目录
内存模型分类
堆和栈的区别
C++中new的工作过程
堆和栈的区别
为什么堆区要比栈区大
内存模型分类


- 文本段(ELF)(数据区):主要用于存放我们编写的代码,但是不是按照代码文本的形式存放,而是将代码文本编译成二进制代码,存放的是二进制代码,在编译时就已经确定这个区域存放的内容是什么了,并且这个区域是只读区域;
- DATA段(初始化静态区,常量区):这个区域主要用于存放编译阶段(非运行阶段时)就能确定的数据,也就是初始化的静态变量、全局变量和常量,这个区域是可读可写的。这也就是我们通常说的静态存储区;
- BSS段(静态区):这个区域存放的是未曾初始化的静态变量、全局变量,但是不会存放常量,因为常量在定义的时候就一定会赋值了。未初始化的全局变量和静态变量,编译器在编译阶段都会将其默认为0;
- HEAP(堆):这个区域实在运行时使用的,主要是用来存放程序员分配和释放内存,程序结束时操作系统会对其进行回收,(程序员分配内存像malloc、free、new、delete)都是在这个区域进行的;
- STACK(栈):存放函数的参数值和局部变量,这个区域的数据是由编译器来自己分配和释放的,只要执行完这个函数,那么这些参数值和变量都会被释放掉;
- 内核空间(env)环境变量:这个区域是系统内部的区域,我们是不可编辑的;
堆和栈的区别
C++中new的工作过程
申请的是普通的内置类型的空间:
(1)调用 C++标准库中 operator new函数,传入大小。(如果申请的是0byte则强制转化成1byte)
(2)申请相对应的空间,如果没有足够的空间或其他问题且没有定义_new_hanlder,那么会抛出bad_alloc的异常并结束程序,如果定义了_new_hanlder回调函数,那么会一直不停的调用这个函数直到问题被解决为止
(3)返回申请到的内存的首地址.
申请的是类空间:
(1)如果是申请的是0byte,强制转换为1byte
(2)申请相对应的空间,如果没有足够的空间或其他问题且没有定义_new_hanlder,那么会抛出bad_alloc的异常并结束程序
(3)如果定义了_new_hanlder回调函数,那么会一直不停的调用这个函数直到问题被解决为止。
(4)如果这个类没有定义任何构造函数,析构函数,且编译器没有合成,那么下面的步骤跟申请普通的内置类型是一样的。
(5)如果有构造函数或者析构函数,那么会调用一个库函数,具体什么库函数依编译器不同而不同,这个库函数会回调类的构造函数。
(6)如果在构造函数中发生异常,那么会释放刚刚申请的空间并返回异常
(7)返回申请到的内存的首地址
delete 与new相反,会先调用析构函数再去释放内存(delete 实际调用 operator delete)
operator new[]的形参是 sizeof(T)*N+4就是总大小加上一个4(用来保存个数);空间中前四个字节保存填充长度。然后执行N次operator new
operator delete[] 类似;
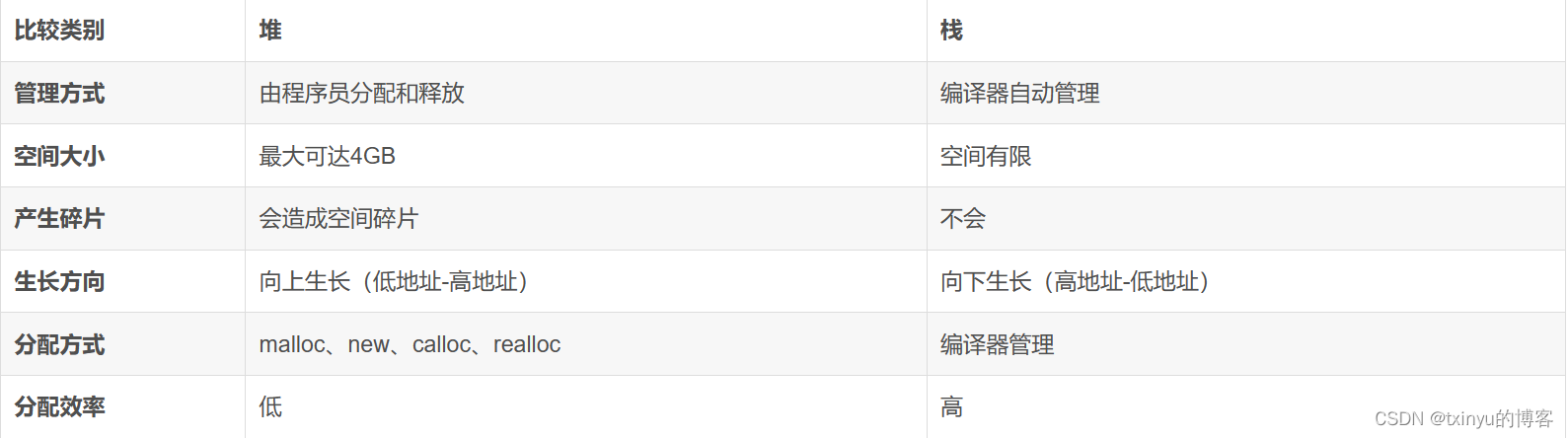
堆和栈的区别
全局数据区存放静态数据、全局变量、常量。
代码区存放所有类成员函数和非成员函数的代码。
栈区存放用于函数的返回地址、形参、局部变量、返回类型。
堆区存放余下的内存(new和delete)。
- 申请方式不同:栈是系统自动分配,堆是程序员申请。
- 系统响应不同:
- 栈:只要栈的剩余空间大于所申请的空间,系统就会为程序提供内存,否则栈溢出。
- 堆:系统收到申请空间的请求后,会遍历一个操作系统用于记录内存空闲地址的链表,当找到一个空间大于所申请空间的堆结点后,就会为该结点从记录内存空闲地址的链表中删除,并将该结点的内存分配给程序,然后在这块内存区域的首地址处记录分配的大小,这样我们在使用delete来释放内存的时候,delete才能正确地识别并删除该内存区域的所有变量。另外,我们申请的内存空间与堆结点的内存空间不一定相等,这是系统会自动将堆结点上多出来的那部分内存空间回收到空闲链表中。空间大小不同:栈是一块连续的区域,大小一般是1~2M;堆是不连续的区域,空间很大,上限取决于有效的虚拟内存。
- 碎片问题:栈是后进先出的队列,内存是连续的,而堆则在多次的new和delete后会产生很多碎片。
- 生长方向:栈是向下,堆是向上。
- 分配方式:堆是动态分配,没有静态分配。栈是静态分配和动态分配,静态分配由编译器完成,例如局部变量的内存分配;动态分配则由alloca函数分配,不同于堆的手工释放,它的分配是完全由编译器自动释放。
- 分配效率:栈是系统的底层数据结构,由专门的寄存器存放栈的地址,专门指令执行压栈出栈,这就决定了栈的效率比较高。而堆是C++函数库提供的,机制复杂,效率低。
为什么堆区要比栈区大
堆干很多事情例如在new一个对象的时候就在堆内存中分配的,那么堆内存是如何管理的呢?堆内存空余内存地址是一个链表的结构存储的,当一个程序请求过来的时候(此时所需的内存大小已经计算好),就会开始遍历这个链表找个比这个程序所需内存大的节点用来给你程序执行所用,此时就会在链表的节点上删除这个即将被占用的内存节点,因为new对象的这个过程是比较缓慢的而且链表上的每个节点内存大小也是不确定的所以就会产生内存碎片,不过用起来非常方便。