目录
1.变量(数据)类型转换
1.1 字符
1.2 字符串
1.3 逻辑操作与赋值
2.Struct结构体数组
2.1函数的详细介绍:
2.1.1 cell2struct
2.1.1.1 垂直维度转换
2.1.1.2 水平维度转换
2.1.1.3 部分进行转换
2.1.2 rmfield
2.1.3 fieldnames(查看结构体中的属性值)
3. 嵌套结构
4.Cell元胞数组
4.1创建对象以及访问
4.2 Cell元胞数组函数
4.2.1 num2cell(转换为相同大小的元胞数组)
4.2.2 matcell(转换为在元胞中包含子数组的元胞数组)
5. 多维数组
5.1 cat()函数
5.2 reshape()函数
6.文件访问
6.1 save()
6.2 load()
7.Excel文件读取
7.1 xlsread()
7.2 xlswrite()
7.3 低级文件的输入/输出
1.变量(数据)类型转换
| double() | 转换为双精度 |
| single() | 转换为单精度 |
| int8() | 转换为8位有符号整数 |
| int16() | 转换为16位有符号整数 |
| int32() | 转换为32位有符号整数 |
| int64() | 转换为64位有符号整数 |
| uint8() | 转换为8位无符号整数 |
| uint16() | 转换为16位无符号整数 |
| uint32() | 转换为32位无符号整数 |
| uint64() | 转换为64位无符号整数 |
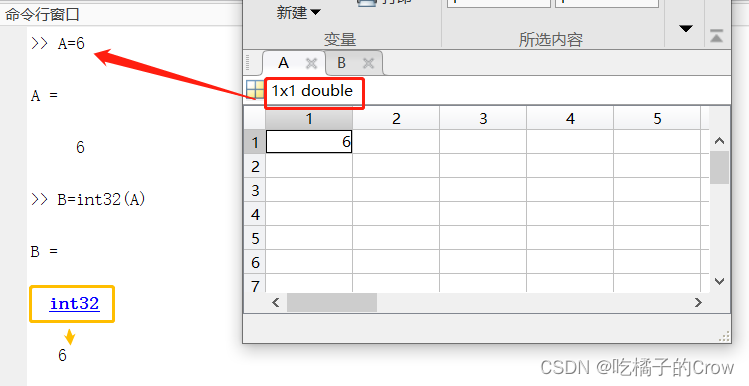
在Matlab中我们可以直接对类型进行转换:
1.1 字符
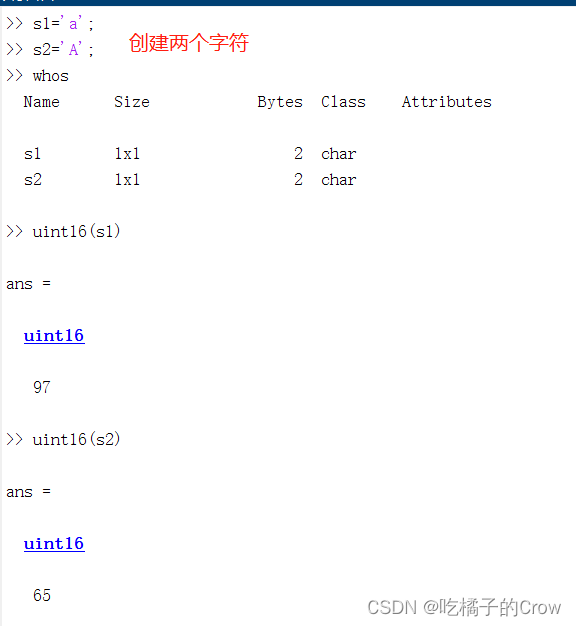
在Matlab中,字符是由引号(单引号或者双引号)括起来的表达式,字符可以包含字母、数字、符号和空格,用于表示文本数据,每一个字符都对应着一个ASSCII码值
1.2 字符串
在MATLAB中,字符串是由引号(单引号或双引号)括起来的字符序列。字符串可以包含字母、数字、符号和空格,用于表示文本数据。

我们在前面讲过怎么将矩阵进行合并,今天我们试着将字符串进行拼接:
- 用方括号进行拼接
水平拼接:
>> s1='Lingda'
s1 =
'Lingda'
>> s2='lisi'
s2 =
'lisi'
>> s3=[s1,s2]
s3 =
'Lingdalisi'垂直拼接:

显然这种方式是错误的,因为两个字符串的长度不一致,故维度不一致,这种拼接的方式仅限于长度一致的字符串才可以进行拼接
>> s3=[s1;s1]
s3 =
2×6 char 数组
'Lingda'
'Lingda'- 用函数进行拼接
垂直拼接:
>> s3=vertcat(s1,s1)
s3 =
2×6 char 数组
'Lingda'
'Lingda'水平拼接:
>> s3=horzcat(s1,s1)
s3 =
'LingdaLingda'
>> s3=horzcat(s1,s2)
s3 =
'Lingdalisi'1.3 逻辑操作与赋值
在数组中每个位置代表的着一个对应的索引,字符串也不例外,一个单个的字符也对应着一个索引
>> str='aadfgtaad'
str =
'aadfgtaad'
>> str(3)
ans =
'd'在Matlab中索引的位置是从1开始的,所以索引为3的位置上是'd'
假设我们要寻找字符为'a'的索引有哪些?该怎么去找呢?
>> 'a'==str
ans =
1×9 logical 数组
1 1 0 0 0 0 1 1 0
>> str=='a'
ans =
1×9 logical 数组
1 1 0 0 0 0 1 1 0这种查找方法,如果匹配的话,索引位置上为1,不匹配的话为0
如果我们需要对两个字符串进行比较,我们需要用strcmp()函数
>> help strcmp
strcmp - 比较字符串
此 MATLAB 函数 比较 s1 和 s2,如果二者相同,则返回 1 (true),否则返回 0
(false)。如果文本的大小和内容相同,则它们将视为相等。返回结果 tf 的数据类型为 logical。
tf = strcmp(s1,s2)>> s1='happy'
s1 =
'happy'
>> s2='happy'
s2 =
'happy'
>> strcmp(s1,s2)
ans =
logical
1如何去反转一个字符串:

%方法一:
>> s1='I like beautiful gril'
s1 =
'I like beautiful gril'
>> s2=s1(size(s1,2):-1:1)
s2 =
'lirg lufituaeb ekil I'
%方法二:
>> s2=s1(length(s1):-1:1)
s2 =
'lirg lufituaeb ekil I'
%方法三:
>> help reverse
reverse - 反转字符串中的字符顺序
此 MATLAB 函数 反转 str 中字符的顺序。
newStr = reverse(str)
>> reverse(s1)
ans =
'lirg lufituaeb ekil I'
%方法四:
>> help flip
flip - 翻转元素顺序
此 MATLAB 函数 返回的数组 B 具有与 A 相同的大小,但元素顺序已反转。B 中重新排序的维度取决于 A 的形状:
B = flip(A)
B = flip(A,dim)
>> flip(s2)
ans =
'I like beautiful gril'
2.Struct结构体数组
在MATLAB中,结构体是一种用于存储和组织数据的数据类型。结构体由多个字段组成,每个字段都可以存储不同类型的数据。
以下是一些关于结构体的基本操作:
- 创建结构体:
s.field1 = value1;
s.field2 = value2;- 访问结构体字段:
value = s.field;- 更新结构体字段的值:
s.field = new_value;- 删除结构体字段:
s = rmfield(s, 'field');- 检查结构体是否包含某个字段:
isfield(s, 'field');- 获取结构体的字段名称:
field_names = fieldnames(s);- 创建结构体数组:
s(1).field = value1;
s(2).field = value2;- 访问结构体数组的元素:
value = s(index).field;对Java了解过的同学很容易将结构体将Java中的类想在一起,两者都是可以存储不同数据,对象以及属性
让我们接下来手动创建一个结构体:
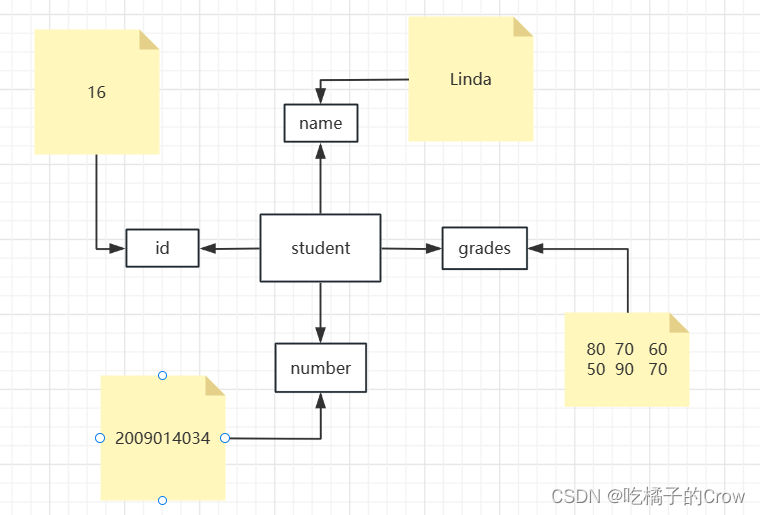
>> student.name='Linda';
>> student.id=16;
>> student.number=2009014034;
>> student.grades=[80 70 60;50 90 70]
student =
包含以下字段的 struct:
name: 'Linda'
id: 16
number: 2.0090e+09
grades: [2×3 double]我们可以通过 . 的方式拿到结构体中的特定值
>> student.grades
ans =
80 70 60
50 90 70
>> student.name
ans =
'Linda'那么结构体中是不是只允许有一个数据呢?NONONO,当然不是,只是我们需要和第一种数据做区分而已
>> student(2).name='Lisi';%用(number)进行区分
student(2).id=18;
student(2).number=2009014036;
>> student(2).grades=[90 50 60;40 80 60]
student =
包含以下字段的 1×2 struct 数组:
name
id
number
grades>> student(2)
ans =
包含以下字段的 struct:
name: 'Lisi'
id: 18
number: 2.0090e+09
grades: [2×3 double]
>> student(1)
ans =
包含以下字段的 struct:
name: 'Linda'
id: 16
number: 2.0090e+09
grades: [2×3 double]| cell2struct | 将单元格数组转换为结构数组 |
| fieldnames | 结构的字段名或对象的公共字段 |
| getfield | 结构体数组字段 |
| isfield | 确定输入是否为结构体数组字段 |
| isstruct | 确定输入是否为结构数组 |
| orderfields | 结构数组的顺序字段 |
| rmfield | 从结构中删除字段 |
| setfield | 给结构数组字段赋值 |
| struct | 创建结构数组 |
| struct2cell | 将结构转换为单元格数组 |
| structfun | 对标量结构的每个域应用函数 |
2.1函数的详细介绍:
2.1.1 cell2struct
structArray = cell2struct(cellArray, fields, dim)
%structArray = cell2struct(cellArray, fields, dim) 通过元胞数组 cellArray 中包含的信息创建一个结构体数组 structArray。
%fields 参数指定结构体数组的字段名称。此参数是一个字符数组、字符向量元胞数组或字符串数组。
%dim 参数向 MATLAB® 指示创建结构体数组时要使用的元胞数组的轴。使用数值 double 指定 dim。案例:

创建初始元胞数组employees:
>> devel = {{'Lee','Reed','Hill'}, {'Dean','Frye'}, ...
{'Lane','Fox','King'}};
sales = {{'Howe','Burns'}, {'Kirby','Ford'}, {'Hall'}};
mgmt = {{'Price'}, {'Clark','Shea'}, {'Sims'}};
qual = {{'Bates','Gray'}, {'Nash'}, {'Kay','Chase'}};
docu = {{'Lloyd','Young'}, {'Ryan','Hart','Roy'}, {'Marsh'}};
>> employees = [devel; sales; mgmt; qual; docu]
employees =
5×3 cell 数组
{1×3 cell} {1×2 cell} {1×3 cell}
{1×2 cell} {1×2 cell} {1×1 cell}
{1×1 cell} {1×2 cell} {1×1 cell}
{1×2 cell} {1×1 cell} {1×2 cell}
{1×2 cell} {1×3 cell} {1×1 cell}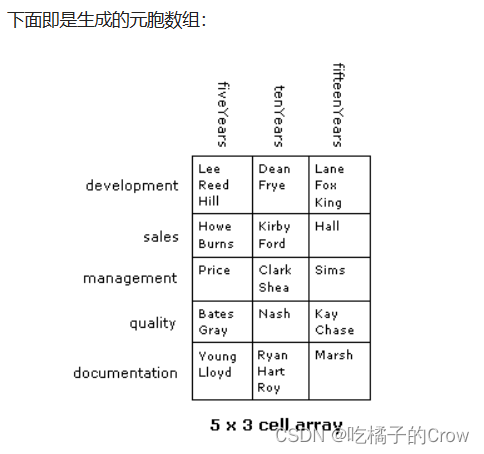
2.1.1.1 垂直维度转换
将元胞数组转换为沿维度1(垂直维度)的结构体:

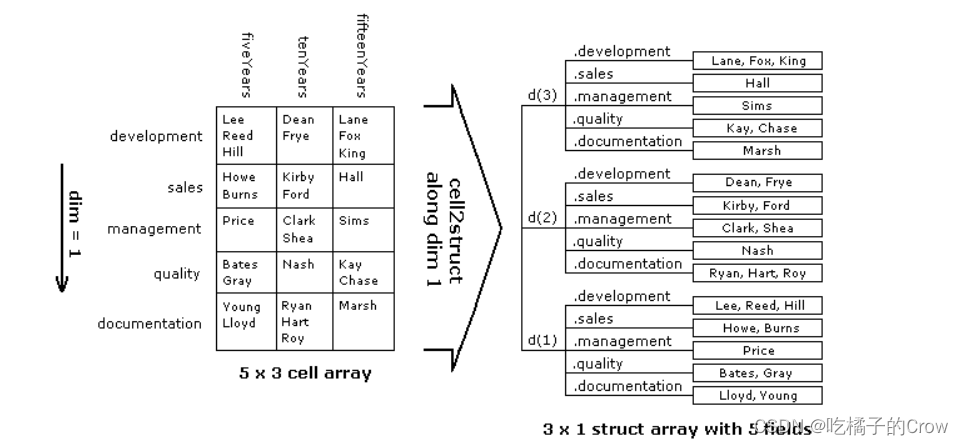
我们需要自定义垂直维度中的每行的标题:
>> rowTitles={'development', 'sales', 'management','quality', 'documentation'}
rowTitles =
1×5 cell 数组
{'development'} {'sales'} {'management'} {'quality'} {'documentation'}将元胞数组转换为于此维度相关的结构体数组dept:
>> depts = cell2struct(employees, rowTitles, 1)
depts =
包含以下字段的 3×1 struct 数组:
development
sales
management
quality
documentation查找特定数值:
>> depts(2:3).development%先确定行再确定哪个属性
ans =
1×2 cell 数组
{'Dean'} {'Frye'}
ans =
1×3 cell 数组
{'Lane'} {'Fox'} {'King'}2.1.1.2 水平维度转换
将元胞数组转换为沿维度2(水平维度)的结构体:
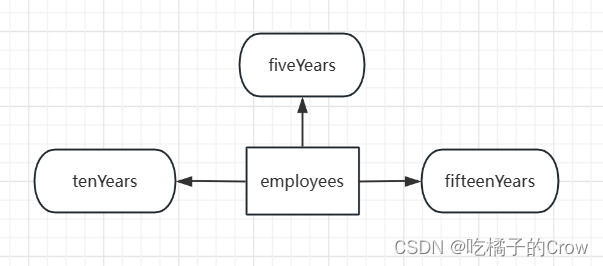
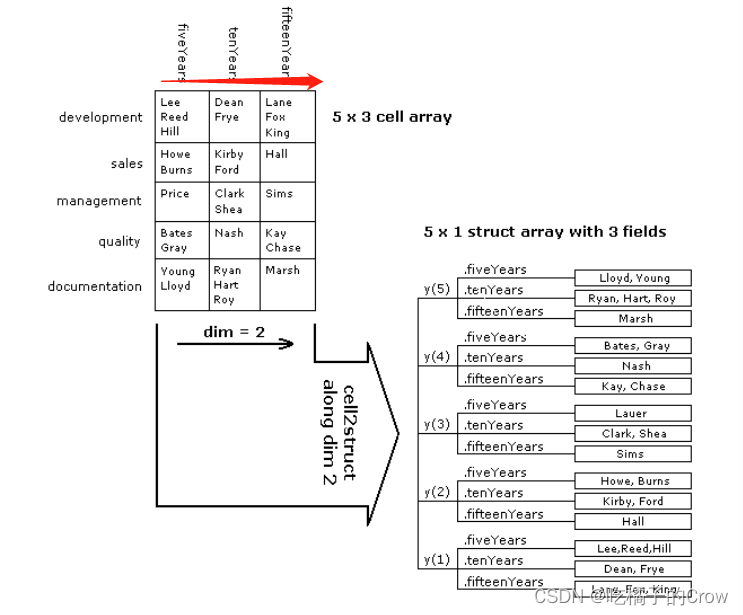
我们需要自定义水平维度中的每行的标题:
>> colHeadings = {'fiveYears' 'tenYears' 'fifteenYears'}
colHeadings =
1×3 cell 数组
{'fiveYears'} {'tenYears'} {'fifteenYears'}将元胞数组转换为于此维度相关的结构体数组dept:
>> years = cell2struct(employees, colHeadings, 2)
years =
包含以下字段的 5×1 struct 数组:
fiveYears
tenYears
fifteenYears使用列向结构体时,将显示已在公司工作至少 5 年的销售和文件部门的员工数
[~, sales_5years, ~, ~, docu_5years] = years.fiveYears
sales_5years =
1×2 cell 数组
{'Howe'} {'Burns'}
docu_5years =
1×2 cell 数组
{'Lloyd'} {'Young'}在上方进行查找的时候,将不需要的列用占位符进行占位,不然会造成错误:
[ sales_5years, docu_5years] = years.fiveYears
sales_5years =
1×3 cell 数组
{'Lee'} {'Reed'} {'Hill'}
docu_5years =
1×2 cell 数组
{'Howe'} {'Burns'}2.1.1.3 部分进行转换
如果我们仅仅要转换元胞数组的第一行和最后一行,我们该怎么操作呢?
>> rowTitlesOnly={'develop','document'}
rowTitlesOnly =
1×2 cell 数组
{'develop'} {'document'}
>> depts=cell2struct(employees([1,5],:),rowTitlesOnly,1)
depts =
包含以下字段的 3×1 struct 数组:
develop
document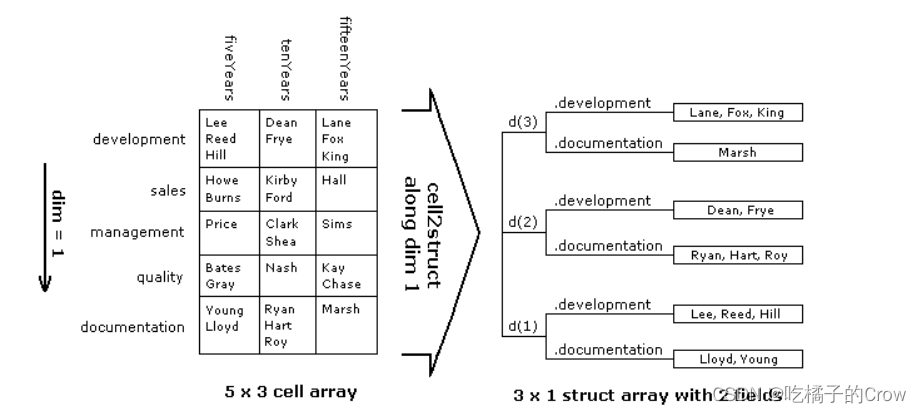
如果我们想知道结构体中有哪些人员,我们只需要这样就可以解决:
>> for k=1:3
depts(k,:)
end
ans =
包含以下字段的 struct:
develop: {'Lee' 'Reed' 'Hill'}
document: {'Lloyd' 'Young'}
ans =
包含以下字段的 struct:
develop: {'Dean' 'Frye'}
document: {'Ryan' 'Hart' 'Roy'}
ans =
包含以下字段的 struct:
develop: {'Lane' 'Fox' 'King'}
document: {'Marsh'}2.1.2 rmfield
删除结构体中的某些字段
>> depts
depts =
包含以下字段的 3×1 struct 数组:
develop
document
>> rmfield(depts,'develop')
ans =
包含以下字段的 3×1 struct 数组:
document
2.1.3 fieldnames(查看结构体中的属性值)
>> fieldnames(depts)
ans =
2×1 cell 数组
{'develop' }
{'document'}3. 嵌套结构
Matlab中的嵌套结构是指在一个结构体中嵌套另一个结构体。通过这种方式,可以创建更复杂的数据结构,以便更好地组织和管理数据。嵌套结构可以通过使用点运算符来访问内部结构体的字段。
>> A = struct('data', [3 4 7; 8 0 1], 'nest', ...
struct('testnum', 'Test 1', ...
'xdata', [4 2 8],'ydata', [7 1 6]));
A(2).data = [9 3 2; 7 6 5];
A(2).nest.testnum = 'Test 2';
A(2).nest.xdata = [3 4 2];
A(2).nest.ydata = [5 0 9];
A.nest
ans =
包含以下字段的 struct:
testnum: 'Test 1'
xdata: [4 2 8]
ydata: [7 1 6]
ans =
包含以下字段的 struct:
testnum: 'Test 2'
xdata: [3 4 2]
ydata: [5 0 9]
>> A(1).data
ans =
3 4 7
8 0 1
>> A(2).data
ans =
9 3 2
7 6 5
>> A(1).nest.testnum%结构体中的结构体
ans =
'Test 1'4.Cell元胞数组
- 存储异构数据的另外一种方法
- 类似于矩阵,但是每个条目包含不同类型的数据
- 通过将索引括在圆括号()中可以引用元胞集,使得花括号{}进行索引来访问元胞的内容
4.1创建对象以及访问
方法一:
>> A(1,1)={[1 4 3; 0 5 8; 7 2 9]};
A(1,2)={'Anne Smith'};
A(2,1)={3+7i};
A(2,2)={-pi:pi:pi};
A
A =
2×2 cell 数组
{3×3 double } {'Anne Smith'}
{[3.0000 + 7.0000i]} {1×3 double }方法二:
>> A{1,1}=[1 4 3; 0 5 8; 7 2 9];
A{1,2}='Anne Smith';
A{2,1}=3+7i;
A{2,2}=-pi:pi:pi;
A
A =
2×2 cell 数组
{3×3 double } {'Anne Smith'}
{[3.0000 + 7.0000i]} {1×3 double }为什么Cell元胞数组能精确的找到对应的值呢?
- 单元格数组中的每个条目都持有一个指向数据结构的指针
- 同一单元阵列的不同单元可以指向不同类型的数据结构
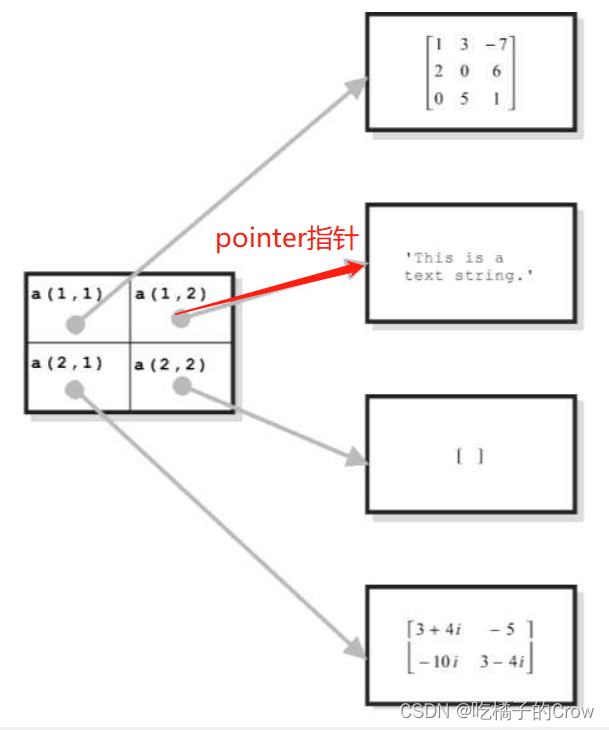
>> C=A(1,1)
C =
1×1 cell 数组
{3×3 double}
>> C=A{1,1}%{}显示具体的元素
C =
1 4 3
0 5 8
7 2 94.2 Cell元胞数组函数
| cell | 创建单元阵列 |
| cell2mat | 将元胞数组转换为基础数据类型的普通数组 |
| cell2struct | 将元胞数组转换为结构体数组 |
| celldisp | 显示元胞数组的内容 |
| cellfun | 对元胞数组中的每个元胞应用函数 |
| cellplot | 以图的方式显示元胞数组的结构体 |
| cellstr | 转换为字符向量元胞数组 |
| iscell | 确定输入是否为元胞数组 |
| mat2cell | 将数组转换为在元胞中包含子数组的元胞数组 |
| num2cell | 将数组转换为相同大小的元胞数组 |
| struct2cell | 将结构体转换为元胞数组 |
4.2.1 num2cell(转换为相同大小的元胞数组)
%C = num2cell(A) 通过将 A 的每个元素放置于 C 的一个单独元胞中,来将数组 A 转换为元胞数组 C。num2cell 函数转换具有任意数据类型(甚至是非数值类型)的数组。
C = num2cell(A)
%C = num2cell(A,dim) 将 A 的内容划分成 C 中单独的元胞,其中 dim 指定每个元胞包含 A 的哪个维度。
C = num2cell(A,dim)
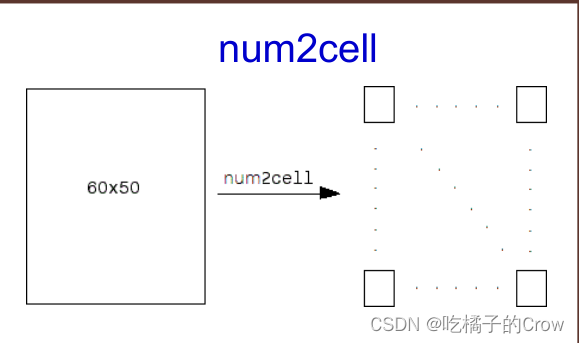
案例实现:
%数字元胞数组
>> a=magic(3)
a =
8 1 6
3 5 7
4 9 2
>> C=num2cell(a)
C =
3×3 cell 数组
{[8]} {[1]} {[6]}
{[3]} {[5]} {[7]}
{[4]} {[9]} {[2]}
%字符串元胞数组
>> a = ['four';'five';'nine']
a =
3×4 char 数组
'four'
'five'
'nine'
>> c = num2cell(a)
c =
3×4 cell 数组
{'f'} {'o'} {'u'} {'r'}
{'f'} {'i'} {'v'} {'e'}
{'n'} {'i'} {'n'} {'e'}4.2.2 matcell(转换为在元胞中包含子数组的元胞数组)
%C = mat2cell(A,dim1Dist,...,dimNDist) 将数组 A 划分为更小的数组,并在元胞数组 C 中返回它们。向量 dim1Dist,...dimNDist 指定如何划分 A 的行、列和(如果适用)更高维度。C 中较小的数组可以具有不同大小。A 可以包含任何数据类型。
C = mat2cell(A,dim1Dist,...,dimNDist)
%C = mat2cell(A,rowDist) 将数组 A 划分为一个 n×1 元胞数组 C,其中 n 等于 rowDist 中元素的数量。
C = mat2cell(A,rowDist)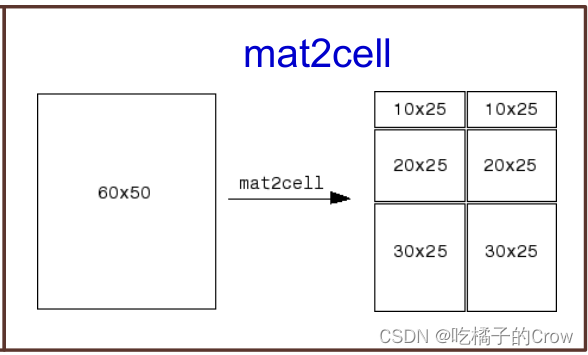
例如:如果A是60*50数组,则可以将此参数指定为[10 20 30],[25 25]来划分A,如上图:
>> A=rand(60,50);
>> C=mat2cell(A,[10 20 30],[25 25])
C =
3×2 cell 数组
{10×25 double} {10×25 double}
{20×25 double} {20×25 double}
{30×25 double} {30×25 double} 对于 A 的第 K 个维度,在指定对应向量 dimKDist 的元素时,需满足 sum(dimKDist) 等于第 K 个维度的大小,如果 A 的第 K 个维度的大小为零,则应将对应向量 dimKDist 指定为空数组 [],如代码中所示。
>> A = rand(3,0,4);
C = mat2cell(A,[1 2],[],[2 1 1])
C =
空的 2×0×3 cell 数组5. 多维数组
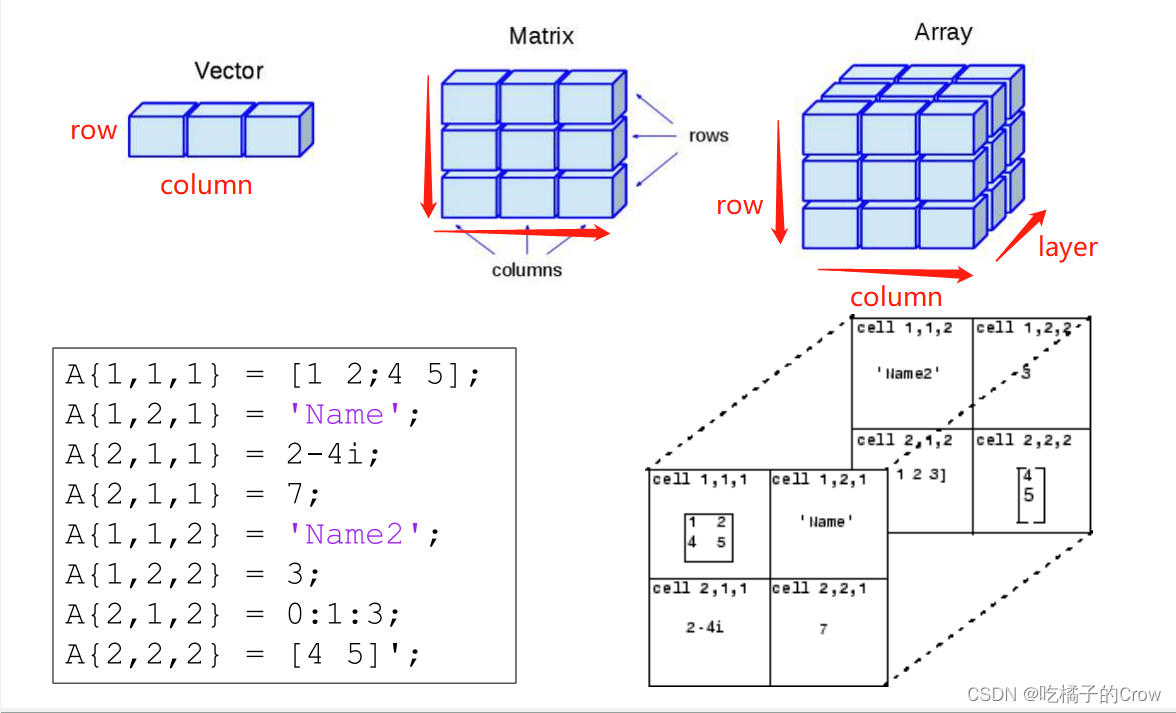
5.1 cat()函数
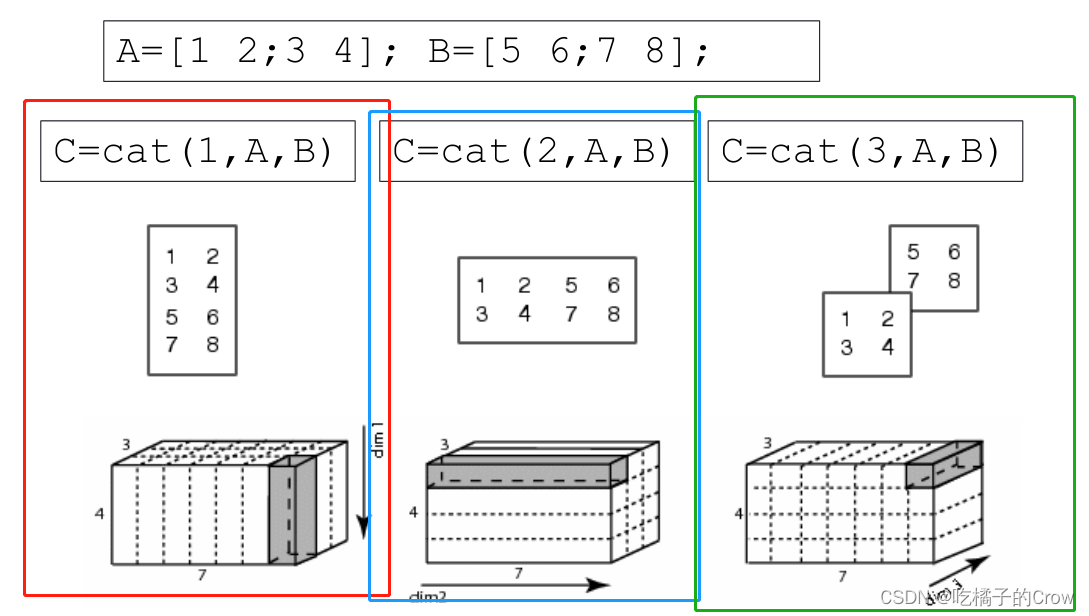
>> A=[1 2;3 4]; B=[5 6;7 8];
>> C=cat(1,A,B)
C =
1 2
3 4
5 6
7 8
>> C=cat(2,A,B)
C =
1 2 5 6
3 4 7 8
>> C=cat(3,A,B)
C(:,:,1) =
1 2
3 4
C(:,:,2) =
5 6
7 85.2 reshape()函数
%B = reshape(A,sz) 使用大小向量 sz 重构 A 以定义 size(B)。例如,reshape(A,[2,3]) 将 A 重构为一个 2×3 矩阵。sz 必须至少包含 2 个元素,prod(sz) 必须与 numel(A) 相同。
B = reshape(A,sz)
%B = reshape(A,sz1,...,szN) 将 A 重构为一个 sz1×...×szN 数组,其中 sz1,...,szN 指示每个维度的大小。可以指定 [] 的单个维度大小,以便自动计算维度大小,以使 B 中的元素数与 A 中的元素数相匹配。例如,如果 A 是一个 10×10 矩阵,则 reshape(A,2,2,[]) 将 A 的 100 个元素重构为一个 2×2×25 数组
B = reshape(A,sz1,...,szN)
>> A=[1 2 3 4 5 6 7 8 9]
A =
1 2 3 4 5 6 7 8 9
>> B=reshape(A,[3,3])%重新分配成3*3的数组
B =
1 4 7
2 5 8
3 6 9
>> A=magic(4)
A =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1
>> B=reshape(A,[],2)%可以指定 [] 的单个维度大小,以便自动计算维度大小,以使 B 中的元素数与 A 中的元素数相匹配
B =
16 3
5 10
9 6
4 15
2 13
11 8
7 12
14 1| isinteger | 确定输入是否为整型数组 |
| islogical | 判断输入是否为逻辑阵列 |
| isnan | 检测非数字元素(NaN) |
| isnumeric | 确定输入是否为数字数组 |
| isprime | 检测数组的质数元素 |
| isreal | 确定所有数组元素是否都是实数 |
| iscell | 确定输入是否为元胞数组 |
| ischar | 确定输入是否为字符数组 |
| isempty | 确定输入是否为空数组 |
| isequal | 确定数组在数值上是否相等 |
| isfloat | 确定输入是否为浮点数组 |
| isglobal | 确定输入是否是全局变量 |
| ishandle | 检测有效的图形对象的句柄 |
| isinf | 检测数组的无限元素 |
6.文件访问
Matlab就相当于是一个中间加工厂(计算),我们需要将其计算的结果保存在我们的文件中

6.1 save()
- 不加 -ascii
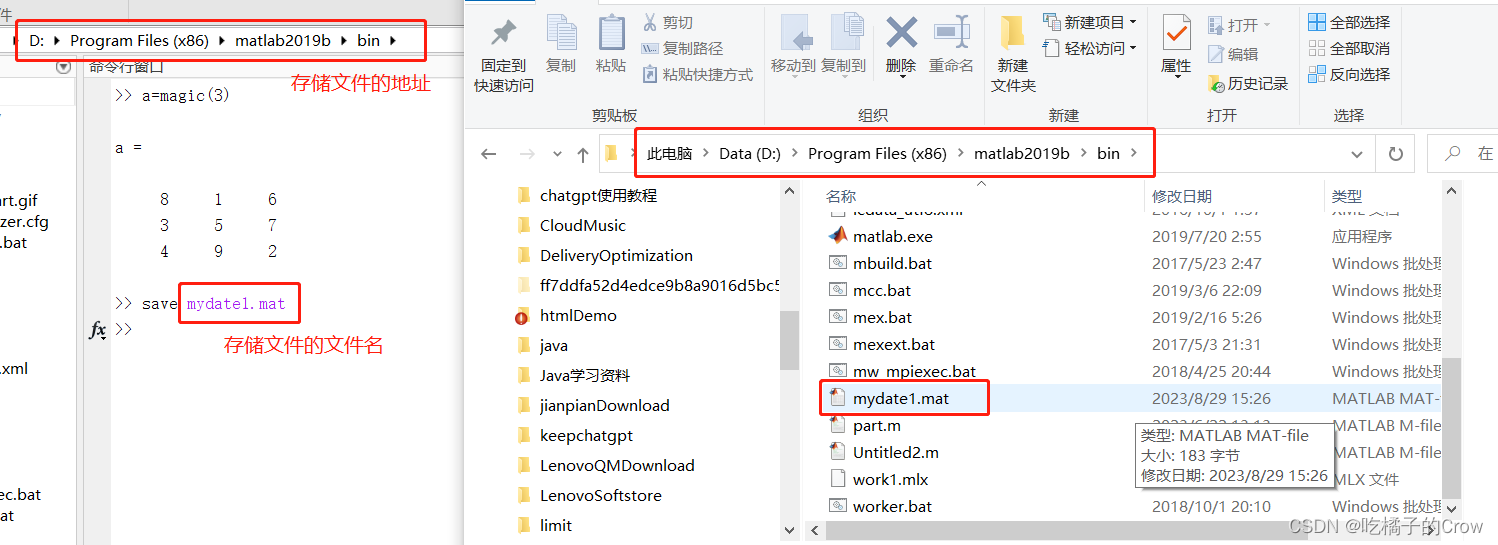

打开是乱码(经过了压缩),这种模式的存储不方便我们人为进行查看
- 加 -ascii


这种方式的存储我们比较容易识别
6.2 load()


在读取文件的时候,如果存储的时候用save -ascii 的方式进行存储,下载的时候同样也需要load -ascii

7.Excel文件读取
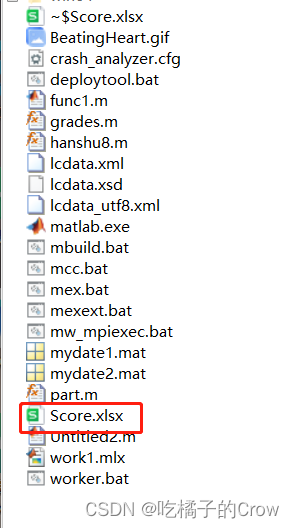
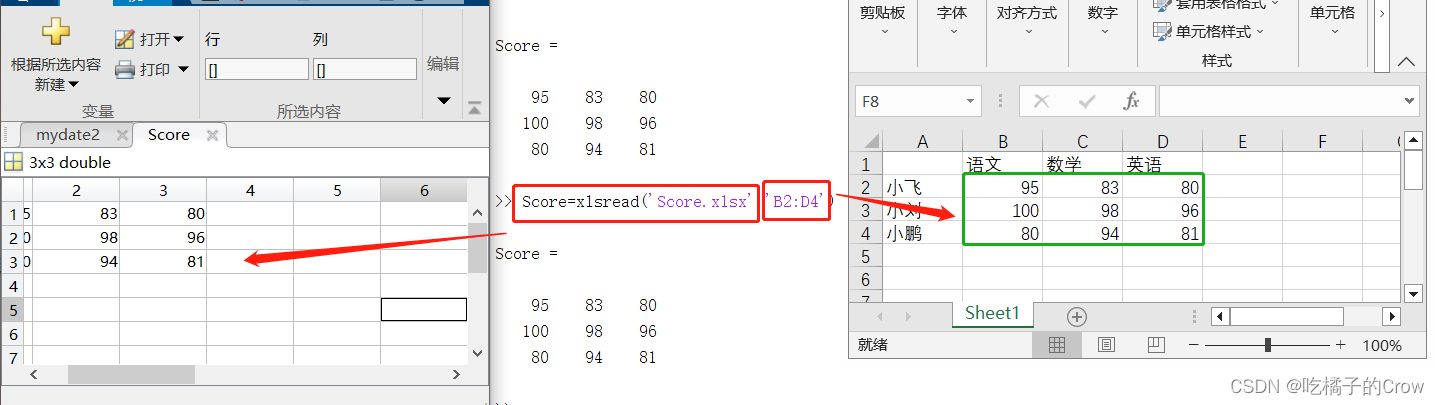
7.1 xlsread()
注意:所有读取的Excel表格应该和运行文件在同一文件夹,在读取的时候默认只能读数字部分,自动省略字符串部分的读取
7.2 xlswrite()
我们需要将其平均值就算出来写出电子表格中
>> help mean
mean - 数组的均值
此 MATLAB 函数 返回 A 沿大小不等于 1 的第一个数组维度的元素的均值。
M = mean(A)
M = mean(A,'all')
M = mean(A,dim)
M = mean(A,vecdim)
M = mean(___,outtype)
M = mean(___,nanflag)>> M=mean(Score')'%mean是以列为单位进行计算,我们首先对元素数组取转置,然后再进行计算
M =
86
98
85xlswrite('Score.xlsx',M,1,'E2:E4') 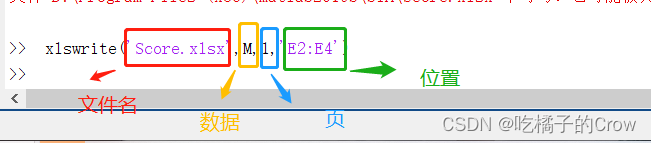

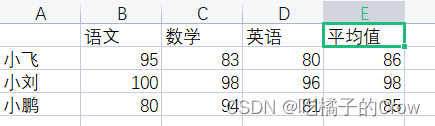
xlswrite('Score.xlsx',{'平均值'},1,'E1')%写列题目
那么我们应该怎么在Excel表格中获取文本呢?

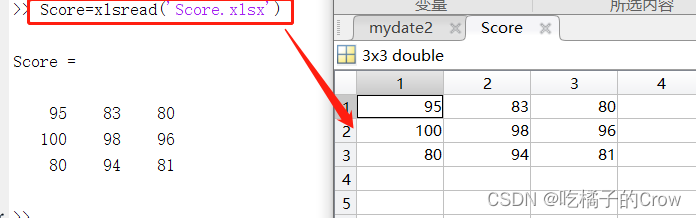
>> [Score Header]=xlsread('Score.xlsx')
Score =
95 83 80 86
100 98 96 98
80 94 81 85
Header =
4×5 cell 数组
{0×0 char} {'语文' } {'数学' } {'英语' } {'平均值' }
{'小飞' } {0×0 char} {0×0 char} {0×0 char} {0×0 char}
{'小刘' } {0×0 char} {0×0 char} {0×0 char} {0×0 char}
{'小鹏' } {0×0 char} {0×0 char} {0×0 char} {0×0 char}7.3 低级文件的输入/输出
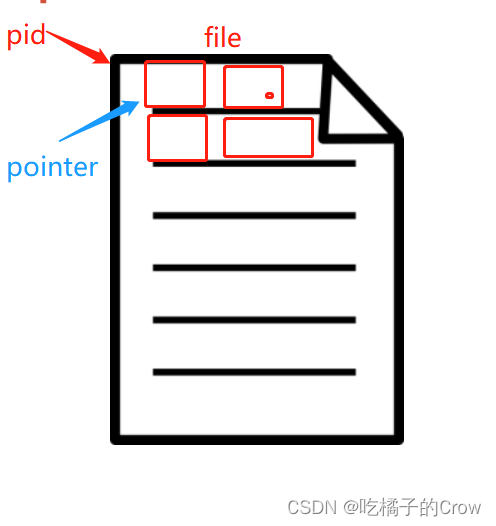
- 在字节或字符级别读取和写入文件
- 文件ID为fid
- 文件中的位置由可移动的指针指定
| 函数 | 描述 |
| fopen | 打开一个文件,或获取打开文件的信息 |
| fclose | 关闭一个或所有打开的文件 |
| fscanf | 从文本文件读取数据 |
| fprintf | 将数据写入文本文件 |
| feof | 测试文件尾 |
打开和关闭文件:
fid=fopen('[filename]','[permission]');%打开文件
permission: 'r' 'r+' 'w' 'w+' 'a' 'a+'
'r':只读,默认
'w':只写,覆盖原内容
'a':附加数据到文件尾部
'r+':读与写
'w+':读与写,写时覆盖原内容
'a+':读与写,写时,附加到文件尾部status=fclose(fid);%关闭文件案例:
将余弦值写入文件:
>> x=0:pi/10:pi;
y=cos(x);
fid=fopen('cos.txt','w');
for i=1:11
fprintf(fid,'%5.3f %8.4f\n',x(i),y(i));
end
>> fclose(fid);
>> type cos.txt
IO的读写操作:
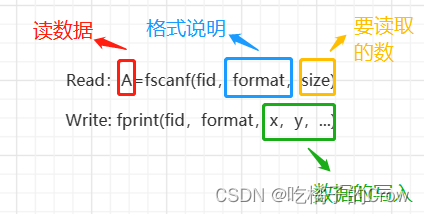

读取文件:
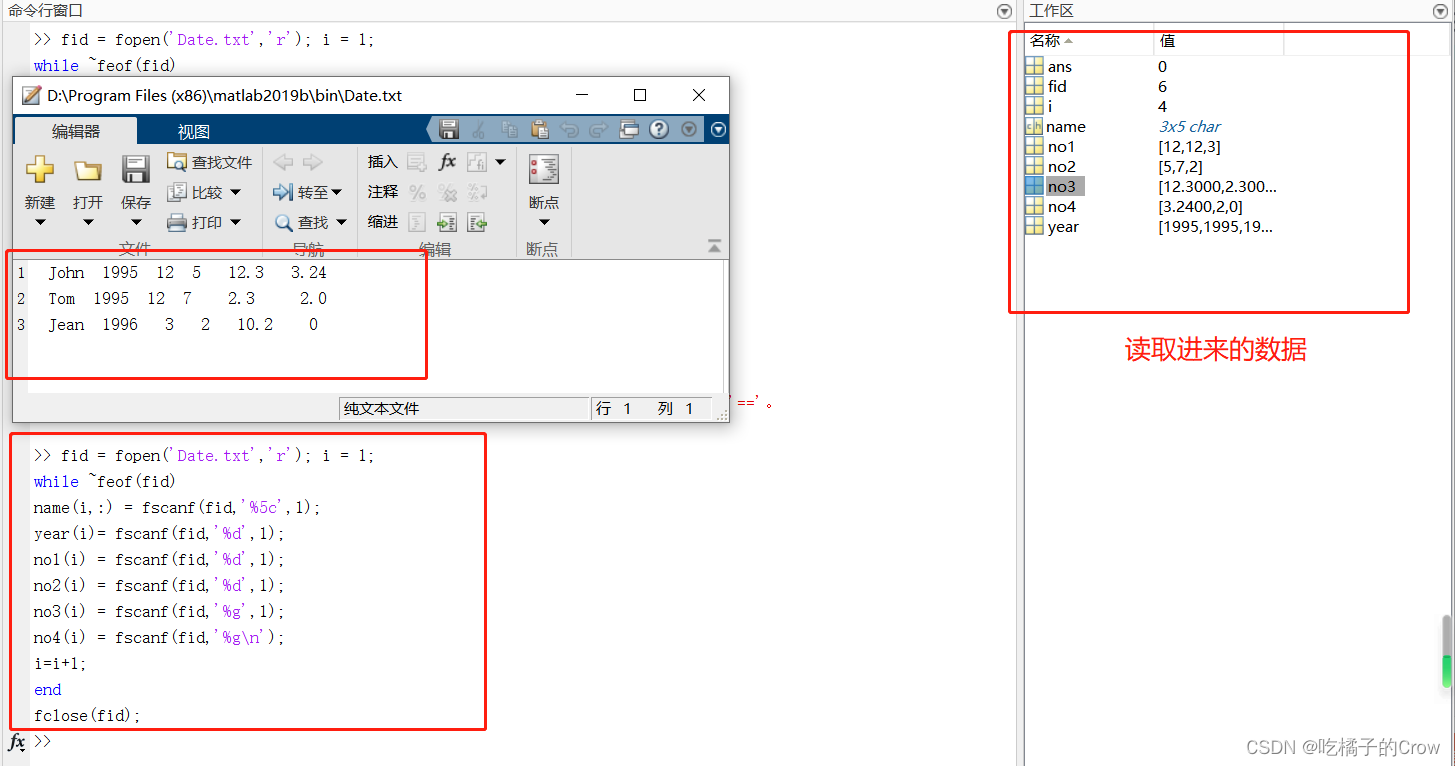
![]()

>> fid = fopen('Date.txt','r'); i = 1;
while ~feof(fid)
name(i,:) = fscanf(fid,'%5c',1);
year(i)= fscanf(fid,'%d',1);
no1(i) = fscanf(fid,'%d',1);
no2(i) = fscanf(fid,'%d',1);
no3(i) = fscanf(fid,'%g',1);
no4(i) = fscanf(fid,'%g\n');
i=i+1;
end
fclose(fid);