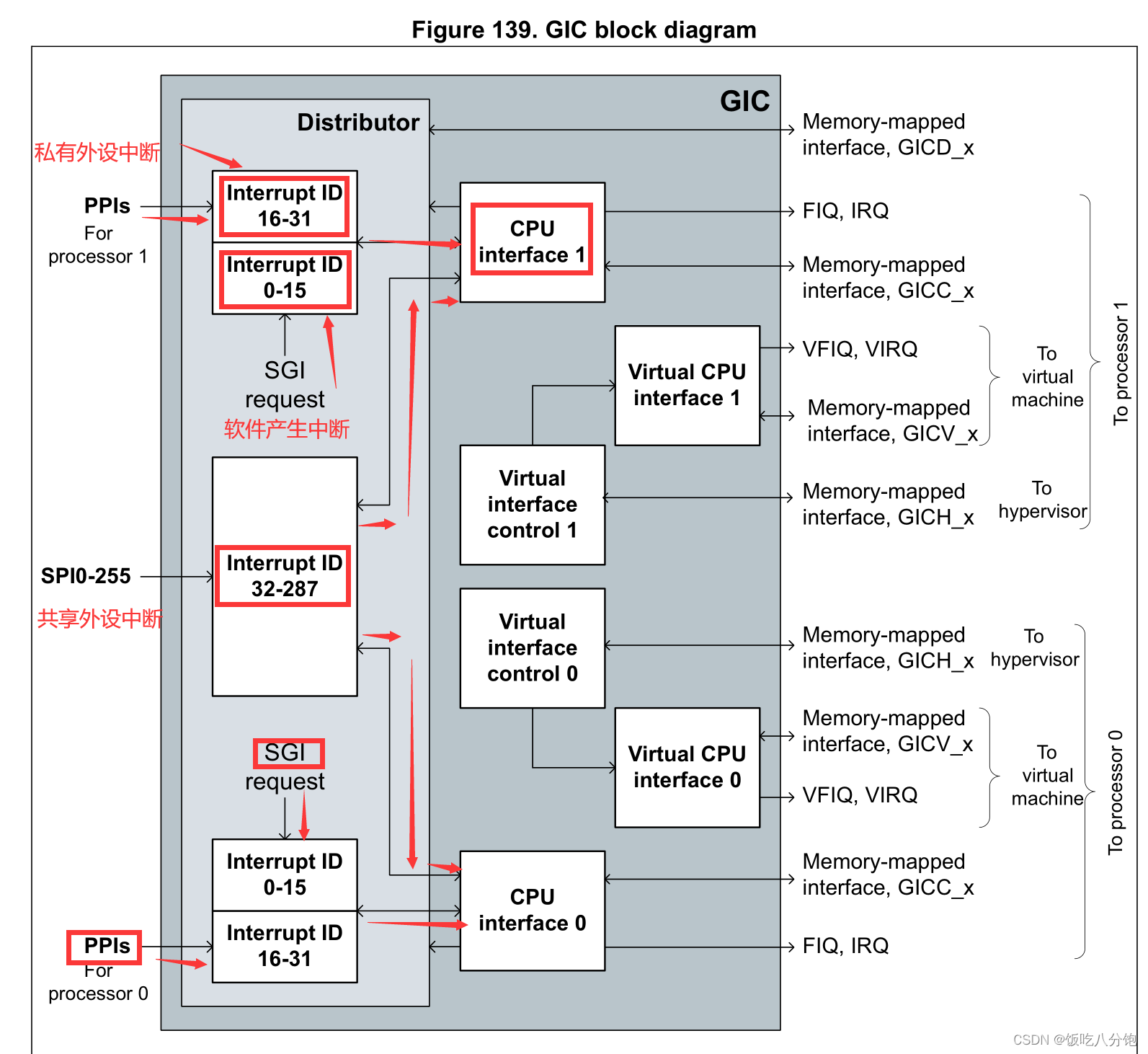
记录纸在吸收一切的人工智能商业模式上戳了洞
8月初,《纽约时报》更新了服务条款(TOS),禁止抓取其用于人工智能训练的文章和图片。报告广告周刊。此举正值科技公司继续利用人工智能语言应用赚钱之际,例如ChatGPT聊天机器人和谷歌诗人该公司通过对互联网数据进行大量未经授权的抓取而获得了他们的能力。
这新条款未经明确的书面许可,禁止使用时报内容(包括文章、视频、图像和元数据)来训练任何人工智能模型。在《服务条款》的第2.1节中,NYT表示,其内容供读者“个人非商业使用”,非商业使用不包括“任何软件程序的开发,包括但不限于训练机器学习或人工智能(AI)系统。”
再往下,在第4.1节,条款规定,未经NYT事先书面同意,任何人不得“将内容用于开发任何软件程序,包括但不限于培训机器学习或人工智能(AI)系统。”
NYT还概述了无视这些限制的后果:“从事被禁止的服务使用可能会导致对用户和帮助用户的人的民事、刑事和/或行政处罚、罚款或制裁。”
虽然听起来很危险,但限制性使用条款此前并没有阻止互联网对机器学习数据集的大规模吞噬。今天所有可用的大型语言模型——包括OpenAI的GPT-4人类的克劳德2,Meta的美洲驼2,还有谷歌的掌上电脑2—接受过从互联网上搜集的大量数据集的培训。使用一种叫做无监督学习,网络数据被输入神经网络,使人工智能模型获得一个概念感通过分析单词之间的关系。
使用抓取的数据训练人工智能模型的争议性,在美国法院尚未完全解决,导致了至少一起诉讼指控OpenAI由于这种做法而剽窃。上周,美联社和其他几家新闻机构发表了一份公开信称“必须制定一个法律框架来保护支持人工智能应用的内容”,以及其他担忧。
OpenAI可能预计到未来会继续面临法律挑战,并已开始采取措施,可能是为了提前应对一些批评。比如最近的OpenAI详述了一种方法这些网站可以利用robots.txt来阻止其人工智能训练网络爬虫。这导致了几个网站和作者公开声明他们会挡住爬行者。
目前,已经刮下来的内容被放进了GPT-4,包括《纽约时报》的内容。我们可能要等到GPT-5才能看到OpenAI或其他AI厂商是否尊重内容所有者被排除在外的意愿。否则,新的人工智能诉讼——或法规——可能即将出现。