简介
ORM框架介绍
ORM(Object Relation Mapping)框架,可以帮助我们把类和数据表进行一个映射,让我们可以通过类和类对象来直接操作数据库中的数据。
优势:根据对接的数据库引擎翻译成对应的sql语句,所以我们不用关注使用的是MySQL还是Oracle等,我们只需要修改数据库配置即可
django中内嵌了ORM框架,不需要直接面向数据库编程,而是定义模型类,通过模型类和对象完成数据表的增删改查操作。
模型
Django 中模型是真实数据的描述,它包含了储存的数据所必要的字段和行为,在创建模型前需要先配置好数据库。每一个模型类即对应一个数据表
数据库配置
Python 内置 SQLite,如果使用SQLite则无需安装额外东西。
以下以TestDjango项目为例 ,我们使用 mysql 数据库
一、数据库连接配置
在 TestDjango 项目目录下,打开 TestDjango/settings.py 配置文件,修改DATABASES 中的数据库信息(默认是sqlite)
# TestDjango/settings.py
DATABASES = {
'default': {
# 指定当前使用的数据库引擎
# django.db.backends.mysql、oracle、sqlite3
'ENGINE': 'django.db.backends.mysql',
'NAME': 'test', # 数据库
'USER': 'root', # 用户名
'PASSWORD': '123456', # 密码
'PORT': 3306, # 数据库的端口号
'HOST': 'localhost' # 主机ip
}
}然后在settings.py所在目录下的__init__py文件中设置Django默认连接MySQL的方式
# TestDjango/__init__py
import pymysql
pymysql.install_as_MySQLdb()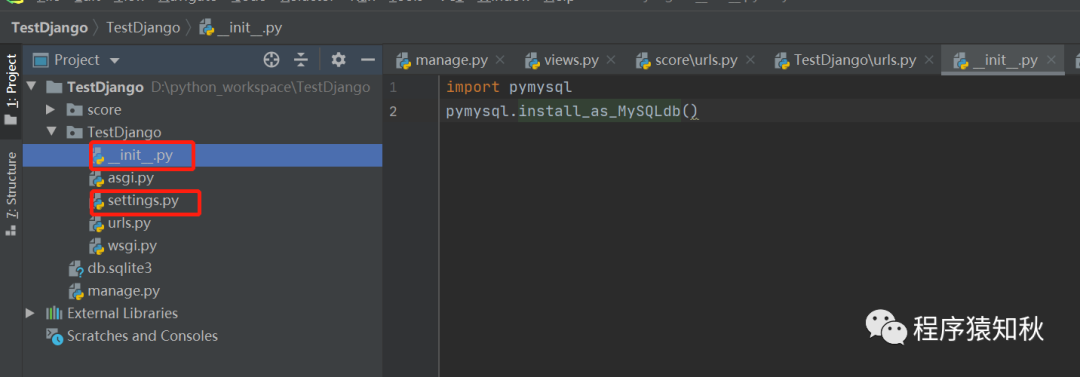
二、创建模型
为了避免不同数据库sql不一样的情况,django统一采用 模型类,模型类 定义在 应用的models.py 文件中
以之前创建的评分系统(scroe)为例,创建两个模型 Student 和 Address
通过编辑 score/models.py 文件定义出来
from django.db import models
class Student(models.Model):
# 模型类中不需要指定 id字段,会自动生成
# 数据库的可变字符串类型 varchar(20)
name = models.CharField(max_length=20)
age = models.IntegerField()
create_time = models.DateTimeField('创建时间')
def __str__(self):
# 对象的描述信息, 此时查看对象,已经不是默认的对象地址,而是学生的名称
return self.name
# 元选项一定属于模型类中的一部分,不能单独使用
class Meta:
db_table = 'student' # 指定表名, 默认为 app名_模型类名
verbose_name = '学生表'
verbose_name_plural = verbose_name
class Address(models.Model):
# CASCADE:当父表数据删除时,相对应的从表数据会被自动删除
student = models.ForeignKey(Student, on_delete=models.CASCADE)
detail = models.CharField(max_length=200)注:
-
每个模型被定义为 django.db.models.Model 类的子类
-
每个 Field 类实例变量的名字也是字段名,如 create_time,定义时需要遵循数据库字段规则
-
可以定义备注名,方便代码理解,如 create_time= models.DateTimeField('创建时间')
常用字段类型
| 类型 | 描述 |
| CharField | 字符串类型(必加 maxlength) |
| IntegerField | 整数类型 |
| FloatField | 小数类型 |
| DateTimeField | 日期+时间 类型 |
| DateField | 日期类型 |
| DecimalField | (精确)小数 类型 |
三、安装应用
现在需要将 score 应用安装到我们 TestDjango 项目中。
首先打开 TestDjango/settings.py 配置文件,在 INSTALLED_APPS 中添加 score 应用的点式路径 'score.apps.ScoreConfig',配置完成如下所示:
# TestDjango/settings.py
INSTALLED_APPS = [
'score.apps.ScoreConfig', #新增polls路径
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]注:因为 ScoreConfig类写在文件 score/apps.py 中,所以它的点式路径是 'score.apps.ScoreConfig'
四、迁移(makemigrations)
模型类创建好后,将模型类迁移到数据库(迁移是 Django 对于模型定义即数据库结构的变化的储存形式)
在终端执行迁移命令,会在对应app下生成一个迁移文件migrations 用来记录数据库迁移的信息
如果数据库出错,需删库重创时,必须把migrations 文件删掉再重新创建,否则报错
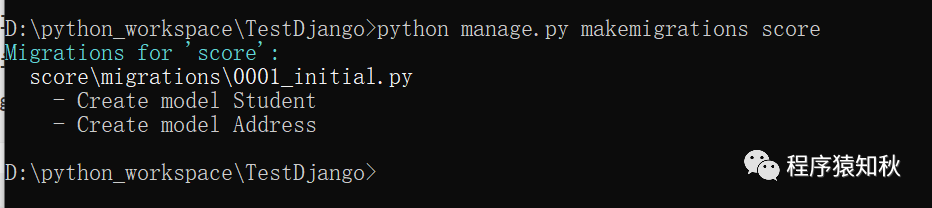
# 生成迁移文件
python manage.py makemigrations score
# 执行迁移文件同步数据到数据库
python manage.py migrate生成迁移文件
同步数据库
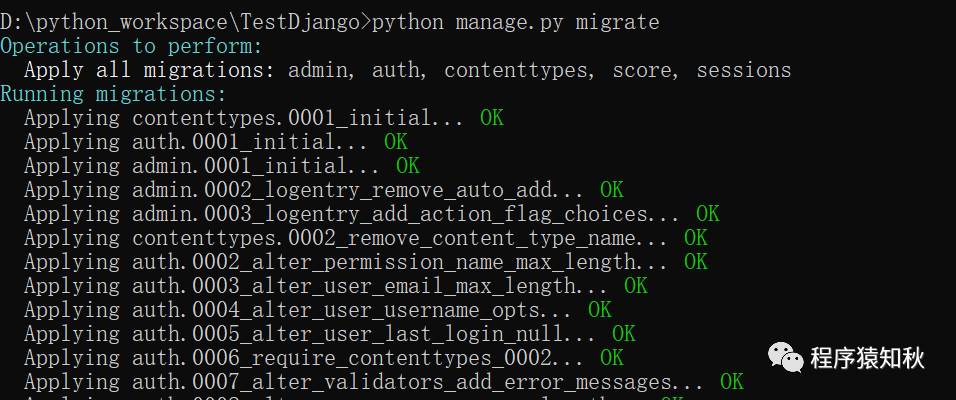
成功后,数据库中将出现以下表
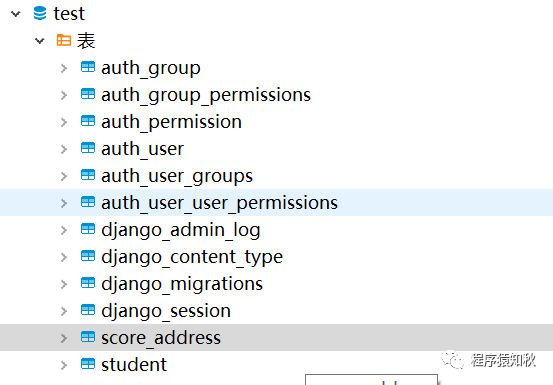
注:执行以上命令如果报以下错时

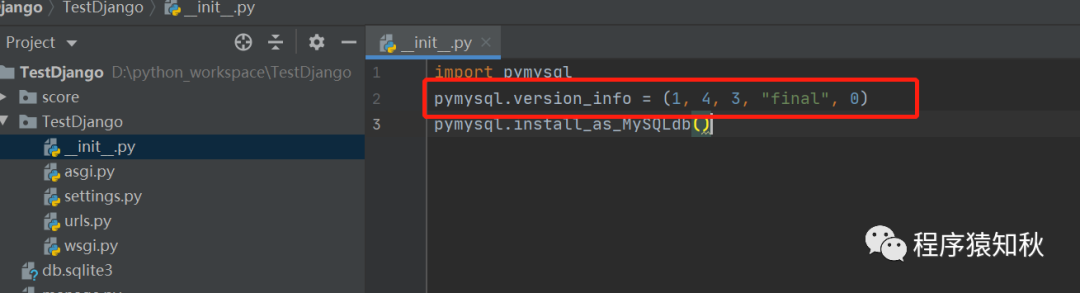
解决:修改__init__.py 文件,指定版本:pymysql.version_info = (1, 4, 3, "final", 0)
然后再重新执行迁移文件的命令即可
数据库操作
新增数据
编辑 TestDjango 项目下score/views.py 文件代码,通过访问URL 在 Student 模型对应表中添加数据
# score/views.py
from django.http import HttpResponse
# Create your views here.
from score.models import Student, Address
from django.utils import timezone
def index(request):
return HttpResponse("这是一个评分系统!!!")
# 添加学生
def add_student(request):
student = Student(
name="张三",
age=22,
create_time=timezone.now()
)
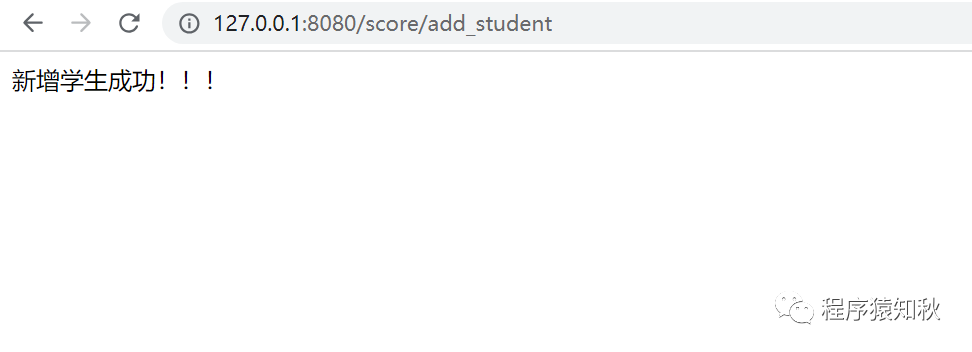
student.save()
return HttpResponse("新增学生成功!!!")再编辑 score/urls.py 文件代码,新增一条路由,代码如下:
# score/urls.py
urlpatterns = [
path('', views.index, name='index'),
path('add_student', views.add_student, name='add_student'), #新增add_student路由
]最后,通过 python manage.py runserver 127.0.0.1:8080 命令启动本地开发服务器,启动后在浏览器中输入URL地址 http://127.0.0.1:8080/score/add_student
修改数据
和新增数据一样,再次编辑 TestDjango 项目下 score/views.py 文件,添加修改方法,并在score/urls.py 添加一条路由
# 修改学生
def update_student(request):
student = Student.objects.get(id=1)
student.name="李四"
student.save()
# 或者通过条件过滤的方式也可以修改
# Student.objects.filter(id=1).update(name='李四')
return HttpResponse("修改学生成功!!!")删除数据
添加修改方法,并在score/urls.py 添加一条路由
# 删除学生
def del_student(request):
student = Student.objects.get(id=1)
student.delete()
# 或者通过条件过滤的方式
# Student.objects.filter(id=1).delete()
return HttpResponse("删除学生成功!!!")查询数据
再次编辑 TestDjango 项目下 score/views.py 文件,添加查询方法,并在score/urls.py 添加一条路由
def query(request):
# 通过objects这个模型管理器的all()获得所有数据行,相当于SQL中的SELECT * FROM student
studentList = Student.objects.all()
# 获取单个对象
response2 = Student.objects.get(id=2)
# 相当于SQL中的WHERE id=2,可设置条件过滤
response3 = Student.objects.filter(id=2)
# 根据id字段排序
response5 = Student.objects.order_by("id")
# 模糊查询 (字段名__contains)判断是否包含,如果要包含%无需转义,直接写即可
response = Student.objects.filter(name__contains="三")
# startswith、endswith :以指定值开头或结尾
response = Student.objects.filter(name__startswith="三")
response = Student.objects.filter(name__endswith="三")
# 空查询 isnull 是否为空 Flase/True
response = Student.objects.filter(name__isnull=False)
#in范围查询
response = Student.objects.filter(id__in=[2,3])
# 比较查询
# gt :大于(greater then)
# gte:大于等于(greater then equal)
# lt :小于(less then)
# lte :小于等于(less then equal)
# 查询id大于2的数据
response = Student.objects.filter(id__gte=2)
# Q查询
# 多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
# & 表示逻辑与、and,| 表示逻辑或、or
# 查询id大于2 并且 age大于20的数据
response = Student.objects.filter(id__gt=2, age__gt=20)
response = Student.objects.filter(Q(id__gt=2) & Q(age__gt=20))
# 查询id大于2 或者 age大于20的数据
response = Student.objects.filter(Q(id__gt=2) | Q(age__gt=20))
res = ""
# 遍历所有对象
for q in studentList:
res += str(q.id) + "." + q.name + " <br />"
return HttpResponse("查询所有学生:<br />" + res)注:查询单个数据 get(id=1) 与 filter(id=1) 的区别:
-
get( id =1):返回模型实例对象,如果查询结果不存在或者有多个,会抛出异常
-
filter(id=1):返回模型实例对象的Set集合,如果查询结果不存在会返回空集合,如果有多个则返回的集合中包裹多个模型对象
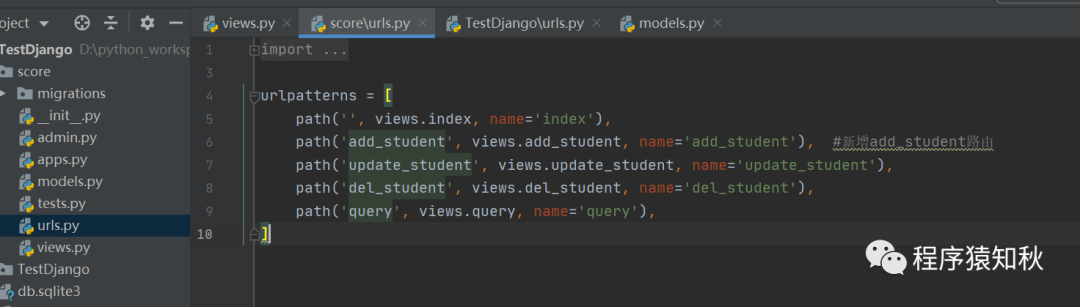
score/urls.py 文件代码
程序猿与投资生活实录已改名为 程序猿知秋,WX 公众号同款,欢迎关注!!