文章目录
- 前言
- 一、mAP原理
- 1、mAP概念
- 2、准确率
- 3、精确率
- 4、召回率
- 5、AP: Average Precision
- 二、mAP0.5与mAP0.5:0.95
- 1、mAP0.5
- 2、mAP0.5:0.95
- 三、mAP代码实现
- 1、真实标签json文件格式
- 2、模型预测标签json文件格式
- 3、mAP代码实现
- 4、mAP结果显示
- 四、模型集成mAP代码
- 1、模型main函数
- 2、模型mAP计算代码
前言
我们在深度学习的论文经常看到实验对比指标mAP,比较mAP@0.5与mAP@0.5:0.95指标。然,又有很多博客并未完全说明清楚,特别说结合代码解释该指标。为此,本文章将梳理mAP指标,主要内容分为mAP原理解释,如何使用代码获得mAP指标,进一步探讨如何结合模型而获得mAP指标。
一、mAP原理
1、mAP概念
mAP,其中代表P(Precision)精确率。AP(Average precision)单类标签平均(各个召回率中最大精确率的平均数)的精确率,mAP(Mean Average Precision)所有类标签的平均精确率。
2、准确率
准确率=预测正确的样本数/所有样本数,即预测正确的样本比例(包括预测正确的正样本和预测正确的负样本,不过在目标检测领域,没有预测正确的负样本这一说法,所以目标检测里面没有用Accuracy的)。
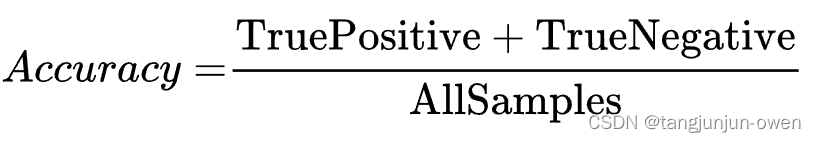
3、精确率
精确率也称查准率,Precision针对的是某一类样本,如果没有说明类别,那么Precision是毫无意义的(有些地方不说明类别,直接说Precision,是因为二分类问题通常说的Precision都是正样本的Precision)。
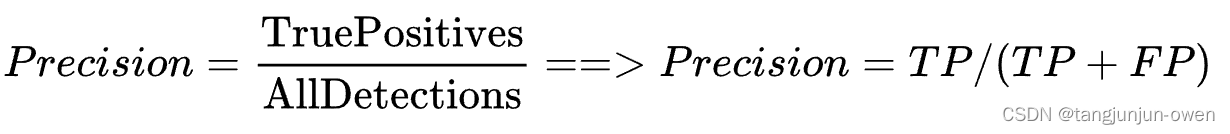
4、召回率
Recall和Precision一样,脱离类别是没有意义的。说道Recall,一定指的是某个类别的Recall。Recall表示某一类样本,预测正确的与所有Ground Truth的比例。
Recall计算的时候,分母是Ground Truth中某一类样本的数量,而Precision计算的时候,是预测出来的某一类样本数。
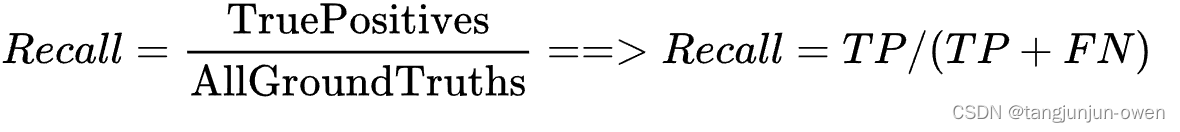
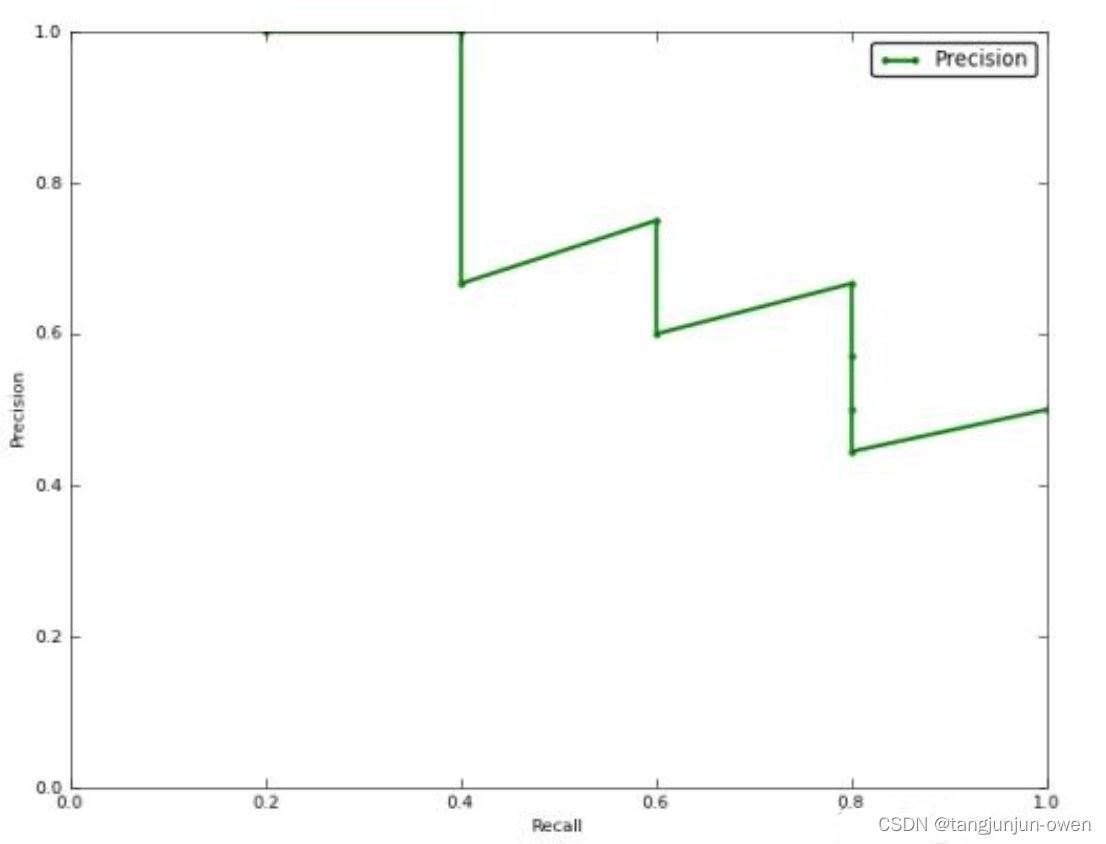
5、AP: Average Precision
AP指单个类别平均精确度,而mAP是所有类别的平均精确度,AP是Precision-Recall Curve曲线下面的面积,以Recall为横轴,Precision为纵轴,就可以画出一条PR曲线,PR曲线下的面积就定义为AP,如下。
由于计算积分相对困难,因此引入插值法,计算AP公式如下:
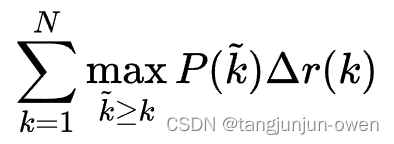
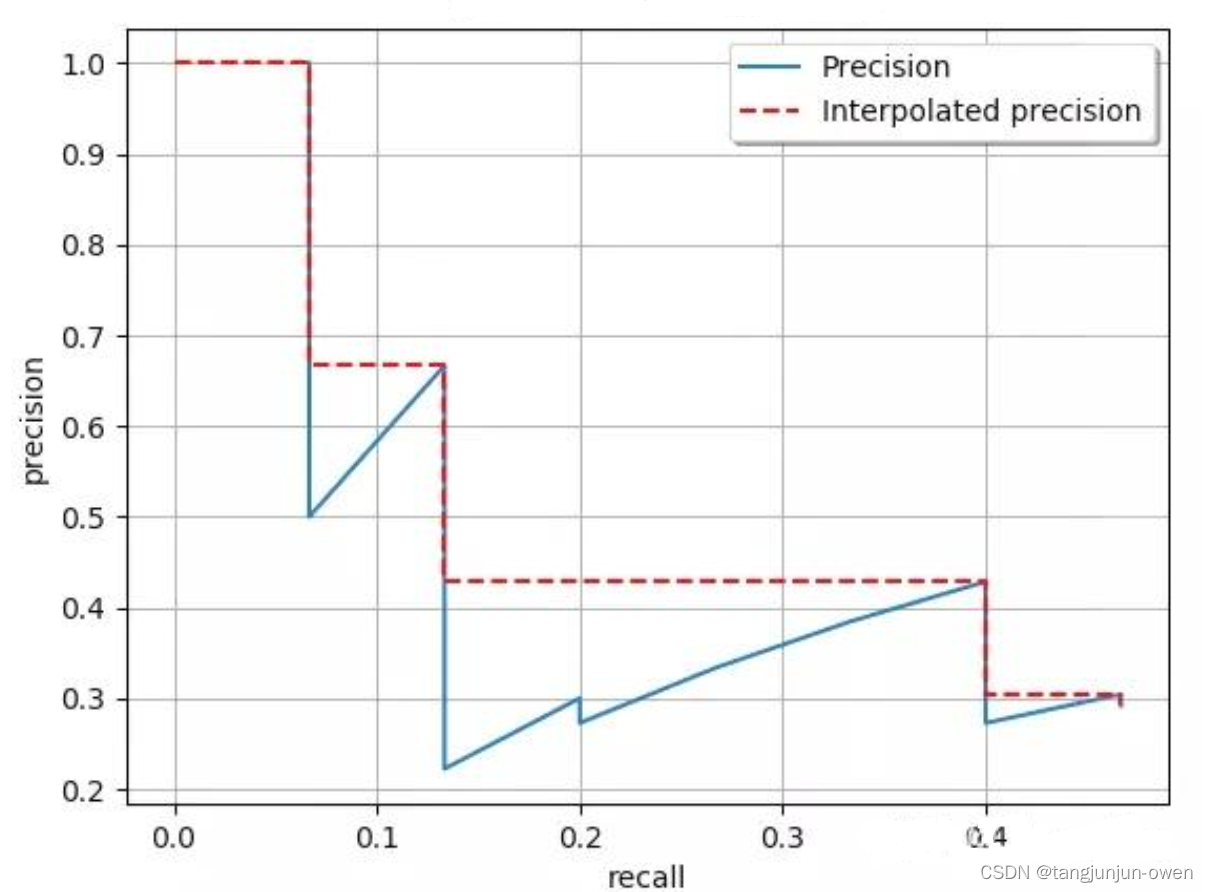
计算面积:
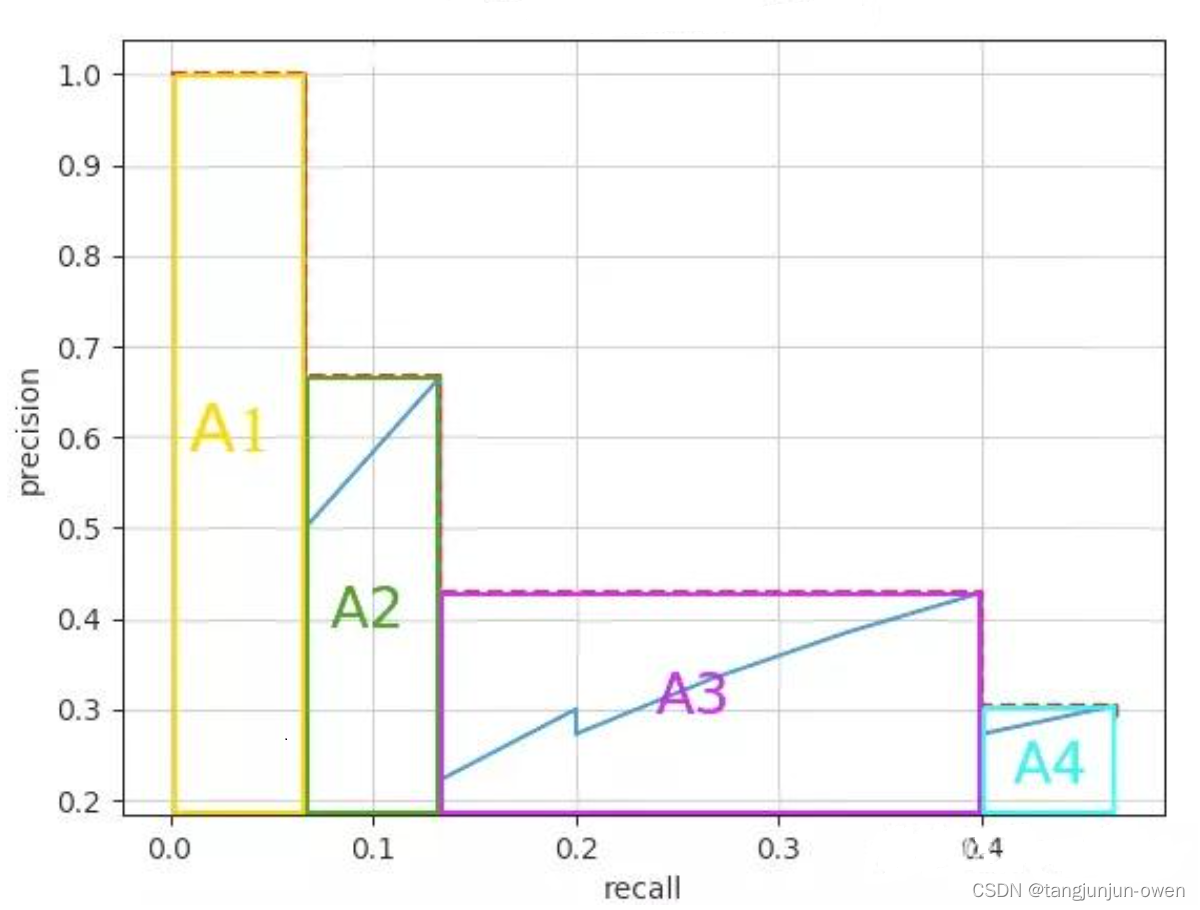
计算方法如下:

二、mAP0.5与mAP0.5:0.95
1、mAP0.5
mAP@0.5: mean Average Precision(IoU=0.5)
即将IoU设为0.5时,计算每一类的所有图片的AP,然后所有类别求平均,即mAP。
2、mAP0.5:0.95
mAP@.5:.95(mAP@[.5:.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
三、mAP代码实现
实现mAP计算,我们需要有已知真实标签与模型预测标签,我将介绍2部分,第一部分如何使用有标记的真实数据产生coco json格式与如何使用模型预测结果产生预测json格式,第二部分如何使用代码计算map。
1、真实标签json文件格式
真实数据json格式实际是coco json 格式,我将以图方式说明。
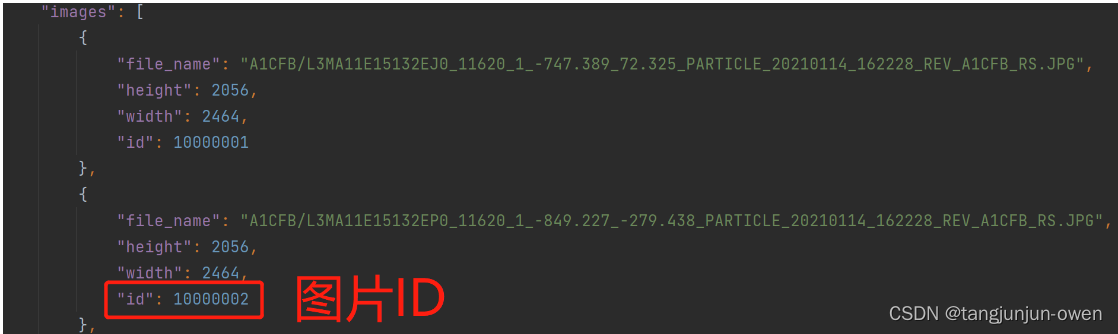
整体json格式内容,包含images、type、annotations、categories,如下图:

images内容如下图:
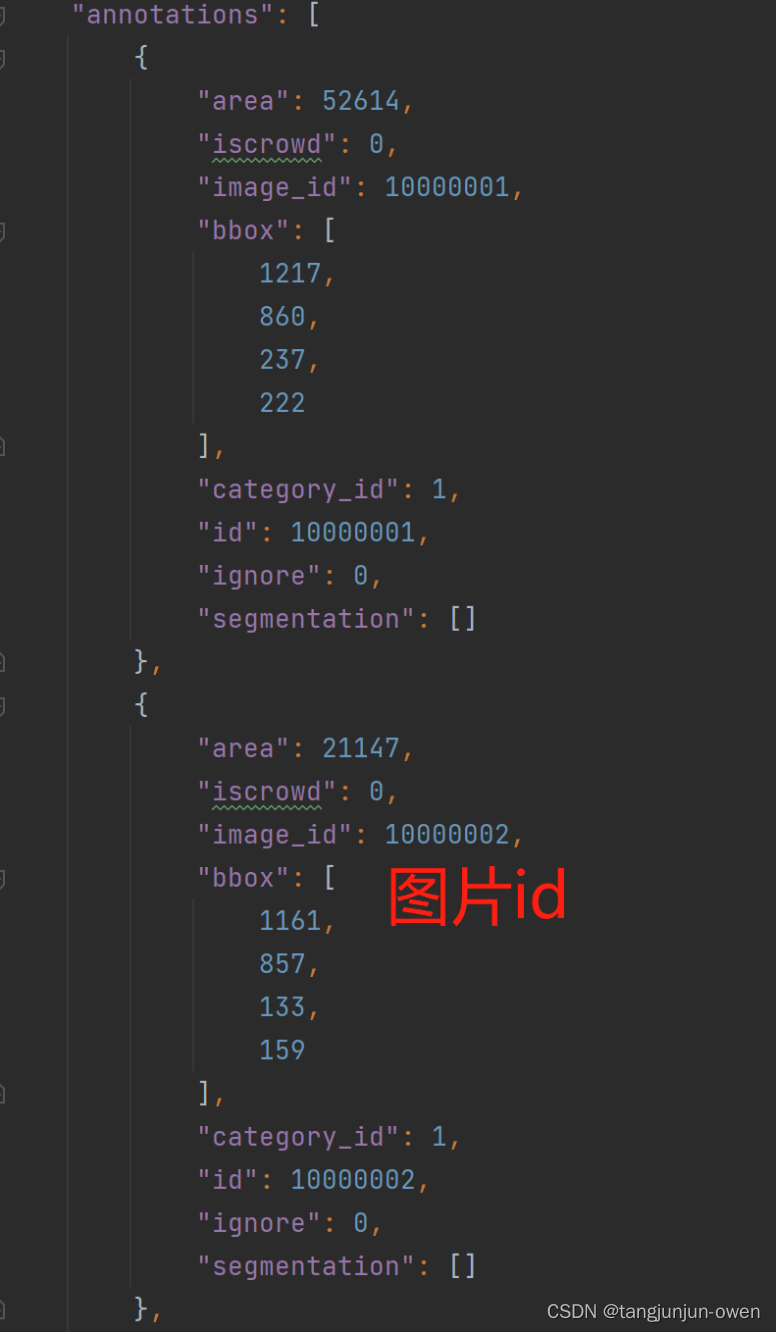
annotations内容如下图:
categories格式为:
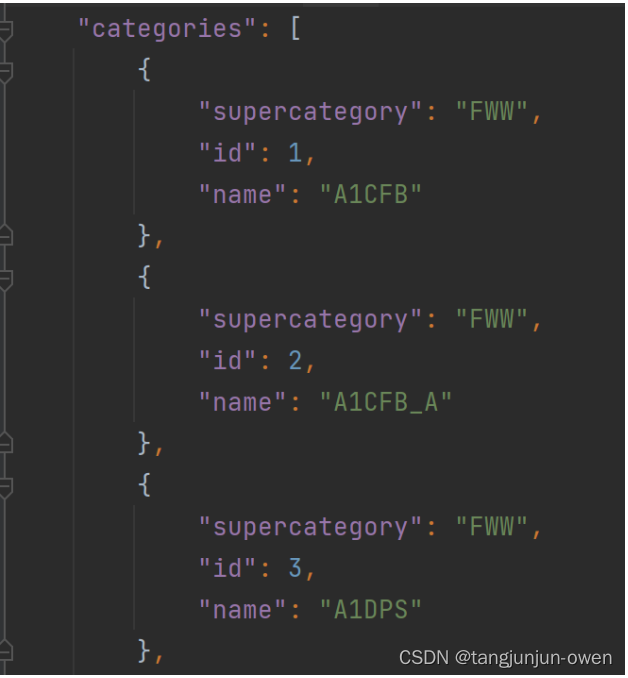
以上为真实数据转换为json的格式。
2、模型预测标签json文件格式
预测结果数据json为列表,列表保存为字典,一个字典记录一个目标,整体json格式如下图:
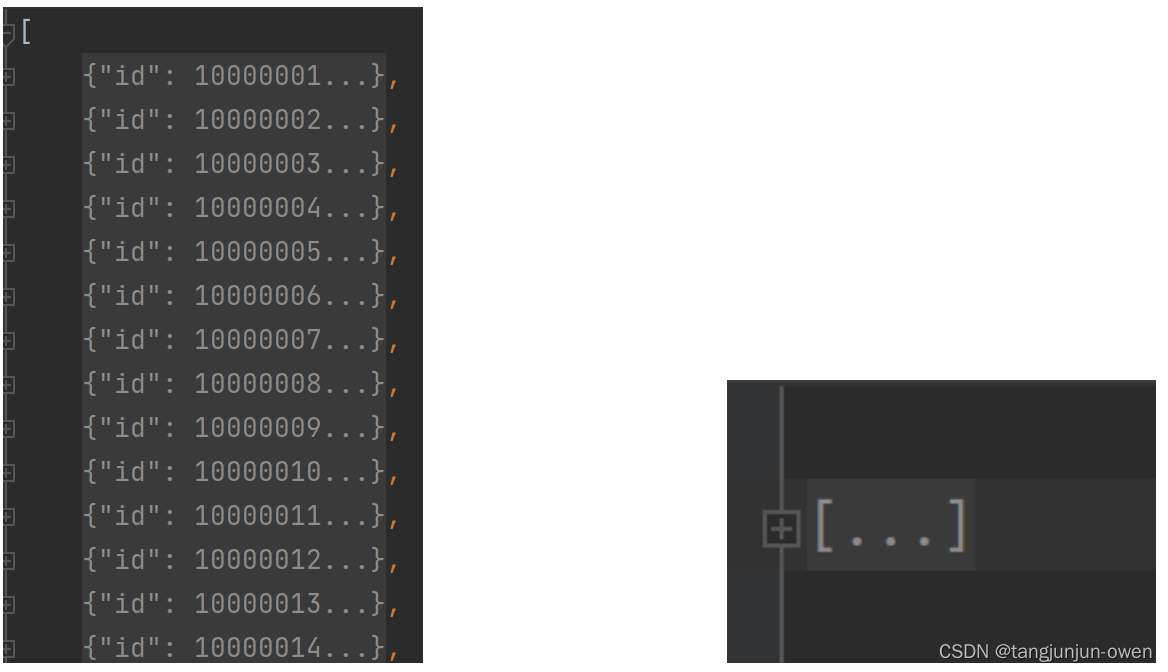
列表中字典内容如下图显示:
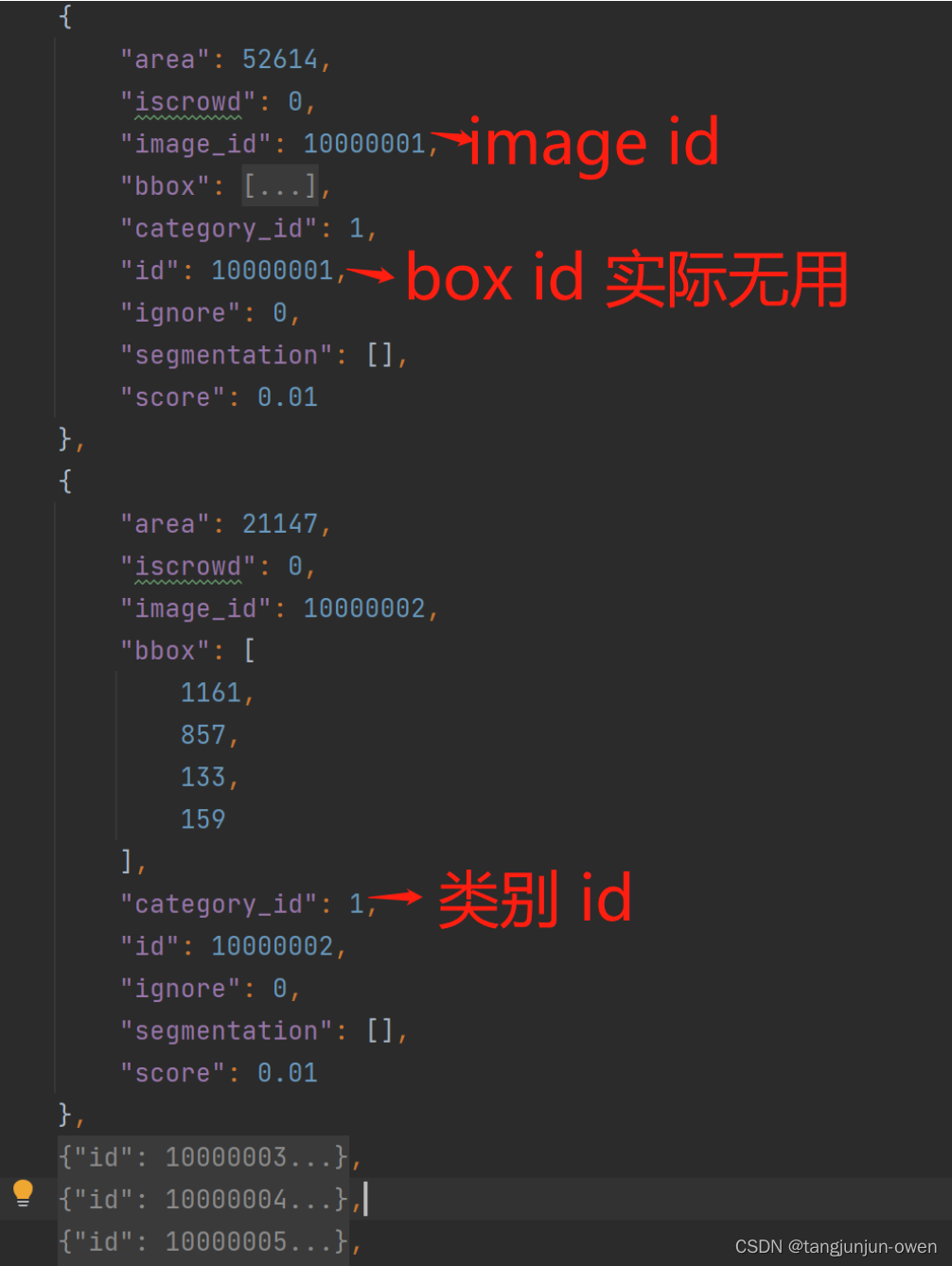
特别注意:image id 对应真实coco json图像的image-id,类别id也是对应真实coco json中的类别id。
3、mAP代码实现
我们调用pycocotool库中集成map方法,按照以上给出gt与pred的json格式,可实现map计算,其详细代码如下:
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
if __name__ == "__main__":
cocoGt = COCO('coco_json_format.json') #标注文件的路径及文件名,json文件形式
cocoDt = cocoGt.loadRes('predect_format.json') #自己的生成的结果的路径及文件名,json文件形式
cocoEval = COCOeval(cocoGt, cocoDt, "bbox")
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
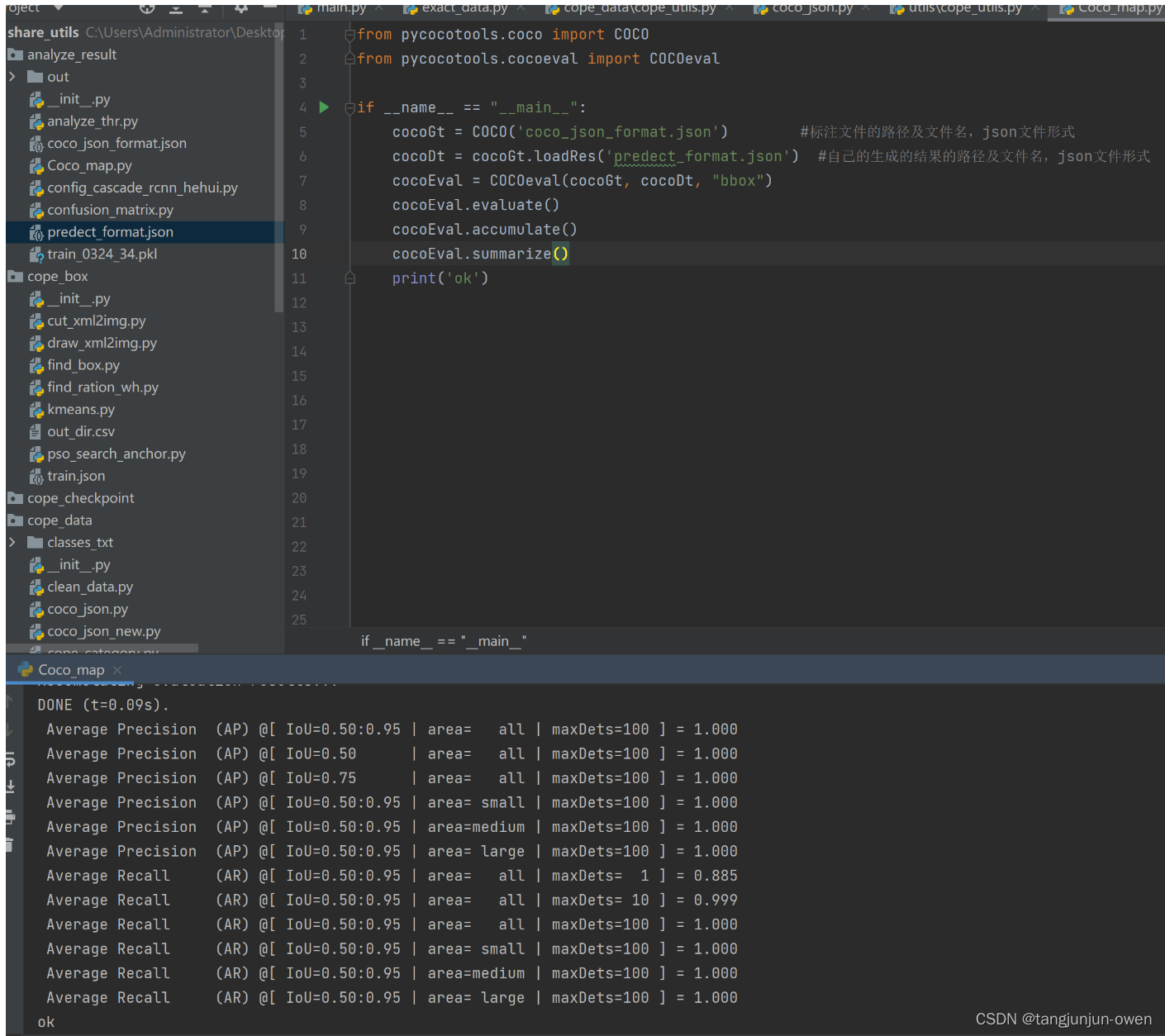
4、mAP结果显示
我使用gt与pred为相同信息,为此结果为1。
四、模型集成mAP代码
最后,我是将mAP代码集成多个检测模型,我也在这里大致介绍如何集成模型预测mAP。
1、模型main函数
以下代码展示,检测模型输出后如何集成Computer_map()函数计算mAP方法,我已在代码中有解释,其详情如下:
def computer_main(data_root, model):
'''
data_root:任何文件夹,但必须保证每个图片与对应xml必须放在同一个文件夹中
model:模型,用于预测
'''
C = Computer_map()
img_root_lst = C.get_img_root_lst(data_root) # 获得图片绝对路径与图片产生image_id映射关系
# 在self.coco_json中保存categories,便于产生coco_json和predetect_json
categories = model.CLASSES # 可以给txt路径读取,或直接给列表 #*********************得到classes,需要更改的地方***********##
C.get_categories(categories)
# 产生coco_json格式
xml_root_lst = [name[:-3] + 'xml' for name in img_root_lst]
for xml_root in xml_root_lst: C.xml2cocojson(xml_root) # 产生coco json 并保存到self.coco_json中
# 产生预测的json
for img_path in img_root_lst:
parse_result = predict(model, img_path) ####**********************需要更改的地方***********************####
result, classes = parse_result['result'], parse_result['classes']
# restult 格式为列表[x1,y1,x2,y2,score,label],若无结果为空
img_name = C.get_strfile(img_path)
C.detect2json(result, img_name)
C.computer_map() # 计算map
2、模型mAP计算代码
以下代码为Computer_map()函数计算mAP方法,我已在代码中有解释,其详情如下:
class Computer_map():
'''
主代码样列
def computer_main(data_root, model):#data_root:任何文件夹,但必须保证每个图片与对应xml必须放在同一个文件夹中,model:模型,用于预测
C = Computer_map()
img_root_lst = C.get_img_root_lst(data_root) # 获得图片绝对路径与图片产生image_id映射关系
# 在self.coco_json中保存categories,便于产生coco_json和predetect_json
categories = model.CLASSES # 可以给txt路径读取,或直接给列表 #*********************得到classes,需要更改的地方***********##
C.get_categories(categories)
# 产生coco_json格式
xml_root_lst = [name[:-3] + 'xml' for name in img_root_lst]
for xml_root in xml_root_lst: C.xml2cocojson(xml_root) # 产生coco json 并保存到self.coco_json中
# 产生预测的json
for img_path in img_root_lst:
parse_result = predict(model, img_path) ####**********************需要更改的地方***********************####
result, classes = parse_result['result'], parse_result['classes']
# restult 格式为列表[x1,y1,x2,y2,score,label],若无结果为空
img_name = C.get_strfile(img_path)
C.detect2json(result, img_name)
C.computer_map() # 计算map
'''
def __init__(self):
self.img_format = ['png', 'jpg', 'JPG', 'PNG', 'bmp', 'jpeg']
self.coco_json = {'images': [], 'type': 'instances', 'annotations': [], 'categories': []}
self.predetect_json = [] # 保存字典
self.image_id = 10000000 # 图像的id,每增加一张图片便+1
self.anation_id = 10000000
self.imgname_map_id = {} # 图片名字映射id
def read_txt(self, file_path):
with open(file_path, 'r') as f:
content = f.read().splitlines()
return content
def get_categories(self, categories):
'''
categories:为字符串,指绝对路径;为列表,指类本身
return:将categories存入coco json中
'''
if isinstance(categories, str):
categories = self.read_txt(categories)
elif isinstance(categories, list or tuple):
categories = list(categories)
category_json = [{"supercategory": cat, "id": i + 1, "name": cat} for i, cat in enumerate(categories)]
self.coco_json['categories'] = category_json
def computer_map(self, coco_json_path=None, predetect_json_path=None):
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
from collections import defaultdict
import time
import json
from pycocotools import mask as maskUtils
import numpy as np
# 继承修改coco json文件
class COCO_modify(COCO):
def __init__(self, coco_json_data=None):
"""
Constructor of Microsoft COCO helper class for reading and visualizing annotations.
:param annotation_file (str): location of annotation file
:param image_folder (str): location to the folder that hosts images.
:return:
"""
# load dataset
self.dataset, self.anns, self.cats, self.imgs = dict(), dict(), dict(), dict()
self.imgToAnns, self.catToImgs = defaultdict(list), defaultdict(list)
if coco_json_data is not None:
print('loading annotations into memory...')
tic = time.time()
if isinstance(coco_json_data, str):
with open(coco_json_data, 'r') as f:
dataset = json.load(f)
assert type(dataset) == dict, 'annotation file format {} not supported'.format(type(dataset))
print('Done (t={:0.2f}s)'.format(time.time() - tic))
else:
dataset = coco_json_data
self.dataset = dataset
self.createIndex()
def loadRes(self, predetect_json_data):
import copy
"""
Load result file and return a result api object.
:param resFile (str) : file name of result file
:return: res (obj) : result api object
"""
res = COCO_modify()
res.dataset['images'] = [img for img in self.dataset['images']]
print('Loading and preparing results...')
tic = time.time()
if isinstance(predetect_json_data, str):
with open(predetect_json_data, 'r') as f:
anns = json.load(f)
print('Done (t={:0.2f}s)'.format(time.time() - tic))
else:
anns = predetect_json_data
assert type(anns) == list, 'results in not an array of objects'
annsImgIds = [ann['image_id'] for ann in anns]
assert set(annsImgIds) == (set(annsImgIds) & set(self.getImgIds())), \
'Results do not correspond to current coco set'
if 'caption' in anns[0]:
imgIds = set([img['id'] for img in res.dataset['images']]) & set([ann['image_id'] for ann in anns])
res.dataset['images'] = [img for img in res.dataset['images'] if img['id'] in imgIds]
for id, ann in enumerate(anns):
ann['id'] = id + 1
elif 'bbox' in anns[0] and not anns[0]['bbox'] == []:
res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])
for id, ann in enumerate(anns):
bb = ann['bbox']
x1, x2, y1, y2 = [bb[0], bb[0] + bb[2], bb[1], bb[1] + bb[3]]
if not 'segmentation' in ann:
ann['segmentation'] = [[x1, y1, x1, y2, x2, y2, x2, y1]]
ann['area'] = bb[2] * bb[3]
ann['id'] = id + 1
ann['iscrowd'] = 0
elif 'segmentation' in anns[0]:
res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])
for id, ann in enumerate(anns):
# now only support compressed RLE format as segmentation results
ann['area'] = maskUtils.area(ann['segmentation'])
if not 'bbox' in ann:
ann['bbox'] = maskUtils.toBbox(ann['segmentation'])
ann['id'] = id + 1
ann['iscrowd'] = 0
elif 'keypoints' in anns[0]:
res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])
for id, ann in enumerate(anns):
s = ann['keypoints']
x = s[0::3]
y = s[1::3]
x0, x1, y0, y1 = np.min(x), np.max(x), np.min(y), np.max(y)
ann['area'] = (x1 - x0) * (y1 - y0)
ann['id'] = id + 1
ann['bbox'] = [x0, y0, x1 - x0, y1 - y0]
print('DONE (t={:0.2f}s)'.format(time.time() - tic))
res.dataset['annotations'] = anns
res.createIndex()
return res
coco_json_data = coco_json_path if coco_json_path is not None else self.coco_json
cocoGt = COCO_modify(coco_json_data) # 标注文件的路径及文件名,json文件形式
predetect_json_data = predetect_json_path if predetect_json_path is not None else self.predetect_json
cocoDt = cocoGt.loadRes(predetect_json_data) # 自己的生成的结果的路径及文件名,json文件形式
cocoEval = COCOeval(cocoGt, cocoDt, "bbox")
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
def get_img_root_lst(self, root_data):
import os
img_root_lst = []
for dir, file, names in os.walk(root_data):
img_lst = [os.path.join(dir, name) for name in names if name[-3:] in self.img_format]
img_root_lst = img_root_lst + img_lst
for na in img_lst: # 图片名字映射image_id
self.image_id += 1
self.imgname_map_id[self.get_strfile(na)] = self.image_id
return img_root_lst # 得到图片绝对路径
def get_strfile(self, file_str, pos=-1):
'''
得到file_str / or \\ 的最后一个名称
'''
endstr_f_filestr = file_str.split('\\')[pos] if '\\' in file_str else file_str.split('/')[pos]
return endstr_f_filestr
def read_xml(self, xml_root):
'''
:param xml_root: .xml文件
:return: dict('cat':['cat1',...],'bboxes':[[x1,y1,x2,y2],...],'whd':[w ,h,d])
'''
import xml.etree.ElementTree as ET
import os
dict_info = {'cat': [], 'bboxes': [], 'box_wh': [], 'whd': []}
if os.path.splitext(xml_root)[-1] == '.xml':
tree = ET.parse(xml_root) # ET是一个xml文件解析库,ET.parse()打开xml文件。parse--"解析"
root = tree.getroot() # 获取根节点
whd = root.find('size')
whd = [int(whd.find('width').text), int(whd.find('height').text), int(whd.find('depth').text)]
xml_filename = root.find('filename').text
dict_info['whd'] = whd
dict_info['xml_filename'] = xml_filename
for obj in root.findall('object'): # 找到根节点下所有“object”节点
cat = str(obj.find('name').text) # 找到object节点下name子节点的值(字符串)
bbox = obj.find('bndbox')
x1, y1, x2, y2 = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
b_w = x2 - x1 + 1
b_h = y2 - y1 + 1
dict_info['cat'].append(cat)
dict_info['bboxes'].append([x1, y1, x2, y2])
dict_info['box_wh'].append([b_w, b_h])
else:
print('[inexistence]:{} suffix is not xml '.format(xml_root))
return dict_info
def xml2cocojson(self, xml_root):
'''
处理1个xml,将其真实json保存到self.coco_json中
'''
assert len(self.coco_json['categories']) > 0, 'self.coco_json[categories] must exist v'
categories = [cat_info['name'] for cat_info in self.coco_json['categories']]
xml_info = self.read_xml(xml_root)
if len(xml_info['cat']) > 0:
xml_filename = xml_info['xml_filename']
xml_name = self.get_strfile(xml_root)
img_name = xml_name[:-3] + xml_filename[-3:]
# 转为coco json时候,若add_file为True则在coco json文件的file_name增加文件夹名称+图片名字
image_id = self.imgname_map_id[img_name]
w, h, d = xml_info['whd']
# 构建json文件字典
image_json = {'file_name': img_name, 'height': h, 'width': w, 'id': image_id}
ann_json = []
for i, category in enumerate(xml_info['cat']):
# 表示有box存在,可以添加images信息
category_id = categories.index(category) + 1 # 给出box对应标签索引为类
self.anation_id = self.anation_id + 1
xmin, ymin, xmax, ymax = xml_info['bboxes'][i]
o_width, o_height = xml_info['box_wh'][i]
if (xmax <= xmin) or (ymax <= ymin):
print('code:[{}] will be abandon due to {} min of box w or h more than max '.format(category,
xml_root)) # 打印错误的box
else:
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id': image_id,
'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': self.anation_id, 'ignore': 0,
'segmentation': []}
ann_json.append(ann)
if len(ann_json) > 0: # 证明存在 annotation
for ann in ann_json: self.coco_json['annotations'].append(ann)
self.coco_json['images'].append(image_json)
def detect2json(self, predetect_result, img_name,score_thr=-1):
'''
predetect_result:为列表,每个列表中包含[x1, y1, x2, y2, score, label]
img_name: 图片的名字
'''
if len(predetect_result) > 0:
categories = [cat_info['name'] for cat_info in self.coco_json['categories']]
for result in predetect_result:
x1, y1, x2, y2, score, label = result
if score>score_thr:
w, h = int(x2 - x1), int(y2 - y1)
x1, y1 = int(x1), int(y1)
img_name_new = self.get_strfile(img_name)
image_id = self.imgname_map_id[img_name_new]
category_id = list(categories).index(label) + 1
detect_json = {
"area": w * h,
"iscrowd": 0,
"image_id": image_id,
"bbox": [
x1,
y1,
w,
h
],
"category_id": category_id,
"id": image_id,
"ignore": 0,
"segmentation": [],
"score": score
}
self.predetect_json.append(detect_json)
def write_json(self,out_dir):
import os
import json
coco_json_path=os.path.join(out_dir,'coco_json_data.json')
with open(coco_json_path, 'w') as f:
json.dump(self.coco_json, f, indent=4) # indent表示间隔长度
predetect_json_path=os.path.join(out_dir,'predetect_json_data.json')
with open(predetect_json_path, 'w') as f:
json.dump(self.predetect_json, f, indent=4) # indent表示间隔长度
原理参考博客点击这里