加油站ai视觉分析预警系统通过yolov8图像识别和行为分析,加油站ai视觉分析预警算法识别出打电话抽烟、烟火行为、静电释放时间是否合规、灭火器摆放以及人员工服等不符合规定的行为,并发出预警信号以提醒相关人员。YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。YOLOv8 的训练策略和 YOLOv5 没有啥区别,最大区别就是模型的训练总 epoch 数从 300 提升到了 500,这也导致训练时间急剧增加。
在介绍Yolo算法之前,首先先介绍一下滑动窗口技术,这对我们理解Yolo算法是有帮助的。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图3所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。
YOLOv8分割模型使用-seg后缀,即yolov8n- seg .pt,并在COCO上进行预训练。在COCO128-seg数据集上训练YOLOv8n-seg 100个epoch,图像大小为640。在COCO128-seg数据集上验证训练过的YOLOv8n-seg模型的准确性。不需要传递参数,因为模型保留了它的训练数据和参数作为模型属性。图像分类器的输出是一个单一的类标签和一个置信度分数。当您只需要知道图像属于什么类,而不需要知道该类对象的位置或它们的确切形状时,图像分类是有用的。YOLOv8分类模型使用-cls后缀,即yolov8n-cls.pt,并在ImageNet上进行预训练。其他的使用方法和检测与分割类似,不再赘述。
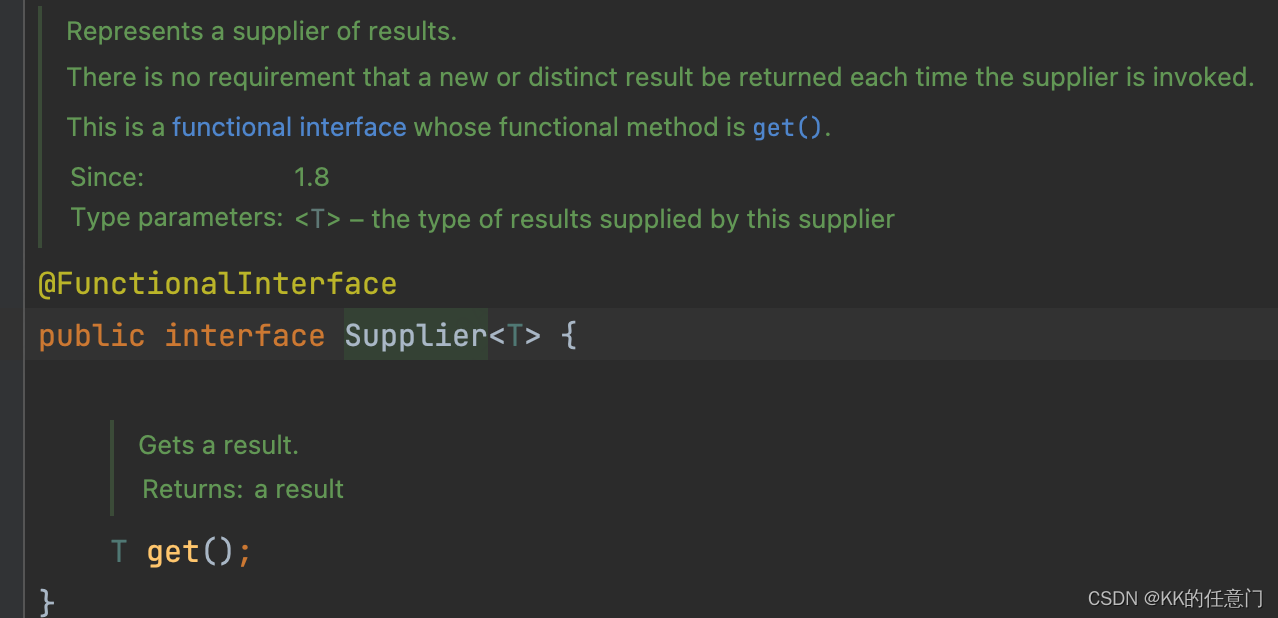
Adapter接口定义了如下方法:
public abstract void registerDataSetObserver (DataSetObserver observer)
Adapter表示一个数据源,这个数据源是有可能发生变化的,比如增加了数据、删除了数据、修改了数据,当数据发生变化的时候,它要通知相应的AdapterView做出相应的改变。为了实现这个功能,Adapter使用了观察者模式,Adapter本身相当于被观察的对象,AdapterView相当于观察者,通过调用registerDataSetObserver方法,给Adapter注册观察者。
public abstract void unregisterDataSetObserver (DataSetObserver observer)
通过调用unregisterDataSetObserver方法,反注册观察者。
public abstract int getCount () 返回Adapter中数据的数量。
public abstract Object getItem (int position)
Adapter中的数据类似于数组,里面每一项就是对应一条数据,每条数据都有一个索引位置,即position,根据position可以获取Adapter中对应的数据项。
public abstract long getItemId (int position)
获取指定position数据项的id,通常情况下会将position作为id。在Adapter中,相对来说,position使用比id使用频率更高。
public abstract boolean hasStableIds ()
hasStableIds表示当数据源发生了变化的时候,原有数据项的id会不会发生变化,如果返回true表示Id不变,返回false表示可能会变化。Android所提供的Adapter的子类(包括直接子类和间接子类)的hasStableIds方法都返回false。
public abstract View getView (int position, View convertView, ViewGroup parent)
getView是Adapter中一个很重要的方法,该方法会根据数据项的索引为AdapterView创建对应的UI项。