【简单题】(暴力遍历法很简单)但是时间复杂度很高,n的立方级别了。。。
代码:
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
vector<int> ans; // 存放结果
for (int i = 0; i < nums1.size(); i++) {
int t = nums1[i]; // 暂存要查找的值
for (int j = 0; j < nums2.size(); j++) { // 在nums2中找与t相等的值
if (nums2[j] == t) { // 如果找到相等的值,就往后找第一个比他大的
int k;
for (k = j + 1; k < nums2.size(); k++) {
if (nums2[k] > t) { // 找到第一个比它大的元素,压入该元素入栈
ans.push_back(nums2[k]);
break;
}
}
if (k == nums2.size()) { // 遍历完nums2数组,没有找到比它大的元素。压入 -1 入栈
ans.push_back(-1);
}
}
}
}
return ans;
}
};运行结果:

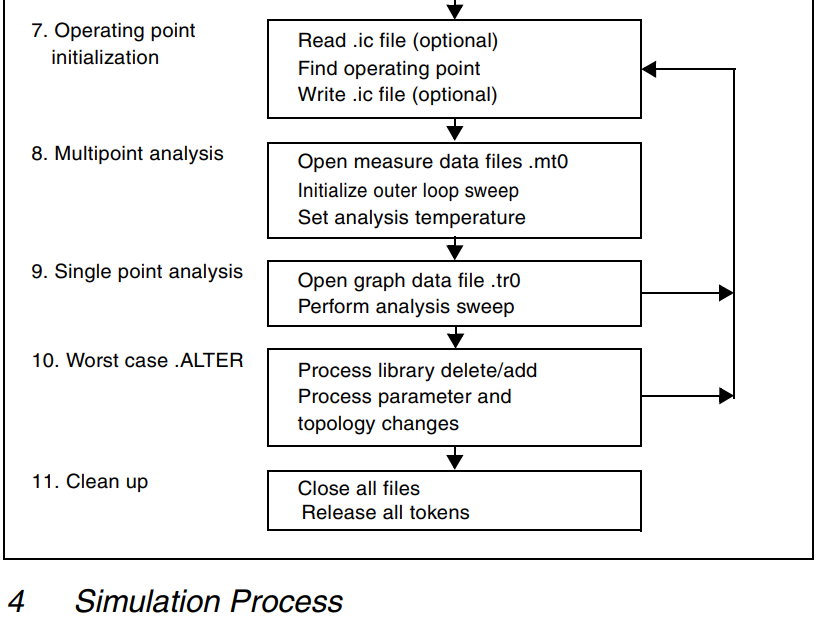
进阶方法:
进阶:你可以设计一个时间复杂度为 O(nums1.length + nums2.length) 的解决方案吗?
答案思路:【单调栈】
怎么样才能使得 用 nums1中的元素去 nums2中查找的时候,能够很快的不用遍历就可以查到第一个比它大的元素呢?
先预处理 num2,使得对于他的每个元素,用一个哈希表来存储第一个比他大的元素的映射。
步骤(参考leetcode官方题解)

遍历完之后 hashmap 中存储的键值对如下所示:

自己的话总结:
从后往前遍历(当前值为t),如果栈中的值比 t 小,则出栈到没有比它小 或 栈空位置。然后设置哈希映射,键为 t,值为 栈顶元素。然后将该元素入栈。直到遍历完第一个元素。
这样,对于 nums2中的每一个元素,在hashmap中都存储了 第一个比他大的元素 的映射。
注意:
使用 unordered_map 时,要引入库文件:#include <unordered_map>
代码:
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int, int> mp; // 设置哈希表
stack<int> st; // 栈
for (int i = nums2.size() - 1; i >= 0; i--) { // 从后往前遍历 nums2
int t = nums2[i];
while (!st.empty() && t > st.top()) // 如果栈非空的条件下,当前值 > 栈顶元素,就出栈
st.pop();
if (st.empty()) { // 如果栈为空,说明在该数组中,该元素没有第一个比它大的元素,设置它的映射值为 -1
mp[t] = -1;
}
else {
mp[t] = st.top(); // 如果栈非空,那么该元素的哈希映射值为 栈顶元素。
}
st.push(t);
}
vector<int> ans;
for (int i = 0; i < nums1.size(); i++) {
ans.push_back(mp[nums1[i]]);
}
return ans;
}
};