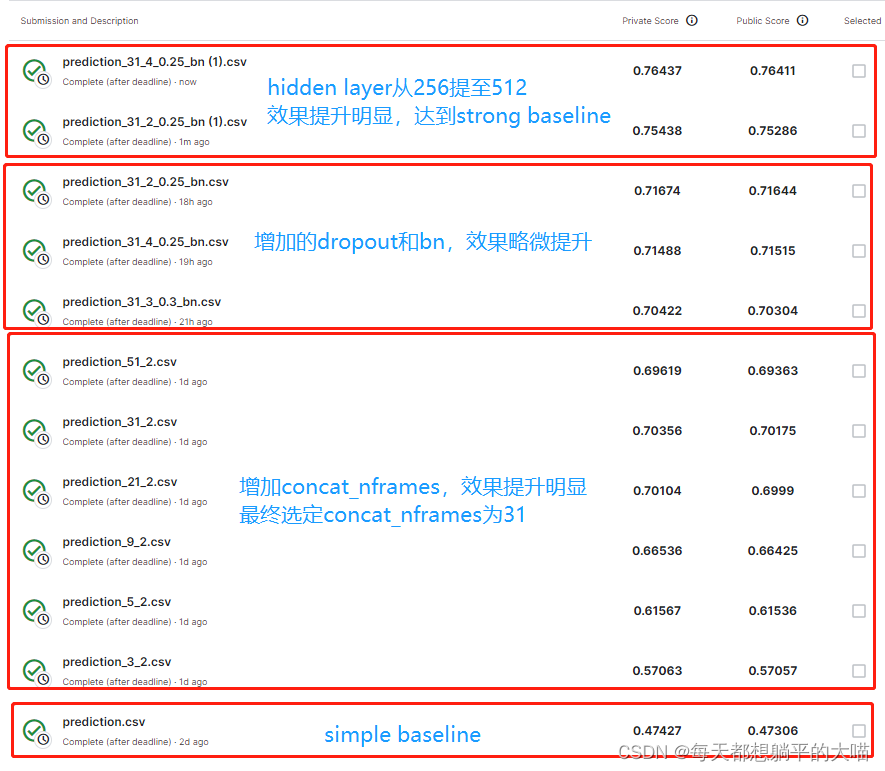
前文再续,书接上一回。
上次我们讲了方向分布工具,这个工具会生成一个标准差椭圆,其中有这样的一句话描述:
“短半轴表示数据分布的范围,短半轴越短,表示数据呈现的向心力越明显;反之,短半轴越长,表示数据的离散程度越大”。
工具的使用和结果都非常的简单明了,而且也说了,有专家仅使用这个工具,就可以发N篇论文——这里就需要提醒同学们的是:现在很多同学写论文的时候,更多的去关注了各种花样百出纷繁多变的分析工具,而恰恰把分析的原意给淡忘掉了……而真正的高手,都是举重若轻的,他们只需要很简单的工具,就能够深切的揭示数据的意义,乃至于分析后面所蕴含的机理,这才是分析的原意。
金庸先生在笔下,不管是笑傲江湖里面的“无招胜有招”,还是神雕侠侣里面的“重剑无锋,大巧不工”,都是想说明了这个道理:

不过方向分布工具,有时候会带来这个问题:

比如上面这两份数据,如果我们做方向分布的话,会得到下面这样的结果:

也就发现,二者的变化基本上很少,因方向几乎相同,这是因为这种数据,本身就是按照行政区划来进行采集的,所以采集的方式就决定了你最后的结果。当然,二者也还是有不同的,就上面所表现的来看,相较之下,蓝色(宾馆酒店)的范围略大,而红色(特色风味餐厅)的方向性更显著。
从上面这个例子,可以得到一个这样一个原则:你需要分析的数据,原生的范围约束性越强,效果越不好。啥叫原生范围的约束性呢?就是比如你的数据采集,就是依赖于行政区划来进行采集的,这种约束性就比较强了,特别是POI,大多都充斥满整个行政区划的。
当然,方向分布工具效果不好,还存在一些其他的约束,解决方法也有,比如用属性加权,这个有兴趣的同学后面咱们有空在讨论。
好了,上面是简单聊了一下方向分布的一个遗留问题,下面我们进入今天要讲的工具:标准距离。
如果说,一批数据表现出了明显的向心力,也就是在中心附近进行了聚集,那么他们的分散和聚集程度到底是怎么样的呢?有没有方法进行度量呢?这就是今天要讲的这个工具的作用,与第21节平均最近邻很像。
所以今天我们讲的这个算法:标准距离,就是用户度量一组要素,在平均中心附近的离散或者就集中的程度。
我们先看看,这个工具(算法)能够输出什么结果。数据还是如昨天的那一份伤寒病例,通过标准距离工具计算,结果如下:

与方向分布不同的是,这个算法(工具)会生成一个圆形,这个圆形是以所有样本数据的平均中心为圆心,以所有数据的标准距离为半径的一个圆。
这个圆代表的就是所有数据对平均中心的聚集程度,半径越小,向心力就越强(集中程度越高)。它一般用来度量数据分布相对于中心点的分散或者紧密程度。
标准距离在空间统计里面也是一个常用的方法,因为它可提供有关中心周围要素分布的单一汇总度量值(此方法类似于通过标准差测量统计平均值周围数据值的分布)。
又到每日历史起源科普时间:这个算法最早是有英国的统计学家狄金森(Gordon Cawood Dickinson)在1973年提出来的(原文请自行查阅:《Statistical mapping and the presentation of statistics》一书,亚马逊有,但是电子版我也没找到……)

(Gordon Cawood Dickinson,英国统计学家)
(一个很神秘的统计学家,我查了半天没有查到他的其他信息)
当然,在60年代英国和美国一些统计学家也描述过这个算法,但是首次正式的学术出版,是在1973年,开始他的目的主要是为了说明地图在统计图形图表的重要性(也就是说给英国的统计学家们做GIS可视化的宣传),后来经过不断的发展,变成了空间统计学里面的一个重要的工具和算法。
画圆比绘制椭圆容易多了,仅需要圆心和半径,所以标准距离工具的公式也很简单:

其中 x i , y i 和 z i 为要素 i 的坐标,{x̄, ȳ, z̄} 表示要素的平均中心,n 为要素总数。
如果需要属性加权,则扩展如下:

其中 wi 是要素 i 的权重,{Xw, Yw, Zw} 表示加权的平均中心。
在计算中,首先要计算的是平均中心,这个说了好多次了,直接跳过。接下去就是计算标准距离,从上面的公式可以看出,用的就是统计学里面的均方差算法。因为均方差(也叫标准差)主要就用来测量分布程度的,所以这里直接借鉴了这个方法。
除了在地图上会生成一个圆面要素以外,还会给出如下属性:

与上一个方向分布工具很类似,只是没有长短半轴而已,Shape_Leng和Shape_Area表示输出的圆面要素的周长和面积,单位与你数据的单位是一致的;当然,如果使用经纬度的,就只有参考意义了。
(空间分析的时候,如果需要比较精确的测量属性,
一定要使用投影坐标系!
一定要使用投影坐标系!!
一定要使用投影坐标系!!!
再次把重要的事情说三遍)
CenterX和CenterY是平均中心,也是要生成的圆面的圆心。
StdDist就是计算出来的标准距离了。
因为空间分析有空间尺度这个概念,所以分析的结果,通常需要进行对比,如果有多份数据进行对比,自然就容易了,比如下面我们继续用2000年和2001年的太湖流域的伤寒数据,进行对比:

红色的三角和蓝色的三角,是我通过属性里面的坐标信息标记上去的,表示两个年度的数据中心,可以发现2000的中心比2001年的中心,更靠近长江。
然后下面对他们的标准距离进行比较,如下:

很容易的可以对比出,2001年的数据集中的程度要高于2000年的数据。
最后,关于画的这个圆并没有把所有的样本点都包含进去的问题,原因和上一篇的方向分布是一样的,采用了三级标准差方式,如下表:

我这里只用了第一级标准差,也就是默认的标准差,只包含有大约68%左右的数据在这个圈里面。

最后我们来看看这个工具可能的应用:
比如可以利用两种或多种分布的值,对数据表示的事件的分布进行比较。例如,犯罪分析人员可以对袭击行为和汽车偷窃行为的紧密度进行比较。了解不同犯罪类型的分布情况,可能有助于警察制定出应对犯罪行为的策略。如果特定区域内的犯罪行为分布很紧凑,那么在该区域中心附近配置一辆警车也许就足够了。但如果分布较分散,则可能需要几辆警车同时巡查该区域,才能更有效地对犯罪行为做出响应。
还可以对同一类型要素在不同时间段内的分布情况进行比较。例如,犯罪分析人员可以对白天盗窃行为和夜间盗窃行为进行比较,以了解白天与夜间相比,盗窃行为是更加分散还是更加紧凑。
此外,还可将要素分布与静态要素进行比较。例如,可以针对某个区域内各响应消防站在几个月内接到的紧急电话的分布情况进行度量和比较,以了解哪些消防站响应的区域较广。
以上案例,以后有机会会进行展示。
最后,同方向分布,依然可以使用R语言的aspace这个包进行标准距离的分析:

(看起来像是椭圆,实际上是地图投影造成的)