因为它会出现写偏序(write skew)。Write skew 本质上是并发事务之间出现了读写冲突(读写冲突不一定会导致 write skew,但是发生 write skew 时肯定有读写冲突),但是 Snapshot Isolation 在事务提交时只检查了写写冲突。为了避免 write skew,应用程序必须根据具体的情况去做适配,比如使用SELECT … FOR UPDATE,或者在应用层引入写写冲突。这样做相当于把数据库事务的一份工作扔给了应用层。
(3)Serializable Snapshot Isolation,简称 SSI
有人提出了基于SI的可串行化 —— SSI(PostgreSQL已经支持 SSI)。
为了分析 SI 下的事务调度可串行化问题,有论文提出了一种叫做 Dependency Serialization Graph (DSG) 的方法。通过分析事务之间的 rw、wr、ww 依赖关系,可以形成一个有向图。如果图中无环,说明这种情况下的事务调度顺序是可串行化的。这个算法理论上很完美,但是有一个很致命的缺点,就是复杂度比较高,难以用于工业生产环境。在 Snapshot Isolation 下, DSG 形成的环肯定有两条 rw-dependency 的边,即是“连续”的(一进一出)。
1.3 测试结果
3TS-Coo一致性检查工具的检查结果有两种类型:
- 异常 (anomaly,简称A):数据库无法识别数据异常,从而导致数据不一致,意味着没有等效的可序列化执行(或偏序对(POP)生命周期)
- 一致性(consistency):
- 数据库通过(P)具有可序列化结果的异常测试用例(无pop周期),数据保持一致性
- 达到规则 (rules,R)、死锁检测 (deadlock detection,D) 或超时 (timeout ,T) 而回滚事务
二、工具
工欲善其事,必先利其器
过多的基础介绍不方便写到报告这里介绍一下搭建3TS测试环境基础概念;
2.1 cmake
Cmake是一个跨平台构建工具,用于构建大型C++项目。它支持构建、测试和打包软件。它使用平台无关的配置文件来控制编译过程,并生成适合您选择的编译器环境的项目文件,如VS项目文件或Makefile。下面是它的工作流程图:
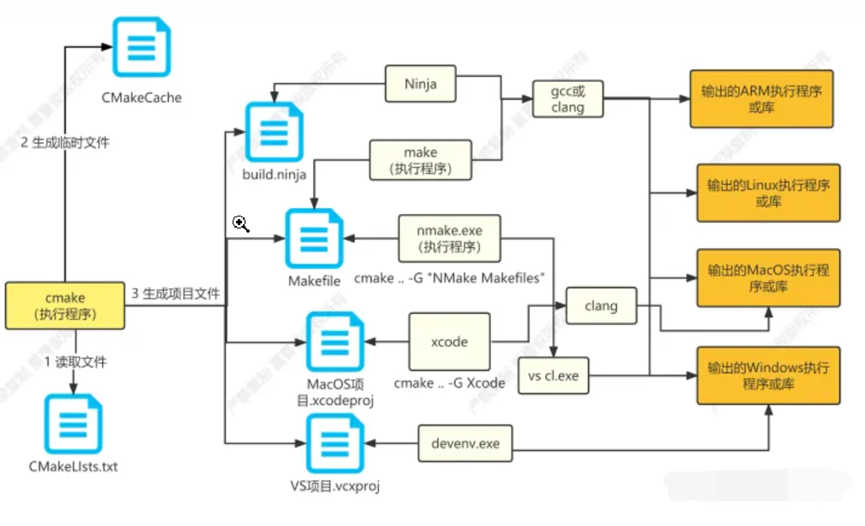
configure 和 CMake 用生成 Makefile,负责将源代码与当前系统进行配置和适配。
而 make 则根据 Makefile 中的规则进行实际的编译过程,生成可执行文件或库。
最后,make install 负责将最终编译好的文件复制到指定的安装目录中,以供系统中的其他程序使用。
一些参考链接:
- 官网: http://cmake.org.cn/
- 编译工具:https://blog.csdn.net/LSW1737554365/article/details/132079584
- B站上看了一个cmake的教学视频忘了存链接了
2.2 ODBC
ODBC (Open Database Connectivity)是一种标准的接口技术,用于管理多个数据库系统。它提供了一个统一的API(应用程序接口),使得应用程序可以通过相同的方法与多种不同类型(例如Oracle、MySQL、SQL Server等)的数据库进行通信。
所以安装了ODBC以后在本项目中想要测试什么数据库,只需要安装想测试的数据库和对应版本的数据库驱动,去配置以后生成makefile文件,再make
odbc官网 : https://www.unixodbc.org/
2.3 PostgreSQL
官方网站:https://www.postgresql.org/
# ubantu安装后,系统会创建一个数据库超级用户 postgres,密码为空
sudo apt-get update
sudo apt-get install postgresql postgresql-client
# PostgreSQL 安装完成后,自带了一个命令行工具 SQL Shell(psql),Linux 系统可以直接切换到 postgres 用户来开启命令行工具
sudo -i -u postgres
# 进入PostgreSQL,进入成功显示:postgres=#
psql
# 退出PostgreSQL,退出成功显示:postgres@用户名:~$
\q
# 查看用户名和密码,复制查看对应用户的加密的密码(注意去掉md5的前缀)到网站解密:https://www.somd5.com/
SELECT rolname,rolpassword FROM pg_authid;
# 修改密码
ALTER USER postgres WITH PASSWORD 'postgres';
# 新建用户和密码
create user 用户名 with password '密码';
# 查看默认端口,默认5432
sudo netstat -plunt |grep postgres
postgresql驱动程序: https://www.postgresql.org/ftp/odbc/versions/src/
ps aux | grep postgresql-odbc # 检查postgresql-odbc是否安装
ps aux | grep unixODBC # 检查postgresql-odbc是否安装
postgresql官网事务隔离级别的解释:http://www.postgres.cn/docs/12/transaction-iso.html
PostgreSQL 中的事务隔离级别和多版本并发控制(MVCC)的实现原理。
PostgreSQL提供了四个事务隔离级别,其中之一是 Repeatable Read(可重复读)。在该隔离级别下,每个事务在开始时会获取一个快照,事务执行过程中只能看到在此快照之前已经提交的修改,看不到其他并发事务的未提交修改。这通过在数据库中使用时间戳和版本号来实现。
MVCC 是 PostgreSQL 使用的一种并发控制机制。它通过在数据库引擎中为每个事务保留一个一致性的快照,这样每个事务在执行读取操作时,都能看到事务开始之前的数据库状态。当执行写入操作时,MVCC 会创建一个新版本,而不是直接在原始数据上进行修改。
三、并发控制算法
在数据库中多个事务可能会访问同一数据项,为保证事务的ACID特性,必须采用某种方式高效地调度并发事务,该技术称为并发控制技术。并发控制技术的实现策略可分为乐观并发控制与悲观并发控制,这两种控制思想是从“何时检测冲突”的角度定义的。
乐观(OCC):从一开始,每一项操作都允许进行,但在事务提交的时候,会进行隔离性与完整性约束的检查,如果有违反则终止事务。在冲突较少的情况下,乐观并发控制方法是合适的。
乐观(PCC):从一开始,即检查每一项操作是否违反隔离性与完整性约束,如果可能违反,则阻塞该操作。如两阶段封锁技术中读锁阻塞另一个事务的写操作,是因为写操作可能造成上述提到的读异常。因此两阶段封锁技术属于悲观的方法,提前做出预防。
3.1 两段封锁技术(2PL)
三级封锁协议目的是在不同程序上保证数据的一致性,而两段锁协议的目的是保证并发调度的正确性,DBMS为了保证并发调度的正确性,普遍使用两段锁协议实现并发调度的可串行性,保证调度的正确性。具体内容如下:
- 加锁阶段:在对任何数据进行读、写操作之前,事务首先要申请并获得对该数据的封锁;
- 解锁阶段:在释放一个封锁之后,事务不再申请和获得任何其他封锁。
若并发的所有事务均遵守两段锁协议,则对这些事务的任何并发调度策略都是可串行化的


3.2 多版本并发控制技术(MVCC)
MVCC(Multi Version Concurrency Control)通过维护数据历史版本,从而解决并发访问情况下的读一致性问题。
postgres中MVCC的实现方式之一为快照隔离,快照隔离的核心思想是: 每个事务都从一个数据库的快照中读数据。 (即:事务看到的所有数据,都是在事务开始的时间点之前 committed 的数据。) 如果有些数据在当前事务开始之后,被其他事务改变了值,快照隔离能够保证当前事务无法看到这个新值。在快照隔离中每一次读都是从一个过去的快照中读取的,因此不会出现多次读一个值却读到不一致结果的情况。
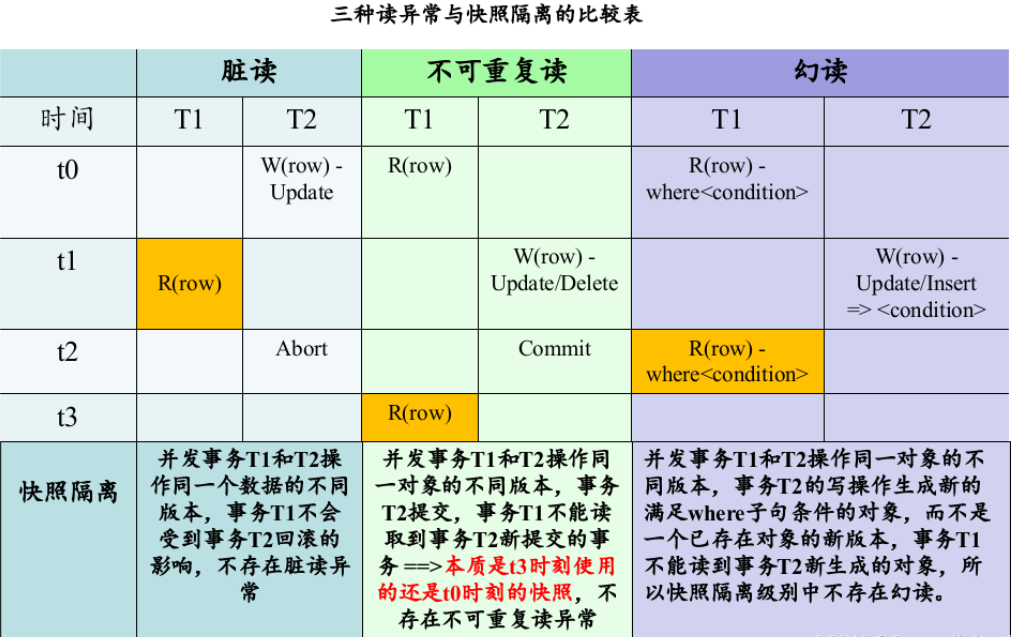
快照隔离技术会发生写偏序异常问题,会导致事务的不可串行化,可以通过可串行化快照隔离SSI技术解决此问题
最后,可能有不对的地方欢迎指出来交流,部分是官方文档,部分是论文的摘抄和个人理解,部分是网络资料的整合,文章中附有大量可参考的链接资源。部分参考文章如下:
参考文章
- 数据库事务(Transaction)与锁(Locking)详解图https://blog.csdn.net/weixin_45670060/article/details/119977481
- 面试中的事务和锁:https://zhuanlan.zhihu.com/p/187345419
- 深入讲解 :https://www.cnblogs.com/leijiangtao/p/11911644.html
- https://zhuanlan.zhihu.com/p/133823461
- 官网文档:https://axingguchen.github.io/3TS/
- 写倾斜的解释:https://www.jdon.com/55452.html
- mvcc的隔离级别的理解:https://cloud.tencent.com/developer/article/1529460
- 快照隔离:https://blog.csdn.net/songchuwang1868/article/details/97630005
- acid四大特性的理解:https://cloud.tencent.com/developer/article/1888427
- https://blog.csdn.net/qq_52668274/article/details/129843223