url
aHR0cHM6Ly9wYXNzcG9ydC41MS5jb20vP2dvdXJsPWh0dHBzOi8vd2FuLjUxLmNvbS92dWUvaW5kZXg=
接口分析
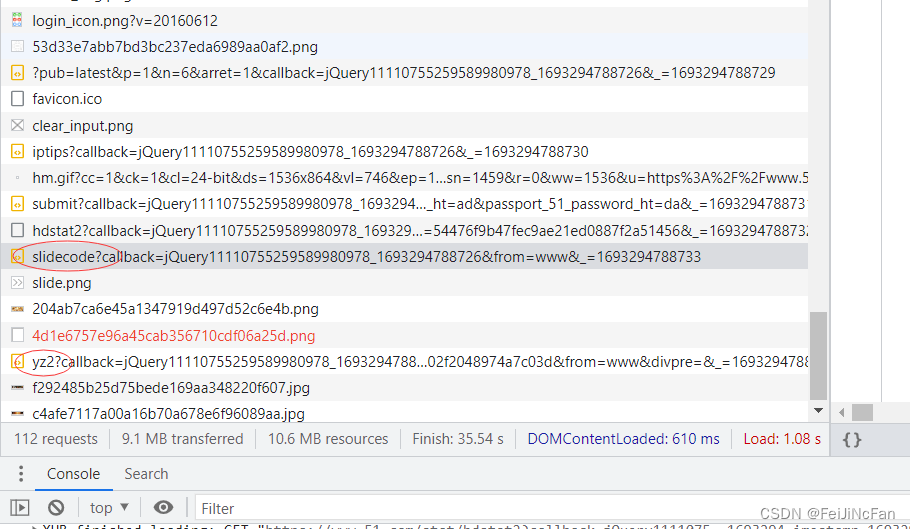
圈起来的两个接口,一个拿滑块,一个验证。
参数分析
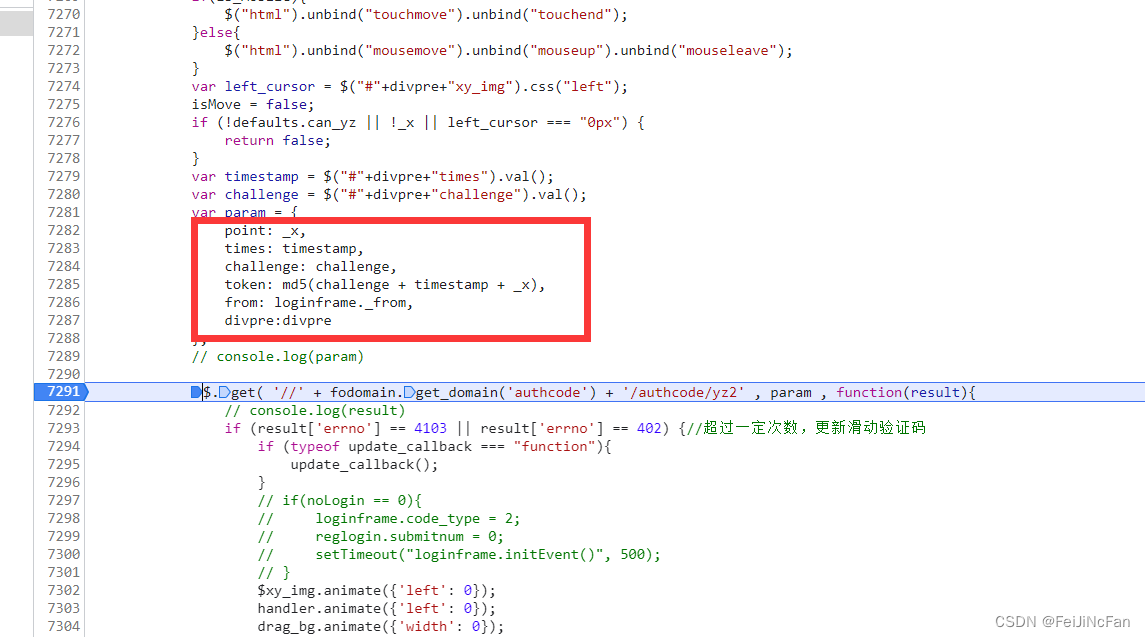
没用特别难的加密
验证识别
需要注意的是,我们先拿到的图片是混乱的,需要按行来抠图。
如下:

识别可以采用cv2或者ddddocr
完整代码
# -*- coding: utf-8 -*-
# @Time : 29/8/2023 上午 11:22
# @Author : 明月清风我
# @File : main.py
# @Software: PyCharm
import hashlib
import json
import cv2
import requests
import re
from PIL import Image
import io
import time
import loguru
import ddddocr
def copy_headers_dict(headers_raw):
if headers_raw is None:
return None
headers = headers_raw.splitlines()
headers_tuples = [header.split(":", 1) for header in headers]
result_dict = {}
for header_item in headers_tuples:
if not len(header_item) == 2:
continue
item_key = header_item[0].strip()
item_value = header_item[1].strip()
result_dict[item_key] = item_value
return result_dict
def identify_gap(bg, tp):
# 读取背景图片和缺口图片
bg_img = cv2.imread(bg) # 背景图片
tp_img = cv2.imread(tp) # 缺口图片
# 识别图片边缘
bg_edge = cv2.Canny(bg_img, 100, 200)
tp_edge = cv2.Canny(tp_img, 100, 200)
# 转换图片格式
bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)
tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)
# 缺口匹配
res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配
# 绘制方框
th, tw = tp_pic.shape[:2]
tl = max_loc # 左上角点的坐标
# 返回缺口的X坐标
return tl[0]
def identify_gap1(bg, tp):
det = ddddocr.DdddOcr(det=False, ocr=False, show_ad=False)
with open(tp, 'rb') as f:
target_bytes = f.read()
with open(bg, 'rb') as f:
background_bytes = f.read()
_x = str(det.slide_match(target_bytes, background_bytes, simple_target=True)['target'][0])
return _x
requests = requests.session()
headers = copy_headers_dict("""
Host: authcode.51.com
Pragma: no-cache
Referer: https://passport.51.com/?gourl=https://wan.51.com/vue/index
sec-ch-ua: "Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Sec-Fetch-Dest: script
Sec-Fetch-Mode: no-cors
Sec-Fetch-Site: same-site
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
""")
def main():
cnt = 0
for _ in range(100):
time.sleep(0.3)
slidecode_url = "https://authcode.51.com/authcode/slidecode"
params={
'callback': 'jQuery1111011556910494181394_1693292335405',
'from': 'passport',
'_': str(int(time.time())*1000)
}
response = requests.get(slidecode_url, headers=headers, params=params)
challenge=re.compile('<input.*?challenge.*?value=(.*?)>').findall(response.text)[0].replace('\\"','')
times=re.compile('<input.*?times.*?value=(.*?)>').findall(response.text)[0].replace('\\"','')
big_img_url = "https:" + re.compile('url\((.*?)\)').findall(response.text)[0].replace("\/","/")[2:-2]
small_img_url = "https:" + re.compile('url\((.*?)\)').findall(response.text)[1].replace("\/","/")
positions= re.compile("class='gt_cut_fullbg_slice' style='background-position:(.*?)px (.*?)px;'>").findall(response.text)
pos_lists=[]
for ps in positions:
x=int(ps[0])
y=int(ps[1])
pos_lists.append({"x":x,"y":y})
bg_img = requests.get(big_img_url).content
small_img= requests.get(small_img_url).content
bg_img=io.BytesIO(bg_img)
im = Image.open(bg_img)
with open('target.png','wb')as f:
f.write(small_img)
#取整用int 去绝对值也就是去除负号abs
new_pos=[]
for pos in pos_lists:
if pos['y'] == -75:
new_pos.append(im.crop((abs(pos['x']), 75, abs(pos['x']) + 13, 100)))
if pos['y'] == -50:
new_pos.append(im.crop((abs(pos['x']), 50, abs(pos['x']) + 13, 75)))
if pos['y'] == -25:
new_pos.append(im.crop((abs(pos['x']), 25, abs(pos['x']) + 13, 50)))
if pos['y'] == 0:
new_pos.append(im.crop((abs(pos['x']), 0, abs(pos['x']) + 13, 25)))
new_im = Image.new('RGB', (260, 100))
x_offset = 0
y_offset=0
for im in new_pos:
if (x_offset==260):
x_offset=0
y_offset+=25
new_im.paste(im, (x_offset, y_offset))
x_offset += 13
new_im.save('./{}.png'.format('background'))
# _x = str(identify_gap1('target.png', 'background.png'))
_x = str(identify_gap('target.png', 'background.png'))
my_time=int(time.time()*1000)
submit_url='https://authcode.51.com/authcode/yz2'
loguru.logger.info(_x)
params={
'callback': 'jQuery1111011556910494181394_'+str(my_time),
'point': _x,
'times': times,
'challenge': challenge,
'token': hashlib.md5((challenge+times+_x).encode('utf8')).hexdigest(),
'from': 'passport',
'divpre':'',
'_': str(my_time +6)
}
resp=requests.get(submit_url,params=params,headers=headers)
loguru.logger.info(json.loads(resp.text[len("jQuery1111011556910494181394_1693292857236("):-2]))
loguru.logger.info(json.loads(resp.text[len("jQuery1111011556910494181394_1693292857236("):-2])['errno'])
if json.loads(resp.text[len("jQuery1111011556910494181394_1693292857236("):-2])['errno'] == 0:
cnt += 1
loguru.logger.info(str(cnt/100*100) + "%" )
if __name__ == '__main__':
main()
# 2023-08-29 15:12:54.831 | INFO | __main__:<module>:147 - {'errno': 401, 'error': '抱歉错误', 'data': []}
# 2023-08-29 15:12:54.832 | INFO | __main__:<module>:148 - 401
# 2023-08-29 15:12:54.832 | INFO | __main__:<module>:151 - 17
# 2023-08-29 15:12:54.832 | INFO | __main__:<module>:152 - 17.0%

成功率偏低,校验比较严格,_x相差1可能都过不了了。