"we had our heads in the clouds"
String类型
字符串类型是Redis最基础的数据类型,关于字符串需要特别注意的是:
● Redis中所有的键类型都是字符串类型.⽽且其他⼏种数据结构也都是在字符串类似基础上构建的,例如列表和集合的元素类型是字符串类型。
● 字符串类型的值实际可以是字符串,包含⼀般格式的字符串或者类似JSON、XML格式的字符串,数字;可以是整型或者浮点型;甚⾄是⼆进制流数据(视频、音频),但是其总大小不得超过512MB。

(1) SET | MSET
SET命令
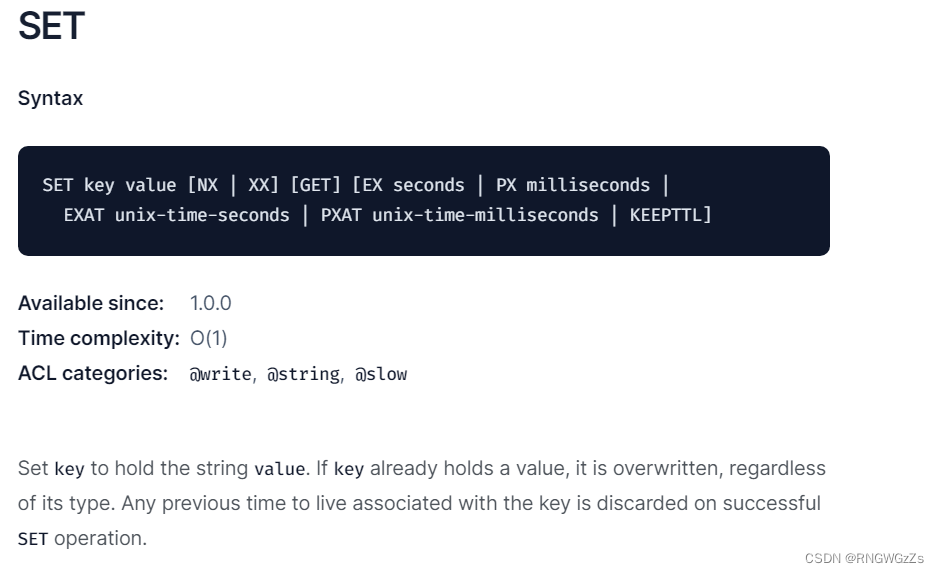
● NX: 如果key不存在,才设置;如果key存在,则不设置返回(nil).
● XX: 如果key存在,进行更新;如果key不存在,则不设置返回(nil).
● PX: 使⽤毫秒作为单位设置key的过期时间.
● EX: 使⽤秒作为单位设置key的过期时间.
在redis文档中的语法格式说明: "[]" 相当于一个独立的单元,其中的所有参数都是可选项。"[]"之间可以同时存在。"|"表示多个选项中,只能出现一个的意思。
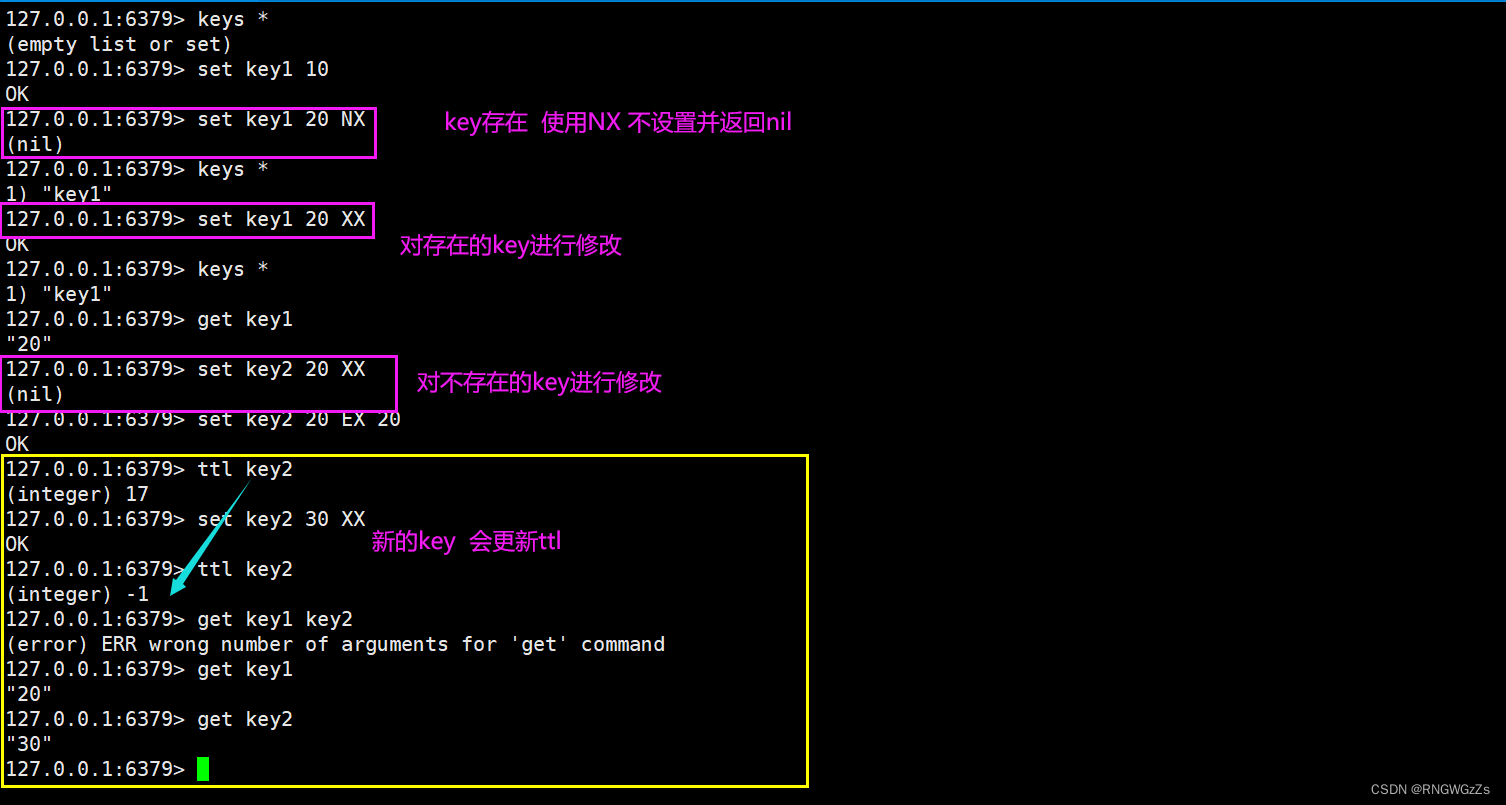
注: 如果key存在,让新的value去覆盖旧的value的同时,可能会改变原来的数据类型,原来key的ttl也会失效。
其中SETNX | SETTX | SETPX都是SET命令带上“[]"里的效果,所以会用一个SET命令仅够用了。

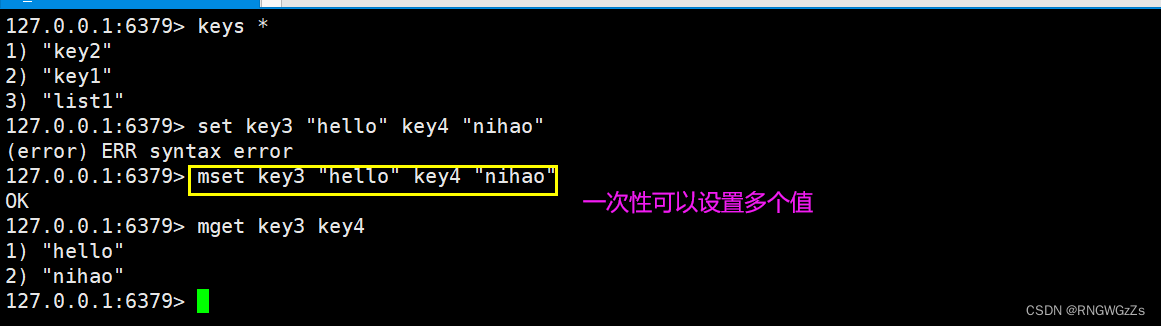
⼀次性设置多个key的值.
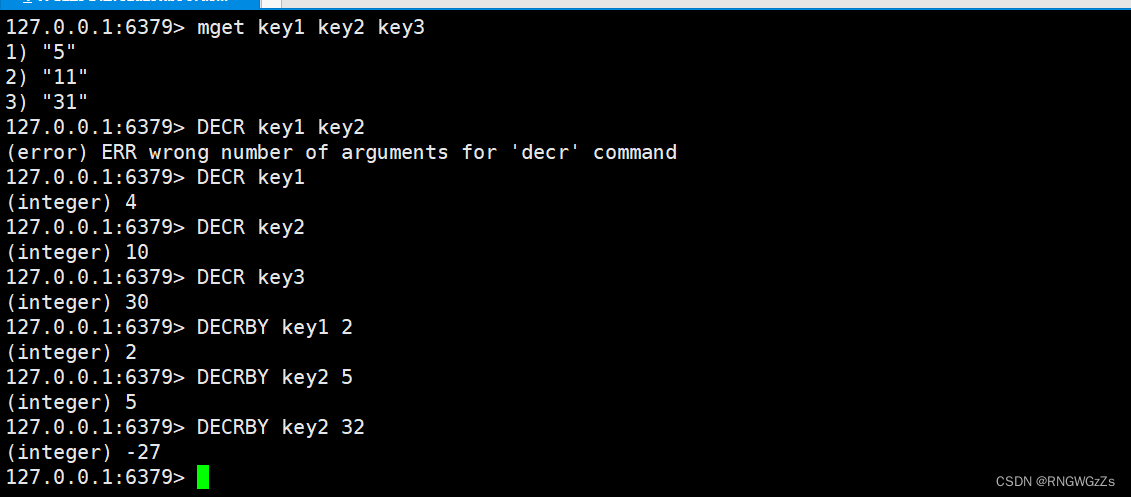
(2) GET | MGET

获取key对应的value。如果key不存在,返回nil。如果value的数据类型不是string,会报错 。 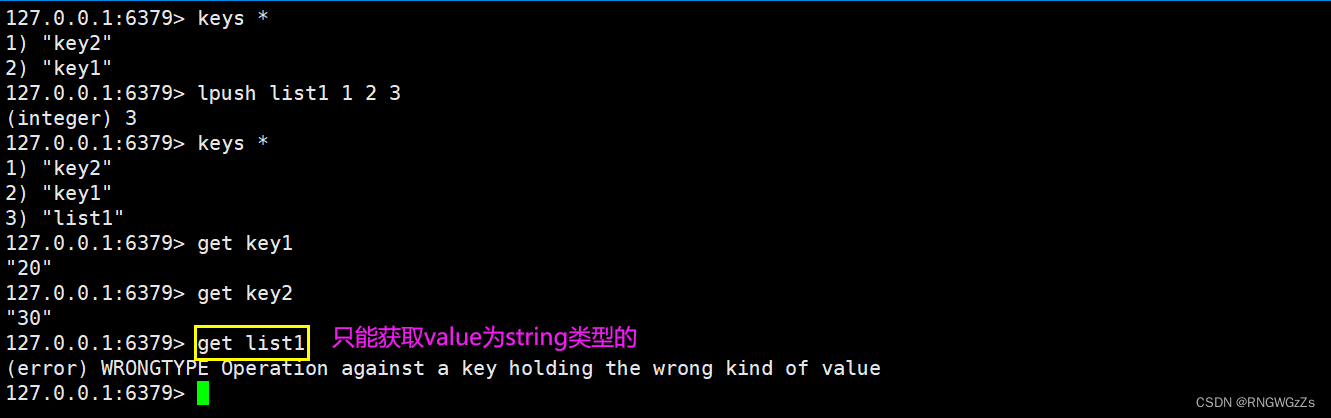
 ⼀次性获取多个key的值。如果对应的key不存在或者对应的数据类型不是string,返回nil。
⼀次性获取多个key的值。如果对应的key不存在或者对应的数据类型不是string,返回nil。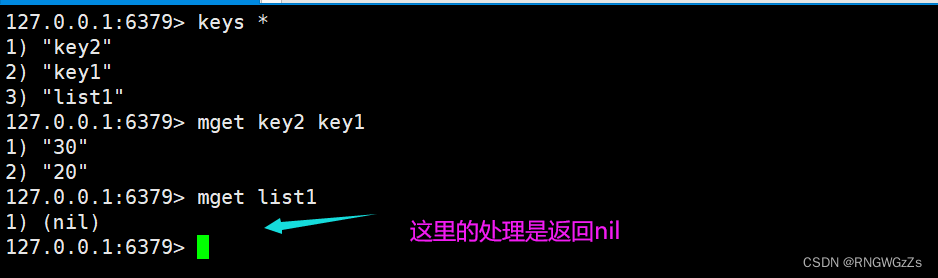
多次getvs单次mget: 
我们先使用 "keys *" 将缓存在redis中的数据打印出来,现在我们需要得到这些keys的value是什么。  这两种查询方法有什么区别呢?是不是都是一样呢?
这两种查询方法有什么区别呢?是不是都是一样呢?
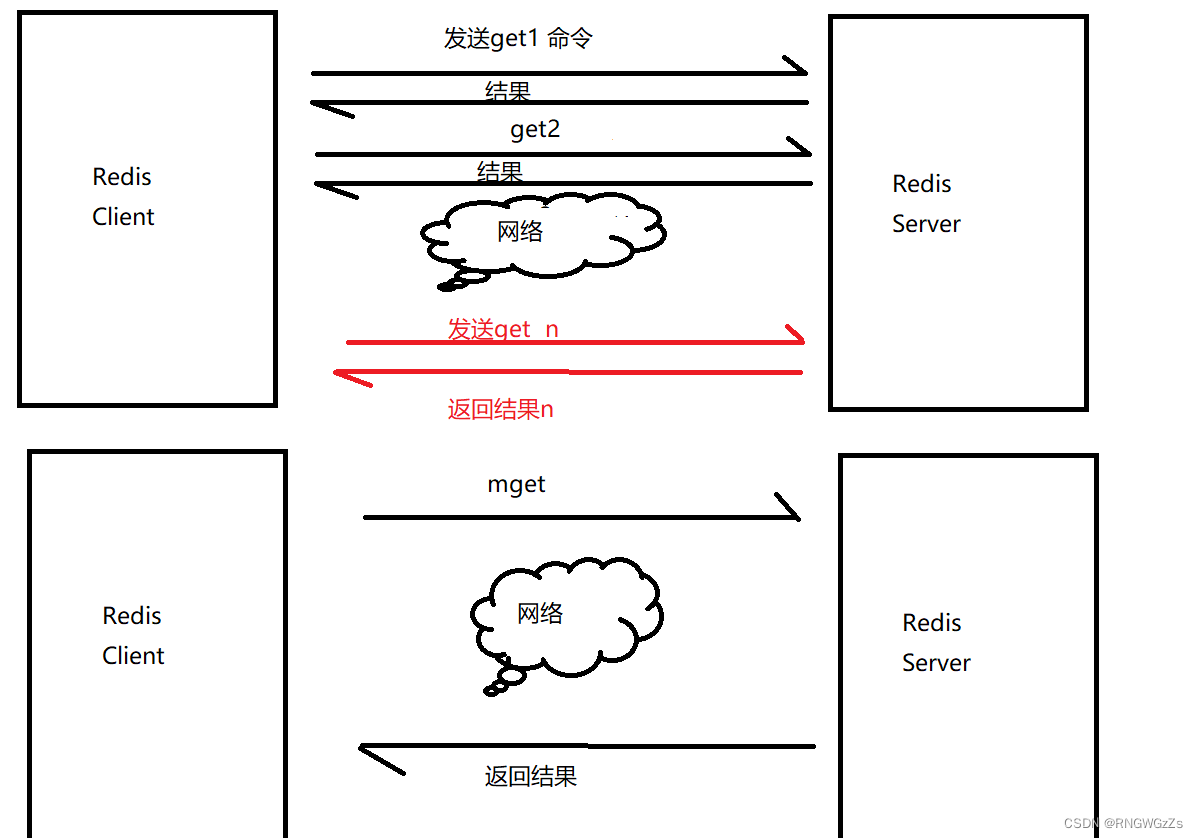 redis作为网络服务器,任何一条请求、命令都是需要通过网络设备进行发送的,当你发送多条命令,意味着多次网络IO,相反如果你能使用一次网络IO就将你需要的结果拿到,效率一定是更快的。
redis作为网络服务器,任何一条请求、命令都是需要通过网络设备进行发送的,当你发送多条命令,意味着多次网络IO,相反如果你能使用一次网络IO就将你需要的结果拿到,效率一定是更快的。
(3) 计数命令
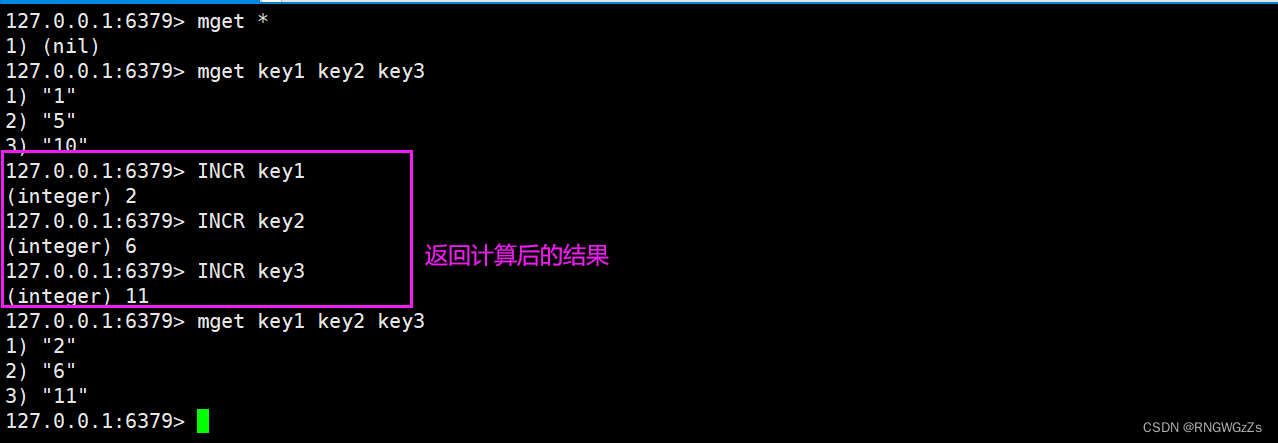
INCR:
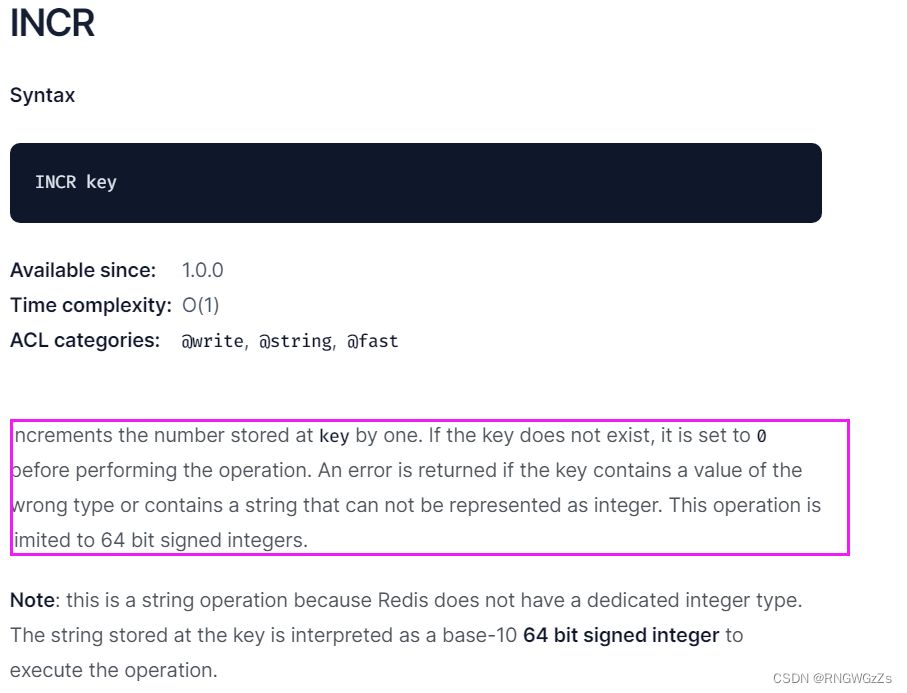 将key对应的string表⽰的数字加⼀。如果key不存在,则视为key对应的value是0。如果key对应的string不是⼀个整型或者范围超过了64位有符号整型。
将key对应的string表⽰的数字加⼀。如果key不存在,则视为key对应的value是0。如果key对应的string不是⼀个整型或者范围超过了64位有符号整型。
Redis中的String支持数字,这也就意味着String更容易支持 运算符操作。
INCRBY:
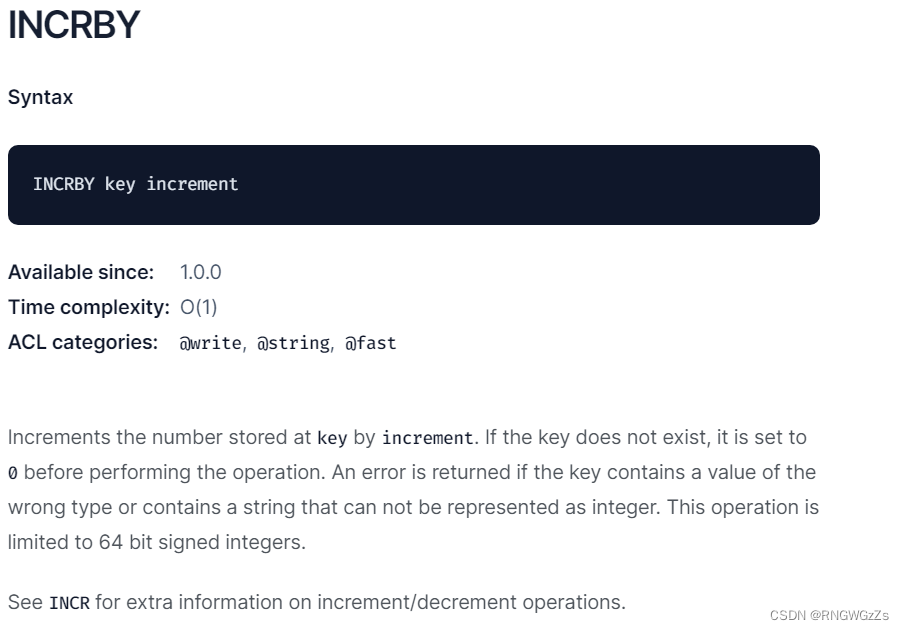 将key对应的string表⽰的数字加上对应的值,如果key不存在,则视为key对应的value是0果key对应的string不是⼀个整型或者范围超过了64位有符号整型,则报错。
将key对应的string表⽰的数字加上对应的值,如果key不存在,则视为key对应的value是0果key对应的string不是⼀个整型或者范围超过了64位有符号整型,则报错。
INCRBY的使用同INCR是一样的,只不过你可以指定增加多少。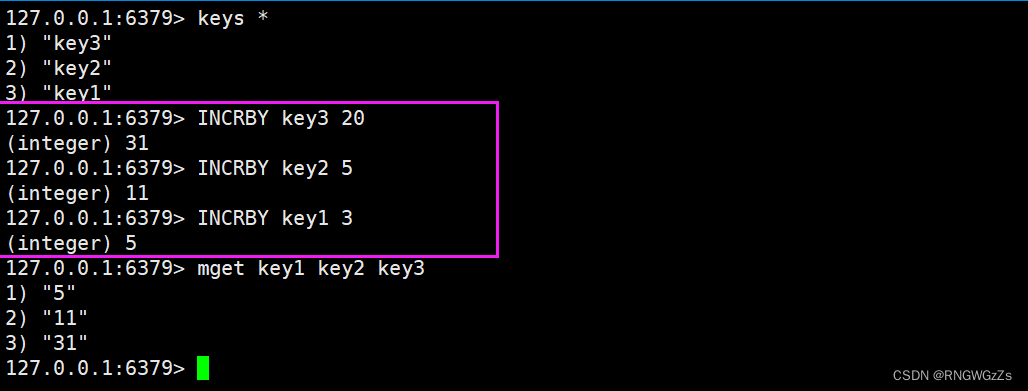
DECR\DECRBY:
将key对应的string表⽰的数字减⼀。如果key不存在,则视为key对应的value是0。如果key对应的string不是⼀个整型或者范围超过了64位有符号整型,则报错。
INCRBYFLOAT:

将key对应的string表⽰的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果key不存在,则视为key对应的value是0。如果key对应的不是string,或者不是⼀个浮点数,则报错。允许采⽤科学计数法表⽰浮点数。 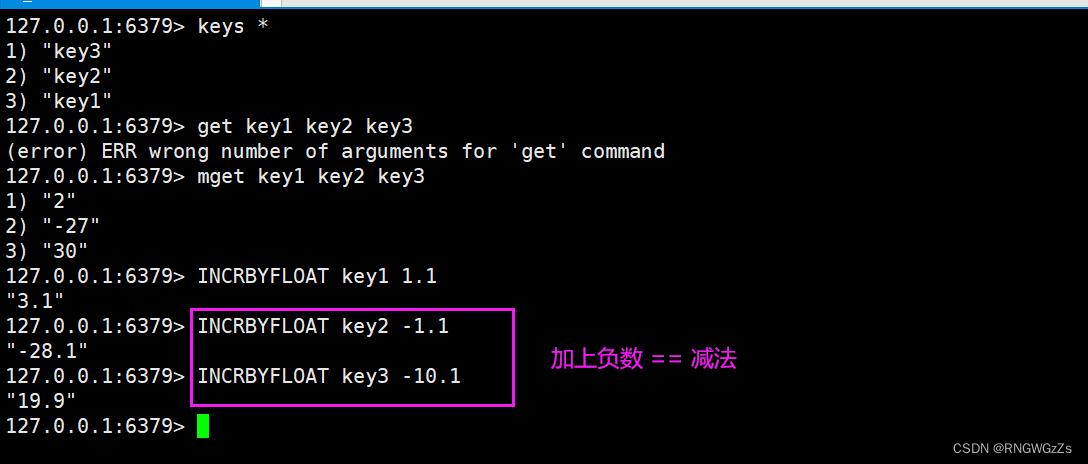
针对这个浮点数版本, redis没有提供负数版本,但是通过控制"+-"也可以实现减法版本。 因为redis在处理命令的时候,是单线程模型,虽然多个客户端可能同时对一个key进行INCR,但也不会引发线程安全问题。
(4) 其他命令字符串命令
前面的一些命令似乎和字符串关系不大,本小结的一些命令会让这个value字符串类型更像字符一样使用。
APPEND:

如果key已经存在并且是⼀个string,命令会将value追加到原有string的后边。如果key不存在,则效果等同于SET命令。
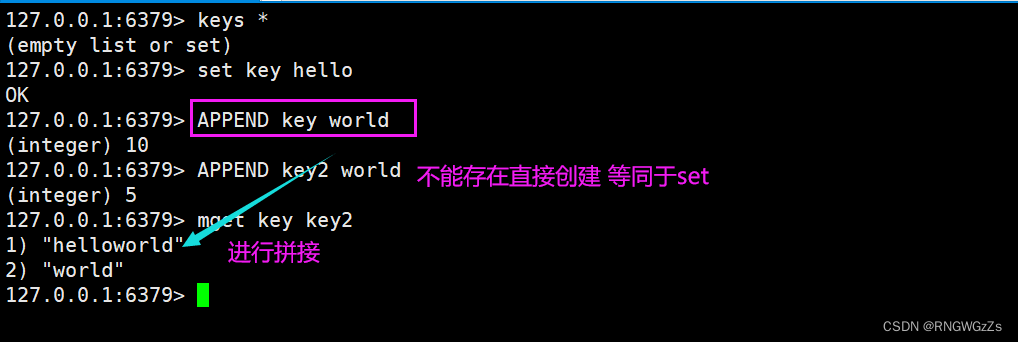
redis中的字节与字符:
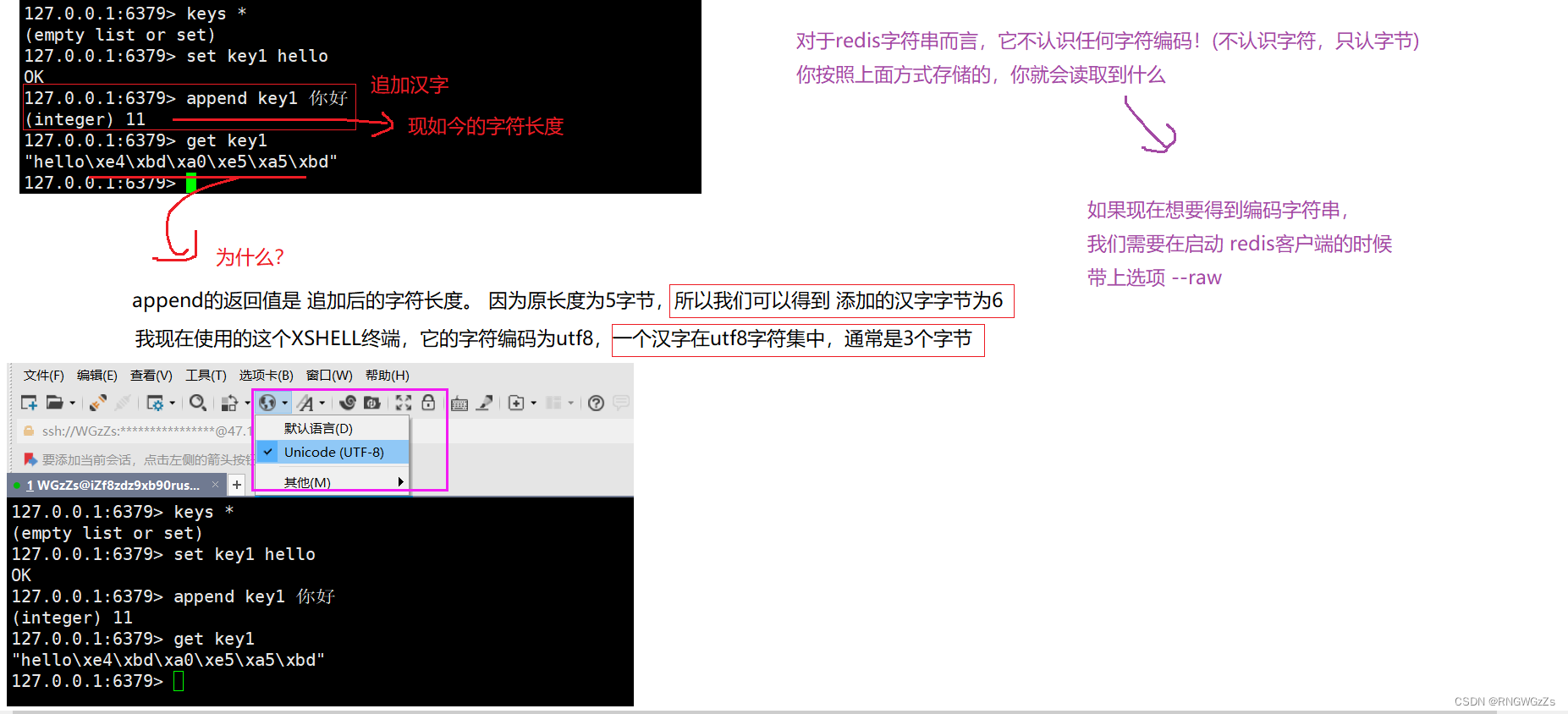
我们重启redis-cli客户端,并携带选项--raw。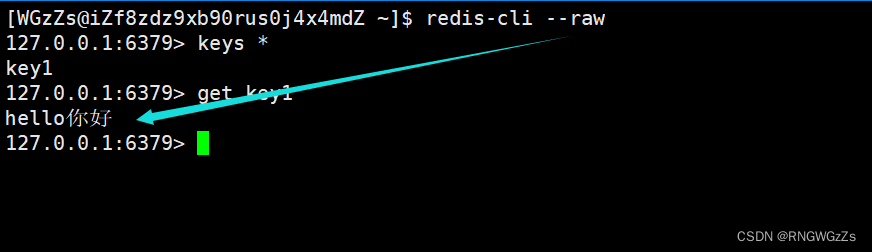
GETRANGE: 
返回key对应的string的⼦串,由start和end确定(左闭右闭)。可以使⽤负数表⽰倒数。-1代表倒数第⼀个字符,-2代表倒数第⼆个,其他的与此类似。超过范围的偏移量会根据string的⻓度调整成正确的值。 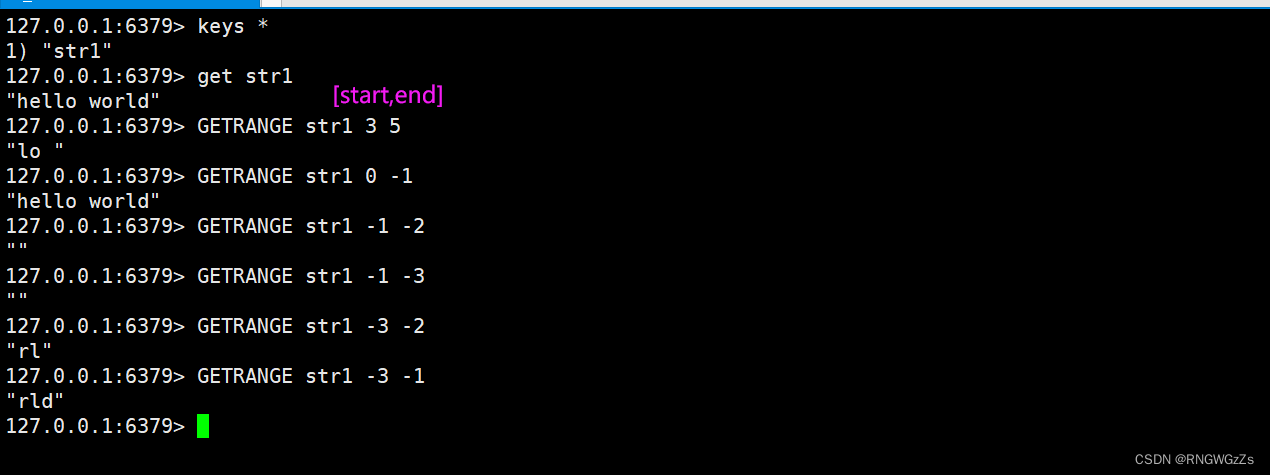
SETRANGE:

覆盖字符串的⼀部分,从指定的偏移开始。
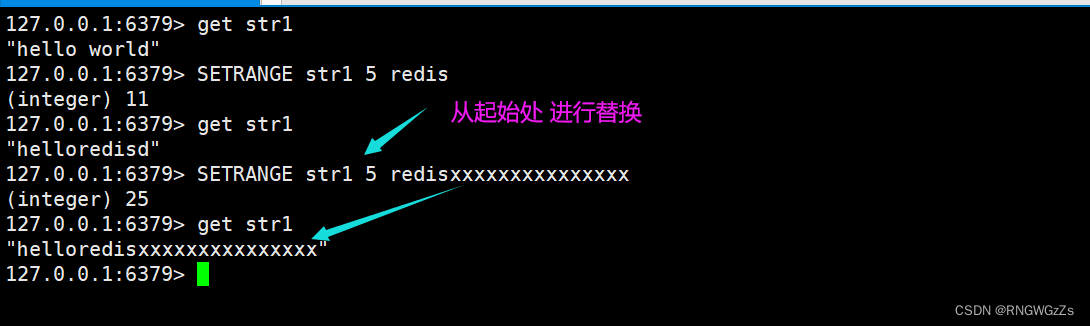
STRLEN:

获取key对应的string的⻓度。当key存放的类似不是string时,报错.

String命令小结:
| 命令 | 执行效果 | 时间复杂度 |
| set key value | 设置key的值value | O(1) |
| get key | 获取key的value | O(1) |
| del key [key ...] | 删除指定的key | O(k),k为键个数 |
| mset key value [key value..] | 批量设置多个key和value | O(N) |
| mget key | 批量获取多个key | O(N) |
| incr\incrby +b key | 指定key+1\+n | O(1) |
| decrby key n | 指定key-1 | O(1) |
| incrbyfloat key n | 指定key +- n | O(1) |
| strlen key | 获取字符串类型key的长度 | O(n),字符长度 |
| setrange key offset value | 从offset的位置用value覆盖key | O(n),n是字符串长度 |
| getrange key start end | 指定获取key的value 从start到end | O(n),n为字符串长度 |
String 内部编码
字符串类型的内部编码有3种:
• int:64位/8字节的正数。
• embstr:⼩于等于39个字节的字符串,压缩字符串适合存储短字符串。
• raw:⼤于39个字节的字符串。普通字符串,只是一个单纯的字节数组。
我们可以通过这个命令,查看一个key对应的数据value的内部编码:

 这里到底是超过多少字节就由embstr 转为 raw这个限度是可以进行配置的。
这里到底是超过多少字节就由embstr 转为 raw这个限度是可以进行配置的。
 因为redis存储小数,本质上仍然是用字符串来存储的,这就和单纯存储整数相差挺大的。当小数参与到算术运算时,一定要做的步骤是,将字符串转换为小数数值,得到结果后又将该小数转换为字符串。
因为redis存储小数,本质上仍然是用字符串来存储的,这就和单纯存储整数相差挺大的。当小数参与到算术运算时,一定要做的步骤是,将字符串转换为小数数值,得到结果后又将该小数转换为字符串。
String应用场景
① 缓存Cache功能:
我们可以看如下的一个典型场景:
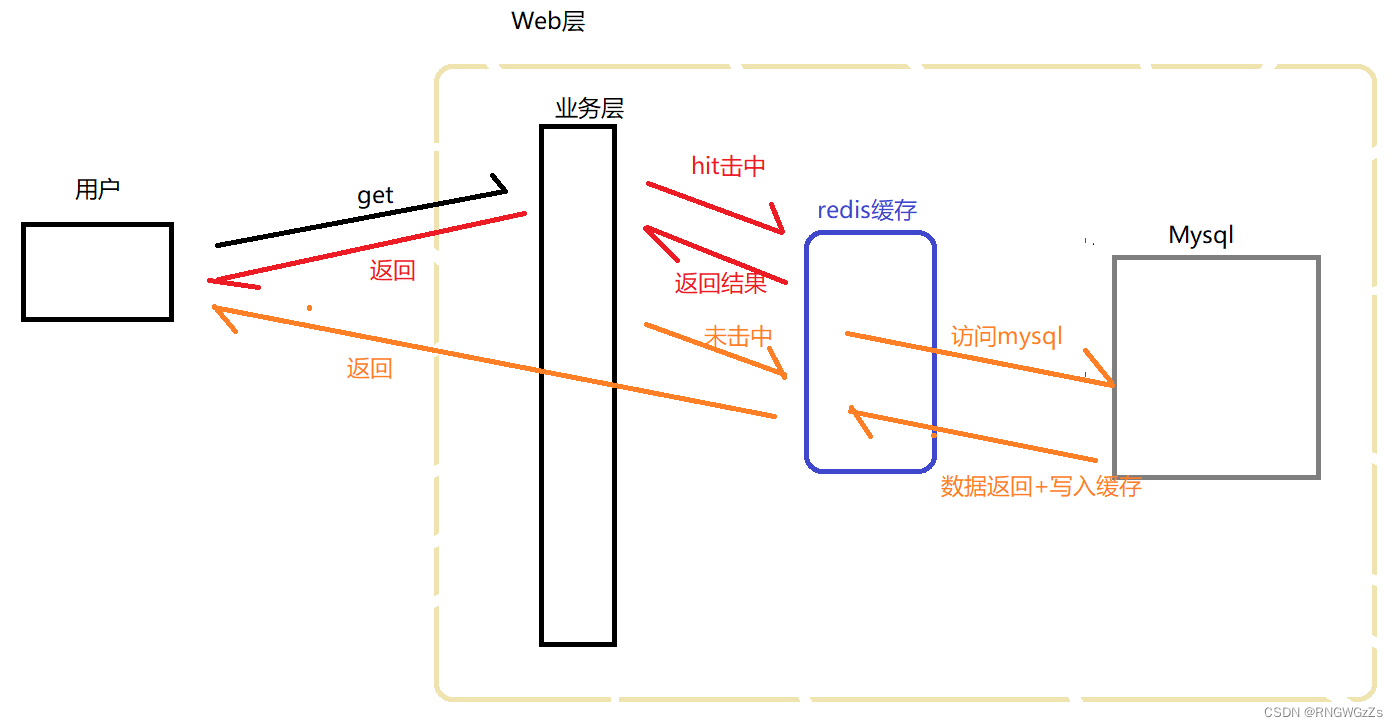
其中redis作为缓冲层,Mysql作为主要存储层,绝大部分请求数据会通过redis缓存拿到结果。因为redis具有⽀撑⾼并发的特性,缓存常能起到加速读写和降低后端压⼒的作⽤。
随着访问量的增加,redis一定会遇到缓存被打满的情况,redis提供了一系列措施来解决redis面对的存储空间变小的,例如 给key设置过期策略,定期、惰性删除以及当redis内存不足时,使用的淘汰策略。
② 计数器Counter:
做自媒体的博主,十分在意的就是用户浏览量。许多应⽤都会使⽤Redis作为计数的基础⼯具,它可以实现快速计数、查询缓存的功能,同时数据可以异步处理或者落地到其他数据源。 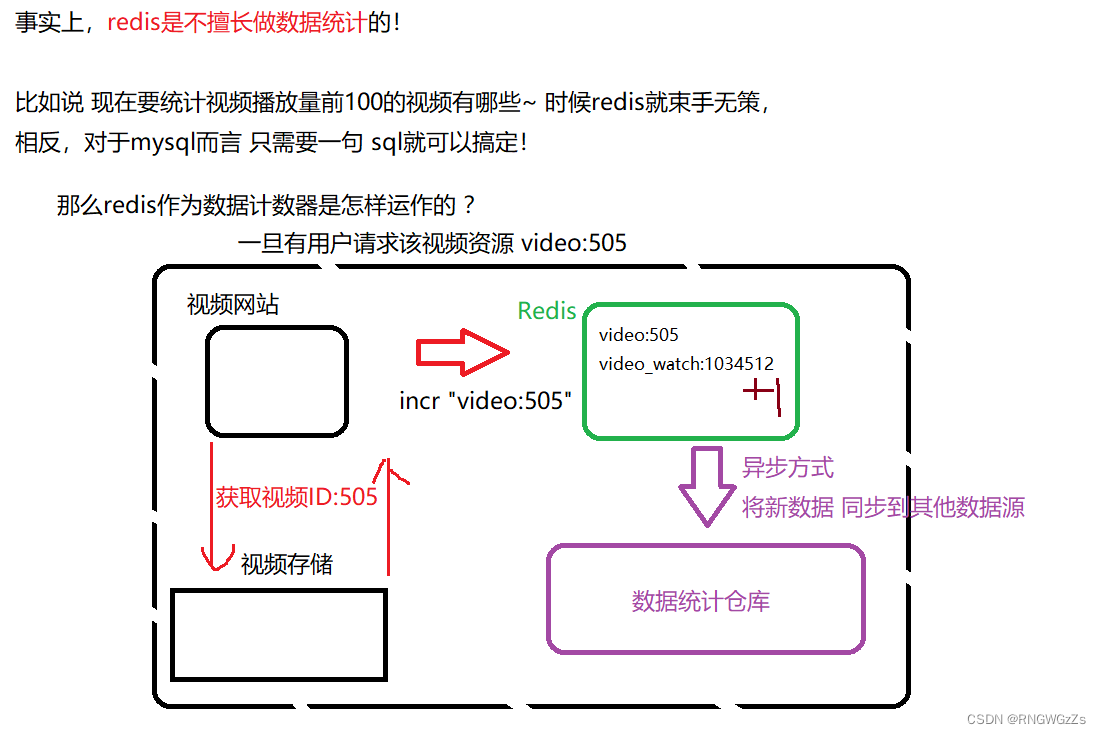
③ 会话Session:
什么是session?
Session:在计算机中,尤其是在网络应用中,称为“会话控制”。Session对象存储特定用户会话所需的属性及配置信息。
在一个分布式Web中,如果服务器将⽤⼾的Session信息保存在各⾃的服务器中,这样做就会导致一个问题:由于负载均衡器的缘故,分布式服务会将⽤⼾的访问请求均衡到不同的服务器上,也就是你的第一次请求和第二次请求可能被打在了不同的服务器上。很显然,接收你第二次请求的服务器不应该知道你是已经登录过了的,或者你历史访问的信息。 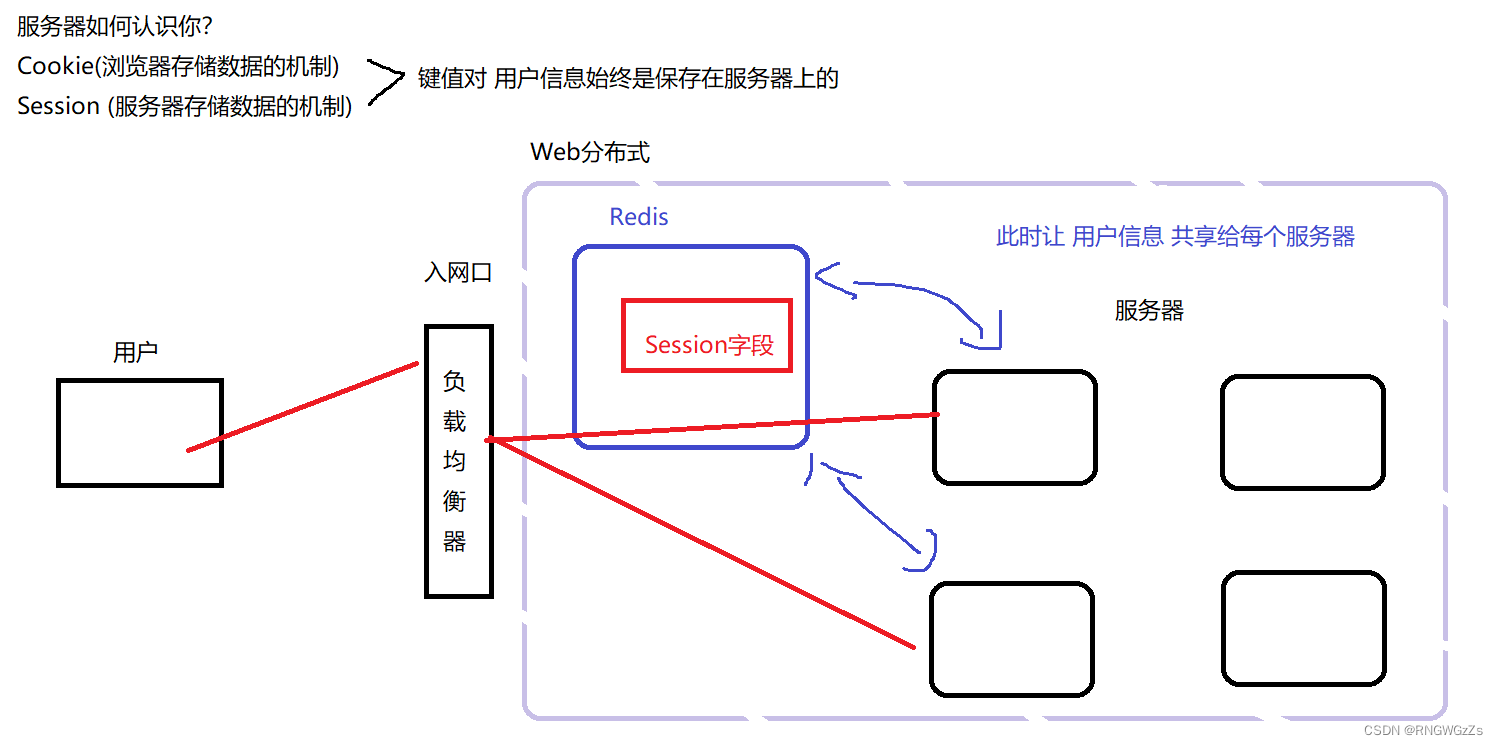
以上介绍了使⽤Redis的字符串数据类型可以使⽤的⼏个场景,当然其适⽤场景远不⽌于此,开发⼈员可以结合字符串类型的特点以及提供的命令,充分发挥⾃⼰的想象⼒,在⾃⼰的业务中去找到合适的场景去使⽤Redis的字符串类型。
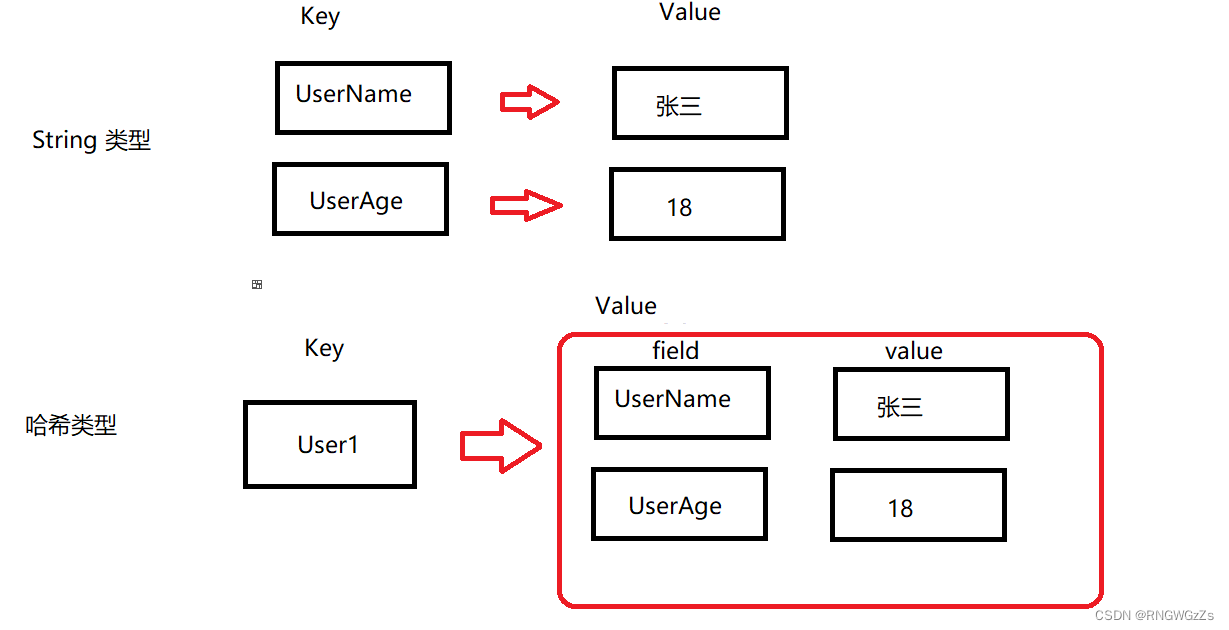
Hash类型
⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数
组、映射。在Redis中,哈希类型是指值(value)本⾝⼜是⼀个键值对结构。
字符串 vs 哈希结构:
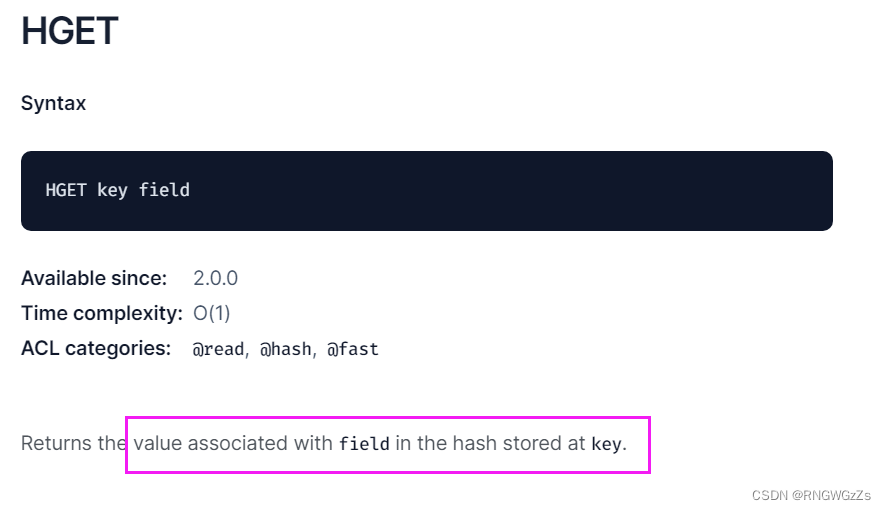
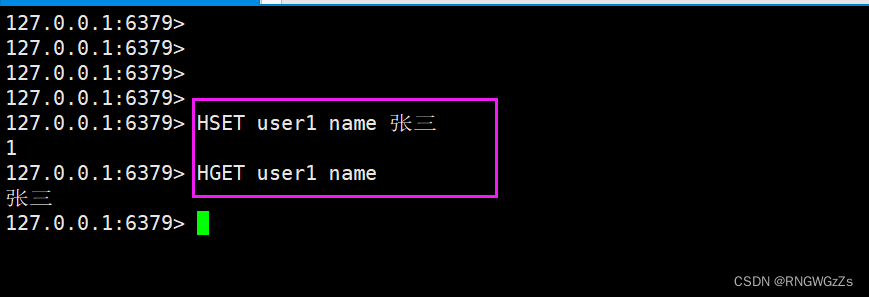
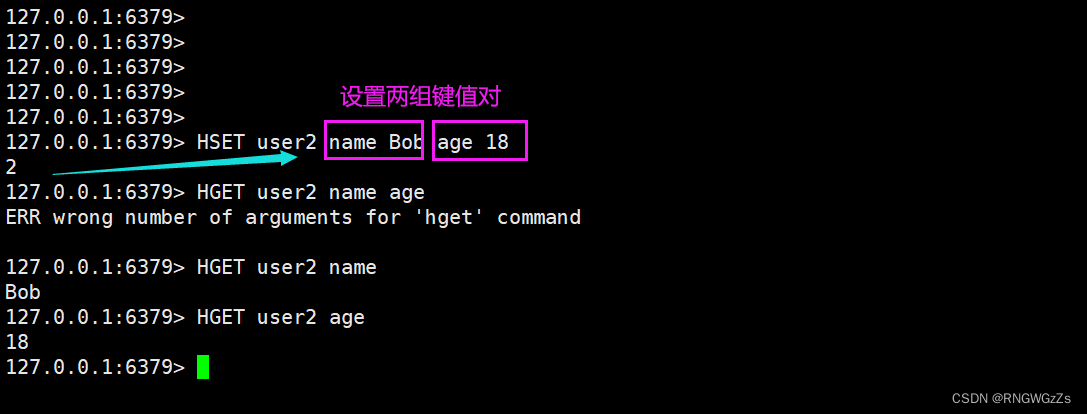
(1) HSET\HGET

设置hash中指定的字段(field)的值(value)。
 获取hash中指定字段的值。
获取hash中指定字段的值。
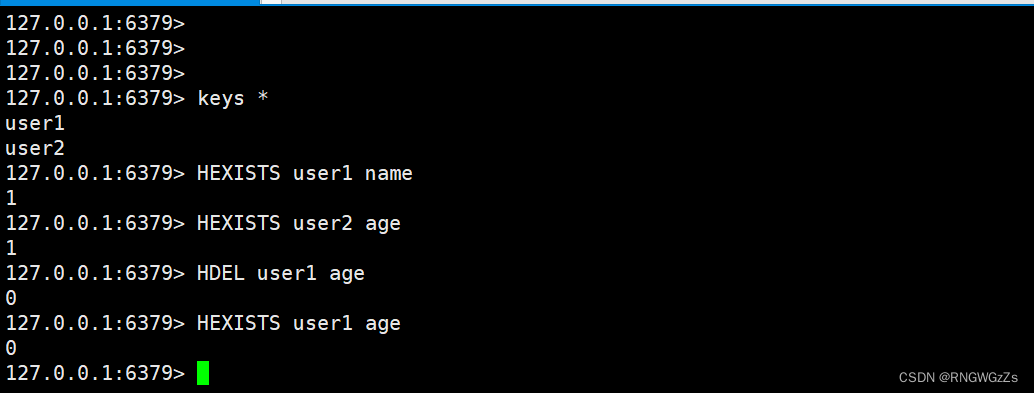
(2) HDEL\HEXISTS
删除hash类型中指定的字段。 判断hash中是否有指定的字段。
判断hash中是否有指定的字段。
(3) HKEYS\HVALS
 获取指定key中hash的所有字段。这个先根据key,找到对应的hash(O(1)),然后再遍历整个hash。
获取指定key中hash的所有字段。这个先根据key,找到对应的hash(O(1)),然后再遍历整个hash。
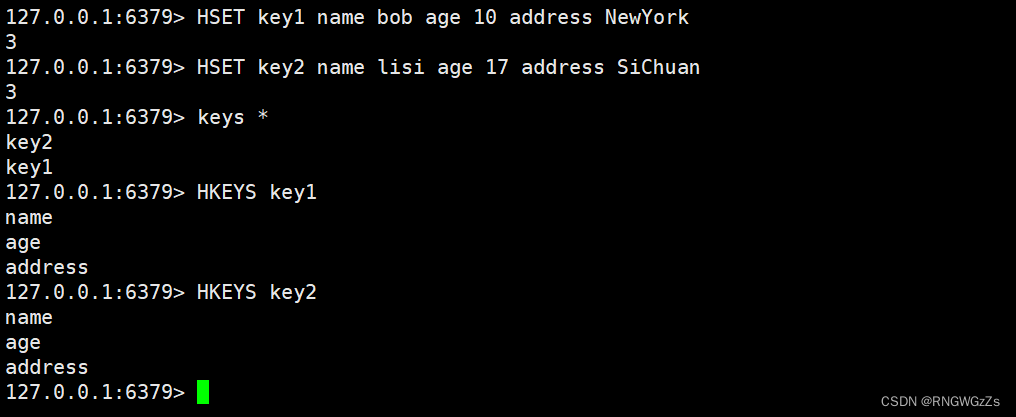

获取hash中的所有的值。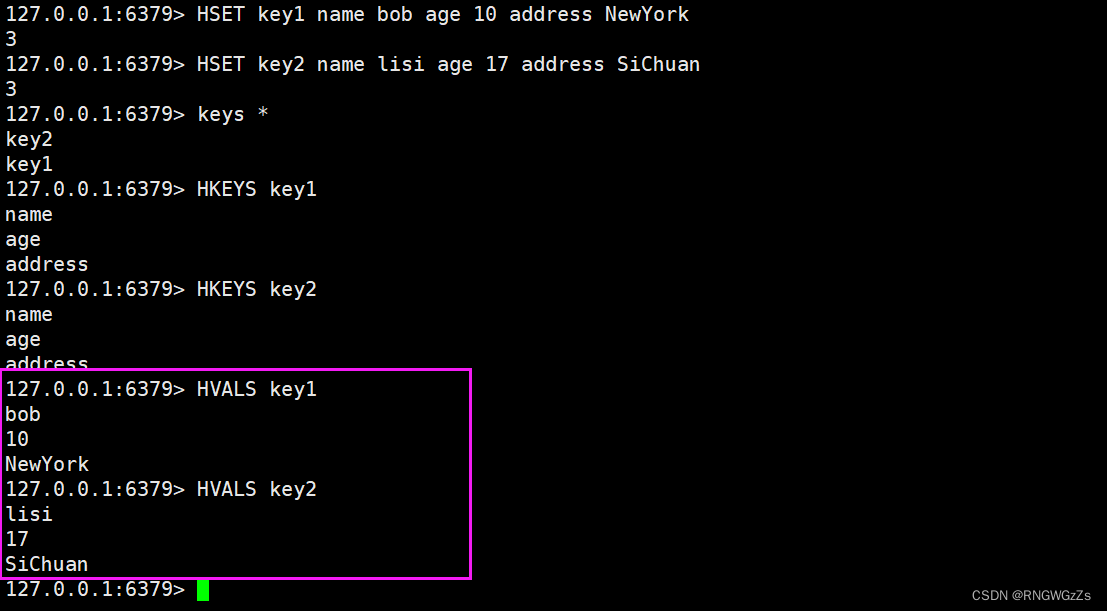 这个两个操作同 “keys * " 大同小异,实际中在我们不知道field和value的情况下,不用为上策。
这个两个操作同 “keys * " 大同小异,实际中在我们不知道field和value的情况下,不用为上策。
(4) HGETALL\HMGET
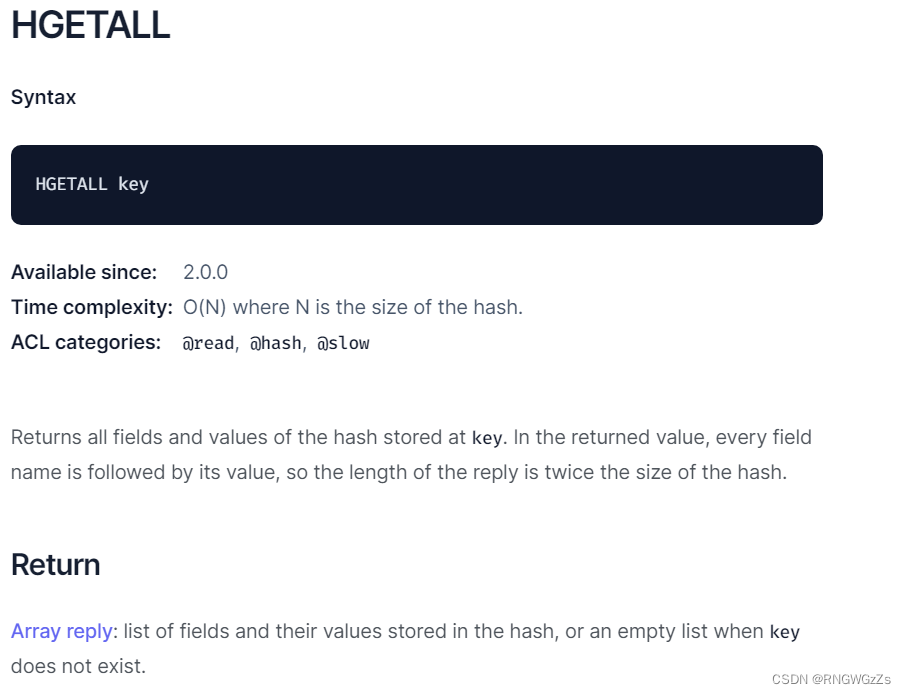
获取hash中的所有字段以及对应的值。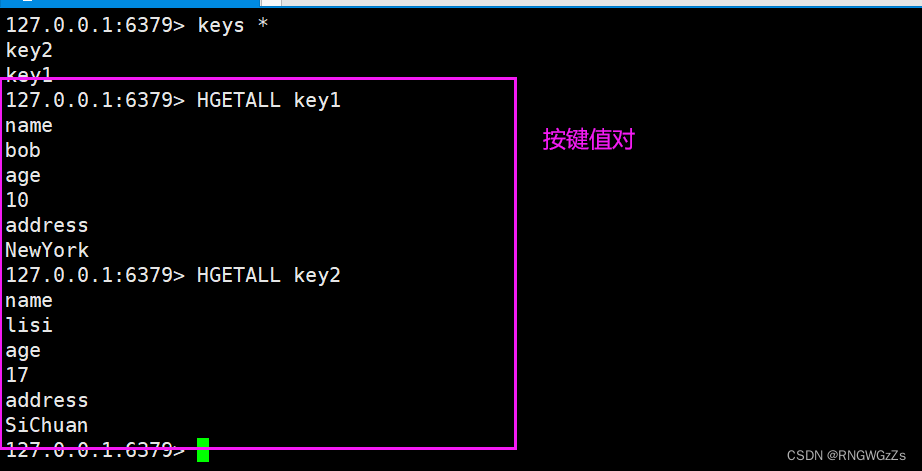

⼀次获取hash中多个字段的值。
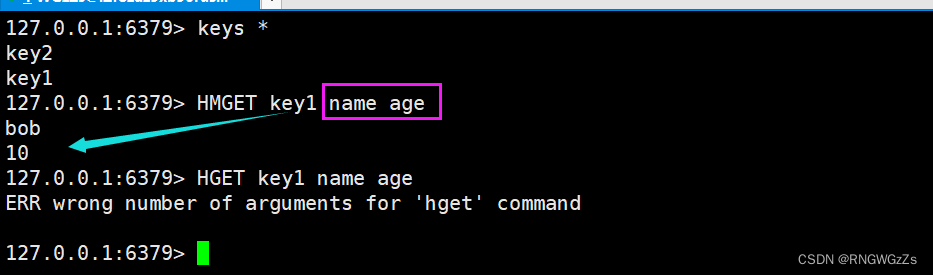
因为HSET已经可以设置多个field 、value 所以虽然有HMSET但是可以被替代了。
(5) HLEN

获取hash中的所有字段的个数。
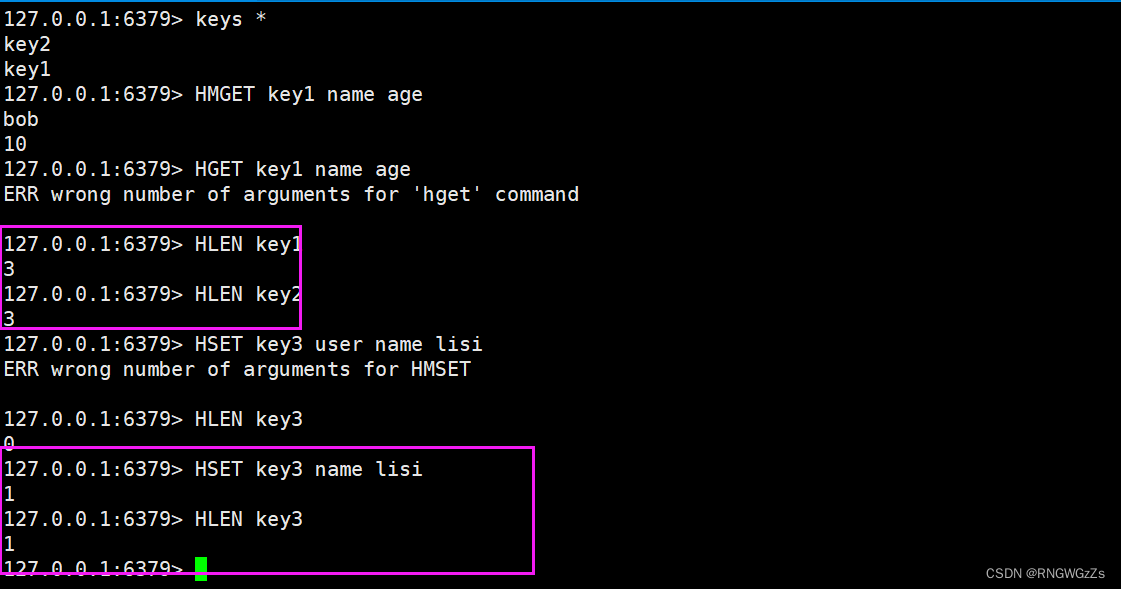
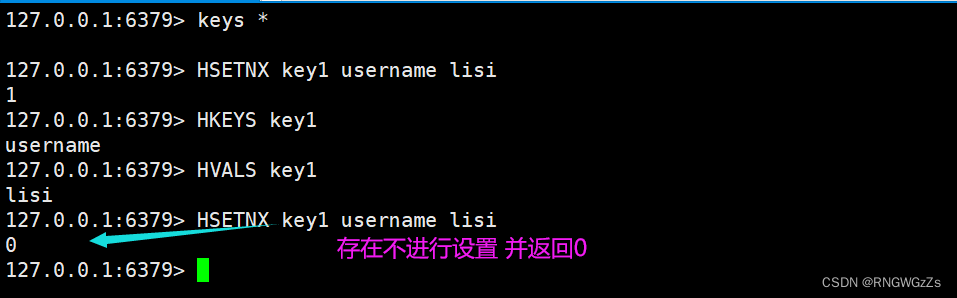
(6) HSETNX\HINCRBYFLOAT\HINCRBY

在字段不存在的情况下,设置hash中的字段和值。
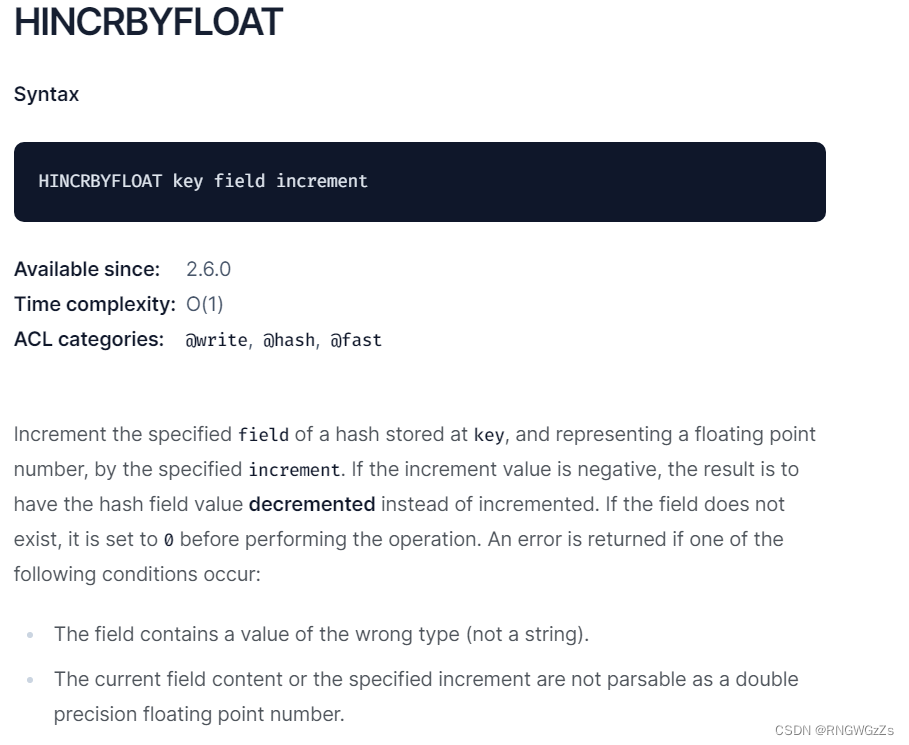
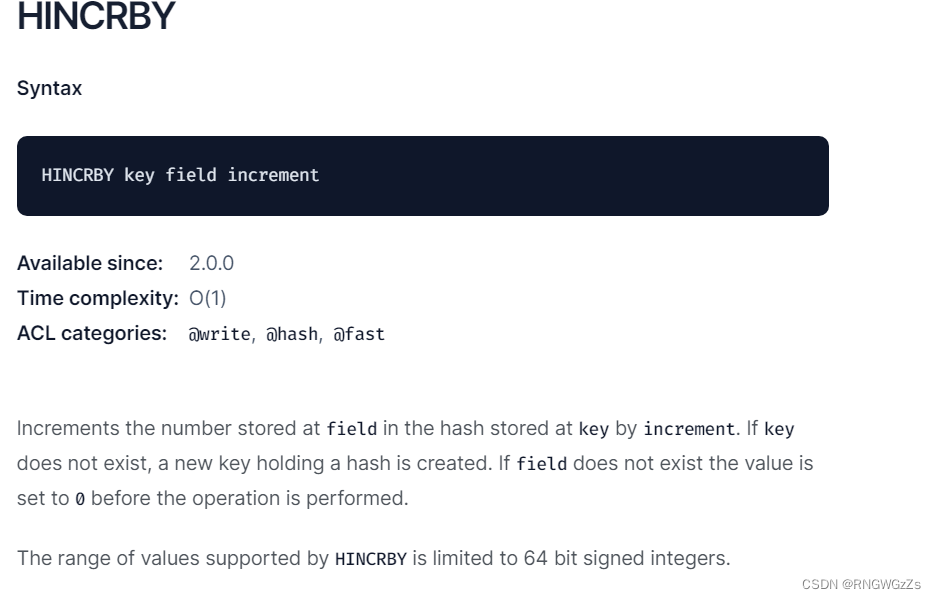
HINCRBY的浮点数版本,将hash中字段对应的数值添加指定的值。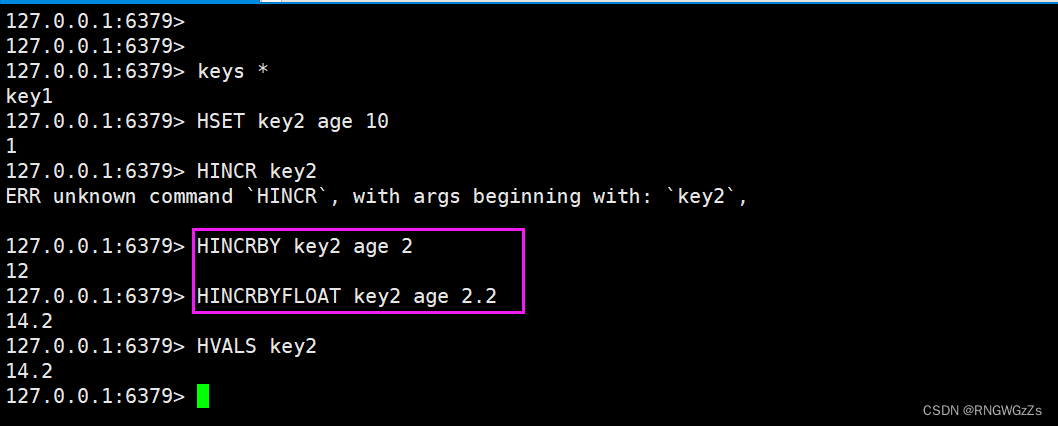
Hash命令小结:
| 命令 | 执行效果 | 时间复杂度 |
| hset key field value | 设置值 | O(1) |
| hget key field | 获取值 | O(1) |
| hdel key field [field...] | 删除field | O(n),n是field的个数 |
| hlen key | 计算field个数 | O(1) |
| hgetall key | 获取所有的field-value | O(n),n是field的个数 |
| hmget field[field...] | 批量获取value | O(n),n是field的个数 |
| hmset field value [field value....] | 批量设置值 | O(n),n是field的个数 |
| hexists key field | 判断field是否存在 | O(1) |
| hkeys\vals key | 获取所有的key\value | O(n),n是field的个数 |
| hsetnx key field value | filed不存在才成功 | O(1) |
| hincrby key field n | 对应的value+n | O(1) |
| hincrbyfloat key field n | 浮点数版本 | O(1) |
| hstrlen key field | 计算value的字符串长度 | O(1) |
Hash内部编码:
哈希的内部编码有两种:
• ziplist(压缩列表)当哈希类型元素个数⼩于hash-max-ziplist-entries配置(默认512个)、
同时所有值都⼩于hash-max-ziplist-value配置(默认64字节)时,Redis会使⽤ziplist作为哈
希的内部实现,ziplist使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存⽅⾯⽐
hashtable更加优秀。
• hashtable(哈希表)当哈希类型⽆法满⾜ziplist的条件时,Redis会使⽤hashtable作为哈希
的内部实现,因为此时ziplist的读写效率会下降,⽽hashtable的读写时间复杂度为O(1)。
如何理解压缩? 
ziplist也是同理,因为一个普通的哈希表,如果存储少量的值,存在一定的空间浪费,这显然对redis这类极其看重空间的组件来说是不能容忍的。但,ziplist付出的代价是,进行读写元素时速度还是很慢,这种效果随着插入的元素增多而愈发明显。
Hash应用场景:
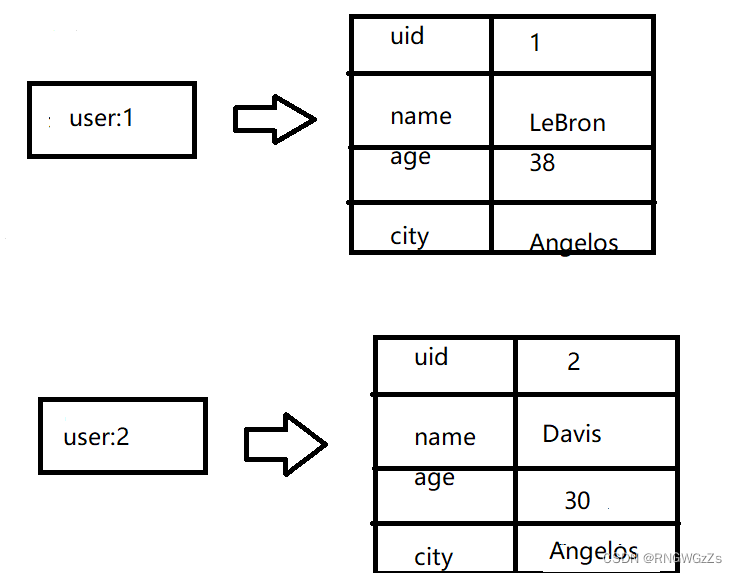
① 关系型表数据转换
| uid | name | age | city |
| 1 | LeBron James | 38 | LosAngels |
| 2 | Anthony Davis | 30 | LosAngels |
映射关系表⽰⽤⼾信息:
但是需要注意的是哈希类型和关系型数据库有两点不同之处:
| uid | name | age | city | gender | favor |
| 1 | James | 38 | LosAngel | <null> | sports |
| 2 | Davis | 30 | LosAngel | <null> | sports |
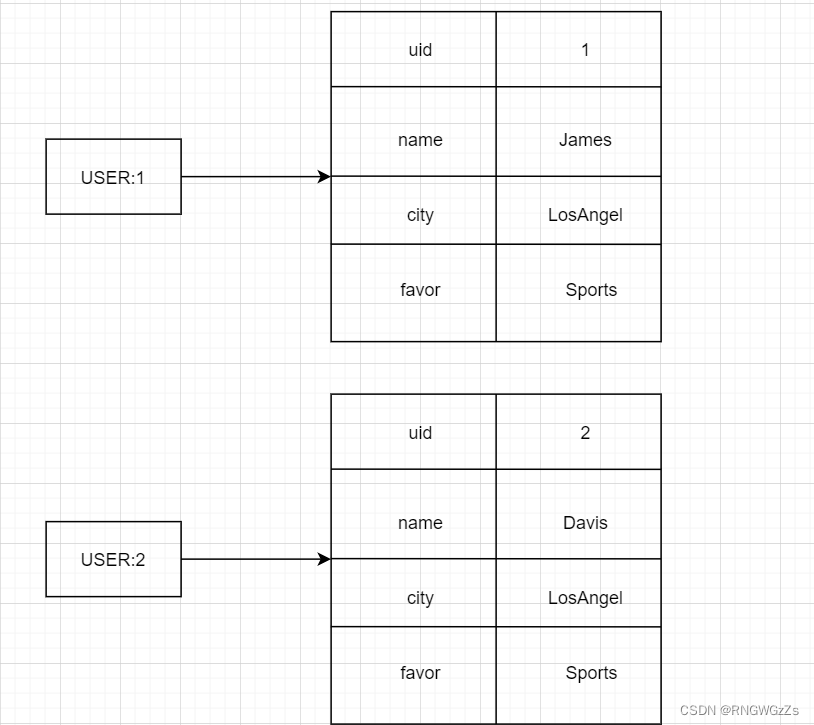 ● 哈希类型是稀疏的,⽽关系型数据库是完全结构化的.
● 哈希类型是稀疏的,⽽关系型数据库是完全结构化的.
● 关系数据库可以做复杂的关系查询,⽽Redis去模拟关系型复杂查询.
② 缓存⽅式对⽐
● 原⽣字符串类型⸺使⽤字符串类型,每个属性⼀个键
# 这里的field中的value 是字符串
set user:1:name James
set user:1:age 38
set user:1:city LosAngel优点:实现简单,针对个别属性变更也很灵活。
缺点:占⽤过多的键,内存占⽤量较⼤,同时⽤⼾信息在Redis中⽐较分散,缺少内聚性,所以这种⽅案基本没有实⽤性。
● 序列化字符串类型,例如JSON格式
set user:1 经过序列化后的⽤⼾对象字符串优点:针对总是以整体作为操作的信息⽐较合适,编程也简单。同时,如果序列化⽅案选择合适,内存的使⽤效率很⾼。
缺点:本⾝序列化和反序列需要⼀定开销,同时如果总是操作个别属性则⾮常不灵活。
当我们需要修改Json中的某些值时,需要将Json中保存的所有值先反序列化成字符串,操作field,再重写完成后序列化成Json,再写回去。
● 哈希类型
hmset user:1 name James age 38 city LosAngel优点:简单、直观、灵活。尤其是针对信息的局部变更或者获取操作。
缺点:需要控制哈希在ziplist和hashtable两种内部编码的转换,可能会造成内存的较⼤消耗。
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~