说明
为了进一步提升程序设计与运维的可靠性,我觉得(目前看来)只有依赖图的结构。
提升主要包含如下方面:
- 1 程序结构的简洁性:节点和边
- 2 程序执行的可视化:交通图(红、黄、绿)
- 3 程序支持的逻辑复杂性。子图嵌套。
其实这种方法在很多AI工具(例如KNIME)都已经使用了,似乎这也是唯一可行的方法。之所以要自己开发,还是基于一条假设:现成的工具永远无法实现你最重要的20%需求。
抛开一些可视化效果不说,目前的图工具又有什么特别棒的地方呢?
内容
1 想法
通过结构上的设计来确保万无一失,而不是依赖主观意愿的不出错
子图。子图是最常见的管理单位,一个子图一定具有的结构是Input、Core和Output。Core也可以称为子图核心,从运行上可以认为是一个服务,或者是一个以固定的定时程序来替代(间歇性服务)。
子图是一个合理的功能划分,通常不超过10个节点,这个规模属于人能容易看清楚,而工作量大约为几个人天的规模。
子图在某种程度上也可以认为是一个大号的节点。节点会包含某种处理和存储,简单的时候,可以理解为节点“run"一个函数,然后根据input(s)处理为output(s)。当处理比较复杂的时候,那么就是一个子图,里面有若干个节点的处理流程。所以子图同样需要类似input(s)处理为output(s), 同样,子图也有run方法,但是子图的run会按顺序(BFS)若干节点的run。
在实际运行时,最小的单位应该就是子图,因为子图有核心,可以改变结构,最重要的可以进行常态服务。如果某块工作只有一个节点,那么这个节点也应该注册到某个子图。
关联操作。之所以要将节点注册到子图,最大的原因是这些操作(结果)间存在关联,将它们放在一起执行是合适的:产生的中间结果可以在一次图会话中暂存,可以切进去反复调试、修改。
子图模板与运行子图。我们基于某项具体的任务或者业务进行(逻辑)处理上的设计,所形成的图称为子图模板,例如实体识别的处理是一个子图模板,当用于业务A的时候,启动一个子图称为运行子图,运行子图是一个子图模板的副本,但挂载了与业务相关的资源(例如磁盘、CPU、GPU),并保存了相应的执行信息,例如日志。
子图最终是以嵌套的方式构成更复杂的结构的。因为子图和节点的结构(input和output)以及调用方法都是固定的,所以最终可以视为都是某一张子图的运行。这样做的好处是,同样所有的结构都是高度相似的。当然也有坏处,就是我们无法得知一张子图到底有多"深",这会带来运行时间和效率的不确定性。所以在设计每一个子图的时候,要让其容纳足够的逻辑复杂性。随着计算机性能的提升,处理复杂性并维持逻辑稳定性显然是更重要的。只要确保每次子图的执行时间是可行的,那么通过分布式系统可以同时计算大量的任务。
最终,一个大的问题变为了一个子图设计问题,这确保了各个组件间自动的关联。子图和节点有着同样的结构,这样在开发时又是高度一致,并且简洁的。
2 尝试
首先,先确定本地的图工具为Networkx。这是一个比较经典的网络工具包,本身可以进行一些常见的图计算。这里,我主要利用这个包本身的网络构造方法,未来可能还会用一些路径算法,来计算最小距离之类的。当本地的开发成熟后,网络信息将以Json形式同步到Mongo和Neo4j,从而实现全局的存储、应用和搜索(图查询)。
下面定义了一个网络,是一个数据处理的流程(相对粗粒度)。
- 1 可以感觉到,定义到6个节点时,开始略微觉得有点烦,但还可以接受。我觉得这个就是一个子图合适的尺寸。一般的任务可以大致以3层子图来进行规划,这样容纳的就是6**3 ~ 216个节点。
- 2 每个节点的属性实际上就是一个标准字典,可以容纳函数。但是要进行Json保存的时候就会有问题(函数无法Json序列化)。
# =============== 例子
import networkx as nx
import matplotlib.pyplot as plt
# =======================> 图的定义
# Create a directed graph
G = nx.DiGraph()
def hello():
print('This is Node Running ...')
G.add_node(1)
G.nodes[1]['name'] = 'M'
G.nodes[1]['description'] = '数据1'
G.nodes[1]['run'] = hello
G.add_node(2)
G.nodes[2]['name'] = 'C'
G.nodes[2]['description'] = '数据2'
G.nodes[2]['run'] = hello
G.add_node(3)
G.nodes[3]['name'] = 'MergeData'
G.nodes[3]['description'] = '合并数据'
G.nodes[3]['run'] = hello
G.add_edge(1,3)
G.add_edge(2,3)
G.add_node(4)
G.nodes[4]['name'] = 'FeatureHorizonal'
G.nodes[4]['description'] = '特征处理(横向)'
G.nodes[4]['run'] = hello
G.add_edge(3,4)
G.add_node(5)
G.nodes[5]['name'] = 'ImbalanceSample'
G.nodes[5]['description'] = '不等比采样'
G.nodes[5]['run'] = hello
G.add_edge(4,5)
G.add_node(6)
G.nodes[6]['name'] = 'FeatureVertical'
G.nodes[6]['description'] = '特征处理(纵向)'
G.nodes[6]['run'] = hello
G.add_edge(5,6)
# =======================> 图的绘画
# 获取节点标签属性
node_labels = nx.get_node_attributes(G, "name")
# pos = nx.shell_layout(G)
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=False, node_size=1000, font_size=12, font_color='black', arrows=True)
# 绘制节点标签
_ = nx.draw_networkx_labels(G, pos, labels=node_labels)
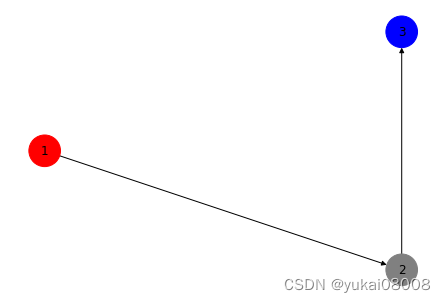
这个画的图不是上面的网络,只是证明可以很容易给不同的节点标色,这个在可视化上很重要。
2.1 BFS
在任何一个子图中,比较重要的就是节点的执行顺序。简单的来说,我们可以认为节点是按层分布的,按照顺序去执行这些层的节点就可以了。所以,首先通过nx实现子图的BFS。
按上面的想法,一个子图中的节点可能是一个节点,也可能是一张子图,但是从执行上,我们可以都当做是节点。只不过在真实执行时,如果对应的节点是子图类型,那么在其内部会再进行展开。对于任何一个子图,总是需要先通过BFS确定内部节点或子图的执行顺序
- 1 在图中选取入度为0的节点,作为第一层
- 2 遍历第一层中的节点,选择以这些节点作为起点的边,边的另一端就是第二层几点
- 3 循环以致图中无节点
# 查看图中节点的入度
G.in_degree()
# 获取入度为 0 的节点列表
nodes_with_in_degree_zero = [node for node, in_degree in G.in_degree() if in_degree == 0]
layer_dict = {}
# 初始化节点
init_node_list = [node for node, in_degree in G.in_degree() if in_degree == 0]
layer_dict[0] = init_node_list
# 节点的入度字典
in_degree_dict = dict(G.in_degree())
all_nodes = set(G.nodes)
travel_nodes = set(init_node_list)
# 迭代节点
for i in range(1,10):
last_layer_nodes = layer_dict[i-1]
layer_dict[i] = []
for last_node in last_layer_nodes:
out_nodes = list(G.successors(last_node))
if len(out_nodes):
for out_node in out_nodes:
out_node_degree = in_degree_dict[out_node]
out_node_degree1 = out_node_degree-1
if out_node_degree1 == 0:
layer_dict[i].append(out_node)
travel_nodes.add(out_node)
else:
in_degree_dict[out_node] = out_node_degree1
gap_set = all_nodes - travel_nodes
if len(gap_set) ==0:
break
# 打印观察
for l in sorted(list(layer_dict.keys())):
# print(l)
for n in layer_dict[l]:
# print(n)
G.nodes[n]['run']()
代码中,构造了一个空的字典,然后选择入度为0的节点作为第0层。然后进行若干次(层)的搜索,每次搜索都遍历上一层的所有节点,假设这个节点为n。
对所有的n,都列出其后续节点,然后遍历到n时进行入度减1处理。当这个后续节点的入度为0时,说明节点所有的依赖都被满足,那么将节点放入本层。
在每层的搜索完成时,都将所有节点减去已遍历完成的节点,如果差集为0,那么中断BFS的继续迭代。
2.2 保存为json
通过nx自带的包,就可以把图的json信息导出,同时也可以通过载入json来恢复这个图。之所以选择json是因为这种格式比较容易通过网络传播,也容易存储在redis或者mongo中。
from networkx.readwrite import json_graph
# 保存图
data = json_graph.node_link_data(G)
3 设计
首先明确这个的设计目标是什么。由于复杂的逻辑处理,以及各种可能性的探索,我希望能够通过这个工具来进行大规模的探索,在合适的时候可以轻易的转入生产服务态,从中受益。
从一般人工智能的角度出发,这个设计要能够支持学习(Learn)与变换(Transform)模式。
从图的角度想象,学习与变换过程的网络是极其相似(重合的),所以可以把图分为两层,底层是相同的变换过程,而上层是学习层,构成变换所需的元数据节点。
在运行时,由最外层的子图负责服务。子图核心会定时的启动轮询。如果是文件模式,那么决定是否进行流通是根据输入输出文件夹的文件差;如果是数据库或者服务模式,那么输入输出就是缓冲数据。
这样input节点的运行状态就是「正常|绿色」,如果是生产态子图就会开始基于已有的BFS开始执行,如果是开发态,子图就会开始BFS然后执行。
每次传播都是基于每一层的节点一次执行,最理想的情况是全部的运行状态都是「正常|绿色」,如果某个节点类型是子图,那么就会下钻到这个子图执行,然后返回。子图节点的状态由其内部节点的运行状态决定(例如有一个红色,那么就该节点就为红色)。所以可视化查看时,也可能需要层层下钻。
整个子图的数据都是可json的,这也意味着节点的方法将以文本的方式声明,存储在一个专门的对象中。同时,在节点运行过程中的数据,也将以共享工作空间的方式挂在某个对象上。
- 1 子图。包含了整个处理所有的相关结构和元数据。
- 2 方法对象。通过名称和参数来声明的处理。
- 3 数据对象。子图的所有共享数据。数据只能在同一子图中共享,如果需要跨子图共享,就需要通过子图的数据入口进行声明与对接。
4 Wrapped Up
本次只是原型设计的一次探索,在短时间内暂时不会真正全面实施,所以到这里进行一个打包。
- 1 封装方法。将BFS的过程抽象为函数。未来这个方法会多次用到,通过BFS,我们确定了合法的节点执行顺序。
# 输入一个nx图,给出BFS层级字典
def BFS(some_G,max_depth = 100):
layer_dict = {}
# 初始化节点
init_node_list = [node for node, in_degree in some_G.in_degree() if in_degree == 0]
layer_dict[0] = init_node_list
# 节点的入度字典
in_degree_dict = dict(some_G.in_degree())
all_nodes = set(some_G.nodes)
travel_nodes = set(init_node_list)
# 迭代节点
for i in range(1,max_depth):
last_layer_nodes = layer_dict[i-1]
layer_dict[i] = []
for last_node in last_layer_nodes:
out_nodes = list(some_G.successors(last_node))
if len(out_nodes):
for out_node in out_nodes:
out_node_degree = in_degree_dict[out_node]
out_node_degree1 = out_node_degree-1
if out_node_degree1 == 0:
layer_dict[i].append(out_node)
travel_nodes.add(out_node)
else:
in_degree_dict[out_node] = out_node_degree1
gap_set = all_nodes - travel_nodes
if len(gap_set) ==0:
break
return layer_dict
BFS(G)
{0: [1, 2], 1: [3], 2: [4], 3: [5], 4: [6]}
可以看到,这个图是一个Y型的结构。 (1,2)->(3)->(4)->(5)->(6)
- 2 三个功能结构。
子图保留的数据全部为可json的状态,包含了图的(多层)结构,学习层学到的元数据节点。
数据对象 将运行中的子图数据进行保存/暂存,在图会话期间,这些数据将以默认的方式进行共享(同一个子图内),或者显示的传递给子图共享。
方法对象 方法对象主要只是借用了对象这种形式,将函数及其参数进行了形式上的剥离,只是将方法统一的绑定在某个对象上。使得所有的操作变得参数形式化,这样容易被智能代理调用。