🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
复发的基础
扩展语言的循环
使用 RNN 创建文本分类器
堆叠 LSTM
优化堆叠 LSTM
使用 droput
将预训练嵌入与 RNN 结合使用
概括
在第 5 章中,您了解了如何对文本进行标记化和排序,将句子转化为数字张量,然后将其输入神经网络。然后,您在第 6 章中通过查看嵌入对其进行了扩展,嵌入是一种将具有相似含义的单词聚集在一起以启用情感计算的方法。这非常有效,正如您通过构建讽刺分类器所看到的那样。但这有一个限制,也就是说,句子不仅仅是单词包——通常单词出现的顺序将决定它们的整体含义。形容词可以增加或改变它们旁边出现的名词的含义。例如,从情感的角度来看,“蓝色”这个词可能毫无意义,“天空”也可能毫无意义,但是当你将它们放在一起得到“蓝天”时,就会有一种明确的情感,通常是积极的。有些名词可能修饰其他名词,例如“rain cloud”、“writing desk”、“coffee mug”。
为了将这样的序列考虑在内,需要一种额外的方法,那就是将递归因素纳入模型架构。在本章中,您将看到执行此操作的不同方法。我们将探索如何学习序列信息,以及如何使用这些信息来创建一种能够更好地理解文本的模型:递归神经网络(RNN)。
复发的基础
至为了理解递归是如何工作的,让我们首先考虑一下本书迄今为止使用的模型的局限性。最终,创建的模型看起来有点像图 7-1。您提供数据和标签并定义模型架构,模型学习使数据适合标签的规则。然后,这些规则将作为 API 提供给您,为您返回未来数据的预测标签。

图 7-1。模型创建的高级视图
但是,如您所见,数据是集中在一起的。不涉及粒度,也无需努力理解数据发生的顺序。这意味着“今天我是蓝色的,因为天空是灰色的”和“今天我很高兴,那里有美丽的蓝天”等句子中的“蓝色”和“天空”这两个词没有不同的含义。对我们来说,使用这些词的区别是显而易见的,但对于一个模型来说,这里显示的架构确实没有区别。
那么我们如何解决这个问题呢?让我们首先探讨递归的本质,从那里您将能够了解基本的 RNN 是如何工作的。
考虑著名的斐波那契数列。如果您不熟悉它,我已将其中一些放入图 7-2中。

图 7-2。斐波那契数列中的前几个数字
这个序列背后的想法是每个数字都是它前面两个数字的总和。所以如果我们从 1 和 2 开始,下一个数字是 1 + 2,也就是 3。再下一个是 2 + 3,也就是 5,然后是 3 + 5,也就是 8,依此类推。
我们可以把它放在一个计算图中得到图 7-3。
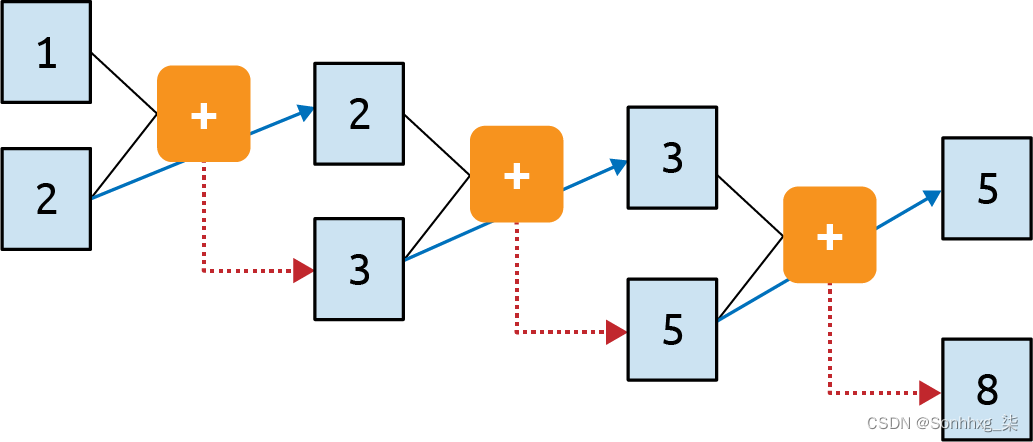
图 7-3。斐波那契数列的计算图表示
在这里你可以看到我们将 1 和 2 送入函数并得到 3 作为输出。我们将第二个参数 (2) 带到下一步,并将其与上一步 (3) 的输出一起输入函数。它的输出是 5,它被送入带有上一步 (3) 的第二个参数的函数,以产生输出 8。这个过程无限期地继续下去,每个操作都取决于它之前的操作。左上角的 1 在整个过程中“幸存”。它是 3 的一个元素被送入第二个操作,它是 5 的一个元素被送入第三个操作,依此类推。因此,1 的一些本质在整个序列中得以保留,尽管它对整体价值的影响被削弱了。
这类似于循环神经元的构建方式。您可以在图 7-4中看到循环神经元的典型表示。
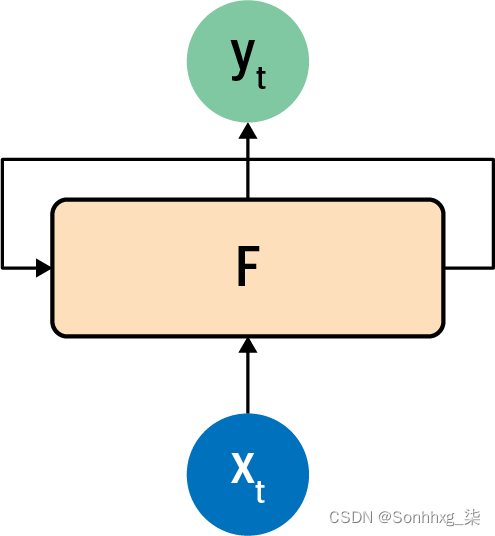
图 7-4。循环神经元
一个值 x 在一个时间步被输入到函数 F 中,所以它通常被标记为 x t。这会在该时间步产生输出 y,通常标记为 y t。它还会产生一个前馈给下一步的值,由从 F 到自身的箭头指示。
如果您查看循环神经元如何跨时间步彼此并排工作,就会更清楚一点,您可以在图 7-5中看到这一点。
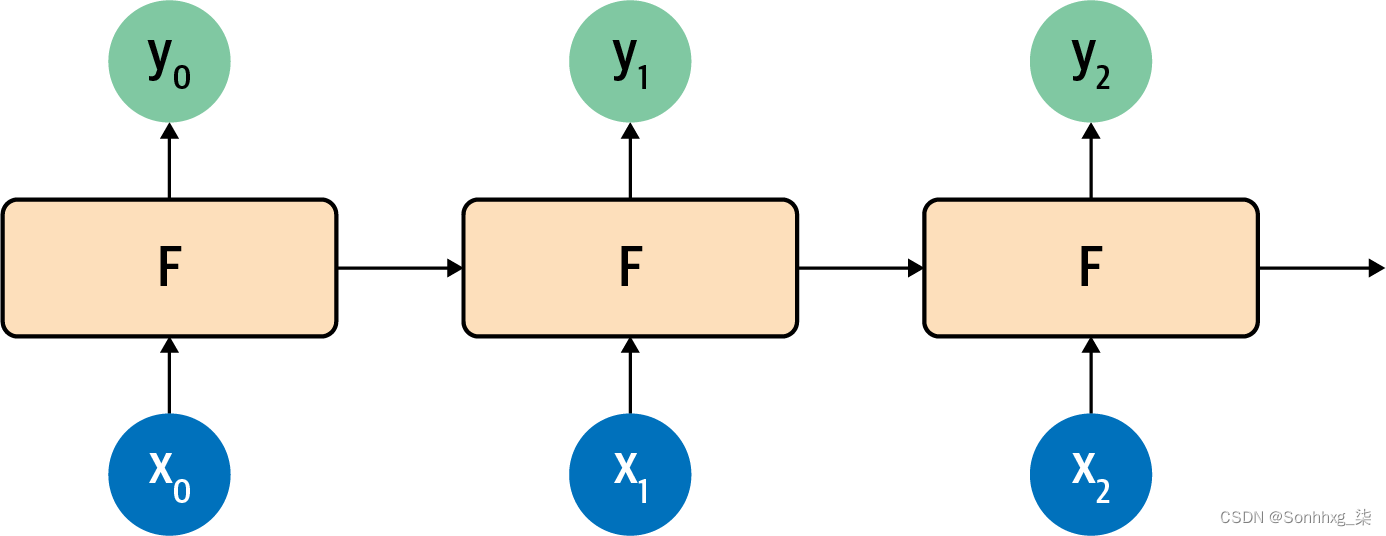
图 7-5。时间步长中的循环神经元
在这里,对 x 0进行运算以获得 y 0和向前传递的值。下一步获取该值和 x 1并生成 y 1和一个向前传递的值。下一个获取该值和 x 2并生成 y 2和一个传递值,依此类推。这类似于我们在斐波那契数列中看到的情况,而且我总是发现在试图记住 RNN 的工作原理时这是一个方便的助记符。
扩展语言的循环
<something> 是盖尔语,但真正给我们这种语境的词是“Ireland”,它位于句子的后面。因此,为了让我们能够识别 <something> 应该是什么,需要一种在更长距离内保存上下文的方法。RNN 的短期记忆需要变得更长,并且认识到这一点,对架构进行了增强,称为 发明了长短期记忆(LSTM)。
尽管我不会详细介绍 LSTM 工作原理的底层架构,图 7-6中显示的高级图表说明了要点。要了解有关内部操作的更多信息,请查看 Christopher Olah关于该主题的优秀博客文章。
LSTM 架构通过添加“单元状态”来增强基本 RNN,使上下文不仅可以逐步维护,而且可以跨整个步骤序列维护。记住这些是神经元,以神经元的方式学习,你可以看到这确保了重要的上下文会随着时间的推移而被学习。

图 7-6。LSTM 架构的高级视图
LSTM 的一个重要部分是它可以是双向的——时间步长向前和向后迭代,因此上下文可以在两个方向上学习。请参见图7-7的高级视图。
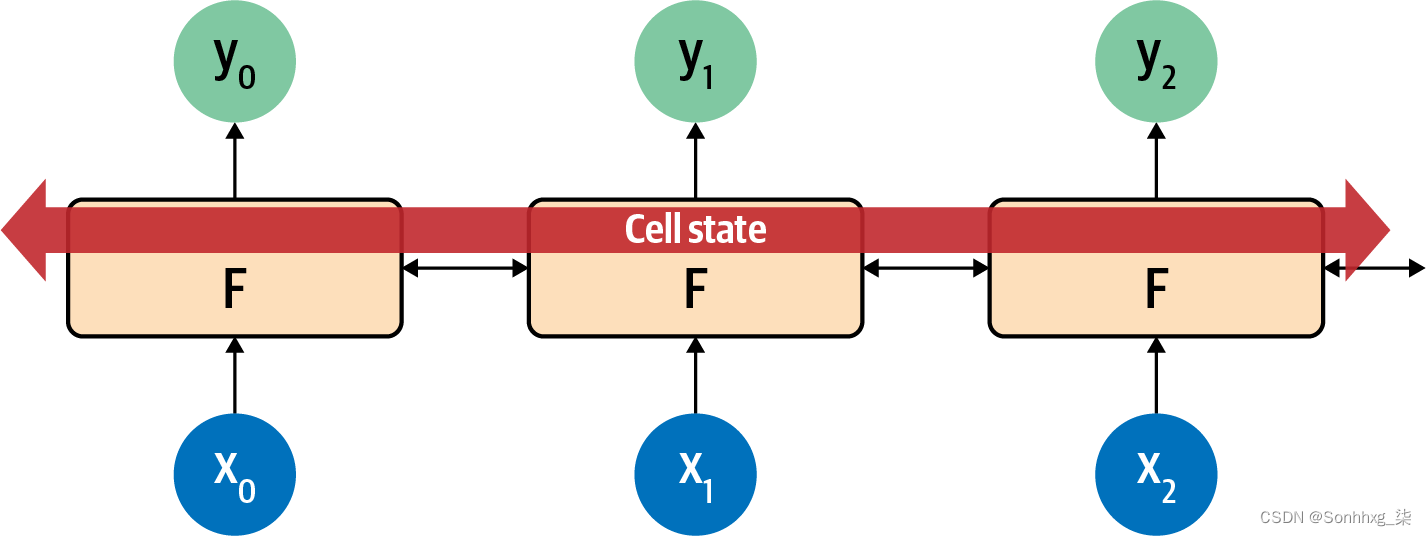
图 7-7。LSTM 双向架构的高级视图
这样,就完成了从 0 到number_of_steps方向的评估,从number_of_steps到 0 的评估也是如此。在每一步,y结果是“前向”传递和“后向”传递的聚合。您可以在图 7-8中看到这一点。
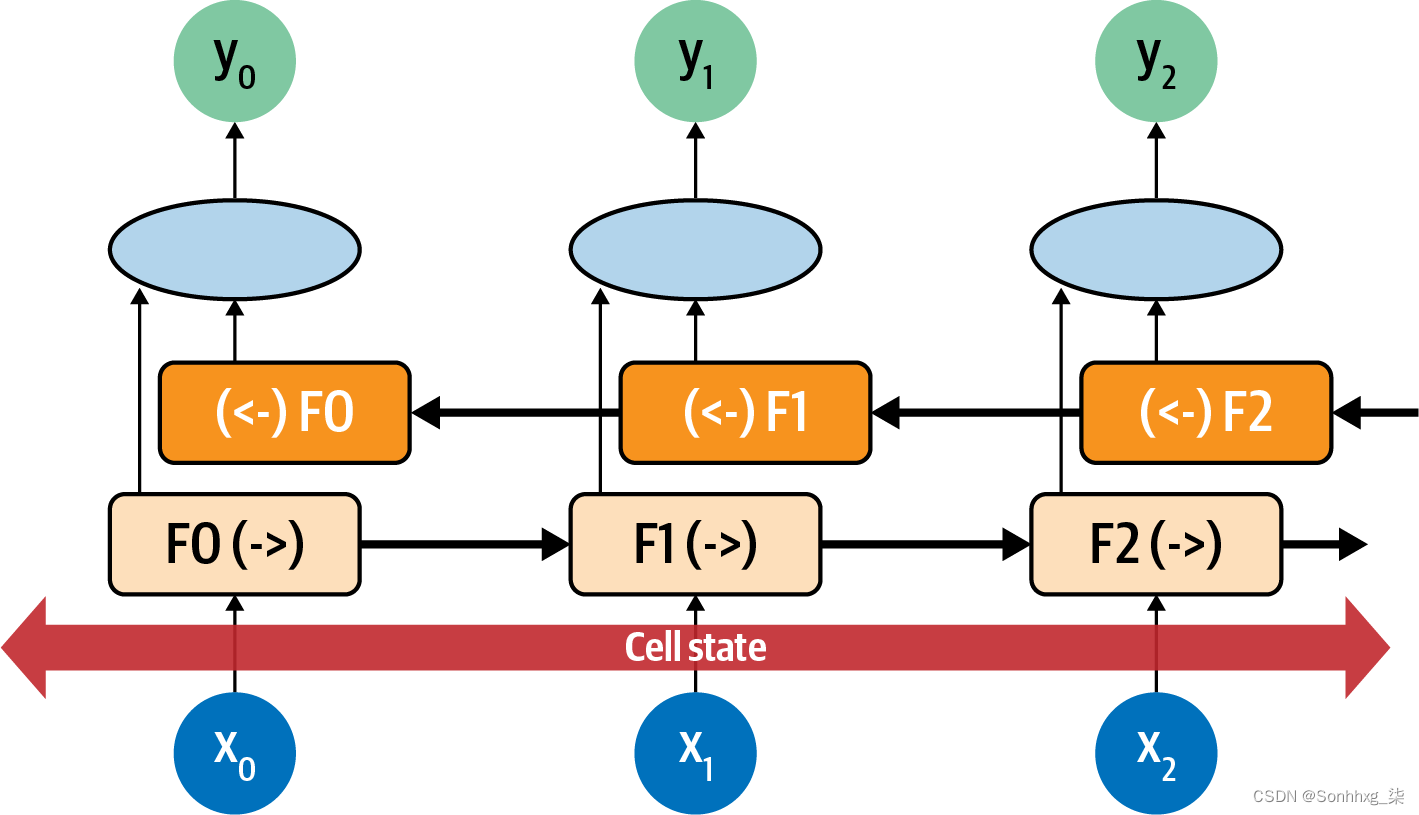
图 7-8。双向 LSTM
考虑每个时间步长的每个神经元为F0,F1,F2等。显示时间步长的方向,因此F1处的计算正向为F1(->),反向为(< -)F1。这些值被聚合以给出该时间步长的 y 值。此外,细胞状态是双向的。这对于管理句子中的上下文非常有用。再次考虑“我住在爱尔兰,所以在高中时我必须学习如何说和写<something>”这句话,你可以看到 <something> 如何被上下文词“爱尔兰”限定为“盖尔语”。 ” 但如果情况正好相反:“我住在<这个国家>,所以在高中时我必须学习如何说和写盖尔语”?你可以通过向后看通过句子我们可以了解到<this country>应该是什么。因此,使用双向 LSTM 可以非常有效地理解文本中的情感(正如您将在第 8 章中看到的那样,它们对于生成文本也非常强大!)。
当然,LSTM 有很多功能,尤其是双向 LSTM,因此预计训练速度会很慢。这是值得投资 GPU 的地方,或者如果可以的话,至少在 Google Colab 中使用托管的 GPU。
使用 RNN 创建文本分类器
在第 6 章你尝试使用嵌入为 Sarcasm 数据集创建分类器。在那种情况下,单词在聚合之前被转化为向量,然后被送入密集层进行分类。使用 LSTM 等 RNN 层时,您无需进行聚合,可以将嵌入层的输出直接馈送到循环层。当谈到循环层的维度时,您经常会看到的一个经验法则是它与嵌入维度的大小相同。这不是必需的,但可以是一个很好的起点。请注意,虽然在第 6 章中我提到嵌入维度通常是词汇表大小的四次方根,但在使用 RNN 时,你会经常看到该规则被忽略,因为它会使循环层的大小太小。
因此,例如,您在第 6 章中开发的讽刺分类器的简单模型架构可以更新为使用双向 LSTM:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])损失函数和分类器可以这样设置(注意学习率为0.00001,即1e-5):
adam = tf.keras.optimizers.Adam(learning_rate=0.00001,
beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam, metrics=['accuracy'])当您打印出模型架构摘要时,您会看到类似这样的内容。请注意,词汇量大小为 20,000,嵌入维度为 64。这在嵌入层中提供了 1,280,000 个参数,双向层将有 128 个神经元(64 个输出,64 个返回):
Layer (type) Output Shape Param #
=================================================================
embedding_11 (Embedding) (None, None, 64) 1280000
_________________________________________________________________
bidirectional_7 (Bidirection (None, 128) 66048
_________________________________________________________________
dense_18 (Dense) (None, 24) 3096
_________________________________________________________________
dense_19 (Dense) (None, 1) 25
=================================================================
Total params: 1,349,169
Trainable params: 1,349,169
Non-trainable params: 0
_________________________________________________________________如您所见,网络在训练数据上的准确率迅速攀升至 90% 以上,但验证数据稳定在 80% 左右。这与我们之前得到的数字相似,但检查图 7-10中的损失图表表明,虽然验证集的损失在 15 个时期后出现分歧,但它也趋于平缓到一个比第 6 章中的损失图表,尽管使用了 20,000 个单词而不是 2,000 个。
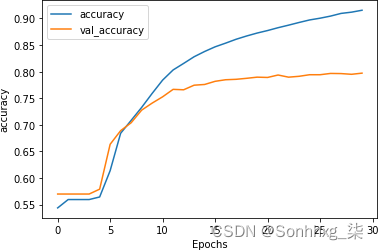
图 7-9。LSTM 超过 30 个时期的准确度
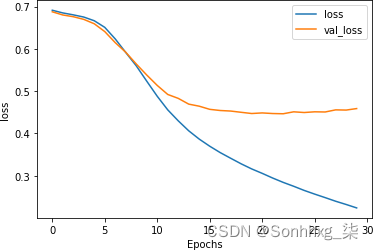
图 7-10。LSTM 超过 30 个时期的损失
然而,这只是使用了一个 LSTM 层。在下一节中,您将了解如何使用堆叠 LSTM 并探索对分类此数据集的准确性的影响。
堆叠 LSTM
在在上一节中,您了解了如何在嵌入层之后使用 LSTM 层来帮助对 Sarcasm 数据集的内容进行分类。但是 LSTM 可以相互堆叠,这种方法被用于许多最先进的 NLP 模型中。
使用 TensorFlow 堆叠 LSTM 非常简单。您可以像添加图层一样将它们添加为额外图层Dense,但除了最后一个图层之前的所有图层都需要具有它们的 return_sequences属性设置为True。这是一个例子:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim,
return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])最后一层也可以有return_sequences=True集合,在这种情况下,它会将值序列返回到密集层进行分类,而不是单个值。这在解析模型的输出时会很方便,我们将在后面讨论。模型架构将如下所示:
Layer (type) Output Shape Param #
=================================================================
embedding_12 (Embedding) (None, None, 64) 1280000
_________________________________________________________________
bidirectional_8 (Bidirection (None, None, 128) 66048
_________________________________________________________________
bidirectional_9 (Bidirection (None, 128) 98816
_________________________________________________________________
dense_20 (Dense) (None, 24) 3096
_________________________________________________________________
dense_21 (Dense) (None, 1) 25
=================================================================
Total params: 1,447,985
Trainable params: 1,447,985
Non-trainable params: 0
_________________________________________________________________添加额外的层将为我们提供大约 100,000 个需要学习的额外参数,增加约 8%。因此,它可能会减慢网络速度,但如果有合理的收益,成本相对较低。
训练 30 个时期后,结果如图7-11所示。尽管验证集上的准确性是平坦的,检查损失(图 7-12)说明了一个不同的故事。
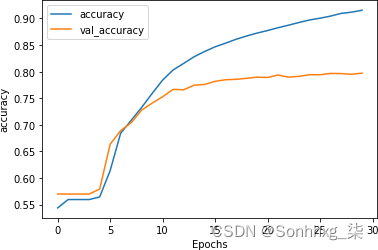
图 7-11。堆叠式 LSTM 架构的准确性
作为你可以在图 7-12中看到,虽然训练和验证的准确性看起来都不错,但验证损失迅速上升,这是过度拟合的明显迹象。

图 7-12。堆叠式 LSTM 架构的损失
这种过度拟合(表现为随着损失平稳下降,训练准确率攀升至 100%,而验证准确率相对稳定,损失急剧增加)是模型对训练集过度专业化的结果。与第 6 章中的示例一样,这表明如果您只查看准确性指标而不检查损失,则很容易陷入错误的安全感。
优化堆叠 LSTM
在第 6 章中,您看到减少过度拟合的一种非常有效的方法是减少学习率。它是值得探索的是,这是否也会对循环神经网络产生积极影响。
例如,以下代码将学习率从 0.00001 降低 20% 至0.000008:
adam = tf.keras.optimizers.Adam(learning_rate=0.000008,
beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam,metrics=['accuracy'])图 7-13演示这对训练的影响。似乎没有太大区别,尽管曲线(尤其是验证集)更平滑一些。
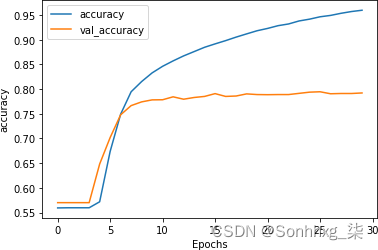
图 7-13。降低学习率对堆叠式 LSTM 准确性的影响
虽然初步查看图 7-14同样表明学习率降低对损失的影响很小,但值得仔细观察。尽管曲线的形状大致相似,但损失增加率明显较低:在 30 个 epoch 后,它约为 0.6,而随着学习率的提高,它接近 0.8。调整学习率超参数当然值得研究。
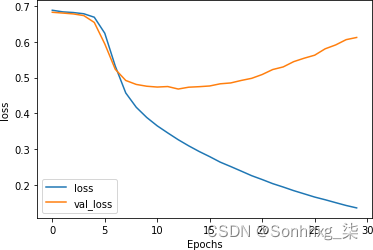
图 7-14。降低学习率对堆叠式 LSTM 损失的影响
使用 droput
在除了改变学习率参数外,还值得考虑在 LSTM 层中使用 dropout。它的工作原理与第 3 章中讨论的密集层完全相同,其中随机神经元被丢弃以防止邻近偏差影响学习。
可以使用 LSTM 层上的参数来实现 Dropout。这是一个例子:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim,
return_sequences=True, dropout=0.2)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim,
dropout=0.2)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])请注意,实施 dropout 会大大减慢您的训练速度。就我而言,使用 Colab,它从每个纪元约 10 秒减少到约 180 秒。
这精度结果见图7-15。
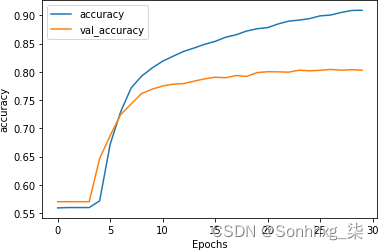
图 7-15。使用 dropout 的堆叠 LSTM 的准确性
作为可以看到,使用dropout对网络的准确率并没有太大的影响,这很好!人们总是担心丢失神经元会使您的模型表现更差,但正如我们在这里看到的那样,情况并非如此。
正如您在图 7-16中所见,这对损失也有积极影响。
虽然曲线明显发散,但它们比以前更接近,并且验证集在大约 0.5 的损失下变平。这明显好于之前看到的 0.8。如本示例所示,dropout 是另一种方便的技术,您可以使用它来提高基于 LSTM 的 RNN 的性能。
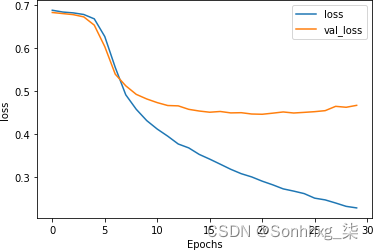
图 7-16。启用 dropout 的 LSTM 的损失曲线
值得探索这些避免数据过度拟合的技术,以及我们在第 6 章中介绍的预处理数据的技术。但是有一件事我们还没有尝试过——一种迁移学习形式,您可以使用预学习的词嵌入而不是尝试学习自己的词嵌入。接下来我们将探讨这一点。
将预训练嵌入与 RNN 结合使用
在在前面的所有示例中,您收集了要在训练集中使用的全套单词,然后用它们训练嵌入。这些在被馈送到密集网络之前最初被聚合,在本章中,您探索了如何使用 RNN 改进结果。在执行此操作时,您只能使用数据集中的单词以及如何使用该数据集中的标签来学习它们的嵌入。
回想第 4 章,我们讨论了迁移学习。如果不是自己学习嵌入,而是使用预先学习的嵌入,研究人员已经完成了将单词转化为向量的艰苦工作,并且这些向量得到了证明,那会怎么样?这方面的一个例子是由斯坦福大学的 Jeffrey Pennington、Richard Socher 和 Christopher Manning 开发的GloVe(用于词表示的全局向量)模型。
在这种情况下,研究人员分享了他们为各种数据集预训练的词向量:
-
一个 60 亿个标记、400,000 个单词的词汇集,分为 50、100、200 和 300 个维度,单词来自维基百科和 Gigaword
-
300 个维度的 420 亿个标记,190 万个单词的词汇来自一个普通的抓取
-
300 个维度的 8400 亿个标记,220 万个单词的词汇来自一个普通的抓取
-
从 Twitter 抓取的 20 亿条推文中提取的 270 亿个标记、120 万个单词的词汇表,分为 25、50、100 和 200 个维度
鉴于向量已经过预训练,在您的 TensorFlow 代码中重用它们很简单,而不是从头开始学习。首先,您必须下载 GloVe 数据。我选择使用包含 270 亿个标记和 120 万个单词的 Twitter 数据。下载的是具有 25、50、100 和 200维度的存档。
为了让您更轻松一点,我托管了 25 维版本,您可以像这样将其下载到 Colab 笔记本中:
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com
/glove.twitter.27B.25d.zip \
-O /tmp/glove.zip这是一个 ZIP 文件,因此您可以像这样解压它以获得名为glove.twitter.27b.25d.txt的文件:
# Unzip GloVe embeddings
import os
import zipfile
local_zip = '/tmp/glove.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/glove')
zip_ref.close()文件中的每个条目都是一个词,后面跟着为它学习的维度系数。使用它的最简单方法是创建一个字典,其中键是单词,值是嵌入。你可以像这样设置这个字典:
glove_embeddings = dict()
f = open('/tmp/glove/glove.twitter.27B.25d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
glove_embeddings[word] = coefs
f.close()此时,您只需将任何单词用作键即可查找该组系数。因此,例如,要查看“青蛙”的嵌入,您可以使用:
glove_embeddings['frog']有了这个资源,您可以像以前一样使用分词器为您的语料库获取单词索引——但现在您可以创建一个新矩阵,我将其称为嵌入矩阵。这将使用 GloVe 集嵌入(取自glove_embeddings)作为其值。因此,如果您检查数据集的单词索引中的单词,如下所示:
{'<OOV>': 1, 'new': 2, … 'not': 5, 'just': 6, 'will': 7那么嵌入矩阵的第一行应该是 GloVe 中“<OOV>”的系数,下一行是“new”的系数,依此类推。
您可以使用以下代码创建该矩阵:
embedding_matrix = np.zeros((vocab_size, embedding_dim))
for word, index in tokenizer.word_index.items():
if index > vocab_size - 1:
break
else:
embedding_vector = glove_embeddings.get(word)
if embedding_vector is not None:
embedding_matrix[index] = embedding_vector这只是创建一个矩阵,其中包含所需词汇量和嵌入维度的维度。然后,对于分词器单词索引中的每个项目,您从 GloVe 中查找系数glove_embeddings,并将这些值添加到矩阵中。
然后,您通过设置参数修改嵌入层以使用预训练嵌入weights,并指定您不希望通过设置训练该层trainable=False:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix], trainable=False),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim,
return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])您现在可以像以前一样训练。但是,您需要考虑您的词汇量。您在上一章中为避免过度拟合所做的优化之一旨在防止嵌入因学习低频词而负担过重;您通过使用较少的常用词词汇表避免了过度拟合。在这种情况下,由于已经使用 GloVe 为您学习了词嵌入,因此您可以扩展词汇量——但扩展多少?
首先要探索的是你的语料库中有多少单词实际上在 GloVe 集中。它有 120 万个单词,但不能保证它包含您的所有单词。
所以,这里有一些代码可以进行快速比较,这样你就可以探索你的词汇量应该有多大。
首先让我们整理一下数据。创建 Xs 和 Ys 的列表,其中 X 是单词索引,如果单词在嵌入中则 Y=1,否则为 0。此外,您可以创建一个累积集,在其中计算每个时间步的词商。例如,索引 0 处的单词“OOV”不在 GloVe 中,因此它的累积 Y 将为 0。下一个索引处的单词“new”在 GloVe 中,因此它的累积 Y 将为 0.5(即,到目前为止看到的单词中有一半在 GloVe 中),您将继续以这种方式计算整个数据集:
xs=[]
ys=[]
cumulative_x=[]
cumulative_y=[]
total_y=0
for word, index in tokenizer.word_index.items():
xs.append(index)
cumulative_x.append(index)
if glove_embeddings.get(word) is not None:
total_y = total_y + 1
ys.append(1)
else:
ys.append(0)
cumulative_y.append(total_y / index)然后使用以下代码绘制 X 与 Y 的对比图:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12,2))
ax.spines['top'].set_visible(False)
plt.margins(x=0, y=None, tight=True)
#plt.axis([13000, 14000, 0, 1])
plt.fill(ys)这将为您提供一个词频图表,如图7-17所示。

图 7-17。词频图
正如您在图表中看到的,密度在 10,000 到 15,000 之间变化。这给你一个眼球检查,在令牌 13,000 左右的某个地方,不在GloVe 嵌入中的单词的频率开始超过那些。如果您随后绘制 与 的cumulative_x对比图cumulative_y,您可以更好地理解这一点。这是代码:
import matplotlib.pyplot as plt
plt.plot(cumulative_x, cumulative_y)
plt.axis([0, 25000, .915, .985])您可以在图 7-18中看到结果。
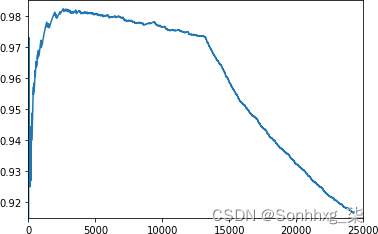
图 7-18。根据 GloVe 绘制单词索引的频率
您现在可以调整参数plt.axis以放大以找到 GloVe 中不存在的单词开始超过 GloVe 中的单词的拐点。这是您设置词汇量的一个很好的起点。
使用这种方法,我选择使用 13,200 个词汇量(而不是之前用于避免过度拟合的 2,000 个)和这个模型架构,这是因为我使用的是 GloVeembedding_dim集25:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix], trainable=False),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim,
return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
adam = tf.keras.optimizers.Adam(learning_rate=0.00001, beta_1=0.9, beta_2=0.999,
amsgrad=False)
model.compile(loss='binary_crossentropy',optimizer=adam, metrics=['accuracy'])对其进行 30 个时期的训练会产生一些出色的结果。精度如图7-19所示。验证精度非常接近训练精度,表明我们不再过度拟合。
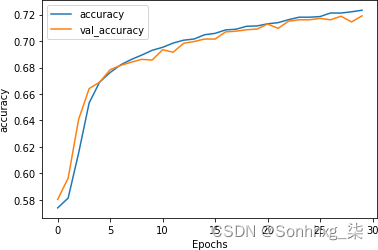
图 7-19。使用 GloVe 嵌入的堆叠 LSTM 精度
如图 7-20所示,损耗曲线加强了这一点。验证损失不再发散,这表明尽管我们的准确度只有 ~73%,但我们可以确信模型准确到那个程度。
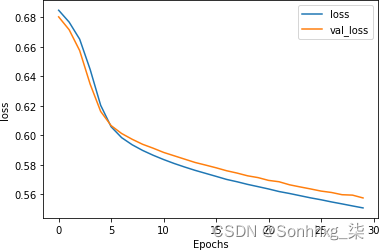
图 7-20。使用 GloVe 嵌入的堆叠 LSTM 损失
对模型进行更长时间的训练显示出非常相似的结果,并表明虽然在第 80 轮左右开始出现过拟合,但模型仍然非常稳定。
准确性指标(图 7-21)显示了一个训练有素的模型。
损失指标(图 7-22)显示在第 80 轮左右开始出现分歧,但模型仍然拟合良好。
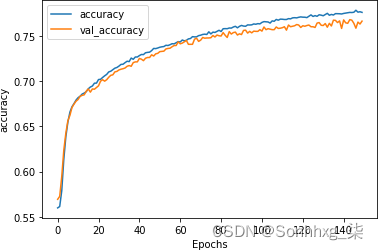
图 7-21。使用 GloVe 的堆叠式 LSTM 超过 150 个时期的准确度
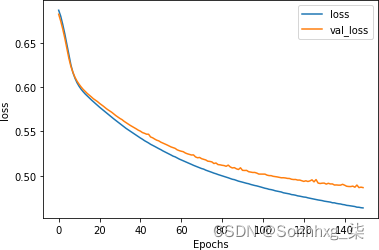
图 7-22。使用 GloVe 的堆叠 LSTM 损失超过 150 个时期
这告诉我们,该模型非常适合提前停止,您只需对其进行 75-80 轮训练即可获得最佳结果。
我用The Onion的标题(Sarcasm 数据集中讽刺标题的来源)与其他句子进行了测试,如下所示:
test_sentences = ["It Was, For, Uh, Medical Reasons, Says Doctor To Boris Johnson,
Explaining Why They Had To Give Him Haircut",
"It's a beautiful sunny day",
"I lived in Ireland, so in high school they made me learn to speak and write in
Gaelic",
"Census Foot Soldiers Swarm Neighborhoods, Kick Down Doors To Tally Household
Sizes"]这些标题的结果如下——请记住,接近 50% (0.5) 的值被认为是中性的,接近 0 的是非讽刺的,接近 1 的是讽刺的:
[[0.8170955 ]
[0.08711044]
[0.61809343]
[0.8015281 ]]摘自The Onion 的第一句和第四句显示讽刺的可能性超过 80%。关于天气的陈述是强烈的非讽刺 (9%),关于在爱尔兰上高中的句子被认为具有潜在的讽刺意味,但可信度不高 (62%)。
概括
本章向您介绍了循环神经网络,它在设计中使用面向序列的逻辑,不仅可以根据句子包含的单词,还可以根据它们出现的顺序来帮助您理解句子中的情绪。您了解了基本 RNN 的工作原理,以及 LSTM 如何在此基础上构建以长期保留上下文。您使用这些来改进您一直在研究的情绪分析模型。然后,您研究了 RNN 的过度拟合问题和改进它们的技术,包括使用来自预训练嵌入的迁移学习。在第 8 章中,您将使用所学知识探索如何预测单词,然后您将能够创建一个模型来创建文本,为您写诗!









![【简单项目实战】用C++实现学生成绩管理系统 | [面向对象]](https://img-blog.csdnimg.cn/698820809eb842a5bbf531258e2713e7.png)