目录
一、目标1:使用函数分割
二、目标2:使用函数模块
三、目标3:使用正则匹配
一、目标1:使用函数分割
目标:x.x.x.x[中国北京 xx云]
方法:split函数+replace函数
1、分割:使用split()方法将其按照"["进行分割,得到一个列表split_ip
2、元素:列表的第一个元素就是IP地址部分,第二个元素是包含位置信息的字符串。
3、获取目标:通过索引split_ip[0]获取IP地址部分,将其赋值给变量ip。通过split_ip[1]获取位置信息部分4、使用replace()方法去掉末尾的"]",将得到的结果赋值给变量location
ip_address = "x.x.x.x[中国北京 xx云]"
split_ip = ip_address.split("[")
ip = split_ip[0]
location = split_ip[1].replace("]", "")
print("IP: ", ip)
print("Location: ", location)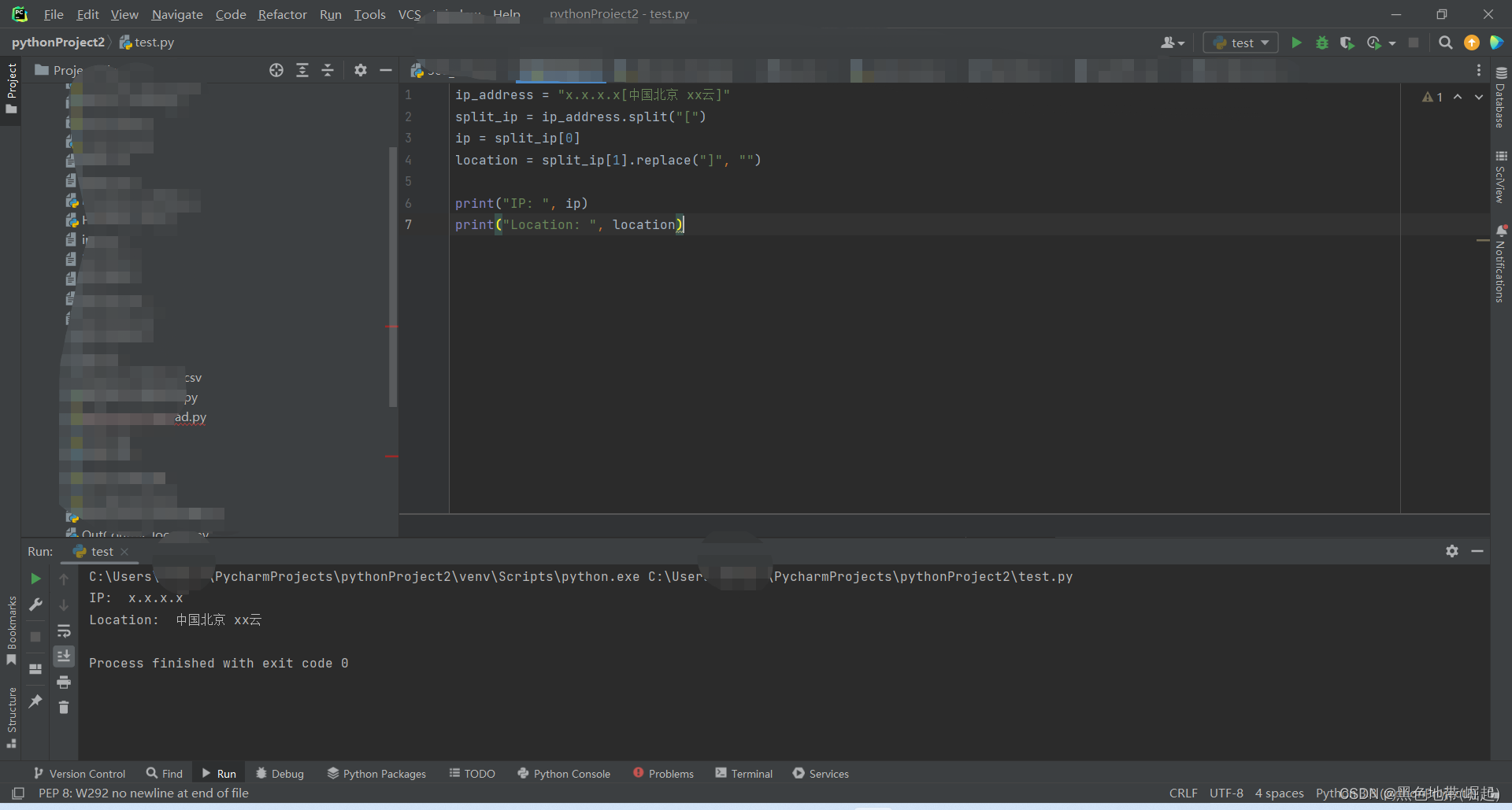
二、目标2:使用函数模块
urlparse函数(urllib模块):可以解析URL并将其拆分为各个组成部分。然后将要截取域名的URL赋值给url变量
from urllib.parse import urlparse
url = "https://www.example.com/path/page.html"
parsed_url = urlparse(url)
domain = parsed_url.netloc
print(domain) # 输出:"www.example.com"
三、目标3:使用正则匹配
正则匹配根据具体情况具体分析
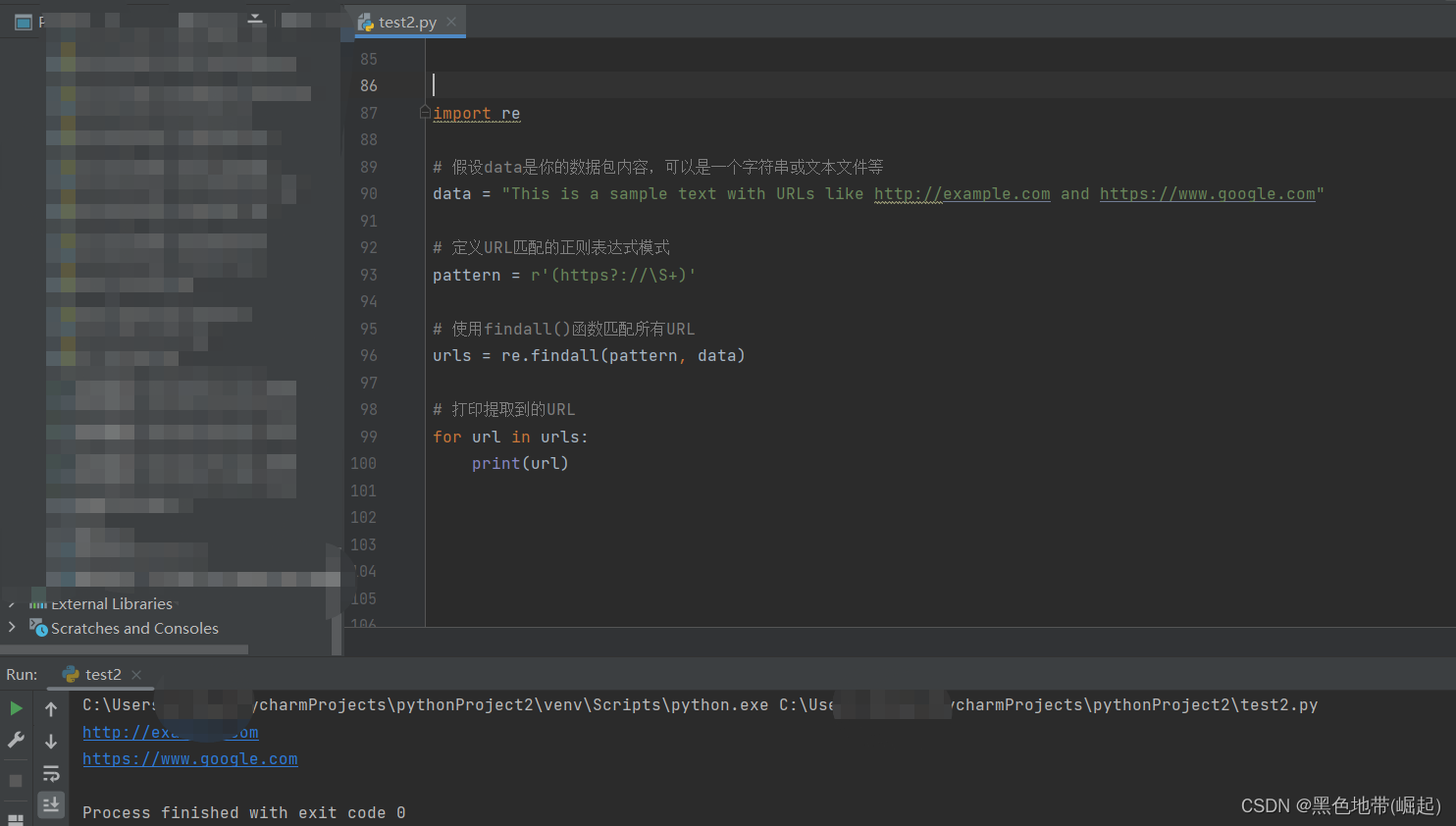
import re
# 假设data是你的数据包内容,可以是一个字符串或文本文件等
data = "This is a sample text with URLs like http://example.com and https://www.google.com"
# 定义URL匹配的正则表达式模式
pattern = r'(https?://\S+)'
# 使用findall()函数匹配所有URL
urls = re.findall(pattern, data)
# 打印提取到的URL
for url in urls:
print(url)