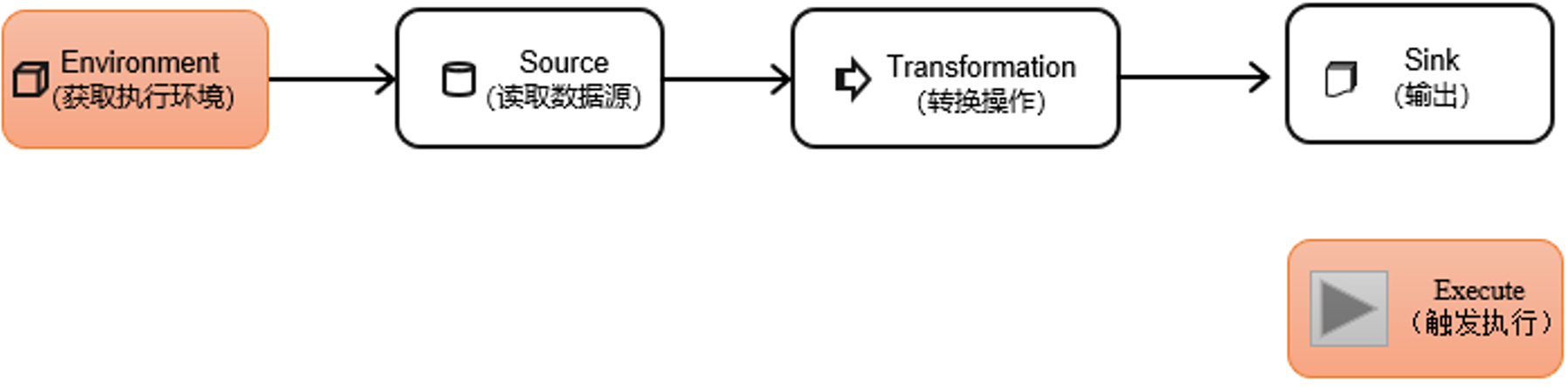
一个Flink程序,其实就是对DataStream的各种转换,代码基本可以由以下几部分构成:
- 获取执行环境
- 读取数据源
- 定义对DataStream的转换操作
- 输出
- 触发程序执行
获取执行环境和触发程序执行都属于对执行环境的操作,那么其构成可以用下图表示:
其核心部分就是Transform,对数据各种转换处理。由于新版本的Flink已经实现流批一体,流数据和批数据都统一使用DataStream API来处理
5.1 执行环境
5.1.1 创建执行环境
1.getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar 包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境
// 旧版
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 1.12.0 版本及之后流批统一,流批都统一使用StreamExecutionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2.createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的 CPU 核心数
LocalStreamEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
3.createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定要在集群中运行的 Jar 包
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment( "host", // JobManager 主机名1234,
8082, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
5.1.2 执行模式
上节中我们获取到的执行环境,是一个 StreamExecutionEnvironment,顾名思义它应该是做流处理的。那对于批处理,又应该怎么获取执行环境呢?
从 1.12.0 版本起,Flink 实现了 API 上的流批统一。DataStream API 新增了一个重要特性:可以支持不同的“执行模式”(execution mode),所以我们通过通过
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
流处理模式(STREAMING)
这是 DataStream API 最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 STREAMING 执行模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING); -
批处理模式(BATCH)
专门用于批处理的执行模式, 这种模式下,Flink 处理作业的方式类似于 MapReduce 框架。对于不会持续计算的有界数据,我们用这种模式处理会更方便
env.setRuntimeMode(RuntimeExecutionMode.BATCH); -
自动模式(AUTOMATIC)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
1.BATCH 模式的配置方法
-
命令行方式【推荐】
bin/flink run -Dexecution.runtime-mode=BATCH ...推荐使用这种方法,因为这样的话同一套代码,只需要改变执行命令就可以切换流/批模式来执行。
-
代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.BATCH);
2.什么时候选择 BATCH 模式
我们知道,Flink 本身持有的就是流处理的世界观,即使是批量数据,也可以看作“有界流”来进行处理。所以 STREAMING 执行模式对于有界数据和无界数据都是有效的;而 BATCH 模式仅能用于有界数据。
看起来 BATCH 模式似乎被 STREAMING 模式全覆盖了,那还有必要存在吗?我们能不能所有情况下都用流处理模式呢?
当然是可以的,但是这样有时不够高效。
我们可以仔细回忆一下 word count 程序中,批处理和流处理输出的不同:在 STREAMING 模式下,每来一条数据,就会输出一次结果(即使输入数据是有界的);而 BATCH 模式下,只有数据全部处理完之后,才会一次性输出结果。最终的结果两者是一致的,但是流处理模式会将更多的中间结果输出。在本来输入有界、只希望通过批处理得到最终的结果的场景下, STREAMING 模式的逐个输出结果就没有必要了。
所以总结起来,一个简单的原则就是:用 BATCH 模式处理批量数据,用 STREAMING 模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我们没得选择——只有 STREAMING 模式才能处理持续的数据流。
5.1.3 触发程序执行
有了执行环境,我们就可以构建程序的处理流程了:基于环境读取数据源,进而进行各种转换操作,最后输出结果到外部系统。需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当 main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算, 这也被称为“延迟执行”或“懒执行”(lazy execution)。所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
5.2 源算子
创建好执行环境后,可以从各种来源获取数据。一般将数据的输入来源称为数据源,读取数据的算子为源算子。
env.addSource()
为了更好地理解,我们先构建一个实际应用场景。比如网站的访问操作,可以抽象成一个三元组(用户名,用户访问的 urrl,用户访问 url 的时间戳),所以在这里,我们可以创建一个类 Event,将用户行为包装成它的一个对象。
package com.zlin.flink.env;
import lombok.Data;
import java.sql.Timestamp;
/**
* @author tangzl
* @date 2023/3/14
**/
@Data
public class Event {
/**
用户名
*/
public String user;
/**
用户访问的url
*/
public String url;
/**
用户访问url的时间戳
*/
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}
这里我使用了lombook也就是这个@Data,如果你也使用了的话需要引入依赖:
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.20</version> </dependency>
这个类我们可以看成是特殊的POJO类,具有以下特点:
-
类是公有(public)的
-
有一个无参构造函数
-
所有属性都是公有(public)的
-
所有属性的类型都是可序列化的
5.2.1 从集合中读取数据
fromCollection // 该方法有多种重载方式,可通过IDEA查看源码自行研究。
举例:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
ArrayList<Event> clicks = new ArrayList<>();
clicks.add(new Event("zhangsan", "./home", 1000L));
clicks.add(new Event("lisi", "./home", 1000L));
clicks.add(new Event("wangwu", "./cart", 2000L));
DataStreamSource<Event> stream = env.fromCollection(clicks);
stream.print();
env.execute();
}
实际应用中这种方式很少用。
5.2.2 从文件中读取数据
readTextFile
通常情况下,我们会从存储介质中获取数据,一个比较常见的方式就是读取日志文件。这也是批处理中最常见的读取方式。
DataStream<String> stream = env.readTextFile("clicks.csv");
说明:
-
参数可以是目录也可以是文件
-
路径可以是相对路径也可以是绝对路径
-
相对路径是从系统属性user.dir获取路径:idea下是project的根目录,standalone模式下是集群节点根目录;
-
也可以从hdfs目录下读取,使用路径hdfs://…,由于Flink没有提供Hadoop相关依赖所以pom文件中需要添加相关依赖;
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.5</version> <scope>provided</scope> </dependency>
5.2.3 从Socket读取数据
socketTextStream
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无界的。这时又从哪里读取呢?
一个简单的方式,就是我们之前用到的读取 socket 文本流。这种方式由于吞吐量小、稳定性较差,一般也是用于测试。
DataStream<String> stream = env.socketTextStream("localhost", 7777);
5.2.4 从kafka读取数据 ★
Kafka 作为分布式消息传输队列,是一个高吞吐、易于扩展的消息系统。而消息队列的传输方式,恰恰和流处理是完全一致的。所以可以说 Kafka 和 Flink 天生一对,是当前处理流式数据的双子星。在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算,这样的架构已经成为众多企业的首选。
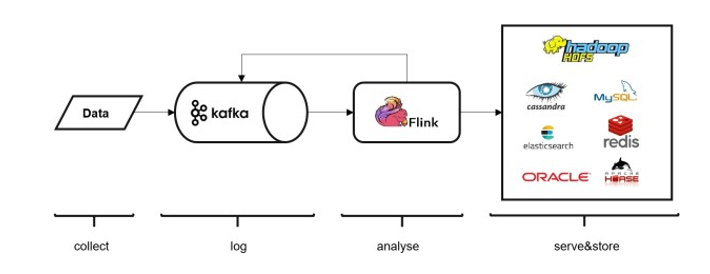
env.addSource(new FlinkKafkaConsumer<String>(...))
添加依赖:
<!-- flink 1.15以后不再支持scala2.11,都默认使用2.12,所以无需选择scala版本 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 配置kafka源
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("bigdata105:9092,bigdata106:9092,bigdata107:9092")
.setTopics("topic_test")
.setGroupId("consumer-group-test")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> clicksStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Clicks");
clicksStream.print();
env.execute();
}
setBootstrapServers:kafka brokers;
setTopics:topic/主题,可以是列表,或者正则表达式;
setGroupId:消费者组;
setStartingOffsets:开始消费的offset;
setValueOnlyDeserializer:”反序列化器“。kafka消息被存储为原始的字节数据,所以需要反序列化为Java对象,上面的SimpleStringSchema是一个简单的内置的反序列化器,将字节数组简单的反序列化成字符串。我们可以根据需要自定义我们的反序列化器。
附:往kafka topic写入数据,python脚本。用于测试
import time import datetime from kafka import KafkaProducer import json producer = KafkaProducer(value_serializer=lambda v: json.dumps(v).encode('utf-8'), bootstrap_servers='bigdata105:9092,bigdata106:9092,bigdata107:9092') topic_name = "topic_test" while True: producer.send(topic_name, datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')) time.sleep(2)
5.2.5 自定义Source
如果遇到特殊情况, 我们想要读取的数据源来自某个外部系统,而 flink 既没有预实现的方法、也没有提供连接器, 又该怎么办呢?那就只好自定义实现 SourceFunction 了。接下来我们创建一个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法:run()和 cancel()。
run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
自定义一个数据源ClickSource
package com.zlin.flink.env;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Calendar;
import java.util.Random;
/**
* @author tangzl
* @date 2023/3/17
**/
public class ClickSource implements SourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
Random random = new Random();
@Override
public void run(SourceContext ctx) throws Exception {
// 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (Boolean.TRUE.equals(running)){
ctx.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}
测试:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> clicksStream = env.addSource(new ClickSource());
clicksStream.print();
env.execute();
}
注意: SourceFunction 接口定义的数据源,并行度只能设置为 1。如果我们想要自定义并行的数据源的话,需要使用 ParallelSourceFunction
5.2.6 Flink支持的数据类型
1、Flink的类型系统
为了方便处理数据,Flink有自己的一整套类型系统。Flink使用”类型信息“(TypeInformation)来统一表示数据类型。
TypeInformation 类是 Flink 中所有类型描述符的基类,它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
2、Flink支持的数据类型
Flink支持的类型在Types工具类中可以看到。
import org.apache.flink.api.common.typeinfo.Types;
分类:
(1)基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger。
(2)数组类型
基本数组和对象数组
(3)符合数据类型
-
Java元组类型Tuple
-
行类型Row
-
Scala样例类及Scala元组不支持空字段
-
POJO
(4)辅助类型
Option,Either,List,Map等
(5)泛型类型
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义, 就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
附:
POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型
类是公共的(public)和独立的(standalone,也就是说没有非静态的内部类);
类有一个公共的无参构造方法;
类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范
3.类型提示
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息, 从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的——只告诉 Flink 当前的元素由
“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API 提供了专门的“类型提示”(type hints)。
回忆一下之前的 word count 流处理程序,我们在将 String 类型的每个词转换成二元组后,就明确地用 returns 指定了返回的类型。因为对于 map 里传入的 Lambda 表达式,系统只能推断出返回的是 Tuple2 类型,而无法得到 Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
这是一种比较简单的场景,二元组的两个元素都是基本数据类型。那如果元组中的一个元素又有泛型,该怎么处理呢?
Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
5.3 转换算子
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cS3RU3oS-1693060509951)(第五章 DataStream API.assets/image-20230319143302666.png)]
从数据源通过源算子读入数据后,我们就要对数据进行处理也是实现业务逻辑的地方,这个处理过程是将一个或多个DataStream转换成新的DataStream。
5.3.1 基本转换算子
1、映射(map)
一个一个处理,来一个处理一个。
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper)
可以看到需要传入一个MapFunction的实现类。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("zhangsan", "./home", 1000L),
new Event("lisi", "./job", 2000L));
// 方式一:直接通过lambda表达式,传入一个MapFunction的实现
stream.map((MapFunction<Event, String>) Event::getUser).print("ddd");
// 方式二:通过创建一个MapFunction实现类
stream.map(new UserExtractor()).print();
env.execute();
}
// Event输入类型,String输出类型,可以自己修改,自定义实现逻辑
public class UserExtractor implements MapFunction<Event, String> {
@Override
public String map(Event value) throws Exception {
return value.getUser();
}
}
2、过滤(filter)
对数据做过滤。
public SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
需要传入FilterFunction的实现类
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("zhangsan", "./home", 1000L),
new Event("lisi", "./job", 2000L));
// 方式一:lambda表达式
stream.filter((FilterFunction<Event>) event -> event.getUser().equals("lisi")).print("ddd");
// 方式二:FilterFunction实现类
stream.filter(new UserFilter()).print();
env.execute();
}
// 实现过滤的逻辑
public class UserFilter implements FilterFunction<Event> {
@Override
public boolean filter(Event value) throws Exception {
return value.getUser().equals("lisi");
}
}
3、扁平映射(flatmap)
DataStream → DataStream: 输入一个参数,产生0个、1个或者多个输出.
public interface FlatMapFunction<T, O> extends Function
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> stream = env.fromElements("ABC","FDS");
stream.flatMap(new FlatMapFunction<String, Character>() {
@Override
public void flatMap(String in, Collector<Character> out) throws Exception {
for(int i = 0; i < in.length(); i++){
out.collect(in.charAt(i));
}
}
}).print("ddd");
stream.flatMap(new MyFlatMap()).print();
env.execute();
}
public class MyFlatMap implements FlatMapFunction<String, Character> {
@Override
public void flatMap(String in, Collector<Character> out) throws Exception {
for(int i = 0; i < in.length(); i++){
out.collect(in.charAt(i));
}
}
}
5.3.2 聚合算子(Aggregation)
1、按键分区(keyBy)
基于不同的key,将流中的数据分配到不同的分区中去。
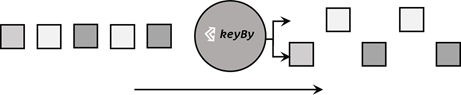
在内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以这里 key 如果是 POJO 的话,必须要重写 hashCode()方法。
public <K> KeyedStream<T, K> keyBy(KeySelector<T, K> key)
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("zhangsan", "./home", 1000L),
new Event("lisi", "./job", 2000L));
KeyedStream<Event, String> keyedStream = stream.keyBy(Event::getUser);
keyedStream.print("a");
stream.keyBy(new MyKeySelector()).print("b");
env.execute();
}
//KeyedStream 分区流、键控流
2、简单聚合
有了KeyedStream分区流,那么怎么把这些分区流的数据聚合起来呢?Flink内置了一些基本的聚合操作
-
sum():按指定字段叠加求和
-
min():指定字段最小值,字段为单位
-
max():指定字段最大值
-
minBy():与min不同的是,会返回包含字段最小值的整条数据,记录为单位
-
maxBy():同理
指定字段有两种方式:指定位置,指定名称。需要注意的是,元组中字段的名称,是以 f0、f1、f2、…来命名的
min和minBy比较:
例如:输入
data.add(new Tuple3<>(0, 1, 1));
data.add(new Tuple3<>(0, 2, 0));
data.add(new Tuple3<>(0, 2, 2));
min()输出:
(0, 1, 1)
(0, 1, 0)
(0, 1, 0)
minBy()输出:
(0, 1, 1)
(0, 2, 0)
(0, 2, 0)
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Tuple2<String, Integer>> stream = env.fromElements( Tuple2.of("a", 3),
Tuple2.of("a", 1),
Tuple2.of("b", 3),
Tuple2.of("b", 4)
);
stream.keyBy(r -> r.f0).sum(1).print();
stream.keyBy(r -> r.f0).sum("f1").print();
stream.keyBy(r -> r.f0).max(1).print();
stream.keyBy(r -> r.f0).max("f1").print();
stream.keyBy(r -> r.f0).min(1).print();
stream.keyBy(r -> r.f0).min("f1").print();
stream.keyBy(r -> r.f0).maxBy(1).print();
stream.keyBy(r -> r.f0).maxBy("f1").print();
stream.keyBy(r -> r.f0).minBy(1).print();
stream.keyBy(r -> r.f0).minBy("f1").print();
env.execute();
}
5.3.3 用户自定义函数(UDF)
1、函数类(XXXFunction)
其实前面我们已经使用过了,例如创建MapFunction的实现类…
public class UserExtractor implements MapFunction<Event, String>
public static class FlinkFilter implements FilterFunction<Event>
2、匿名函数(Lambda表达式)
对于简单类型Flink可以直接提取类型信息,但是对于泛型,由于java编译器编译后擦除了泛型信息,所以Flink无法判断输出的类型信息了。有以下方式可以解决该问题:
-
使用returns显示声明返回的类型
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<String> stream = env.fromElements("ABC","FDS"); stream.flatMap((FlatMapFunction<String, Character>) (in, out) -> { for(int i = 0; i < in.length(); i++){ out.collect(in.charAt(i)); } }).returns(Types.CHAR).print(); env.execute(); } -
使用自定义类来替代Lambda表达式
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<String> stream = env.fromElements("ABC","FDS"); stream.flatMap(new MyFlatMap()).print(); env.execute(); } -
使用匿名类来代替Lambda表达式
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<String> stream = env.fromElements("ABC","FDS"); stream.flatMap(new FlatMapFunction<String, Character>() { @Override public void flatMap(String in, Collector<Character> out) throws Exception { for(int i = 0; i < in.length(); i++){ out.collect(in.charAt(i)); } } }).print("ddd"); env.execute(); }
3、富函数类(Rich Function Classes)
也是DataStream API提供的一个函数类的接口。与常规函数类相比,它可以提供更多、更丰富的功能。主要在于可以获取运行环境的上下文,并拥有一些生命周期方法,可以实现更复杂的功能。
Rich Function 典型的生命周期方法:
-
open(),初始化方法,在调用实际工作方法如map()、filter()时,open会首先被调用。所以主要适合用来完成IO的创建、配置文件的读取、数据库创建连接等一次性操作。
-
close(),最后一个调用的方法,一般用于做一些收尾工作如清理、关闭连接。
注意:生命周期方法对于每一个并行子任务来说,只会调用一次,而实际工作方法,每来一条数据都会执行一次。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L)
);
clicks.map(new MyFunction()).print();
env.execute();
}
索引为0的任务开始
索引为1的任务开始
1> 2000
2> 1000
1> 60000
2> 5000
索引为1的任务结束
索引为0的任务结束
5.3.4 物理分区
“分区”操作就是要将数据进行重新分布,传递到不同的流分区中去进行下一步处理。KeyBy就是一种根据键的哈希值来进行分区的操作。至于分的均不均匀,每个key分布到哪个分区无法控制。所以称KeyBy是一种逻辑分区/软分区。KeyBy分区之后,结果返回是keyedStream。
物理分区:通过分区策略,把数据按照分区策略进行分区。物理分区之后结果仍然是DataStream。
常见的物理分区策略:随机分配、轮询分配、重缩放、广播
1、随机分区(shuffle)
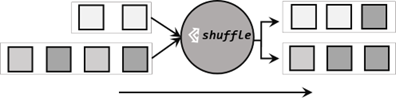
服从均匀分布,把数据随机打乱,均匀传递到下游分区。由于是随机的,所以对于同样的输入数据,每次执行结果也可能不相同。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// .shuffle 将数据打乱,print时将并行度设置为4
stream.shuffle().print().setParallelism(4);
env.execute();
}
3> Event{user='Alice', url='./prod?id=1', timestamp=2023-03-25 22:40:15.498}
1> Event{user='Alice', url='./prod?id=1', timestamp=2023-03-25 22:40:16.521}
4> Event{user='Cary', url='./fav', timestamp=2023-03-25 22:40:17.531}
3> Event{user='Alice', url='./prod?id=1', timestamp=2023-03-25 22:40:18.54}
1> Event{user='Alice', url='./prod?id=2', timestamp=2023-03-25 22:40:19.549}
4> Event{user='Bob', url='./home', timestamp=2023-03-25 22:40:20.562}
4> Event{user='Bob', url='./cart', timestamp=2023-03-25 22:40:21.568}
3> Event{user='Cary', url='./prod?id=2', timestamp=2023-03-25 22:40:22.576}
2> Event{user='Mary', url='./cart', timestamp=2023-03-25 22:40:23.589}
2> Event{user='Alice', url='./prod?id=1', timestamp=2023-03-25 22:40:2
2、轮询分区(Round-Robin)
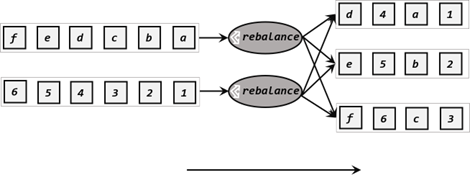
依次轮流分发。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource());
stream.rebalance().print().setParallelism(2);
env.execute();
}
2> Event{user='Alice', url='./cart', timestamp=2023-03-25 22:49:53.459}
1> Event{user='Alice', url='./prod?id=2', timestamp=2023-03-25 22:49:54.478}
2> Event{user='Alice', url='./prod?id=1', timestamp=2023-03-25 22:49:55.488}
1> Event{user='Bob', url='./prod?id=1', timestamp=2023-03-25 22:49:56.489}
2> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 22:49:57.497}
1> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 22:49:58.503}
从结果可以看出数据轮流发送到不同分区。
3、重缩放分区(rescale)
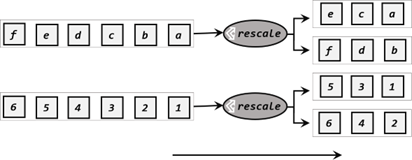
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin 算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中,如图 5-11 所示。也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
当下游任务(数据接收方)的数量是上游任务(数据发送方)数量的整数倍时,rescale 的效率明显会更高。比如当上游任务数量是 2,下游任务数量是 6 时,上游任务其中一个分区的数据就将会平均分配到下游任务的 3 个分区中。
由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看,rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。rebalance 将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource()).setParallelism(2);
stream.rescale().print().setParallelism(4);
env.execute();
}
4、广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource()).setParallelism(2);
stream.broadcast().print().setParallelism(4);
env.execute();
}
1> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
3> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
2> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
4> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
2> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
1> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
3> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
4> Event{user='Mary', url='./prod?id=2', timestamp=2023-03-25 23:51:57.601}
...
从输出结果可以看到:
首先数据源的并行度是2,然后每个数据发送到下游所有分区4。
5、全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource()).setParallelism(2);
stream.global().print().setParallelism(4);
env.execute();
}
6、自定义分区
我们可以通过使用partitionCustom()方法来自定义分区策略。
在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的字段,它的指定方式与 keyBy 指定 key 基本一样:可以通过字段名称指定, 也可以通过字段位置索引来指定,还可以实现一个 KeySelector。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 将自然数按照奇偶分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8)
.partitionCustom(new MyPartitioner(), new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer value) throws Exception { return value;
}
})
.print().setParallelism(2);
env.execute();
}
public class MyPartitioner implements Partitioner<Integer> {
@Override
public int partition(Integer key, int numPartitions) {
return key % numPartitions;
}
}
// 注意这里返回的分区的下标是从0开始。比如你设置的分区数是4,那么partition返回的分区号的范围是[0-3]
5.4 输出算子
源算子是获取数据,转换算子是对数据做处理,输出算子就是将结果输出。同时我们也把输出算子叫做数据汇。
5.4.1 连接到外部系统
像print就是Flink预实现的输出算子,它是将结果输出到控制台。除了一些预实现算子,一般通过调用.addSink()实现。
stream.addSink(new SinkFunction(…));
可以看到,需要传入一个SinkFunction的实现类。这和源算子是类似的。
Flink目前支持的第三方系统连接器:

除 Flink 官方之外,Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一些其他第三方系统与 Flink 的连接器,如图 5-14 所示。
5.4.2 输出到文件
在Flink旧版本中,有一些简单粗暴的api如:writeAsText()、writeAsCsv(),将数据输出到文本文件或者csv文件,但是这种方式不支持同时写入,所以最后的sink操作并行度只能是1。所以写入效率很低。而且故障恢复后的状态一致性也没有保证。目前这些方法即将被弃用。
Flink为此专门提供了一个流式文件系统的连接器:FileSink
File Sink 将传入的数据写入存储桶中。考虑到输入流可以是无界的,每个桶中的数据被组织成有限大小的 Part 文件。 完全可以配置为基于时间的方式往桶中写入数据,比如可以设置每个小时的数据写入一个新桶中。这意味着桶中将包含一个小时间隔内接收到的记录。
FileSink支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet) 格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用 StreamingFileSink 的静态方法
• 行编码:FileSink.forRowFormat(basePath,rowEncoder)。
• 批量编码:FileSink.forBulkFormat(basePath,bulkWriterFactory)。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L)
);
FileSink<String> fileSink = FileSink.forRowFormat(new Path("./output"), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(15))
.withInactivityInterval(Duration.ofMinutes(5))
.withMaxPartSize(MemorySize.ofMebiBytes(1024))
.build()
).build();
stream.map(Event::toString).sinkTo(fileSink);
env.execute();
}
通过.withRollingPolicy()方法指定了一个“滚动策略”。“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
• 至少包含 15 分钟的数据
• 最近 5 分钟没有收到新的数据
• 文件大小已达到 1 GB
5.4.3 输出到kafka
Kafka 是一个分布式的基于发布/订阅的消息系统,本身处理的也是流式数据,所以跟Flink“天生一对”,经常会作为Flink 的输入数据源和输出系统。Flink 官方为Kafka 提供了Source和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数据。如果仅仅是支持读写,那还说明不了 Kafka 和 Flink 关系的亲密;真正让它们密不可分的是,Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。
在pom文件中引入依赖(如果在源算子kakfa章节中,已经添加过了,这里可忽略):
<!-- flink 1.15以后不再支持scala2.11,都默认使用2.12,所以无需选择scala版本 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("bootstrap.servers", "hadoop102:9092");
DataStreamSource<String> stream = env.readTextFile("./input/clicks.csv");
stream
.addSink(new FlinkKafkaProducer<String>( "test",
new SimpleStringSchema(), properties
));
stream.print();
env.execute();
}
[root@hadoop102 bin]# kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic test
"Mary", "./home", 1000L
"Bob", "./cart", 2000L
"Alice", "./prod?id=200", 3500L
5.4.4 输出到redis
添加依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").build();
env.addSource(new ClickSource()).addSink(new RedisSink<Event>(conf, new MyRedisMapper()));
env.execute();
}
public class MyRedisMapper implements RedisMapper<Event> {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "clicks");
}
@Override
public String getKeyFromData(Event event) {
return event.getUser();
}
@Override
public String getValueFromData(Event event) {
return event.getUrl();
}
}
5.4.5 输出到Elasticsearch
添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_2.12</artifactId>
<version>1.14.4</version>
</dependency>
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L)
);
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event element, RuntimeContext ctx, RequestIndexer indexer) {
HashMap<String, String> data = new HashMap<>(); data.put(element.user, element.url);
IndexRequest request = Requests.indexRequest()
.index("clicks")
.type("type") // Es 6 必须定义 type
.source(data);
indexer.add(request);
}
};
stream.addSink(new ElasticsearchSink.Builder<Event>(httpHosts, elasticsearchSinkFunction).build());
env.execute();
}
与RedisSink类 似,连接器也为我们实现了写入到Elasticsearch的SinkFunction——ElasticsearchSink。区别在于,这个类的构造方法是私有(private)的,我们需要使用 ElasticsearchSink 的 Builder 内部静态类,调用它的 build()方法才能创建出真正的SinkFunction。
而 Builder 的构造方法中又有两个参数:
• httpHosts:连接到的 Elasticsearch 集群主机列表
• elasticsearchSinkFunction:这并不是我们所说的 SinkFunction,而是用来说明具体处理逻辑、准备数据向 Elasticsearch 发送请求的函数
具体的操作需要重写中 elasticsearchSinkFunction 中的 process 方法,我们可以将要发送的数据放在一个 HashMap 中,包装成 IndexRequest 向外部发送 HTTP 请求。
5.4.6 输出到MySQL(JDBC)
添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
在mysql中建表
mysql> create table clicks(
-> user varchar(20) not null,
-> url varchar(100) not null);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L)
);
stream.addSink(
JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)", (statement, r) -> {
statement.setString(1, r.user); statement.setString(2, r.url);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/userbehavior")
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("username")
.withPassword("password")
.build()
)
);
env.execute();
}
5.4.7 自定义Sink输出
与 Source 类似,Flink 为我们提供了通用的 SinkFunction 接口和对应的 RichSinkDunction 抽象类,只要实现它,通过简单地调用 DataStream 的.addSink()方法就可以自定义写入任何外部存储。
在实现 SinkFunction 的时候,需要重写的一个关键方法 invoke(),在这个方法中我们就可以实现将流里的数据发送出去的逻辑。我们这里使用了 SinkFunction 的富函数版本,因为这里我们又使用到了生命周期的概念,
例如,Flink 并没有提供 HBase 的连接器,所以需要我们自己写。创建 HBase 的连接以及关闭 HBase 的连接需要分别放在 open()方法和 close()方法中。
添加依赖:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.1</version>
</dependency>
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> stream = env.fromElements("hello", "world");
stream.addSink(new HbaseSink());
env.execute();
}
public class HbaseSink extends RichSinkFunction<String> {
public org.apache.hadoop.conf.Configuration configuration;
public Connection connection; // 管理 Hbase 连接
@Override
public void invoke(String value, Context context) throws Exception {
Table table = connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8)
, "1".getBytes(StandardCharsets.UTF_8));
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","hadoop102:2181");
connection = ConnectionFactory.createConnection(configuration);
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
}