VAE代码
import torch
from torch import nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, input_dim=784, h_dim=400, z_dim=20): # 28x28=784,20可能是这个手写体一共有20类?
super(VAE, self).__init__()
self.input_dim = input_dim
self.h_dim = h_dim
self.z_dim = z_dim
'''编码器要用到的东西'''
self.fc1 = nn.Linear(input_dim, h_dim) # 第一个全连接层
self.fc2 = nn.Linear(h_dim, z_dim) # mu
self.fc3 = nn.Linear(h_dim, z_dim) # log_var
'''解码器要用到的'''
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, input_dim)
def encoder(self, x):
'''
:param x: image
:return: 均值mu和方差log_var
'''
h = F.relu(self.fc1(x))
mu = self.fc2(h)
log_var = self.fc3(h)
return mu, log_var
def reparameterization(self, mu, log_var):
'''
reparameterization是重新采样的意思,标准正态分布 epsilon~N(0,1)
:param mu:
:param log_var:
:return: 采样的z
'''
sigma = torch.exp(log_var * 0.5)
eps = torch.randn_like(sigma)
return mu + sigma * eps
def decode(self, z):
'''
给出一个采样的z,把它解码回图片
:param z:
:return:
'''
h = F.relu(self.fc4(z))
x_hat = torch.sigmoid(self.fc5(h)) # 图片归一化后的数值为0-1,不能用ReLU
return x_hat
def forward(self, x):
'''
:param x: [batch_size,通道,28,28]
:return:
'''
batch_size = x.shape[0]
# x.shape = [128,1,28,28]
x = x.view(batch_size, self.input_dim) # 把[batch_size,1,28,28]合并成 [batch_size,728]
# 输入图片进行encoder 得到均值和方差
mu, log_var = self.encoder(x)
# 重采样得到潜在变量sampled_z
sampled_z = self.reparameterization(mu, log_var)
# 把采样的潜层变量解码回图片
x_hat = self.decode(sampled_z) # 预测的图片
# 把形状改为 (batch,通道,28,28)
x_hat = x_hat.view(batch_size,1,28,28)
return x_hat, mu, log_var
训练部分代码
import torch
import time
from torch import optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from torchvision.utils import save_image
from VAE import VAE
import matplotlib.pyplot as plt
import argparse
import os
import shutil
import numpy as np
# 设置运行的设备
cuda = torch.cuda.is_available()
device = torch.device("cuda" if cuda else "cpu")
# 设置模型参数
parser = argparse.ArgumentParser(description="Variational Auto-Encoder MNIST Example")
parser.add_argument('--result_dir', type=str, default='./VAEResult', metavar='DIR', help='output directory')
parser.add_argument('--save_dir', type=str, default='./checkPoint', metavar='N', help='model saving directory')
parser.add_argument('--batch_size', type=int, default=128, metavar='N', help='batch size for training(default: 128)')
parser.add_argument('--epochs', type=int, default=200, metavar='N', help='number of epochs to train(default: 200)')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed(default: 1)')
parser.add_argument('--resume', type=str, default='', metavar='PATH', help='path to latest checkpoint(default: None)')
parser.add_argument('--test_every', type=int, default=10, metavar='N', help='test after every epochs')
parser.add_argument('--num_worker', type=int, default=1, metavar='N', help='the number of workers')
parser.add_argument('--lr', type=float, default=1e-3, help='learning rate(default: 0.001)')
parser.add_argument('--z_dim', type=int, default=20, metavar='N', help='the dim of latent variable z(default: 20)')
parser.add_argument('--input_dim', type=int, default=28 * 28, metavar='N', help='input dim(default: 28*28 for MNIST)')
parser.add_argument('--input_channel', type=int, default=1, metavar='N', help='input channel(default: 1 for MNIST)')
args = parser.parse_args()
# 如果cuda为True,那么添加两个键值对,num_workers和pin_memory(详细作用看下面的补充)
kwargs = {'num_workers': 2, 'pin_memory': True} if cuda else {}
def dataloader(batch_size=128,num_workers =2):
# 把图片数据转换为tensor
transform = transforms.Compose([transforms.ToTensor()])
# 下载训练数据后对图片进行transform里的toTensor和用均值方差归一化
mnist_train = datasets.MNIST('../data',
train=True,
transform=transform,
download=True)
mnist_test = datasets.MNIST('../data',
train=False,
transform=transform,
download=True)
mnist_train = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
mnist_test = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=True)
classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9')
return mnist_test, mnist_train, classes
def loss_function(x_hat, x, mu, log_var):
"""
Calculate the loss. Note that the loss includes two parts.
:param x_hat:
:param x:
:param mu:
:param log_var:
:return: total loss, BCE and KLD of our model
"""
# 1. the reconstruction loss.
# We regard the MNIST as binary classification
BCE = F.binary_cross_entropy(x_hat, x, reduction='sum')
# 2. KL-divergence
# D_KL(Q(z|X) || P(z)); calculate in closed form as both dist. are Gaussian
# here we assume that \Sigma is a diagonal matrix, so as to simplify the computation
KLD = 0.5 * torch.sum(torch.exp(log_var) + torch.pow(mu, 2) - 1. - log_var)
# 3. total loss
loss = BCE + KLD
return loss, BCE, KLD
def save_checkpoint(state,is_best,outdir):
'''
每当训练一定的epochs后,判断损失函数的值是不是最小的 并保存模型的参数
:param state: 要保存的模型参数,类型为dict
:param is_best: 是否为当前最优
:param outdir: 保存的文件夹
:return:
'''
if not os.path.exists(outdir):
os.makedirs(outdir)
checkpoint_file = os.path.join(outdir,'checkpoint.pth') # 把checkpoint.pth保存在outdir中
best_file = os.path.join(outdir,'model_best.pth')
torch.save(state,checkpoint_file)
if is_best:
# 如果是最优的参数,则把checkpoint_file复制为best_file
shutil.copyfile(checkpoint_file,best_file)
def test(model,optimizer,mnist_test,epoch,best_test_loss):
test_avg_loss = 0.0
with torch.no_grad(): # 测试时不计算梯度
for test_batch_index,(test_x,_) in enumerate(mnist_test):
test_x = test_x.to(device)
# 前向传播
test_x_hat,test_mu,test_log_var = model(test_x)
# 计算损失函数
test_loss,test_BCE,test_KID = loss_function(test_x_hat,test_x,test_mu,test_log_var)
test_avg_loss += test_loss
# 对和求平均值,得到每一张图片的平均损失
test_avg_loss /=len(mnist_test.dataset)
'''测试随机生成的隐变量'''
# 在正态分布中随机采样一个个数为batch_size,形状为z_dim的隐变量
z = torch.randn(args.batch_size,args.z_dim).to(device)
# 把隐变量输入到解码器生成图片
random_res = model.decode(z).view(-1,1,28,28)
# 保存生成的图片
save_image(random_res,'./%s/random_sampled-%d.png'%(args.result_dir,epoch+1))
'''保存目前训练好的模型'''
is_best = test_avg_loss < best_test_loss
best_test_loss = min(test_avg_loss,best_test_loss)
save_checkpoint({
'epoch':epoch,
'best_test_loss':best_test_loss,
'state_dict':model.state_dict(),
'optimizer':optimizer.state_dict(),
},is_best,args.save_dir)
return best_test_loss
def train():
# Step 1: 载入数据
mnist_test, mnist_train, classes = dataloader(args.batch_size, args.num_worker)
# 查看每一个batch图片的规模
x, label = iter(mnist_train).__next__() # 取出第一批(batch)训练所用的数据集
print(' img : ', x.shape) # img : torch.Size([batch_size, 1, 28, 28]), 每次迭代获取batch_size张图片,每张图大小为(1,28,28)
# Step 2: 准备工作 : 搭建计算流程
model = VAE(z_dim=args.z_dim).to(device) # 定义VAE模型,并转移到GPU上去
print('The structure of our model is shown below: \n')
print(model)
optimizer = optim.Adam(model.parameters(), lr=args.lr) # 生成优化器,需要优化的是model的参数,学习率为0.001
# Step 3: 选择是否加载保存的参数
start_epoch = 0
best_test_loss = np.finfo('f').max
if args.resume:
if os.path.isfile(args.resume):
# 载入已经训练过的模型参数与结果
print('=> loading checkpoint %s' % args.resume)
checkpoint = torch.load(args.resume)
start_epoch = checkpoint['epoch'] + 1
best_test_loss = checkpoint['best_test_loss']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print('=> loaded checkpoint %s' % args.resume)
else:
print('=> no checkpoint found at %s' % args.resume)
if not os.path.exists(args.result_dir):
os.makedirs(args.result_dir)
# Step 4: 开始训练
loss_epoch = []
for epoch in range(start_epoch, args.epochs):
# 训练模型
# 每一代都要遍历所有的批次
loss_batch = []
for batch_index, (x, _) in enumerate(mnist_train):
# x : [b, 1, 28, 28], remember to deploy the input on GPU
x = x.to(device)
# 前向传播
x_hat, mu, log_var = model(x) # 模型的输出,在这里会自动调用model中的forward函数
loss, BCE, KLD = loss_function(x_hat, x, mu, log_var) # 计算损失值,即目标函数
loss_batch.append(loss.item()) # loss是Tensor类型
# 反向传播
optimizer.zero_grad() # 梯度清零,否则上一步的梯度仍会存在
loss.backward() # 后向传播计算梯度,这些梯度会保存在model.parameters里面
optimizer.step() # 更新梯度,这一步与上一步主要是根据model.parameters联系起来了
# 每100个epoch打印一次
if (batch_index + 1) % 100 == 0:
print('Epoch [{}/{}], Batch [{}/{}] : Total-loss = {:.4f}, BCE-Loss = {:.4f}, KLD-loss = {:.4f}'
.format(epoch + 1, args.epochs, batch_index + 1, len(mnist_train.dataset) // args.batch_size,
loss.item() / args.batch_size, BCE.item() / args.batch_size,
KLD.item() / args.batch_size))
if batch_index == 0:
# visualize reconstructed result at the beginning of each epoch
x_concat = torch.cat([x.view(-1, 1, 28, 28), x_hat.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, './%s/reconstructed-%d.png' % (args.result_dir, epoch + 1))
# 把这一个epoch的每一个样本的平均损失存起来
loss_epoch.append(np.sum(loss_batch) / len(mnist_train.dataset)) # len(mnist_train.dataset)为样本个数
# 测试模型
if (epoch + 1) % args.test_every == 0:
best_test_loss = test(model, optimizer, mnist_test, epoch, best_test_loss)
return loss_epoch
if __name__ == '__main__':
'''开始计时'''
start_time = time.time()
'''开始训练'''
loss_epoch = train()
'''计时结束'''
end_time = time.time()
run_time = end_time - start_time
# 将输出的秒数保留两位小数
if int(run_time) < 60:
print(f'{round(run_time, 2)}s')
else:
print(f'{round(run_time / 60, 2)}minutes')
# 绘制迭代结果
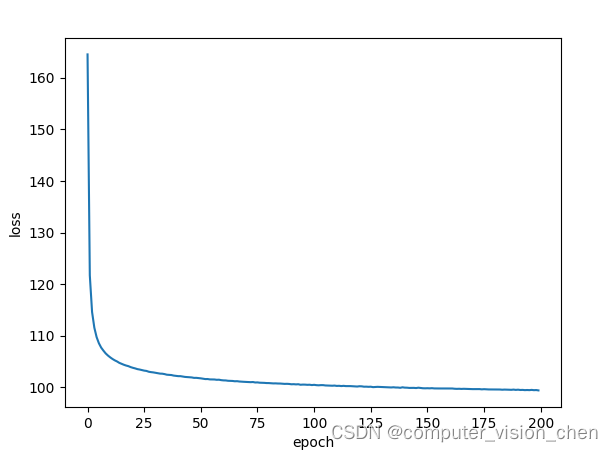
plt.plot(loss_epoch)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
补充
VAE不能用transforms.Normalize(0.5,0.5)进行归一化,否则Loss直接变成负数,loss要最小化,会变成越来越小的负数
F.relu(self.fc1(x))和nn.ReLU(self.fc1(x))有什么区别?
F.relu(self.fc1(x))和nn.ReLU(self.fc1(x))在功能上是相同的,都是使用ReLU(Rectified Linear Unit)作为激活函数来处理self.fc1(x)的结果。它们之间的区别在于调用方式和所属的模块。
F.relu()是PyTorch中torch.nn.functional模块中的一个函数,用于实现激活函数ReLU。这个函数是独立于任何特定的神经网络层的,你可以直接调用它来对张量进行ReLU操作。
nn.ReLU()是PyTorch中torch.nn模块中的一个类,用于构建ReLU激活函数的实例。通过将nn.ReLU()作为一个层添加到神经网络模型中,你可以在模型的前向传播过程中应用ReLU激活函数。
综上所述,F.relu(self.fc1(x))是直接调用了ReLU激活函数功能,而nn.ReLU(self.fc1(x))是通过在神经网络模型中添加一个ReLU层来实现激活函数的功能。
pin_memory参数的作用
pin_memory参数在PyTorch中用于数据加载过程中,特别是在使用GPU进行训练时。当设置pin_memory=True时,数据会被加载到主机(Host)的固定内存区域中,而不是被加载到默认的分页内存(Paged Memory)。这样做的目的是为了将数据从主机内存快速传输到GPU内存,以提高数据加载的效率。
在训练过程中,GPU通常需要频繁地从主机内存中读取数据。如果数据未锁定(pinned)并且位于分页内存中,GPU访问主机内存的速度可能会相对较慢。而将数据锁定在主机内存中,可以避免数据在传输过程中被分页,提高了数据传输的效率,从而减少了数据加载到GPU的时间。
需要注意的是,使用pin_memory=True会占用更多的主机内存资源,因此只有在确实需要提高数据加载效率的情况下才建议使用该参数。