文章目录
- 🍀引言
- 🍀什么是多元线性回归?
- 🍀多元线性回归的应用
- 🍀构建多元线性回归模型的步骤
- 🍀R-squared(R平方)
- 🍀多元线性回归案例---波士顿房价
🍀引言
当谈到回归分析时,多元线性回归是一个非常强大且常用的工具。它允许我们探索多个自变量与一个因变量之间的关系,并用一条线性方程来表示这种关系。在本文中,我们将深入探讨多元线性回归的概念、应用和解释,以及如何使用统计工具来进行模型的建立和评估。
🍀什么是多元线性回归?
多元线性回归是一种统计方法,用于研究多个自变量与一个连续因变量之间的关系。它基于线性方程的概念,即假设自变量与因变量之间存在线性关系。多元线性回归的数学表达式如下:
Y=β0+β1X1+β2X2+…+βpXp+εY=β0+β1X1+β2X2+…+βpXp+ε
在这个方程中,YY 是因变量,X1,X2,…,XpX1,X2,…,Xp 是自变量,β0,β1,β2,…,βpβ0,β1,β2,…,βp 是回归系数,代表了每个自变量对因变量的影响,εε 是误差项。
🍀多元线性回归的应用
- 经济学
在经济学中,多元线性回归可以用来探索多个因素对某一经济指标(如GDP、通货膨胀率)的影响。例如,研究收入、失业率、教育水平等因素对某地区的经济增长的影响。
- 医学
医学研究中,可以利用多元线性回归来分析多个生活方式因素(如饮食、运动)与健康指标(如体重、血压)之间的关系,从而预测健康状况。
- 市场营销
在市场营销领域,可以使用多元线性回归来分析广告支出、促销活动等因素对销售额的影响,从而优化营销策略。
🍀构建多元线性回归模型的步骤
构建一个有效的多元线性回归模型需要以下步骤:
- 数据收集
收集包含因变量和多个自变量的数据集。确保数据质量良好,包括准确性和完整性。
- 特征选择
根据领域知识和统计方法,选择对因变量有显著影响的自变量。避免过多的自变量,以防止过拟合。
- 拟合模型
使用统计软件(如Python中的Scikit-learn、R等)来拟合多元线性回归模型,估计回归系数。
- 模型评估
通过检查回归系数的显著性、模型的拟合优度(如R平方值)等指标来评估模型的质量。
- 残差分析
分析模型的残差,检查是否满足回归假设,如误差项的独立性、常数方差等。
- 预测与解释
使用模型进行预测,并解释各个自变量对因变量的影响程度。可以通过回归系数的正负来判断自变量的影响方向。
🍀R-squared(R平方)
R-squared(R平方),也称为决定系数(coefficient of determination),是多元线性回归模型中常用的一个统计指标,用于衡量模型对因变量变异性的解释程度。它表示因变量的变异有多少可以被模型所解释。
R-squared的取值范围在0到1之间,其中:
-
当 R-squared 接近 1 时,表示模型能够很好地解释因变量的变异,即模型拟合度较高,所用的自变量能够很好地解释因变量的波动。
-
当 R-squared 接近 0 时,表示模型不能够很好地解释因变量的变异,模型可能没有捕捉到数据中的关键模式,或者模型不够适合数据。
R-squared 的计算公式如下:

import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
def r2_score(y_true,y_predict):
return 1-((np.sum((y_true-y_predict)**2)/len(y_true))/np.var(y_true))
x = np.array([1.,2.,3.,4.,5.])
y = np.array([1.,3.,2.,3.,5.])
lin_reg = LinearRegression()
lin_reg.fit(x.reshape(-1,1),y)
y_predict = lin_reg.predict(x.reshape(-1,1))
r2_score(y,y_predict)
lin_reg.score(x.reshape(-1,1),y)
运行结果如下

其中,SSresSSres 是残差平方和(residual sum of squares),表示模型预测值与实际观测值之间的差异的平方和;SStotSStot 是总平方和(total sum of squares),表示实际观测值与因变量均值之间的差异的平方和。
R-squared 的值越接近1,表示模型的拟合效果越好。然而,需要注意的是,R-squared并不是一定越高越好。一个高的R-squared值并不一定意味着模型具有预测能力,因为过拟合问题可能会导致模型在训练数据上表现良好,但在新数据上表现较差。
因此,在解释多元线性回归模型的拟合程度时,需要结合其他评估指标,如调整后的R-squared、残差分析等,来综合评估模型的性能。
🍀多元线性回归案例—波士顿房价
下面我们一步一步分析一下如何使用多元线性回归预测波士顿房价
首先我们需要导入需要的库,并进行实例化
from sklearn.datasets import load_boston
boston.feature_names
之后我们可以查看一下相关的详细信息或者特征值
print(boston.DESCR)
boston.feature_names


这里我们取其中一列
x = boston.data[:,5].reshape(-1,1)
y = boston.target
这两行代码的作用是将波士顿房价数据集中的一个特定特征(第 5 列,例如可能是 “RM”,即每个住宅的平均房间数)作为输入特征 x,将房价作为目标变量 y。这样,您可以使用这些数据来训练机器学习模型,以尝试预测房价(目标变量 y)基于该特定特征(输入特征 x)
接下来我们需要进行一些必要的处理,用来剔除异常值
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
x = x[y<50]
y = y[y<50]
plt.scatter(x,y)
运行结果如下
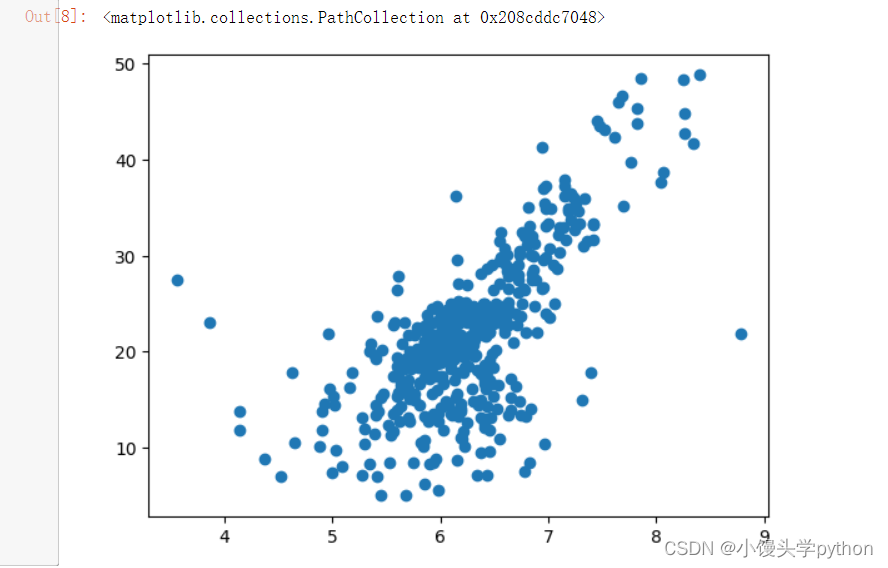
x = x[y < 50]: 这一行代码通过布尔索引筛选出目标变量 y 小于 50 的样本所对应的输入特征 x。换句话说,它从之前准备的输入特征 x 和目标变量 y 中,保留了那些房价小于 50 的数据点的特征值。这种操作可以用来剔除异常值或不符合问题背景的数据点。
y = y[y < 50]: 这一行代码对目标变量 y 也进行了相同的过滤操作,只保留了与之前筛选出的输入特征 x 对应的目标变量值。
接下来我们要进行切割数据集,分为训练集和测试集,之后我们进行拟合得到R^2
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=666)
lin_reg = LinearRegression()
lin_reg.fit(x_train,y_train)
lin_reg.score(x_test,y_test)
运行结果如下

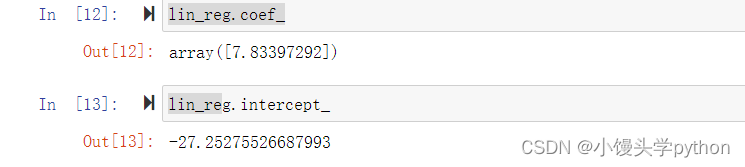
这里我们打印看看系数和截距
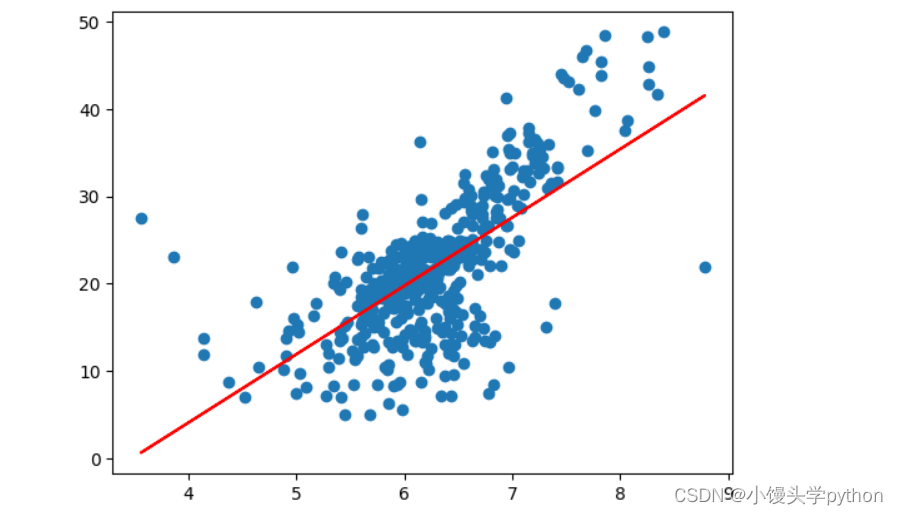
最后我们可以通过一条直线得到
plt.plot(x,lin_reg.predict(x),color='r')
plt.scatter(x,y)
plt.show()
运行结果如下
以上我们只考虑的一列,现在我们我们开始上真家伙
和上面类似
X = boston.data
y1 = boston.target
X = X[y1<50]
y1 = y1[y1<50]
X_train,X_test,y_train,y_test = train_test_split(X,y1,random_state=666)
lin_reg1 = LinearRegression()
lin_reg1.fit(X_train,y_train)
lin_reg1.score(X_test,y_test)
这里我们再打印系数和截距看看
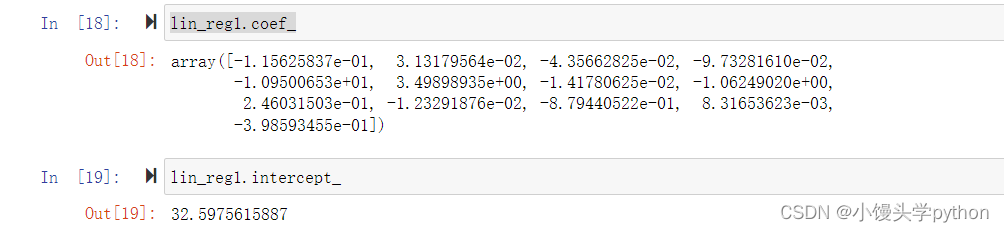
普通的线性回复只有一个特征值,所以只有一个系数,多元线性回归有多个系数
最后我们可以看看哪个特征对整体影响大写
boston.feature_names[np.argsort(lin_reg1.coef_)]
运行结果如下

在波士顿房价数据集中,“NOX” 是一个代表一氧化氮浓度的特征。这个特征描述了一个地区的空气质量,即一氧化氮的浓度。在数据集中,“NOX” 的值是以浓度为单位的数值,表示在该地区的环境中一氧化氮的浓度水平。

挑战与创造都是很痛苦的,但是很充实。