项目场景
利用Pytorch框架,结合FEDformer开源代码(https://github.com/MAZiqing/FEDformer),将自己的数据集作为输入训练模型。
问题描述
训练过程中,发现打印出来的Train loss, Test loss, Test loss中,Test loss从第一个epoch开始就为nan。

输出中间结果后,发现第一个epoch训练到了第二个batch时,模型输出开始出现了nan。

原因分析
查阅了相关资料,有这样一些说法:
- 梯度爆炸:batch size较大、学习率较大、数据特征之间值的差异较大
- 数据本身有缺失值
之后针对数据的缺失值进行了统计,发现并没有缺失值。所以初步认为是发生了梯度爆炸。
随后我做了多组实验,观察每次epoch的每个batch的预测结果是否存在nan:
- 对比实验a: 不断减小batch size
- 对比实验b: 不断减小学习率
- 对比实验c: 减少数据集特征的个数
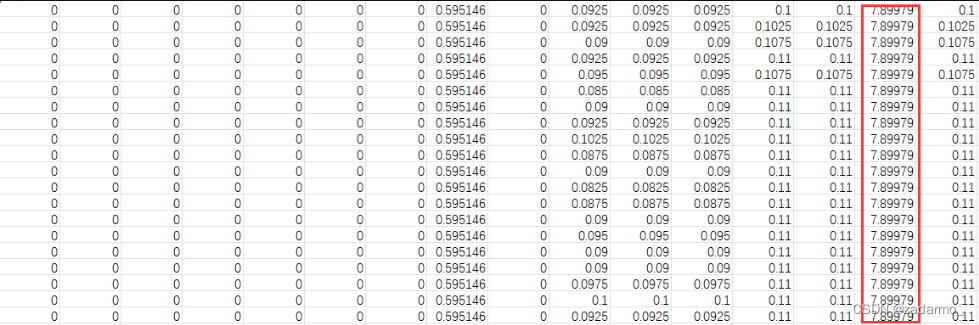
最终发现,是数据集特征的问题。数据集的某个特征和其他特征数值差异较大,导致模型在反向传播计算梯度的时候计算出的梯度值过大,从而导致了梯度爆炸。
解决方案
经过理论分析,这一列特征对于实验结果的影响不会很大,故直接将这一列特征从数据中删除。之后的实验结果也表明确实是这一列的引入导致了模型训练出现了NaN。
总结
深度学习训练过程中损失值出现NaN的情况:
- 梯度爆炸:batch size较大、学习率较大、数据特征之间值的差异较大
- 数据本身有缺失值