目录
一. 链表的定义
1.链表的结构.
2.为啥要存在链表及链表的优势.
二. 无头单向链表的常用接口
1.头插\尾插
2.头删\尾删
3.销毁链表/打印链表
4.在pos位置后插入一个值
5.消除pos位置后的值
6.查找链表中的值并且返回它的地址
7.创建一个动态开辟的结点
三.顺序表与链表的优缺点对比.
文章开始->:
一.链表的定义
首先在学习单链表之前我们已近学过顺序表这一数据结构了,我们知道在使用顺序表的时候,当我们空间不够的时候我们需要扩容,还有在我们进行头插和头删的时候我们需要移动元素,这时进行这些操作的时候是非常浪费时间的,并且扩容的时候还有可能浪费一定的空间当然这也是顺序表的缺点,而为了解决这些麻烦我们就弄出来了另外一个数据结构-->(链表)。
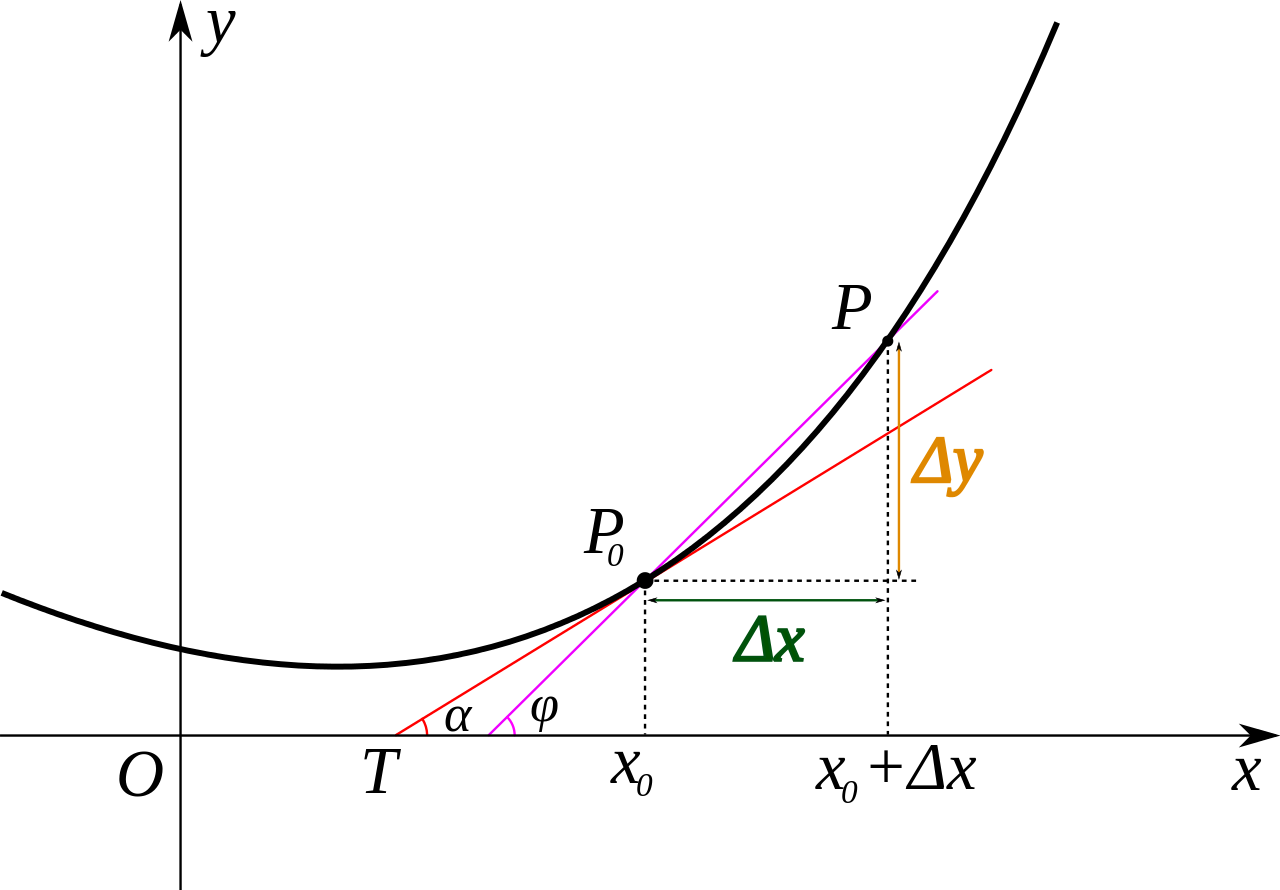
链表的定义:在逻辑结构上元素是连续的,但是实际的物理结构上链表是非连续,非顺序的存储结构,数据元素的逻辑顺序其实是通过指针来连接的。
下面就是正常的逻辑结构

所以链表这种结构可以很简单的解决顺序表的问题,他在管理数据的时候并不需要扩容,而是当我们需要空间的时候他会取开辟一块空间然后我们只需要去改变指针的指向就可以将数据给连接起来了,这也省去了移动元素的时间。
总结单链表的优点:单链表在使用内存空间的时候并不需要想顺序表那样进行扩容,而是我们需要空间的时候会自动去内存中开辟一块空间,也不需要再插入元素的时候移动元素,我们只需要改变指针的指向就可以实现链表逻辑上的顺序管理了。
链表其实最大的好处就是可以进行头插和头删.
下图就是我们插入元素时候的操作:->

这样我们就不需要移动元素只需要改变指针的指向就行了。

接下来就是我们的重点进入常用接口的详细讲解-->
二.无头单链表的常用接口
首先我们要理解的就是无头:所谓的无头就是我们并没有先申请一个结点,而是我们的头指针直接指向了第一个节点,如果链表是空的那么我们我们的头指针指向的是空指针 。
首先我们来看一看链表的结构
在逻辑上-->

在实际上-->
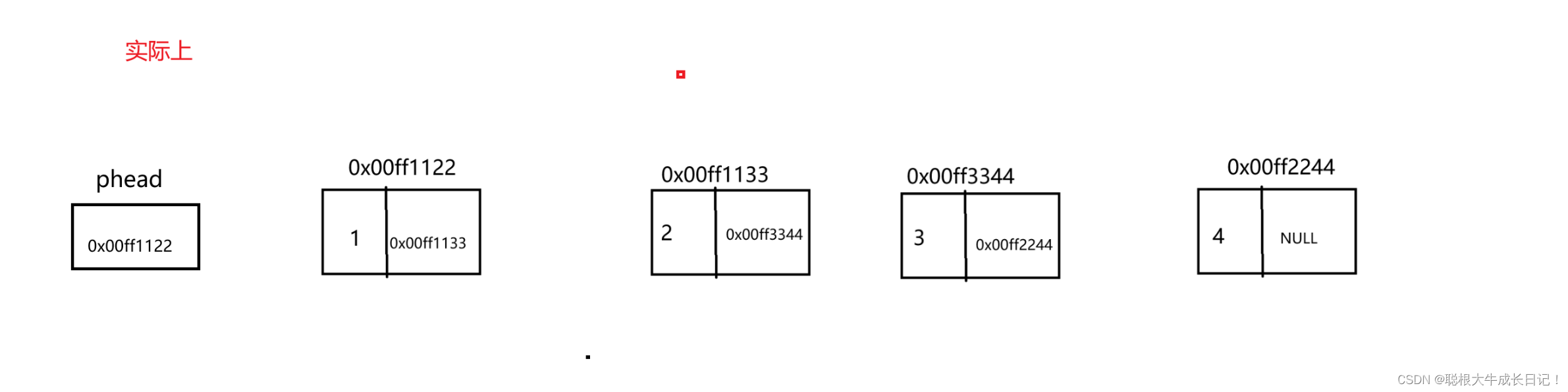
实际上我们内存当中并没有指针指向的说法,只是我们为了方便理解链表这一数据结构而引入进来的。
链表定义的代码如下:
typedef int SlistDataType;
typedef struct Slist
{
struct Slist* next;
SlistDataType data;
}ST;
1.销毁链表/打印链表: 在这里我们要注意就是实参与形参的区别不然我们的操作可能会出现问题,打印的话我们直接遍历就行。
这个接口是必须要有,因为我们在创建链表之前肯定得先有链表这一结构,而销毁链表是为了防止我们程序出现内存泄漏的问题。
销毁链表:因为我们所申请的空间是在堆区上开辟的空间,而堆区上开辟的空间需要我们自己来释放空间,并且链表所开辟的空间并不是一个连续块的空间,所以我们需要来遍历链表这样保证我们将我们所开辟的空间来进行释放完整,防止内存泄漏。
void DestorySlist(STNode* plist)
{
assert(plist);
//这里我们需要一个一个的删除链表的结点
while (plist != NULL)
{
STNode* newplist = plist->next;//存放下一个结点
free(plist);
plist = newplist;
}
}
打印链表:我们只需要遍历到结点为空的情况就行了
下面是打印的代码:
void PrintSlist(STNode* plist)
{
assert(plist);
while (plist != NULL)
{
printf("%d->", plist->data);
plist = plist->next;
}
printf("NULL\n");
}
2.动态开辟一个结点:在我们进行插入有关操作的时候我们需要申请一块空间来存放要插入的值,所以这一步操作也是不能省略的:
我们直接上代码:
STNode* BuySlistNode(SlistDataType x)
{
STNode* newnode = (STNode*)malloc(sizeof(STNode));
//判断开辟的空间成功没
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;//这样设计可以使得我们最后一个结点不需要在进行单独的设空
return newnode;
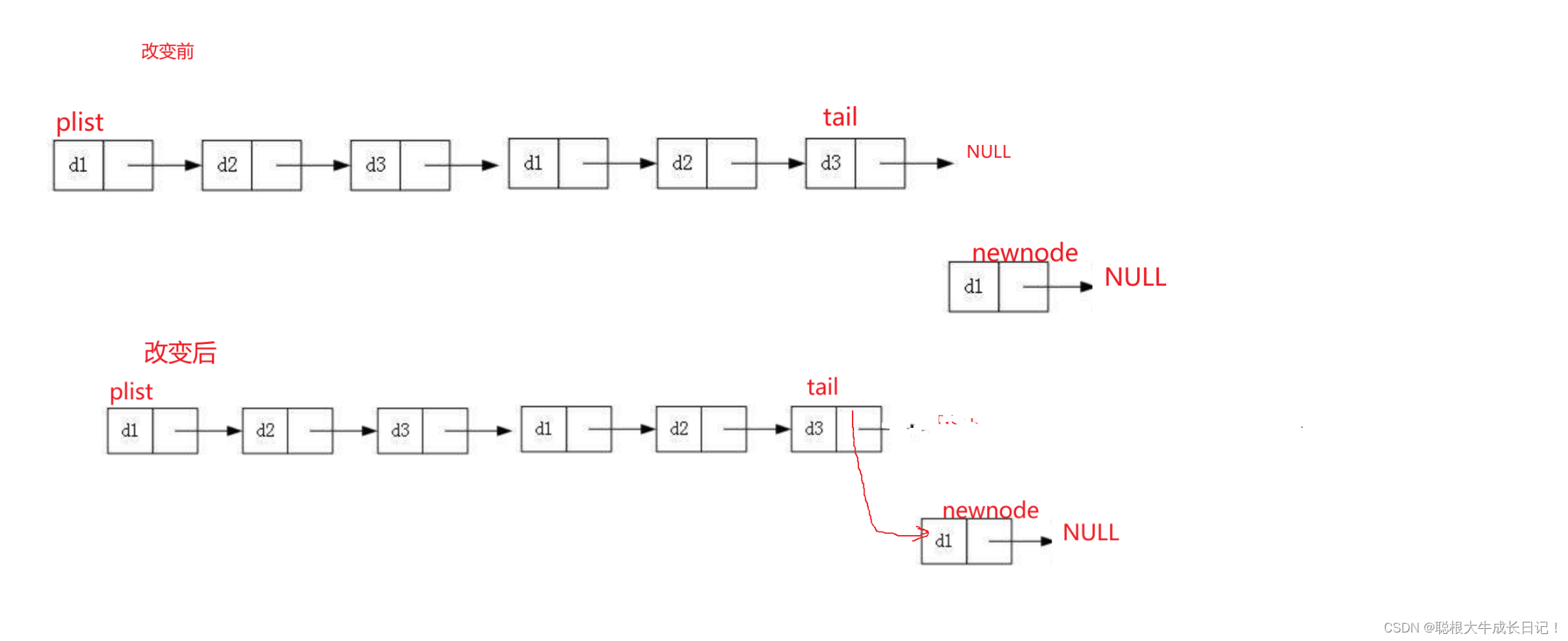
}3.尾插\头插:这里我们需要用到二级指针,因为我们知道改变结构体需要结构体指针,而改变结构体指针,我们需要结构体指针的指针,即二级指针来使用。当我们在进行尾插的第一个插入的时候,我们需要改变结构体指针,所以得用二级指针。,而头插每次都需要改变结构体指针
下面代码:尾插
//注意二级指针
void PushBackSlist(STNode** pplist, SlistDataType x)
{
STNode* newnode = BuySlistNode(x);
if (*pplist == NULL)
{
//插入第一个
*pplist = newnode;
}
else
{
STNode* tail = *pplist;
//我们得先找尾指针
while(tail->next!=NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}尾插的图片:
头插代码:在这里我们需要注意的是在进行改变指针的时我们需要先进行将新节点的next指针先指向头,让后在将头改变,如果反了的话我们会使newnode->next指向自身。
void PushFrontSlist(STNode** pplist, SlistDataType x)
{
STNode* newnode = BuySlistNode(x);
newnode->data = x;
newnode->next = *pplist;
*pplist = newnode;
} 头插图:
4.头删/尾删
头删:我们首先在删除之前判断链表是否为空,如果为空我们就会报错,如果不为空则会继续进行操作,在这里当链表中只有一个结点的时候,那么我们就需要修改结构体指针了。
下面是代码:
void PopFrontSlist(STNode** pplist)
{
//为空
assert(*pplist);
//一个结点
if ((*pplist)->next == NULL)
{
STNode* del = *pplist;
free(del);
*pplist = NULL;
}
//多个结点
else
{
STNode* del = *pplist;
STNode* newnode = (*pplist)->next;
free(del);
*pplist = newnode;
}
}测试时图片:

尾删:这里也要先判断链表是否为空,然后如果只有一个元素我们需要改变结构体指针,其他的我们则只需要将前面一个的指针指向NULL,就行了。
尾删代码:
void PopBackSlist(STNode** pplist)
{
//判断是否为空
assert(*pplist);
//一个结点
if ((*pplist)->next == NULL)
{
STNode* del = *pplist;
free(del);
*pplist = NULL;
}
else
{
STNode* cur = *pplist;
//找前一个
while (cur->next->next != NULL)
{
cur = cur->next;
}
free(cur->next);
cur->next = NULL;
}
}尾删测试:
5.链表的查找接口:如果找到了则返回这个值的地址,如果没找到则打印未找到,思路:我们只需要遍历数组即可。
STNode* FindSlist(STNode* plist, SlistDataType x)
{
assert(plist);
STNode* cur = plist;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
printf("未找到\n");
return NULL;
}
测试:

6.在pos位置后插入,与消除pos位置后的接口
插入:首先我们得判断pos是否有意义,如果有则代表有意义,我们就保存pos位置后的结点,然后pos->next=newnode,newnode->next=posafter;
代码:
void InsertafterSlist( STNode* pos, SlistDataType x)
{
assert(pos);
STNode* posafter = pos->next;
STNode* newnode = BuySlistNode(x);
pos->next = newnode;
newnode->next = posafter;
}测试:
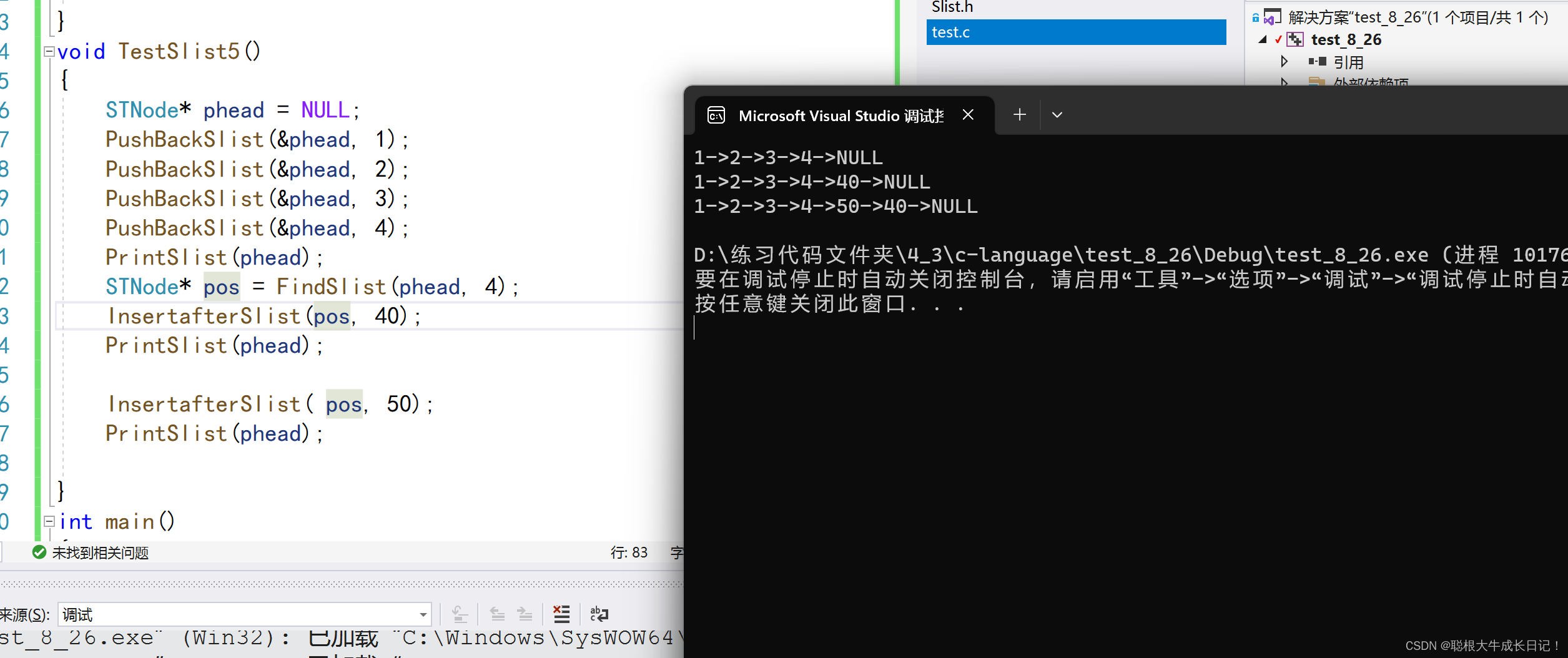
删除pos后面的值:我们先判断pos是否有意义,有意义直接将pos后面的free掉,pos->next=NUll;
代码:
void EraseafterSlist(STNode* pos)
{
assert(pos);
STNode* posafter = pos->next;
pos->next =posafter->next ;
free(posafter);
}
测试图:
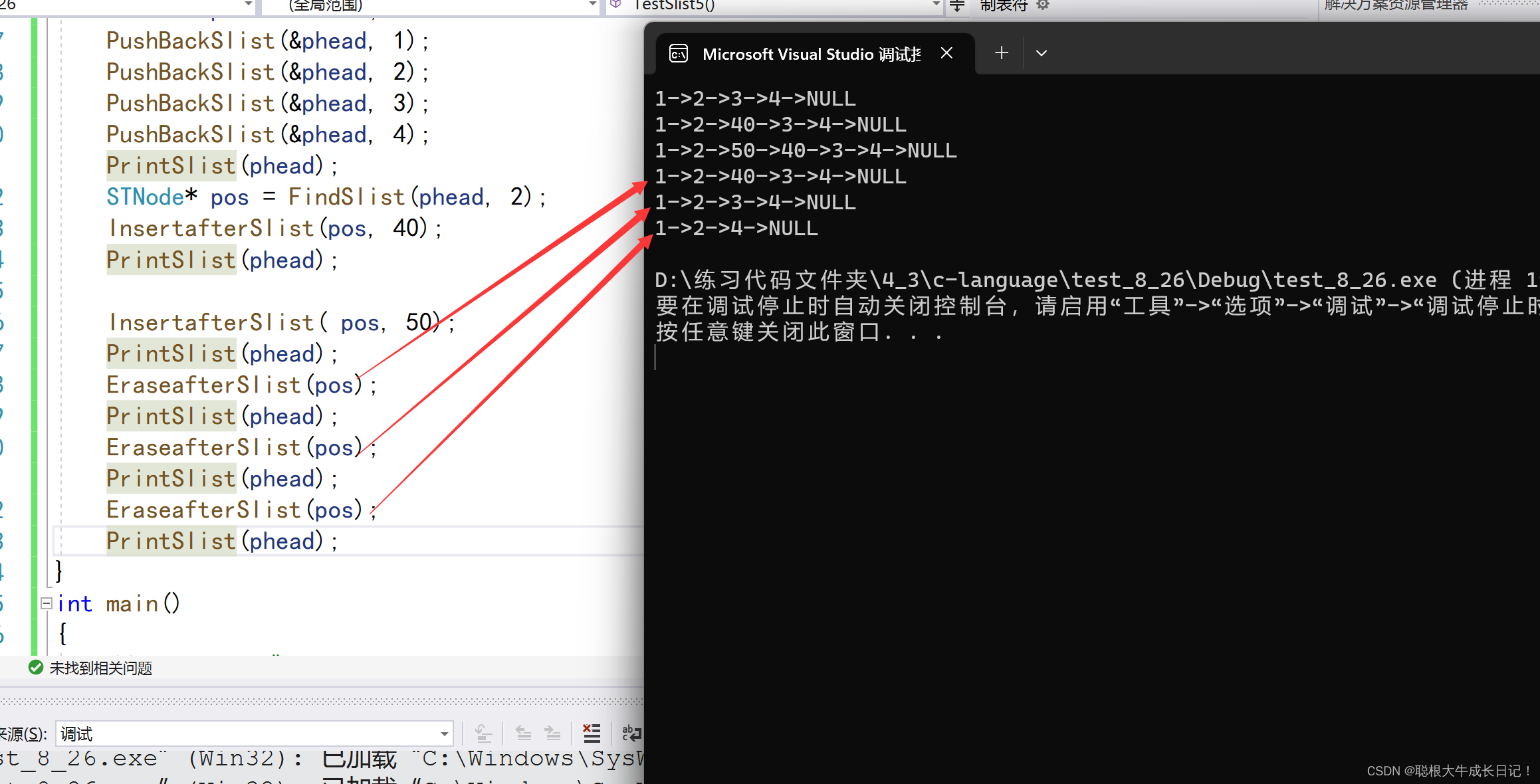
注意:这后面三个接口通常都是一起使用的。
到这里我们常用的接口已近讲解完毕了,接下来进行最后一部分的讲解--->
三:顺序表与链表优缺点对比
顺序表的优点:顺序表可以随机访问开辟空间的地址,且在内存当中是连续的一块空间,,支持随机访问,缓存利用率比较高。
缺点:再进行插入操作的时候需要扩容,而扩容其实底层原理是很麻烦的,这里可以看我前面写过的动态内存开辟的那一张设计realloc扩容,这里就不详细介绍了,且扩容之后还会浪费空间,其次是在进行头删/头插的时候我们需要移动元素,这里会导致很多的空间被持续使用,浪费了大量空间,而且扩容可能扩的非常多,任意插入与删除元素的效率低,时间复杂度为O(n).
顺序表适合频繁访问的场景。
链表的优点:再进行任意位置插入与删除的时候,不需要挪动元素时间复杂度为O(1),也不需要扩容操作,只需新增一个结点就行了,然后改变指针的指向就行了。
缺点:就是不能随机访问内存。且缓存利用率低。
链表适用于任意位置插入与删除的情况。
总而言之:数据结构各有各的优点,也各有各的缺点,这些数据结构适合应用的场景不同而已。
~~本章结束,感谢大家的耐心观看,如果你觉得有用的话,可以点个赞哦!