- https://github.com/ggerganov/whisper.cpp/tree/1.0.3
GGML Tensor Library
-
官方有一个函数使用说明,但是从初始版本就没修改过 : https://github1s.com/ggerganov/ggml/blob/master/include/ggml/ggml.h#L3-L173
-
This documentation is still a work in progress. If you wish some specific topics to be covered, feel free to drop a comment:
https://github.com/ggerganov/whisper.cpp/issues/40
Overview
此库实现:
- 张量运算
- 自动微分
- 基本优化算法
这个库的目的是为各种机器学习任务提供一种最小化方法(a minimalistic approach for various machine learning tasks)。包括但不限于以下内容:
- 线性回归
- 支持向量机
- 神经网络
该库允许用户使用可用的张量运算来定义某个函数。该函数定义通过计算图在内部表示。函数定义中的每个张量运算都对应于图中的一个节点。定义了计算图后,用户可以选择计算函数的值和/或其相对于输入变量的梯度。更近一步,可以使用可用的优化算法之一来优化函数。
例如,在这里我们定义函数: f(x) = a*x^2 + b
{
struct ggml_init_params params = {
.mem_size = 16*1024*1024,
.mem_buffer = NULL,
};
// memory allocation happens here
struct ggml_context * ctx = ggml_init(params);
struct ggml_tensor * x = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);
ggml_set_param(ctx, x); // x is an input variable
struct ggml_tensor * a = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);
struct ggml_tensor * b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);
struct ggml_tensor * x2 = ggml_mul(ctx, x, x);
struct ggml_tensor * f = ggml_add(ctx, ggml_mul(ctx, a, x2), b);
...
}
请注意,上面的函数定义不涉及任何实际计算。只有当用户明确请求时才执行计算。例如,要计算x=2.0时的函数值:
{
...
struct ggml_cgraph gf = ggml_build_forward(f);
// set the input variable and parameter values
ggml_set_f32(x, 2.0f);
ggml_set_f32(a, 3.0f);
ggml_set_f32(b, 4.0f);
ggml_graph_compute_with_ctx(ctx, &gf, n_threads);
printf("f = %f\n", ggml_get_f32_1d(f, 0));
...
}
实际计算是在ggml_graph_compute()函数中执行的。
-
The ggml_new_tensor_…() functions create new tensors. They are allocated in the memory buffer provided to the ggml_init() function. You have to be careful not to exceed the memory buffer size. Therefore, you have to know in advance how much memory you need for your computation. Alternatively, you can allocate a large enough memory and after defining the computation graph, call the ggml_used_mem() function to find out how much memory was actually needed.
-
The ggml_set_param() function marks a tensor as an input variable. This is used by the automatic differentiation and optimization algorithms.
-
所描述的方法允许定义函数图一次,然后多次计算其正向或反向图。所有计算都将使用在ggml_init()函数中分配的相同内存缓冲区。通过这种方式,用户可以避免运行时的内存分配开销。
-
该库支持多维张量-最多4个维度。FP16和FP32数据类型是一类公民(The FP16 and FP32 data types are first class citizens),但理论上,该库可以扩展为支持FP8和整数数据类型。
-
每个张量运算(tensor operation)产生一个新的张量。最初,该库被设想为只支持使用一元和二元运算。大多数可用的操作属于这两类中的一类。随着时间的推移,很明显,库需要支持更复杂的操作。支持这些行动的方法尚不清楚,但以下行动中展示了几个例子:
- ggml_permute()
- ggml_conv_1d_1s()
- ggml_conv_1d_2s()
-
For each tensor operator, the library implements a forward and backward computation function. The forward function computes the output tensor value given the input tensor values. The backward function computes the adjoint of the input tensors given the adjoint of the output tensor. For a detailed explanation of what this means, take a calculus class, or watch the following video:
What is Automatic Differentiation?
https://www.youtube.com/watch?v=wG_nF1awSSY
Tensor data (struct ggml_tensor)
张量通过ggml_tensor结构存储在内存中。该结构提供关于张量的大小、数据类型以及存储张量数据的存储器缓冲区的信息。此外,它还包含指向“源”张量的指针,即用于计算当前张量的张量。例如:
{
struct ggml_tensor * c = ggml_add(ctx, a, b);
assert(c->src[0] == a);
assert(c->src[1] == b);
}
多维张量按行主顺序存储。ggml_tensor结构包含每个维度中元素数(“ne”)和字节数(“nb”,又称步幅)的字段。这允许在存储器中存储不连续的张量,这对于诸如换位和置换之类的操作是有用的。所有张量运算都必须考虑步长,而不是假设张量在内存中是连续的。

- nb[i] 表示在第i纬度移动的步幅
The data of the tensor is accessed via the “data” pointer. For example:
{
const int nx = 2;
const int ny = 3;
struct ggml_tensor * a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, nx, ny);
for (int y = 0; y < ny; y++) {
for (int x = 0; x < nx; x++) {
*(float *) ((char *) a->data + y*a->nb[1] + x*a->nb[0]) = x + y;
}
}
...
}
或者,也可以使用一些辅助函数,例如ggml_get_f32_1d() , ggml_set_f32_1d() .
TODO
The matrix multiplication operator (ggml_mul_mat)
TODO
Multi-threading
TODO
Overview of ggml.c
TODO
SIMD optimizations
TODO
Debugging ggml
TODO
example 最小执行demo
76
├── CMakeLists.txt https://github1s.com/ggerganov/whisper.cpp/blob/1.0.3/CMakeLists.txt
├── ggml.c https://github1s.com/ggerganov/whisper.cpp/blob/1.0.3/ggml.c
├── ggml.h https://github1s.com/ggerganov/whisper.cpp/blob/1.0.3/ggml.h
└── main.cpp
CMakeLists.txt
cmake_minimum_required (VERSION 3.0)
project(76 VERSION 1.0.3)
set(CMAKE_EXPORT_COMPILE_COMMANDS "on")
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin)
set(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib")
if(CMAKE_SOURCE_DIR STREQUAL CMAKE_CURRENT_SOURCE_DIR)
set(WHISPER_STANDALONE ON)
# include(cmake/GitVars.cmake)
# include(cmake/BuildTypes.cmake)
# # configure project version
# if (EXISTS "${CMAKE_SOURCE_DIR}/bindings/ios/Makefile-tmpl")
# configure_file(${CMAKE_SOURCE_DIR}/bindings/ios/Makefile-tmpl ${CMAKE_SOURCE_DIR}/bindings/ios/Makefile @ONLY)
# endif()
# configure_file(${CMAKE_SOURCE_DIR}/bindings/javascript/package-tmpl.json ${CMAKE_SOURCE_DIR}/bindings/javascript/package.json @ONLY)
else()
set(WHISPER_STANDALONE OFF)
endif()
if (EMSCRIPTEN)
set(BUILD_SHARED_LIBS_DEFAULT OFF)
option(WHISPER_WASM_SINGLE_FILE "whisper: embed WASM inside the generated whisper.js" ON)
else()
if (MINGW)
set(BUILD_SHARED_LIBS_DEFAULT OFF)
else()
set(BUILD_SHARED_LIBS_DEFAULT ON)
endif()
endif()
# options
option(BUILD_SHARED_LIBS "whisper: build shared libs" ${BUILD_SHARED_LIBS_DEFAULT})
option(WHISPER_ALL_WARNINGS "whisper: enable all compiler warnings" ON)
option(WHISPER_ALL_WARNINGS_3RD_PARTY "whisper: enable all compiler warnings in 3rd party libs" OFF)
option(WHISPER_SANITIZE_THREAD "whisper: enable thread sanitizer" OFF)
option(WHISPER_SANITIZE_ADDRESS "whisper: enable address sanitizer" OFF)
option(WHISPER_SANITIZE_UNDEFINED "whisper: enable undefined sanitizer" OFF)
option(WHISPER_BUILD_TESTS "whisper: build tests" ${WHISPER_STANDALONE})
option(WHISPER_BUILD_EXAMPLES "whisper: build examples" ${WHISPER_STANDALONE})
option(WHISPER_SUPPORT_SDL2 "whisper: support for libSDL2" OFF)
if (APPLE)
option(WHISPER_NO_ACCELERATE "whisper: disable Accelerate framework" OFF)
option(WHISPER_NO_AVX "whisper: disable AVX" OFF)
option(WHISPER_NO_AVX2 "whisper: disable AVX2" OFF)
else()
option(WHISPER_SUPPORT_OPENBLAS "whisper: support for OpenBLAS" OFF)
endif()
option(WHISPER_PERF "whisper: enable perf timings" OFF)
# sanitizers
if (NOT MSVC)
if (WHISPER_SANITIZE_THREAD)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=thread")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=thread")
endif()
if (WHISPER_SANITIZE_ADDRESS)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=address -fno-omit-frame-pointer")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address -fno-omit-frame-pointer")
endif()
if (WHISPER_SANITIZE_UNDEFINED)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=undefined")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=undefined")
endif()
endif()
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -ffast-math")
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -march=native")
# dependencies
set(CMAKE_C_STANDARD 11)
set(CMAKE_CXX_STANDARD 11)
find_package(Threads REQUIRED)
# on APPLE - include Accelerate framework
if (APPLE AND NOT WHISPER_NO_ACCELERATE)
find_library(ACCELERATE_FRAMEWORK Accelerate)
if (ACCELERATE_FRAMEWORK)
message(STATUS "Accelerate framework found")
set(WHISPER_EXTRA_LIBS ${WHISPER_EXTRA_LIBS} ${ACCELERATE_FRAMEWORK})
set(WHISPER_EXTRA_FLAGS ${WHISPER_EXTRA_FLAGS} -DGGML_USE_ACCELERATE)
else()
message(WARNING "Accelerate framework not found")
endif()
endif()
if (WHISPER_SUPPORT_OPENBLAS)
find_library(OPENBLAS_LIB
NAMES openblas libopenblas
)
if (OPENBLAS_LIB)
message(STATUS "OpenBLAS found")
set(WHISPER_EXTRA_LIBS ${WHISPER_EXTRA_LIBS} ${OPENBLAS_LIB})
set(WHISPER_EXTRA_FLAGS ${WHISPER_EXTRA_FLAGS} -DGGML_USE_OPENBLAS)
else()
message(WARNING "OpenBLAS not found")
endif()
endif()
# compiler flags
if (NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES)
set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE)
set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "RelWithDebInfo")
endif ()
if (WHISPER_ALL_WARNINGS)
if (NOT MSVC)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} \
-Wall \
-Wextra \
-Wpedantic \
-Wshadow \
-Wcast-qual \
-Wstrict-prototypes \
-Wpointer-arith \
")
else()
# todo : msvc
endif()
endif()
if (NOT MSVC)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Werror=vla")
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fno-math-errno -ffinite-math-only -funsafe-math-optimizations")
endif()
message(STATUS "CMAKE_SYSTEM_PROCESSOR: ${CMAKE_SYSTEM_PROCESSOR}")
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm" OR ${CMAKE_SYSTEM_PROCESSOR} MATCHES "aarch64")
message(STATUS "ARM detected")
else()
message(STATUS "x86 detected")
if (MSVC)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /arch:AVX2")
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /arch:AVX2")
else()
if (EMSCRIPTEN)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -pthread")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -pthread")
else()
if(NOT WHISPER_NO_AVX)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx")
endif()
if(NOT WHISPER_NO_AVX2)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx2")
endif()
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mfma -mf16c")
endif()
endif()
endif()
if (WHISPER_PERF)
set(WHISPER_EXTRA_FLAGS ${WHISPER_EXTRA_FLAGS} -DGGML_PERF)
endif()
#
# whisper - this is the main library of the project
#
set(TARGET 76)
add_library(GGML ggml.c )
add_executable(76 main.cpp)
target_link_libraries(${TARGET} GGML)
Forward && Backward
#include "ggml.h"
#include <stdio.h>
#include <stdlib.h>
int main(int argc, const char ** argv) {
const int n_threads = 2;
struct ggml_init_params params = {
.mem_size = 128*1024*1024,
.mem_buffer = NULL,
// .no_alloc = false,
};
struct ggml_context * ctx0 = ggml_init(params);
{
struct ggml_tensor * x = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
ggml_set_param(ctx0, x);
struct ggml_tensor * a = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
struct ggml_tensor * b = ggml_mul(ctx0, x, x);
struct ggml_tensor * f = ggml_mul(ctx0, b, a);
// a*x^2
// 2*a*x
ggml_print_objects(ctx0);
struct ggml_cgraph gf = ggml_build_forward(f);
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
ggml_set_f32(x, 2.0f);
ggml_set_f32(a, 3.0f);
// FORWARD
ggml_graph_compute(ctx0, &gf);
printf("f = %f\n", ggml_get_f32_1d(f, 0));
// FORWARD + BACKWARD
ggml_graph_reset(&gf);
ggml_set_f32(f->grad, 1.0f);
ggml_graph_compute(ctx0, &gb);
printf("f = %f\n", ggml_get_f32_1d(f, 0));
printf("df/dx = %f\n", ggml_get_f32_1d(x->grad, 0));
// SAVE GRAPH
ggml_graph_dump_dot(&gf, NULL, "test1-1-forward.dot");
ggml_graph_dump_dot(&gb, &gf, "test1-1-backward.dot");
}
return 0;
}
OUTPUT
ggml_print_objects: objects in context 0x560856e9d2a8:
- ggml_object: offset = 32, size = 176, next = 0x7f888aa7f0e0
- ggml_object: offset = 240, size = 176, next = 0x7f888aa7f1b0
- ggml_object: offset = 448, size = 176, next = 0x7f888aa7f280
- ggml_object: offset = 656, size = 176, next = 0x7f888aa7f350
- ggml_object: offset = 864, size = 176, next = 0x7f888aa7f420
- ggml_object: offset = 1072, size = 176, next = 0x7f888aa7f4f0
- ggml_object: offset = 1280, size = 176, next = (nil)
ggml_print_objects: --- end ---
f = 12.000000
f = 12.000000
df/dx = 12.000000
f = 27.000000
df/dx = 18.000000
ggml_graph_dump_dot: dot -Tpng test1-1-forward.dot -o test1-1-forward.dot.png && open test1-1-forward.dot.png
ggml_graph_dump_dot: dot -Tpng test1-1-backward.dot -o test1-1-backward.dot.png && open test1-1-backward.dot.png
Process finished with exit code 0
Vector Example
#include "ggml.h"
#include <stdio.h>
#include <cstring>
int main(int argc, const char ** argv) {
const int n_threads = 2;
struct ggml_init_params params = {
.mem_size = 128*1024*1024,
.mem_buffer = NULL,
};
struct ggml_context * ctx0 = ggml_init(params);
{
struct ggml_tensor * x = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 5);
ggml_set_param(ctx0, x);
struct ggml_tensor * a = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 5);
struct ggml_tensor * b = ggml_mul(ctx0, x, x);
struct ggml_tensor * f = ggml_mul(ctx0, b, a);
// a*x^2
ggml_print_objects(ctx0);
struct ggml_cgraph gf = ggml_build_forward(f);
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
std::vector<float> digit={1,2,3,4,5};
memcpy(x->data, digit.data(), ggml_nbytes(x));
// ggml_set_f32(x, 2.0f);
ggml_set_f32(a, 3.0f);
// FORWARD
ggml_graph_compute(ctx0, &gf);
printf("f = %f\n", ggml_get_f32_1d(f, 0));
printf("f = %f\n", ggml_get_f32_1d(f, 1));
printf("f = %f\n", ggml_get_f32_1d(f, 2));
printf("f = %f\n", ggml_get_f32_1d(f, 3));
printf("f = %f\n", ggml_get_f32_1d(f, 4));
}
return 0;
}
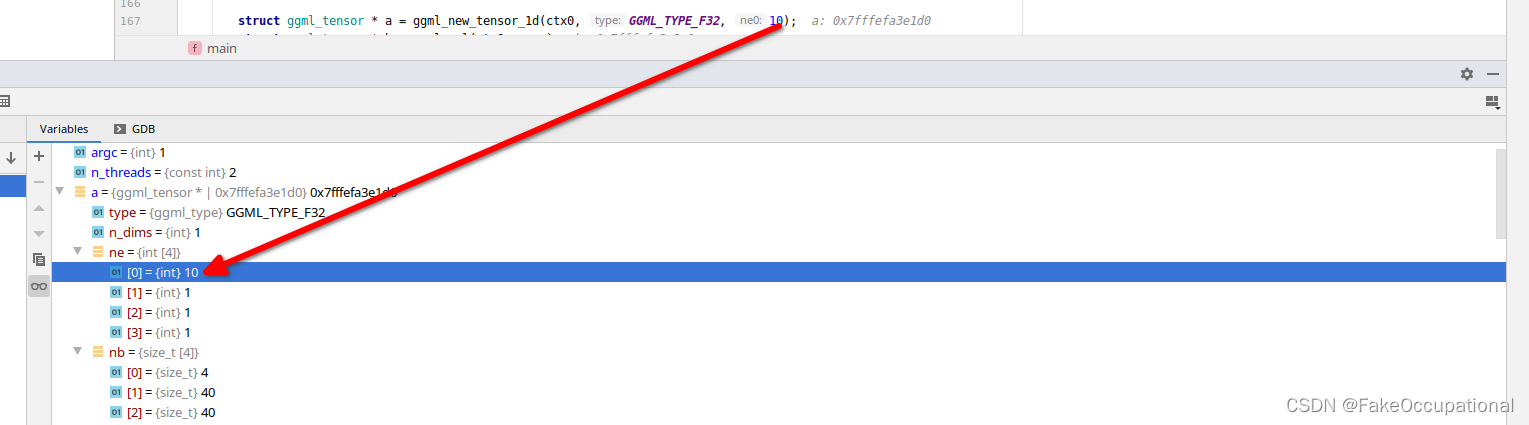
Compute Graph
构建计算图的语句 struct ggml_cgraph gf = ggml_build_forward(f);
计算图的定义及地址
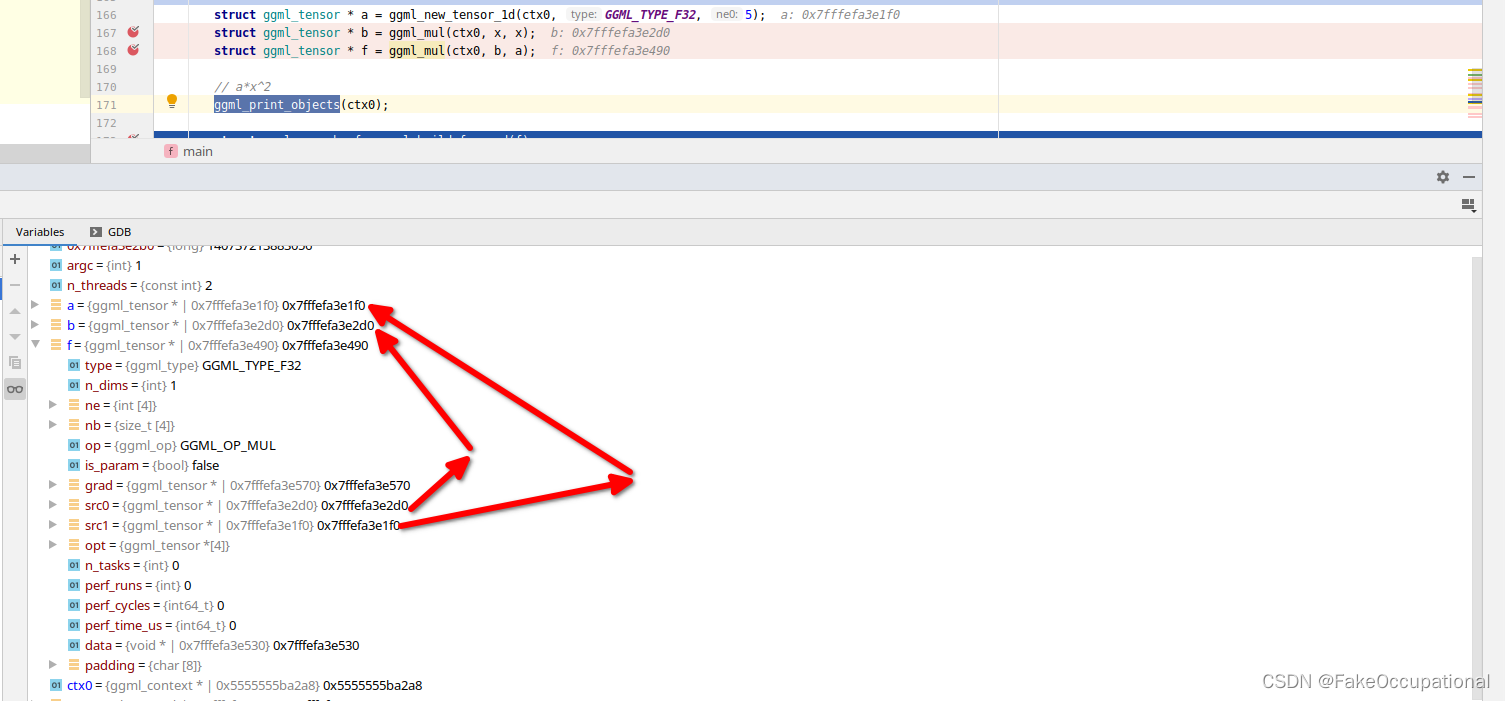
构建过程 ggml_build_forward
struct ggml_cgraph ggml_build_forward(struct ggml_tensor * tensor) {
struct ggml_cgraph result = {
/*.n_nodes =*/ 0,
/*.n_leafs =*/ 0,
/*.n_threads =*/ 0,
/*.work_size =*/ 0,
/*.work =*/ NULL,
/*.nodes =*/ { NULL },
/*.grads =*/ { NULL },
/*.leafs =*/ { NULL },
/*.perf_runs =*/ 0,
/*.perf_cycles =*/ 0,
/*.perf_time_us =*/ 0,
};
ggml_build_forward_impl(&result, tensor, false);
return result;
}
void ggml_build_forward_impl(struct ggml_cgraph * cgraph, struct ggml_tensor * tensor, bool expand) {
if (!expand) {
cgraph->n_nodes = 0;
cgraph->n_leafs = 0;
}
const int n0 = cgraph->n_nodes;
UNUSED(n0);
ggml_visit_parents(cgraph, tensor);// 函数会递归地遍历节点的src0、src1和opt数组中的节点,并将它们添加到计算图中。这样可以确保所有的父节点都会被添加到计算图中。最后,函数会根据节点的op和grad属性来判断节点的类型。如果op为GGML_OP_NONE且grad为NULL,则说明该节点是一个叶子节点,不是梯度图的一部分(例如常量节点)。此时,函数会将该节点添加到计算图的leafs数组中。否则,函数会将该节点添加到计算图的nodes数组中,并将其grad属性添加到计算图的grads数组中。
const int n_new = cgraph->n_nodes - n0;
GGML_PRINT_DEBUG("%s: visited %d new nodes\n", __func__, n_new);
if (n_new > 0) {
// the last added node should always be starting point
assert(cgraph->nodes[cgraph->n_nodes - 1] == tensor);
}
}
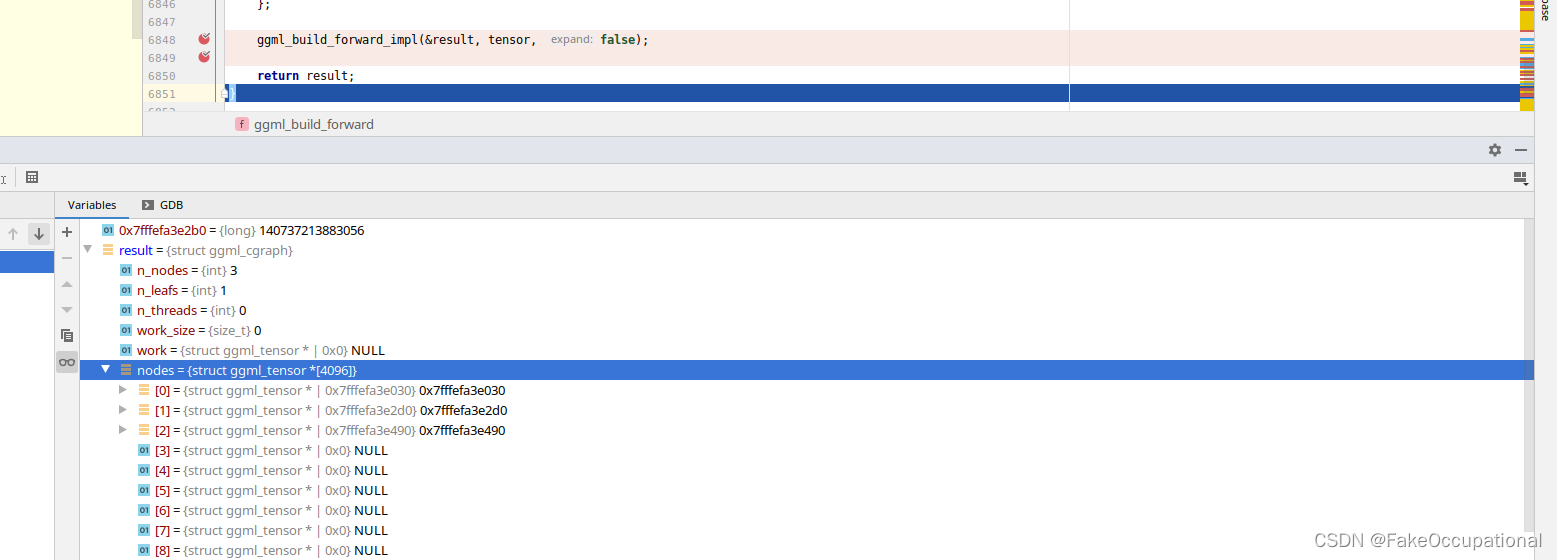
计算过程 ggml_graph_compute
void ggml_graph_compute(struct ggml_context * ctx, struct ggml_cgraph * cgraph) {
if (cgraph->n_threads <= 0) {
cgraph->n_threads = 8;
}
const int n_threads = cgraph->n_threads;
struct ggml_compute_state_shared state_shared = {
/*.spin =*/ GGML_LOCK_INITIALIZER,
/*.n_threads =*/ n_threads,
/*.n_ready =*/ 0,
/*.has_work =*/ false,
/*.stop =*/ false,
};
struct ggml_compute_state * workers = n_threads > 1 ? alloca(sizeof(struct ggml_compute_state)*(n_threads - 1)) : NULL;
create thread pool
在程序启动时创建一定数量的线程,然后将待处理的任务分配给这些线程进行执行。线程池能够在任务到达时立即执行,节省了线程创建和销毁的开销。
// create thread pool
if (n_threads > 1) {
ggml_lock_init(&state_shared.spin);
atomic_store(&state_shared.has_work, true); // 将true存储到state_shared.has_work位置,并确保该操作是原子的
//创建了n_threads-1个线程
for (int j = 0; j < n_threads - 1; j++) {
workers[j] = (struct ggml_compute_state) {
.thrd = 0,
.params = {
.type = GGML_TASK_COMPUTE,
.ith = j + 1,
.nth = n_threads,
.wsize = cgraph->work ? ggml_nbytes(cgraph->work) : 0,
.wdata = cgraph->work ? cgraph->work->data : NULL,
},
.node = NULL,
.shared = &state_shared,
};
int rc = pthread_create(&workers[j].thrd, NULL, ggml_graph_compute_thread, &workers[j]);// 创建一个线程。
// ggml_graph_compute_thread是一个函数指针,指向要在新创建的线程中执行的函数。
assert(rc == 0);
UNUSED(rc);// 使用`UNUSED(rc)`来消除编译器的未使用变量警告。
}
}
initialize tasks + work buffer
这段代码的作用是初始化任务和工作缓冲区。它首先遍历计算图中的每个节点,并根据节点的操作类型分配任务数量。然后根据节点类型确定工作缓冲区的大小,并分配相应大小的内存空间。
具体地,对于每个节点,根据其操作类型,分配相应数量的任务。例如,对于GGML_OP_NONE,GGML_OP_MUL操作,分配1个任务;对于GGML_OP_ADD操作,分配n_threads个任务(与线程数相同)。
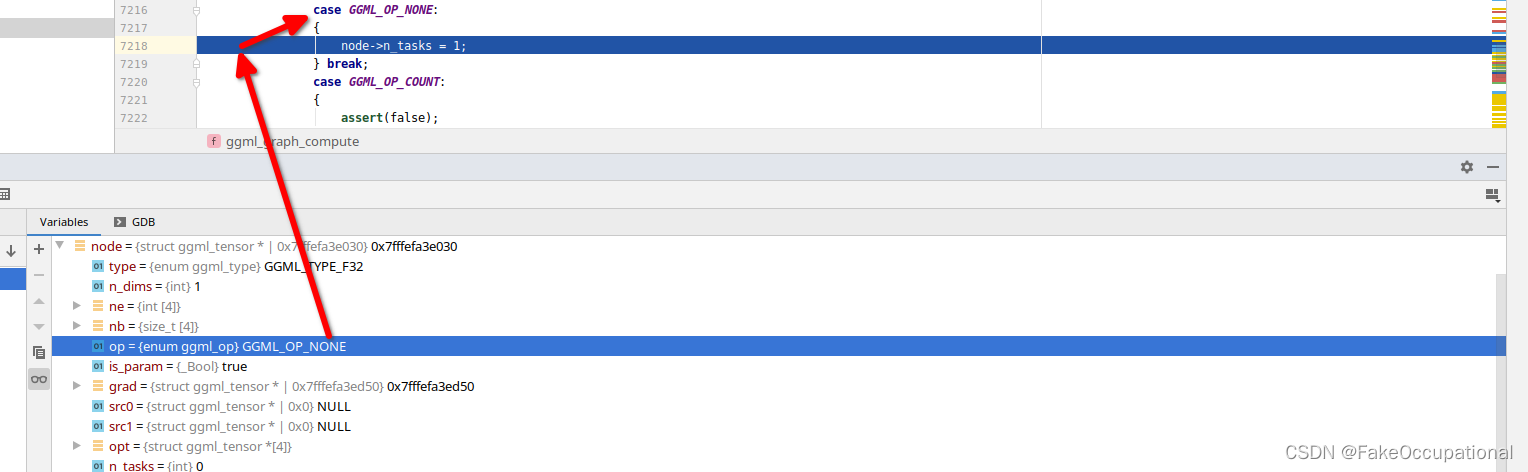
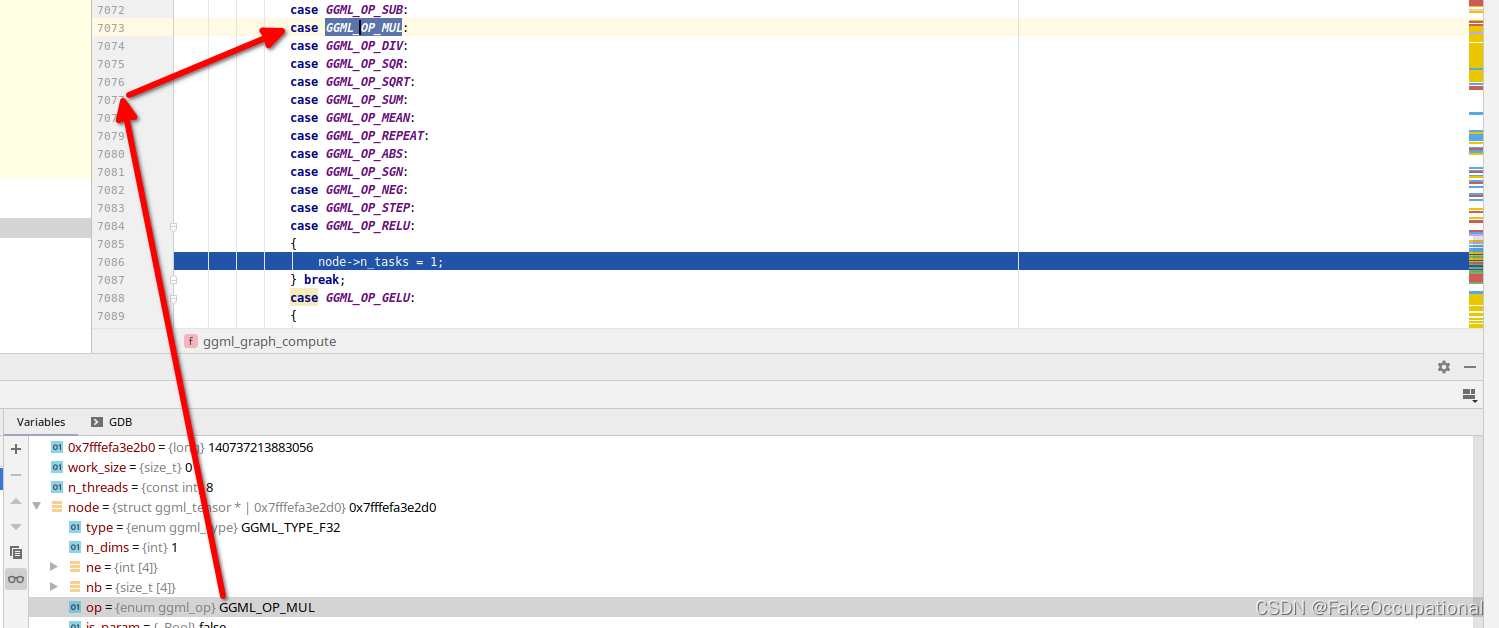
在分配任务数量时,还会计算工作缓冲区的大小。例如,对于GGML_OP_MUL_MAT操作,根据矩阵的大小和是否转置等因素确定任务数量,并更新工作缓冲区的大小。最后,根据工作缓冲区的大小,如果需要分配内存空间并且当前未分配,则分配相应大小的内存空间。
但是本例的node->n_tasks > 1都为false,直接运行ggml_compute_forward即可。
// initialize tasks + work buffer
{
size_t work_size = 0;
// thread scheduling for the different operations
for (int i = 0; i < cgraph->n_nodes; i++) {
struct ggml_tensor * node = cgraph->nodes[i];
switch (node->op) {
case GGML_OP_DUP:
{
node->n_tasks = 1;
} break;
case GGML_OP_ADD:
{
node->n_tasks = n_threads;
} break;
case GGML_OP_SUB:
case GGML_OP_MUL:
case GGML_OP_DIV:
case GGML_OP_SQR:
case GGML_OP_SQRT:
case GGML_OP_SUM:
case GGML_OP_MEAN:
case GGML_OP_REPEAT:
case GGML_OP_ABS:
case GGML_OP_SGN:
case GGML_OP_NEG:
case GGML_OP_STEP:
case GGML_OP_RELU:
{
node->n_tasks = 1;
} break;
case GGML_OP_GELU:
{
node->n_tasks = n_threads;
} break;
case GGML_OP_NORM:
{
node->n_tasks = n_threads;
} break;
case GGML_OP_MUL_MAT:
{
// TODO: use different scheduling for different matrix sizes
node->n_tasks = n_threads;
size_t cur = 0;
// TODO: better way to determine if the matrix is transposed
if (node->src0->nb[1] < node->src0->nb[0]) {
cur = ggml_nbytes(node)*node->n_tasks; // TODO: this can become (n_tasks-1)
} else {
if (node->src0->type == GGML_TYPE_F16 &&
node->src1->type == GGML_TYPE_F32) {
#if defined(GGML_USE_ACCELERATE) || defined(GGML_USE_OPENBLAS)
if (ggml_compute_forward_mul_mat_use_blas(node->src0, node->src1, node)) {
cur = sizeof(float)*(node->src0->ne[0]*node->src0->ne[1]);
} else {
cur = sizeof(ggml_fp16_t)*ggml_nelements(node->src1);
}
#else
cur = sizeof(ggml_fp16_t)*ggml_nelements(node->src1);
#endif
} else if (node->src0->type == GGML_TYPE_F32 &&
node->src1->type == GGML_TYPE_F32) {
cur = 0;
} else {
GGML_ASSERT(false);
}
}
work_size = MAX(work_size, cur);
} break;
case GGML_OP_SCALE:
{
node->n_tasks = n_threads;
} break;
case GGML_OP_CPY:
case GGML_OP_RESHAPE:
case GGML_OP_VIEW:
case GGML_OP_PERMUTE:
case GGML_OP_TRANSPOSE:
case GGML_OP_GET_ROWS:
case GGML_OP_DIAG_MASK_INF:
{
node->n_tasks = 1;
} break;
case GGML_OP_SOFT_MAX:
{
node->n_tasks = n_threads;
} break;
case GGML_OP_ROPE:
{
node->n_tasks = 1;
} break;
case GGML_OP_CONV_1D_1S:
case GGML_OP_CONV_1D_2S:
{
node->n_tasks = n_threads;
GGML_ASSERT(node->src0->ne[3] == 1);
GGML_ASSERT(node->src1->ne[2] == 1);
GGML_ASSERT(node->src1->ne[3] == 1);
size_t cur = 0;
const int nk = node->src0->ne[0];
if (node->src0->type == GGML_TYPE_F16 &&
node->src1->type == GGML_TYPE_F32) {
cur = sizeof(ggml_fp16_t)*(
nk*ggml_up32(node->src0->ne[1])*node->src0->ne[2] +
( 2*(nk/2) + node->src1->ne[0])*node->src1->ne[1]
);
} else if (node->src0->type == GGML_TYPE_F32 &&
node->src1->type == GGML_TYPE_F32) {
cur = sizeof(float)*(
nk*ggml_up32(node->src0->ne[1])*node->src0->ne[2] +
( 2*(nk/2) + node->src1->ne[0])*node->src1->ne[1]
);
} else {
GGML_ASSERT(false);
}
work_size = MAX(work_size, cur);
} break;
case GGML_OP_FLASH_ATTN:
{
node->n_tasks = n_threads;
size_t cur = 0;
if (node->src1->type == GGML_TYPE_F32) {
cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)
cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2
}
if (node->src1->type == GGML_TYPE_F16) {
cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)
cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2
}
work_size = MAX(work_size, cur);
} break;
case GGML_OP_FLASH_FF:
{
node->n_tasks = n_threads;
size_t cur = 0;
if (node->src1->type == GGML_TYPE_F32) {
cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)
cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2
}
if (node->src1->type == GGML_TYPE_F16) {
cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)
cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2
}
work_size = MAX(work_size, cur);
} break;
case GGML_OP_NONE:
{
node->n_tasks = 1;
} break;
case GGML_OP_COUNT:
{
assert(false);
} break;
};
}
if (cgraph->work != NULL && work_size > cgraph->work_size) {
assert(false); // TODO: better handling
}
if (work_size > 0 && cgraph->work == NULL) {
cgraph->work_size = work_size + CACHE_LINE_SIZE*(n_threads - 1);
GGML_PRINT_DEBUG("%s: allocating work buffer for graph (%zu bytes)\n", __func__, cgraph->work_size);
cgraph->work = ggml_new_tensor_1d(ctx, GGML_TYPE_I8, cgraph->work_size);
}
}
const int64_t perf_start_cycles = ggml_perf_cycles(); #计时用
const int64_t perf_start_time_us = ggml_perf_time_us();#计时用
for (int i = 0; i < cgraph->n_nodes; i++) {
GGML_PRINT_DEBUG_5("%s: %d/%d\n", __func__, i, cgraph->n_nodes);
struct ggml_tensor * node = cgraph->nodes[i];
// TODO: this could be used to avoid unnecessary computations, but it needs to be improved
//if (node->grad == NULL && node->perf_runs > 0) {
// continue;
//}
const int64_t perf_node_start_cycles = ggml_perf_cycles();
const int64_t perf_node_start_time_us = ggml_perf_time_us();
INIT
// INIT
struct ggml_compute_params params = {
/*.type =*/ GGML_TASK_INIT,
/*.ith =*/ 0,
/*.nth =*/ node->n_tasks,
/*.wsize =*/ cgraph->work ? ggml_nbytes(cgraph->work) : 0,
/*.wdata =*/ cgraph->work ? cgraph->work->data : NULL,
};
ggml_compute_forward(¶ms, node);
COMPUTE
// COMPUTE
if (node->n_tasks > 1) {
if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {
atomic_store(&state_shared.has_work, false);
}
while (atomic_load(&state_shared.has_work)) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
// launch thread pool
for (int j = 0; j < n_threads - 1; j++) {
workers[j].params = (struct ggml_compute_params) {
.type = GGML_TASK_COMPUTE,
.ith = j + 1,
.nth = n_threads,
.wsize = cgraph->work ? ggml_nbytes(cgraph->work) : 0,
.wdata = cgraph->work ? cgraph->work->data : NULL,
};
workers[j].node = node;
}
atomic_fetch_sub(&state_shared.n_ready, 1);
while (atomic_load(&state_shared.n_ready) > 0) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
atomic_store(&state_shared.has_work, true);
}
params.type = GGML_TASK_COMPUTE;
ggml_compute_forward(¶ms, node);
// wait for thread pool
if (node->n_tasks > 1) {
if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {
atomic_store(&state_shared.has_work, false);
}
while (atomic_load(&state_shared.has_work)) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
atomic_fetch_sub(&state_shared.n_ready, 1);
while (atomic_load(&state_shared.n_ready) != 0) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
}
FINALIZE
// FINALIZE
if (node->n_tasks > 1) {
if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {
atomic_store(&state_shared.has_work, false);
}
while (atomic_load(&state_shared.has_work)) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
// launch thread pool
for (int j = 0; j < n_threads - 1; j++) {
workers[j].params = (struct ggml_compute_params) {
.type = GGML_TASK_FINALIZE,
.ith = j + 1,
.nth = n_threads,
.wsize = cgraph->work ? ggml_nbytes(cgraph->work) : 0,
.wdata = cgraph->work ? cgraph->work->data : NULL,
};
workers[j].node = node;
}
atomic_fetch_sub(&state_shared.n_ready, 1);
while (atomic_load(&state_shared.n_ready) > 0) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
atomic_store(&state_shared.has_work, true);
}
params.type = GGML_TASK_FINALIZE;
ggml_compute_forward(¶ms, node);
// wait for thread pool
if (node->n_tasks > 1) {
if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {
atomic_store(&state_shared.has_work, false);
}
while (atomic_load(&state_shared.has_work)) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
atomic_fetch_sub(&state_shared.n_ready, 1);
while (atomic_load(&state_shared.n_ready) != 0) {
ggml_lock_lock (&state_shared.spin);
ggml_lock_unlock(&state_shared.spin);
}
}
// performance stats (node)
{
int64_t perf_cycles_cur = ggml_perf_cycles() - perf_node_start_cycles;
int64_t perf_time_us_cur = ggml_perf_time_us() - perf_node_start_time_us;
node->perf_runs++;
node->perf_cycles += perf_cycles_cur;
node->perf_time_us += perf_time_us_cur;
}
}
join thread pool
// join thread pool
if (n_threads > 1) {
atomic_store(&state_shared.stop, true);
atomic_store(&state_shared.has_work, true);
for (int j = 0; j < n_threads - 1; j++) {
int rc = pthread_join(workers[j].thrd, NULL);
assert(rc == 0);
UNUSED(rc);
}
ggml_lock_destroy(&state_shared.spin);
}
// performance stats (graph)
{
int64_t perf_cycles_cur = ggml_perf_cycles() - perf_start_cycles;
int64_t perf_time_us_cur = ggml_perf_time_us() - perf_start_time_us;
cgraph->perf_runs++;
cgraph->perf_cycles += perf_cycles_cur;
cgraph->perf_time_us += perf_time_us_cur;
GGML_PRINT_DEBUG("%s: perf (%d) - cpu = %.3f / %.3f ms, wall = %.3f / %.3f ms\n",
__func__, cgraph->perf_runs,
(double) perf_cycles_cur / (double) ggml_cycles_per_ms(),
(double) cgraph->perf_cycles / (double) ggml_cycles_per_ms() / (double) cgraph->perf_runs,
(double) perf_time_us_cur / 1000.0,
(double) cgraph->perf_time_us / 1000.0 / cgraph->perf_runs);
}
}


![[管理与领导-55]:IT基层管理者 - 扩展技能 - 1 - 时间管理 -2- 自律与自身作则,管理者管好自己时间的五步法](https://img-blog.csdnimg.cn/6d9e69c1648344bcbc09817f085f7693.png)