诸神缄默不语-个人CSDN博文目录
文章目录
- 1. 多线程
- 2. 多进程
- 示例1:multiprocessing.Pool直接实现对一个列表中的每个元素的函数操作
- 示例2:使用苏神写的工具函数实现对一个迭代器中每个元素的函数操作
1. 多线程
2. 多进程
示例1:multiprocessing.Pool直接实现对一个列表中的每个元素的函数操作
from tqdm import tqdm
from multiprocessing import Pool
original_data #给定列表
#对每个元素的函数操作
def process_factor(i):
try:
#输入元素索引,返回对该元素实现操作后的结果
return result
except Exception as e:
print(f"Error processing factor {i}: {e}")
return None
if __name__ == "__main__":
#全局变量在每个进程中是不共享的,所以如果在process_factor()中直接修改original_data的话,将不会反映到主进程中
#在使用多进程(multiprocessing)时,每个新进程都会重新导入当前模块,如果这些代码不在 if __name__ == "__main__": 块内,代码会在每个新进程中重新运行。这不仅可能导致性能问题,还可能产生意外的副作用。对于Windows和某些Unix系统,这是必要的,否则代码可能完全无法运行。
with Pool() as p:
results = list(tqdm(p.imap_unordered(process_factor,range(len(original_data))),total=len(original_data)))
# 更新 original_data
for i, result in enumerate(results):
if result is not None:
original_data[i] = result
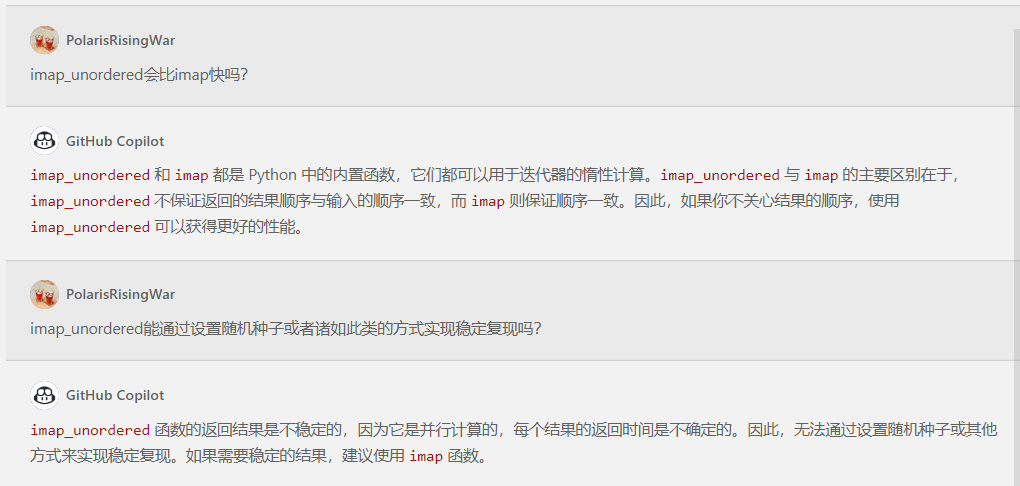
关于选择imap()还是imap_unordered():
示例2:使用苏神写的工具函数实现对一个迭代器中每个元素的函数操作
这是苏神的代码(复制自https://github.com/bojone/bert4keras/blob/master/bert4keras/snippets.py):
def parallel_apply_generator(
func, iterable, workers, max_queue_size, dummy=False, random_seeds=True
):
"""多进程或多线程地将func应用到iterable的每个元素中。
注意这个apply是异步且无序的,也就是说依次输入a,b,c,但是
输出可能是func(c), func(a), func(b)。结果将作为一个
generator返回,其中每个item是输入的序号以及该输入对应的
处理结果。
参数:
dummy: False是多进程/线性,True则是多线程/线性;
random_seeds: 每个进程的随机种子。
"""
if dummy:
from multiprocessing.dummy import Pool, Queue
else:
from multiprocessing import Pool, Queue
in_queue, out_queue, seed_queue = Queue(max_queue_size), Queue(), Queue()
if random_seeds is True:
random_seeds = [None] * workers
elif random_seeds is None or random_seeds is False:
random_seeds = []
for seed in random_seeds:
seed_queue.put(seed)
def worker_step(in_queue, out_queue):
"""单步函数包装成循环执行
"""
if not seed_queue.empty():
np.random.seed(seed_queue.get())
while True:
i, d = in_queue.get()
r = func(d)
out_queue.put((i, r))
# 启动多进程/线程
pool = Pool(workers, worker_step, (in_queue, out_queue))
# 存入数据,取出结果
in_count, out_count = 0, 0
for i, d in enumerate(iterable):
in_count += 1
while True:
try:
in_queue.put((i, d), block=False)
break
except six.moves.queue.Full:
while out_queue.qsize() > max_queue_size:
yield out_queue.get()
out_count += 1
if out_queue.qsize() > 0:
yield out_queue.get()
out_count += 1
while out_count != in_count:
yield out_queue.get()
out_count += 1
pool.terminate()
def parallel_apply(
func,
iterable,
workers,
max_queue_size,
callback=None,
dummy=False,
random_seeds=True,
unordered=True
):
"""多进程或多线程地将func应用到iterable的每个元素中。
注意这个apply是异步且无序的,也就是说依次输入a,b,c,但是
输出可能是func(c), func(a), func(b)。
参数:
callback: 处理单个输出的回调函数;
dummy: False是多进程/线性,True则是多线程/线性;
random_seeds: 每个进程的随机种子;
unordered: 若为False,则按照输入顺序返回,仅当callback为None时生效。
"""
generator = parallel_apply_generator(
func, iterable, workers, max_queue_size, dummy, random_seeds
)
if callback is None:
if unordered:
return [d for i, d in generator]
else:
results = sorted(generator, key=lambda d: d[0])
return [d for i, d in results]
else:
for i, d in generator:
callback(d)
使用示例(这个项目比较大,前后省略的函数我就不写了,总之意会就行):
(代码复制自https://github.com/bojone/SPACES/blob/main/extract_convert.py)
#对每个元素的函数操作
def extract_flow(inputs):
"""单个样本的构建流(给parallel_apply用)
"""
text, summary = inputs
texts = text_split(text, True) # 取后maxlen句
summaries = text_split(summary, False)
mapping = extract_matching(texts, summaries)
labels = sorted(set([i[1] for i in mapping]))
pred_summary = ''.join([texts[i] for i in labels])
metric = compute_main_metric(pred_summary, summary)
return texts, labels, summary, metric
#对整个迭代器实现批量操作
def convert(data):
"""分句,并转换为抽取式摘要
"""
D = parallel_apply(
func=extract_flow,
iterable=tqdm(data, desc=u'转换数据'),
workers=100,
max_queue_size=200
)
total_metric = sum([d[3] for d in D])
D = [d[:3] for d in D]
print(u'抽取结果的平均指标: %s' % (total_metric / len(D)))
return D
if __name__ == '__main__':
data = convert(data)