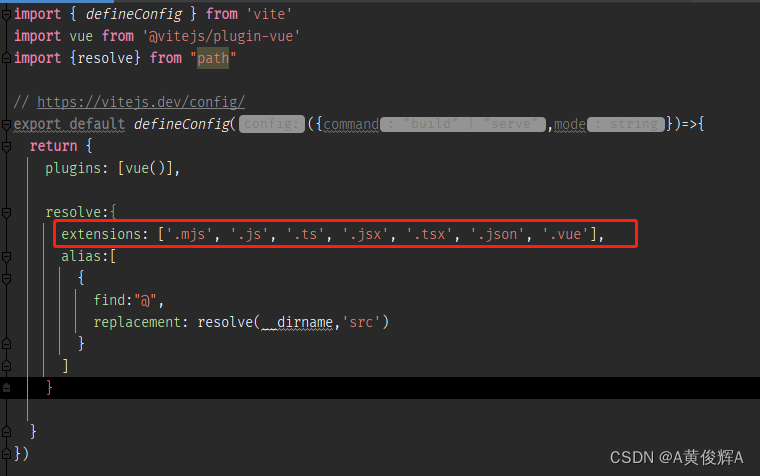
逻辑覆盖测试法是常用的一类白盒测试方法,其以程序内部逻辑结构为基础,通过对程序逻辑结构的遍历来实现程序测试的覆盖。逻辑覆盖测试法要求测试人员对程序的逻辑结构有清晰的了解。
逻辑覆盖测试法是一系列测试过程的总称,是使测试过程逐渐进行越来越完整的通路测试。从覆盖源程序语句的详尽程度,可以将其分为语句覆盖、判定覆盖、条件覆盖、判断/条件覆盖、条件组合覆盖和路径覆盖等。接下来将通过下面程序的逻辑覆盖测试用例一一介绍这些覆盖准则,该程序的流程图如图1所示,其中,a、b、c、d、e是控制流上的若干程序点。
main()
{
int a,b;
float x;
scanf("%d,%d,%f",&a, &b, &x);
if((a>1)and(b = 0))
x = x/a;
if((a = 2)or(x>1))
x= x+1
prinf("x=%f",x);
} 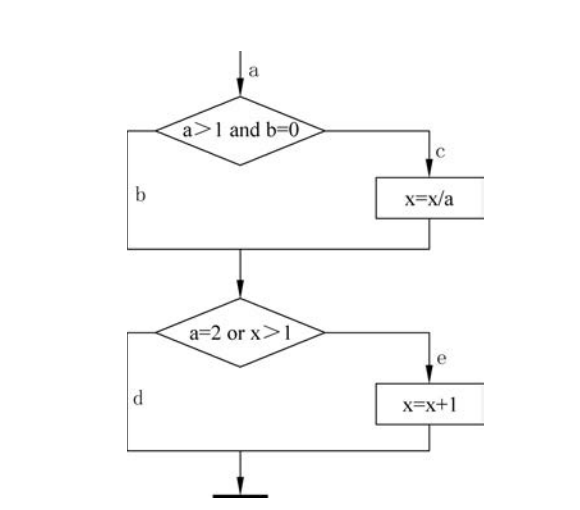
■ 图1 程序流程图
01、逻辑覆盖测试的综合案例
通过一个案例将相关测试方法进行一次综合应用,即设计以下程序的逻辑覆盖测试用例。
void DoWork(int x,int y,int z)
{
int k=0,j=0;
if((x > 3)&&(z < 10))
{
k = x*y-1;
j = sqrt(k);
}//语句块1
if((x == 4)||(y> 5))
{
j= x*y+10;};
}//语句块 2
j= j%3;//语句块 3
}图2给出了该例子的流程图,其中a、b、c、d和e是控制流上的若干程序点。
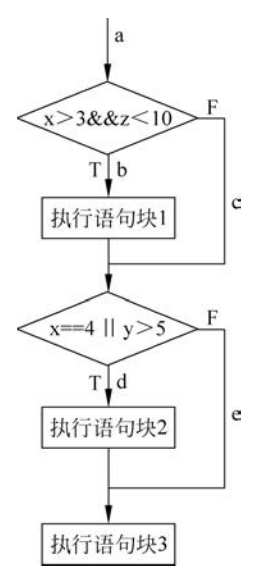
■ 图2 程序流程图
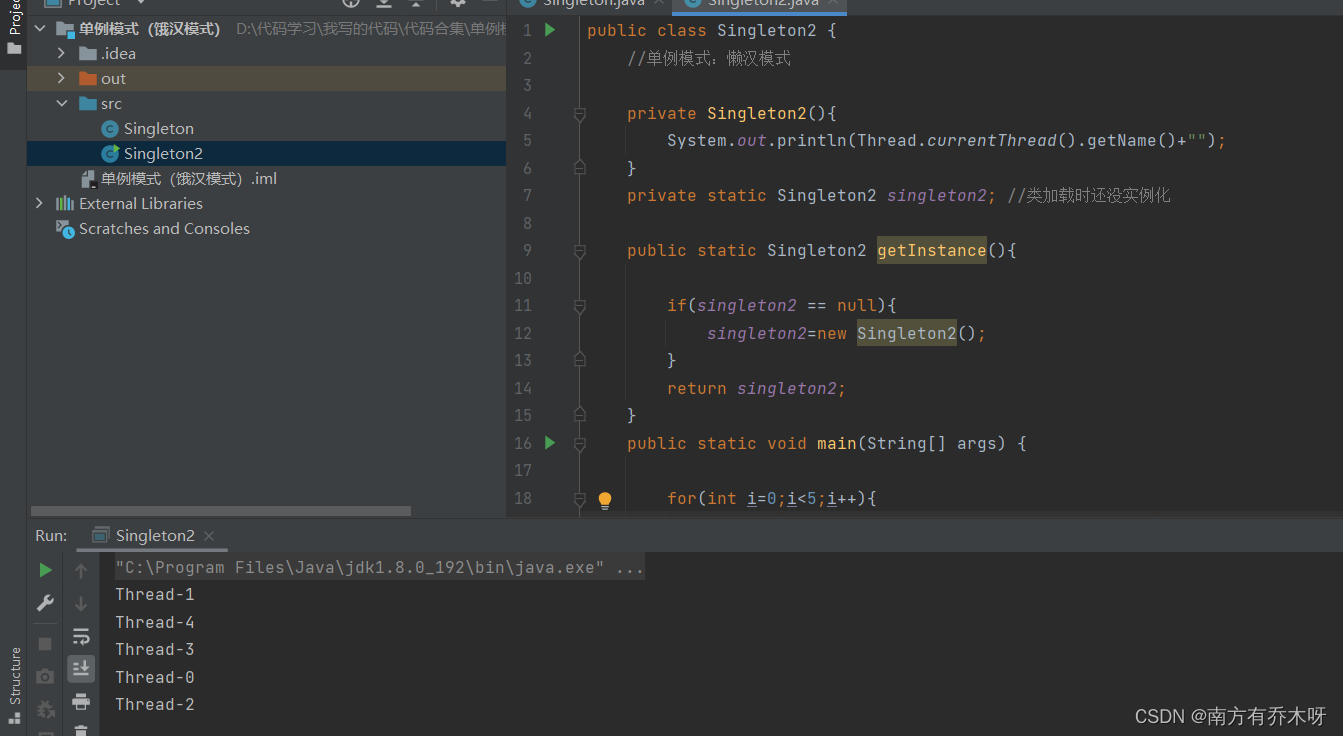
1. 语句覆盖
要测试DoWork函数,只需设计一个测试用例就可以覆盖程序中所有可执行语句,程序执行的路径是abd,具体测试用例输入如下。
{x=4 y=5 z=5}
分析:语句覆盖可以保证程序中的每个语句都得到执行,但发现不了判定中逻辑运算的错误,即它不是一种充分的检验方法。例如,在第一个判定(x>3)&&(z<10)中把“&&”错误地写成“||”,这时仍使用该测试用例,则程序仍会按照流程图上的路径abd执行,这再次说明语句覆盖是最弱的逻辑覆盖准则。
2. 判定覆盖
要实现DoWork函数的判定覆盖,需要设计两个测试用例,其程序执行的路径分别是abd和ace,对应测试用例的输入为:
{x=4 y=5 z=5};{x=2 y=5 z=5}
分析:上述两个测试用例不仅满足了判定覆盖,同时还做到了语句覆盖。从这点看似乎判定覆盖比语句覆盖更强一些,但其仍然无法确定判定内部条件的错误。例如,把第二个判定中的条件y>5错误写为y<5,然后使用上述测试用例,照样能按原路径执行而不影响结果。因此,需要更强的逻辑覆盖准则去检验判定内的条件。
3. 条件覆盖
一个判定中通常都包含若干条件。条件覆盖的目的是设计若干测试用例,在执行被测程序后,使每个判定中每个条件的可能值至少满足一次。
对DoWork函数各个判定的各种条件取值加以标记。
(1) 对于第一个判定(x>3&&z<10):
条件x>3取真值记为t1,取假值记为-t1;
条件z<10取真值记为t2,取假值记为-t2。
(2) 对于第二个判定(x==4||y>5):
条件x==4取真值记为t3,取假值记为-t3;
条件y>5取真值记为t4,取假值记为-t4。
根据条件覆盖的基本思想,要使上述4个条件可能产生的8种情况至少满足一次,其设计测试用例如表1所示。
■ 表1 条件覆盖测试用例

分析: 表4-6中这组测试用例不但覆盖了4个条件的全部8种情况,而且将两个判定的4个分支b、c、d、e也同时覆盖了,即同时达到了条件覆盖和判定覆盖。
虽然前面的一组测试用例同时达到了条件覆盖和判定覆盖,但是,并不是说满足条件覆盖就一定能满足判定覆盖。如果设计了如表2中的这组测试用例,则其虽然满足了条件覆盖,但也只是覆盖了程序中第一个判定的取假分支c和第二个判定的取真分支d,不能满足判定覆盖的要求。
■ 表2 另一组条件覆盖测试用例

4. 判定/条件覆盖
根据判定/条件覆盖的基本思想,只需设计如表3中的两个测试用例便可以覆盖4个条件的8种取值以及4个判定分支。
■ 表3 判定/条件覆盖测试用例

分析: 从表面上看,判定/条件覆盖了各个判定中的所有条件的取值,但实际上,编译器在检查含有多个条件的逻辑表达式时,某些情况下的某些条件将会被其他条件掩盖。例如,对第一判定(x>3)&&(z<10)来说,必须x>3和z<10这两个条件同时满足才能确定该判定为真。如果x>3为假,则编译器将不再会去检查z<10这个条件,那么即使这个条件有错也无法被发现。对第二个判定(x==4)||(y>5)来说,若条件x==4满足,编译器就会认为该判定为真,这时将不会再去检查y>5,那么同样也无法发现这个条件中的错误。因此,判定/条件覆盖也不一定能够完全检查出逻辑表达式中的错误。
5. 条件组合覆盖
对DoWork函数中的各个判定的条件取值组合加以标记。
(1) x>3,z<10记为t1,t2,即第一个判定的取真分支。
(2) x>3,z≥10记为t1,-t2,即第一个判定的取假分支。
(3) x≤3,z<10记为-t1,t2,即第一个判定的取假分支。
(4) x≤3,z≥10记为-t1,-t2,即第一个判定的取假分支。
(5) x==4,y>5记为t3,t4,即第二个判定的取真分支。
(6) x==4,y≤5记为t3,-t4,即第二个判定的取真分支。
(7) x≠4,y>5记为-t3,t4,即第二个判定的取真分支。
(8) x≠4,y<=5记为-t3,-t4,即第二个判定的取假分支。
根据组合覆盖的基本思想,以上可得设计测试用例如表4所示。
■ 表4 条件组合覆盖测试用例

分析:表4中这组测试用例覆盖了所有8种条件取值的组合,也覆盖了所有判定的真假分支,但丢失了一条路径abe。
6. 路径覆盖
根据路径覆盖的基本思想,在满足组合覆盖测的测试用例中修改第三个测试用例,则可以实现路径覆盖,如表5所示。
■ 表5 路径覆盖测试用例

分析: 虽然前面一组测试用例满足了路径覆盖,但并没有覆盖程序中所有的条件组合(丢失了组合3和7),即满足路径覆盖的测试用例并不一定满足条件组合覆盖。
02.文末赠书
一、前言
目前,资讯、社交、游戏、消费、出行等丰富多彩的互联网应用已经渗透到了人们生活和工作的方方面面,正深刻改变着信息时代。随着用户规模的增长和应用复杂度的上升,服务端面临的技术挑战越来越严峻。在头部互联网企业,服务端开发岗位的职责早已不再局限于简单地围绕数据库编排“增删改查”服务,而要求工程师具备业务分析、架构设计、代码编写、技术攻关、团队协作、系统维护等综合能力。很多时候,服务端的第一行代码尚未写就,工程师便不得不与产品、运营、法务等人员和网络、中间件、操作系统、数据、算法、运维、安全等技术体系打交道。
二、AI 时代,服务端开发面临新挑战
2022 年 11 月 30 日,OpenAI 发布了一款名为 ChatGPT 的聊天机器人程序,旋即引爆网络,在全球范围内引起巨大反响。紧随其后,各种大语言模型如雨后春笋不断出现。国外如 Google 的 Bard、Anthropic 的 Claude,国内如百度文心一言、阿里通义千问、讯飞星火认知大模型、昆仑万维天工大模型等。
相较于之前的模型,以 ChatGPT 为代表的大模型在代码生成、代码解释能力方面有了质的飞跃。一些有条件的人已经开始借助 AI 来编写、优化代码和辅助解决问题。AI 技术极大地缩短了掌握知识的路径,一些原本需要读很多书、看很多专栏才能搞懂的知识点,借助 AI 工具举例可以快速地掌握。一些看似并不复杂的代码,如果你自己去写可能要写半小时, AI 则可能只需一两分钟就能产出,而且质量往往更高。有了 AI 的加持,一些编程经验并不丰富的初级工程师,也可以 “写出” 相对优秀的代码。
时至今日,我们应清醒地认识到,AI 时代必将对人类社会的生产、生活带来深刻的变革。虽然目前大模型还存在很多缺点,如幻觉、推理能力弱等,但其潜力不可小觑。AI 时代,简单、重复的任务被 AI 取代是不可避免的。在不久的将来,AI 完全有望取代一些低水平(比如仅会 CRUD)的程序员 。鉴于此,新的时代,我们需要重新审视核心竞争力的内涵, 持续学习,不断夯实自身的能力护城河。

三、服务端开发会被 AI 取代吗?
大型软件系统,本身往往具有较高的复杂度。我们可以简单地将复杂度分为两个维度:业务与技术。高业务复杂度的系统,必须进行科学、有效的需求分析与领域建模,方可在满足当前功能性需求的同时获得可持续演进的应用架构;高技术复杂度的分布式系统,则需要充分考虑诸如高并发、高可用、高性能、数据一致性等非功能性问题,才能在设计权衡中寻求技术架构最优解。很幸运,目前 AI 尚无法应对上述两种复杂度。
此外,大模型虽然具备生成代码、解释代码甚至优化代码的能力,但是还多停留在 “函数/方法” 维度,不能很好地生成类维度、模块维度、项目维度的代码。同时,生成的代码仍然需要人工审阅、优化、部署、验证。对于复杂的任务,还需要人工拆解为大模型能够 “理解” 的粒度。
再者,即便不考虑数据安全、自研模型成本等因素,单就服务端研发流程来看,编码只是整个软件生命周期的一环 ,软件开发还包括需求分析、抽象建模、系统设计、数据设计、非功能性设计、测试、运维等环节。很多时候,编写代码作为解决问题的最终技术手段,并不困难,而困难在于对问题的识别、理解、定义和抽象,这些都依赖人工反复推演。当一个问题被明确并拆解到软件项目维度的时候,面对确定的任务、清晰的目标、合理的架构,可以解决问题的人就非常多了,AI 自然也才有用武之地。
四、知识体系化,构建核心竞争力
对于服务端开发岗位而言,掌握一门主流的编程语言、熟悉常用的中间件和数据库是基础而重要的,但是还远远谈不上核心竞争力。只有当知识形成体系时,才可以称之为真正的核心竞争力。
那么,服务端开发的知识体系包含哪些内容呢?从服务端开发的流程来看,涵盖需求分析、抽象建模、系统设计、数据设计和非功能性设计等环节,我们需要掌握相关技术和方法。从互联网行业服务端开发的难点来看,针对高并发、高可用、高性能、缓存、幂等、数据一致性等问题,我们需要掌握相应地解决方案。
知识体系如此庞大,如何高效地学习呢?想象一下,为什么你对家所在的小区周边特别了解,随便把你放在一个角落,你都能慢慢摸索出来?究其原因,是因为你脑海中已经形成了小区周边的整体大图,并对关键节点了然于胸。如果把你放到陌生的小区,你可能就懵了,关键节点、整体大图都没有,胡乱摸索,即便你把摸索路上所见到的每一个下水道井盖的情况都搞清楚了,也没什么意义,过几条街你就忘了。
回到上面抛出的问题,高效学习、知识体系化的关键在于:构建宏观层面的整体大图,并深入理解关键知识点。这些关键点就是这个领域的骨架、支点。缺少骨架和支点自然难以体系化,缺了宏观大图则容易误入歧途。
五、业界首本体系化、全景式解读服务端开发的著作

《服务端开发:技术、方法与实用解决方案》一书取材自阿里和蚂蚁集团的精品内训课程,由资深服务端技术专家、技术讲师、阿里第二届技术讲师课程大赛年度冠军得主、CSDN 博客专家撰写。该书理论与实践结合,全景式、体系化地阐述了服务端开发,核心内容包括以下两个部分。
-
第一部分:服务端开发的技术和方法
首先介绍服务端开发的职责、技术栈、核心流程和进阶路径;然后从需求分析、抽象建模、系统设计、数据设计和非功能性设计 5 个方面展开,结合案例深入讲解了服务端开发的实操方法和重难点,为读者呈现服务端开发的全景图,帮助读者快速、体系化地掌握服务端开发的知识和方法。
-
第二部分:服务端典型问题的解决方案
针对高并发、高性能、高可用、缓存、数据一致性、幂等、秒杀等服务端开发实践中的典型问题,给出了对应的解决方案和开发规范,同时还结合案例深入分析了不同方案的优缺点。此外,还总结了接口设计、日志打印、异常处理、代码编写、代码注释等落地层面的行业案例和规范。
读者对象
-
IT 从业人员:服务端开发工程师、客户端开发工程师、产品经理、测试开发工程师等。
-
高校学生:计算机、软件、自动化、电气、通信等专业有志于进入 IT 行业的在校学生。