目录
一、字符集概念
1、字符(Character)
2、字符编码
3、字符集(Character set)
二、字符集原理
1、ASCII字符集
2、GB2312
3、GBK
4、GB18030
5、BIG5
6、Unicode 编码
三、字符序
四、MySQL字符集 & 字符序
1、mysql 字符集
2、mysql 字符序
3、字符集与字符序的关系
五、MySQL 数据存储字符集 | 数据库内部操作字符集
1. 字符集层级关系
2、如何设置字符集
2.1 服务器字符集设置
2.2 数据库字符集设置
2.3 数据表字符集设置
2.4 字段字符集设置
3、多级的字符集 & 多种字符集的作用
六、MySQL 客户端与服务端交互字符集 | 数据库外部字符集
1、客户端与服务端的交互
2、如何设置字符集
我们在使用 MySQL 的过程中,经常会碰到诸如乱码之类的问题。字符编码与字符集密切相关,MySQL 支持种类繁多的字符集类型,这些字符集到底如何影响 MySQL 数据存储与数据传输的呢?我们该如何选择正确的字符集:character_set_client、character_set_connection 和 character_set_results?那就通过这篇文章来帮你捋清个中细节和解除困扰吧!
本文依赖以下环境:
操作系统:MAC OS 10.11.6
MySQL:Server version: 5.6.21 MySQL Community Server (GPL)
一、字符集概念
1、字符(Character)
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字、😀(emoji表情)等属于字符的范畴。
2、字符编码
计算机是通过 BIT 来存储数据的,将人类可识别的字符转换成计算机能够存储的形式,这个过程就是字符编码。
3、字符集(Character set)
字符集是多个字符的集合,包含一组字符以及对应的编码方式。字符集种类较多,每个字符集包含的字符个数和编码方式不同,常见字符集名称:ASCII 字符集、GB2312 字符集、BIG5 字符集、 GB18030 字符集、Unicode 字符集等。
二、字符集原理
1、ASCII字符集
我们熟知的 ASCII 字符集是一种现代美国英语适用的字符集。包括的字符有数字、大小写字母、分号、换行之类的符号,编码方式是用一个 7bit 表示一个字符,例如A的编码是 65,b 的编码是 98。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,主要编码表如下图所示。
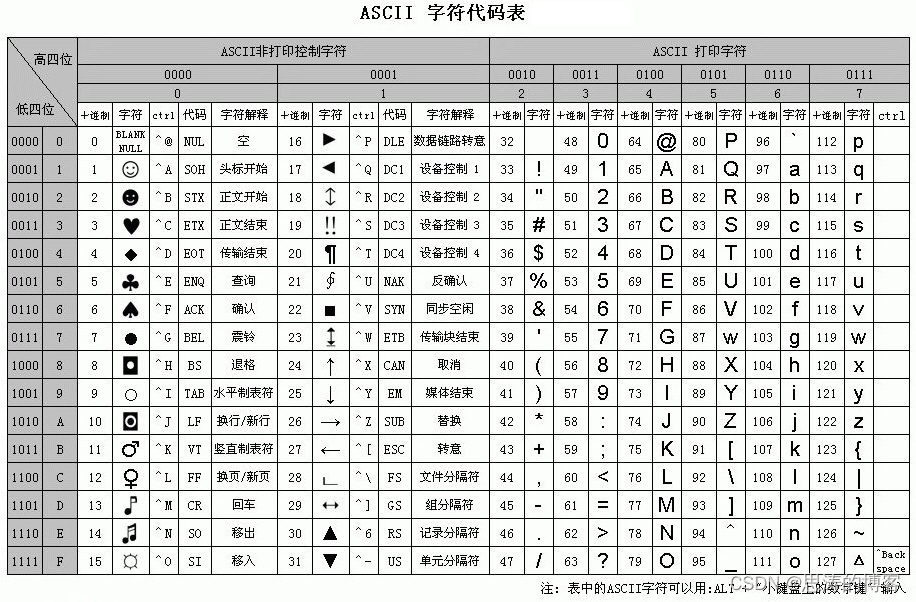
2、GB2312
GB2312 字符集是一种对汉字比较友好的字符集,共收录 6700 多个汉字,基本涵盖了绝大部分常用汉字。不过,GB2312 字符集不支持绝大部分的生僻字和繁体字。对于英语字符,GB2312 编码和 ASCII 码是相同的,1 字节编码即可。对于非英字符,需要 2 字节编码。
3、GBK
GBK 字符集可以看作是 GB2312 字符集的扩展,兼容 GB2312 字符集,共收录了 20000 多个汉字。GBK 中 K 是汉语拼音 Kuo Zhan(扩展)中的 “Kuo” 的首字母。
4、GB18030
GB18030 完全兼容 GB2312 和 GBK 字符集,纳入中国国内少数民族的文字,且收录了日韩汉字,是目前为止最全面的汉字字符集,共收录汉字 70000 多个。
5、BIG5
BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
6、Unicode 编码
ASCII 只对英文符号和英文字母做了编码,GB2312对英文符号,英文字母,汉字做了编码。每个国家为了更加适合本国语言,都有一套自己的字符集。不同的字符集可以表示的字符范围以及编码规则存在差异。同一个编码,对于不同的字符集来说就可能代表不同的字符:

这就导致了一个非常严重的问题:使用错误的编码方式查看一个包含字符的文件就会产生乱码现象。就比如说你使用 UTF-8 编码方式打开 GB2312 编码格式的文件就会出现乱码。示例:“牛”这个汉字 GB2312 编码后的十六进制数值为 “C5A3”,而 “C5A3” 用 UTF-8 解码之后得到的却是 “ţ”。
为了解决不同语言编码之间不兼容的问题,Unicode 出现了。Unicode 字符集致力于为全世界每一个语言的每一个字符都有统一且唯一的编码,Unicode 字符序号的范围是 0x000000 到0x10FFFF,可以容纳 110 多万个字符。UTF8、UTF16、UTF32 是 Unicode 编码的不同实现方式:
- UTF-8 使用 1 到 4 个字节为每个字符编码, UTF-16 使用 2 或 4 个字节为每个字符编码,UTF-32 固定位 4 个字节为每个字符编码。
- UTF-8 可以根据不同的符号自动选择编码的长短,像英文字符只需要 1 个字节就够了,这一点 ASCII 字符集一样 。因此,对于英语字符,UTF-8 编码和 ASCII 码是相同的。
- UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这类字符消耗的空间是 UTF-8 的 4 倍之多。
三、字符序
一个字符集中有多个字符,那么如何对其中的字符进行排序呢?这就是字符序。简单来说,字符序就是字符排序的规则集合。
一个字符集中有多个字符,那么如何对其中的字符进行排序呢?这就是字符序。比如一个字符集有下面几个字符以及字符编码:

我们可以直接按照 A > B > a > b 的规则来进行排序,这就是这个简单字符集的一个字符序。如果想让小写字母放在前面,比如 a > b > A > B,这又是一种字符序。如果还想加上大小写无关或大小写相关,这就产生了不同的字符序。
四、MySQL字符集 & 字符序
接下来我们来看看 MySQL 的字符集与字符序。MySQL 目前支持多种字符集,支持在不同的字符集之间转换(便于移植和支持多语言)。
1、mysql 字符集
通过命令: mysql -u[username] -p[password] 连接上MySQL后,用下面命令查询MySQL 支持的字符集:
SHOW CHARACTER SET;结果:
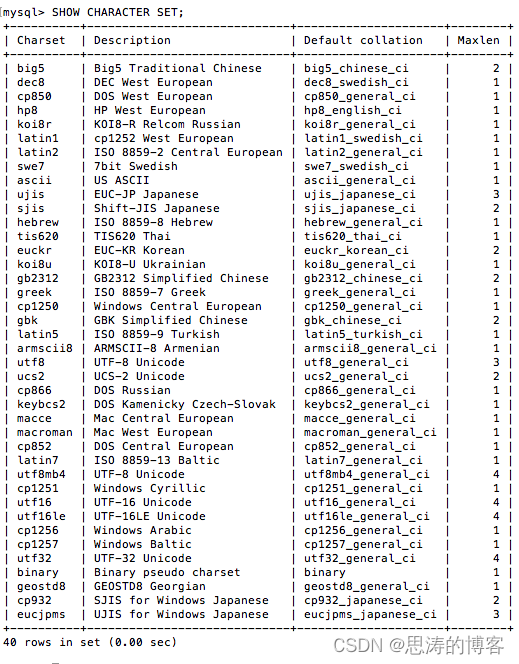
指定条件查询:
SHOW CHARACTER SET LIKE 'utf%';结果:

字段含义:
- Charset: 字符集的名称;
- Description:字符集的简单描述;
- Default collation:该字符集的默认字符序;
- Maxlen:该字符集中字符最大存储长度。
2、mysql 字符序
每个字符集都对应一个或多个字符序,可以通过下面的语句查看所有的字符序:
SHOW COLLATION;结果(部分展示):
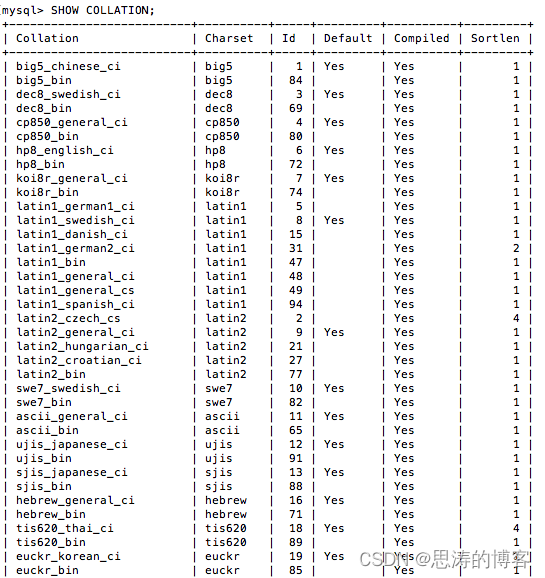
指定条件查询:
SHOW COLLATION WHERE Charset = 'utf8mb4';结果:

字段含义:
- Collation:字符序名称;
- Charset:该字符序关联的字符集;
- Id:字符序ID;
- Default:该字符序是否是所关联的字符集的默认字符序。比armscii8_general_ci就是armscii8的默认字符序,而armscii8_bin就不是;
- Compiled:字符集是否已编译到服务器中;
- Sortlen:这与对以字符集表示的字符串进行排序所需的内存量有关;
- Pad_attribute:这表明了字符序在比较字符串时对末尾padding的处理。NO PAD表明在比较字符串时,末尾的padding也会考虑进去,否则不考虑。
每个字符序都是以该字符序所关联的字符集为前缀的,同时还有一些有规律的后缀:
- bin:二进制;
- ci:大小写不敏感;
- cs:大小写敏感;
- ai:口音(Accent)不敏感;
- as:口音敏感;
- ks:假名(Kanatype)敏感。
同时有的字符序是面向某种语言的,也会在字符序名字中有所体现,比如big5_chinese_ci。
3、字符集与字符序的关系
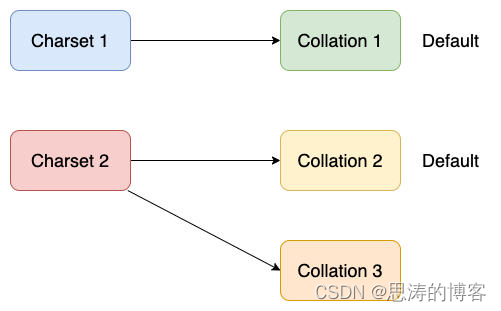
字符集与字符序的关系可以上面的图来表示:
- 每个字符集都有一个或多个字符序;
- 每个字符集都有一个默认的字符序;
- 每个字符序都关联一个且只有一个字符集;
- 两个不同的字符集没有相同的字符序。
五、MySQL 数据存储字符集 | 数据库内部操作字符集
1. 字符集层级关系
MySQL 是按层级来设定字符集与字符序的,MySQL 可以设置:服务器级字符集、数据库级字符集、数据表级字符集、表列级别字符集。实际上,最终使用字符集的地方是存储字符的列,它决定了数据库中存储的数据采用哪个字符集的编码和字符序。
结构图:

层级图:

如上图所示:
上一层级如果没有指定字符集与字符序,就采用下一层级的字符集与字符序。也就是说:新建数据库时没有指定字符集,就默认设置为服务器的字符集;如果新建数据表时没有指定字符集,就默认设置为数据库的字符集;如果向数据表添加新列时没有指定列的字符集,那么这些列就默认设置为数据表的字符集。与字符集相同,如果不特别指定,字符序也采取了默认值继承的方式。
另一方面,直接改变这四个层次的编码并不会改变它们各自所有下层对象的当前编码。比如修改 Server 级,那么所有已经存在的数据库、数据表、表、列的字符集都不会发生改变。同样,修改某个字段的字符集,该字段下每一条现有记录的字符仍然按原来的编码存储。
2、如何设置字符集
我们先来看下,MySQL 刚安装完,MySQL 字符集的的初始字符集和字符序是什么?
查看字符集变量:
SHOW VARIABLES LIKE 'character_set\_%';查看字符序变量:
SHOW VARIABLES LIKE '%collation%';查询结果:

character_set_server:服务器的字符集是 latin1
collation_server: 服务器的字符序是 latin1_swedish_ci
character_set_database:数据库的字符集是 latin1
collation_database:数据库的字符序是 latin1_swedish_ci
从上图可以看出,MySQL 服务器安装后已经初始化了服务器和数据库的默认字符集和字符序,那么,默认的配置从何而来呢?
- 编译MySQL 时,指定了一个默认的字符集,这个字符集是 latin1,MySQL 8.0 以后默认值应是 utf8mb4;
- 安装MySQL 时,可以在配置文件 (myconf | my.ini) 中指定一个默认的的字符集,如果没指定,这个值继承自编译时指定的;
- 启动mysqld 时,可以在命令行参数中指定一个默认的的字符集,如果没指定,这个值继承自配置文件中的配置,此时 character_set_server 被设定为这个默认的字符集。
另外,我们在创建数据库、表、添加字段时,都可以默认采用上一级的字符集和字符序,也可以在创建时自行指定。
2.1 服务器字符集设置
通过 character_set_server 变量的设定字符集的几个方式:
方式 1:在 my.cnf | my.ini 中配置
[mysqld]
character-set-server=utf8方式 2:启动时配置参数
mysqld --charater-set-server=utf8方式 3:编译时指定
[root@database-one ~]# cmake . -DDEFAULT_CHARSET=utf82.2 数据库字符集设置
// -- 示例: 创建数据库
create database if not exists dbtest character set utf8;
// -- 示例:修改数据库
ALTER DATABASE dbtest CHARACTER SET 'utf8';2.3 数据表字符集设置
// -- 创建表时:DEFAULT CHARSET=utf8mb4 设置字符集
CREATE TABLE `t_employee` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '员工ID',
`code` varchar(10) NOT NULL COMMENT '员工编码',
`name` varchar(10) NOT NULL COMMENT '员工姓名',
`age` int(10) unsigned DEFAULT NULL COMMENT '年龄',
`sex` int(10) unsigned DEFAULT NULL COMMENT '性别',
`cert_type` int(10) unsigned DEFAULT NULL COMMENT '证件类型',
`cert_no` varchar(20) DEFAULT NULL COMMENT '证件号',
`birthday` date DEFAULT NULL COMMENT '生日',
`income_date` date DEFAULT NULL COMMENT '入职日期',
PRIMARY KEY (`id`),
UNIQUE KEY `code` (`code`),
UNIQUE KEY `cert_type` (`cert_type`,`cert_no`)
) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8mb4 COMMENT='员工表';
// -- 修改表的字符集
ALTER TABLE `dbtest`.`t_employee` CHARACTER SET = utf8mb4;
2.4 字段字符集设置
// -- 创建表时:CHARACTER SET utf8mb4指定字段字符集
CREATE TABLE `t_employee` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '员工ID',
`code` varchar(10) NOT NULL COMMENT '员工编码',
`name` varchar(10) NOT NULL COMMENT '员工姓名',
`age` int(10) unsigned DEFAULT NULL COMMENT '年龄',
`sex` int(10) unsigned DEFAULT NULL COMMENT '性别',
`cert_type` int(10) unsigned DEFAULT NULL COMMENT '证件类型',
`cert_no` varchar(20) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '证件号',
`birthday` date DEFAULT NULL COMMENT '生日',
`income_date` date DEFAULT NULL COMMENT '入职日期',
PRIMARY KEY (`id`),
UNIQUE KEY `code` (`code`),
UNIQUE KEY `cert_type` (`cert_type`,`cert_no`)
) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='员工表';
// -- 修改字段的字符集:CHARACTER SET utf8mb4
ALTER TABLE `dbtest`.`t_employee`
MODIFY COLUMN `cert_no` varchar(20) CHARACTER SET utf8mb4 NULL DEFAULT NULL COMMENT '证件号' AFTER `cert_type`;3、多级的字符集 & 多种字符集的作用
多级继承的字符集与字符序:可以方便快捷的设置下一层级的字符集和字符序,比如一个数据库下面有很多张表,只需要将数据库的字符集设置为 UTF8,所有表创建时就指定了默认的字符集。
MySQL 早期只支持有限数量字符集,后来不断的扩展,例如从早期的 latin 1 到 UTF8(阉割版本的utf8, MySQL 较早的版本为了节省存储空间,只三个字节)完全够用了,后面出现了 EMOJI 表情符号、复杂的汉字、繁体字等需要 4 个字节存储,就不能满足要求了,于是有 mysql 的 utf8mb4 字符集。
MySQL 支持在同一个服务器的数据库设置不同的字符集,同一个数据库下的不同表也可以设定不同的字符集,同一个表的不同字段也可以设定不同的字符集,都是为了方便业务的移植和扩展。(例如以前一个业务只覆盖了欧洲英文国家,采用 ladin 1字符集就足够了,但是后来有扩展到中国,于是需要将字符集扩展到 UTF8;之前全部字段(nickname)采用UTF8字符集,但是发现有些用户的昵称 EMOJI 表情符号,导致注册失败,于是将 nickname 字段的字符集修改为 utf8mb4)。
六、MySQL 客户端与服务端交互字符集 | 数据库外部字符集
1、客户端与服务端的交互
上面 4 种级别的字符集都是用于数据保存的,属于「数据库内部操作字符集」。另外,客户端和服务器之间的交互也受到其它「数据库外部字符集」的影响。
MySQL 采用 C/S 架构,所以它有服务端和客户端(如:MySQL自带的客户端、Navicat for MySQL等), 如果两端分布在不同的的主机上,那么两端通常需要通过 TCP/IP 获其他协议建立连接,然后实现通信或数据传输。跟 HTTP 协议有点异曲同工,HTTP 发起请求时会在 Header 里附上客户端“信息体”采用的字符集,MySQL 两端也需要提前沟通好通信采用的字符集,否则服务器端不知道客户端要的是什么,客户端也不知道服务端给的是什么,也就是鸡同鸭讲,乱码就会出现了。
MySQL提供了 character_set_client、character_set_connection 和 character_set_results 三个变量来辅助客户端与服务端的通信。
- character_set_client:服务器会将请求(如:一条 SQL 查询语句)的字节序列当作采用
character_set_client字符集进行编码的字节序列。 - character_set_connection:连接数据库时的字符集。
- character_set_results:数据库给客户端返回时使用的字符集。
每次客户端在连接服务器时,都会将客户端「默认的字符集」与用户名、密码等信息一起发给服务器,服务器根据发过来的信息,统一把这三个系统变量设定好。
客户端「默认的字符集」与客户端所在的操作系统环境变量有关,如果在 Unix 或 Linux 上,你设置了 LANG 或 LC_ALL 这样的环境变量,那么 MySQL 的客户端程序会默认检查应该使用哪一个字符集。例如:如果将 LC_ALL 设置为 en_US.UTF-8 ,那么 mysql 客户端将默认使用 UTF8 字符集 。
用 local 命令查看系统环境的字符集:UTF8
shitao-2:~ shitao$ locale
LANG="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_CTYPE="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_ALL=基于笔者的操作系统环境,现在我们通过命令来查看这三个变量的赋值:
SHOW VARIABLES LIKE 'character_set\_%';结果如下:

可以看到这三个变量都被设置成了 UTF8 字符集。现在我们来看下客户端发起的一次请求,这三个变量是如何起作用的。
流程图:
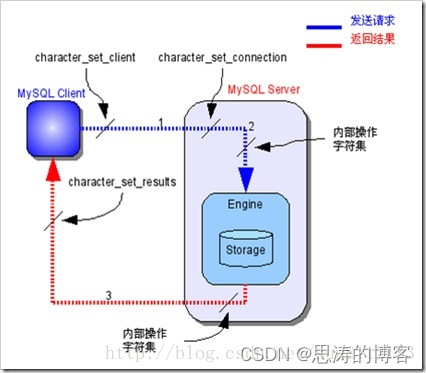
(1)mysql Server 收到请求时将请求数据从 character_set_client 字符集转换为 character_set_connection 字符集;
(2)进行内部操作前将请求数据从 character_set_connection 字符集转换为内部操作字符集,步骤如下
A. 使用每个数据字段的字符集设定值;
B. 若上述值不存在,则使用对应数据表的字符集设定值;
C. 若上述值不存在,则使用对应数据库的字符集设定值;
D. 若上述值不存在,则使用 character_set_server 设定值。
(3)最后将操作结果从内部操作字符集转换为 character_set_results 字符集。
为什么不直接将 character_set_client 字符集转为内部操作字符集 ,中间 character_set_connection 转换步骤的是否是多余的呢?其作用机制可以参考:Mysql中character_set_client、connection和results
为了加深理解,我们做两个小测试:
测试一:在数据集库里新建表 tb_example, 表和字段的字符集都默认是 utf8, 插入数据如下:

输入一条查询语句:
select id from tb_example where name = "牛";正常返回查询结果:
+------+
| id |
+------+
| 1001 |
+------+
现在我们在客户端执行下列语句:
set character_set_client=gbk;然后再次执行上面相同的查询语句,却返回为空
mysql> select id from example where name = "牛";
Empty set (0.03 sec)分析:因为服务端 character_set_client 被设置为 GBK 后,服务器会将请求的字节序列(UTF8)当作用 GBK 编码的字节序列。 例如:“牛”的 UTF8编码是 E7899B,这个编码在GBK里对应的就是其他字符了,所以导致查询的结果为空。
测试二:现在恢复到测试一之前的情况,输入下面的语句
set character_set_resuluts=gbk;执行下面的查询语句:
select * from example where name = "牛";返回结果:
+------+------+
| id | name |
+------+------+
| 1001 | ţ |
+------+------+
分析:可以看到存入数据库里的字符“牛”(UTF8编码),却按照 character_set_resuluts 指定的字符集(GBK编码)返回给客户端,字符的内容就错乱了。
另外,这三个变量其实是有作用域的(global | session),每一次创建新的连接,就为这三个变量创建了一个会话作用域 session ,刚才针对 character_set_client 和 character_set_resulut 的设置都这是针对当前 session 起作用的。关闭后或重新打开新的连接,这三个变量都会恢复到最初的设置。
让我们通过命令查看全局变量,与之前查询命令相比,添加了 global 修饰符:
SHOW global VARIABLES LIKE 'character_set\_%';结果:


可以观察到,这三个字符集全局变量(global)与 会话变量(session),并不相同,那么这全局变量有什么作用呢?可以参考 <mysql 8.0 版本>:MySQL 官网的解释
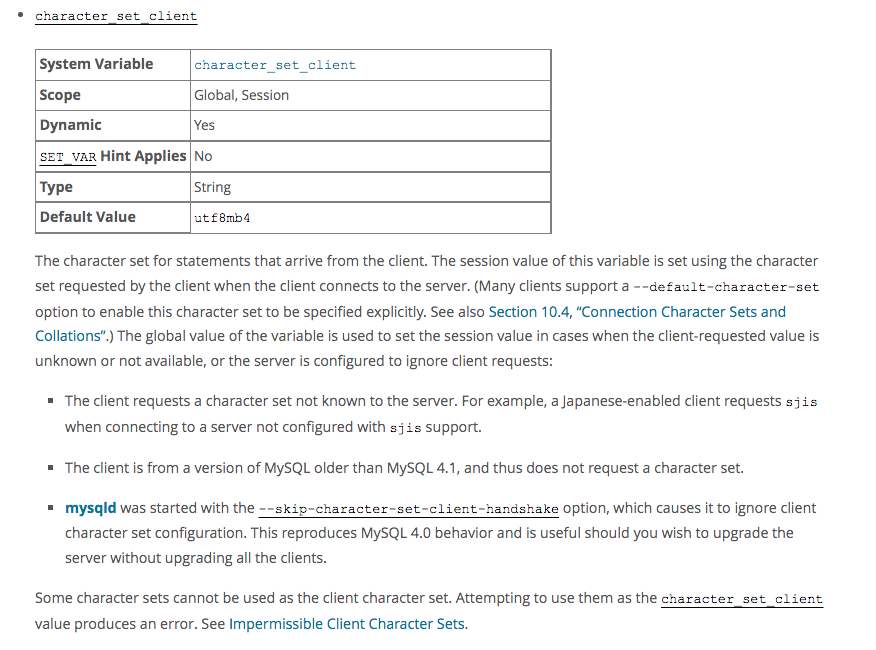
如上图所示:以 character_set_client 为例,服务端是根据客户端的请求来设定该值的(如:前面所说客户端默认字符集 + 后面将会提到的其他三种设置方式),如果服务端没有办法获取到客户端的请求字符集,或者客户端设置的字符集服务端不支持,那么将采用全局变量里这三个变量的值,在 mysql 8.0 版本,这三个值的默认值为 utf8mb4, 在笔者这里查询到这三个全局变量字符集是 Ladin 1,也可以推断上图的 default_value 应该是 Ladin 1。
2、如何设置字符集
如果你不想采用系统环境变量的默认字符集,也可以采用其他方式来进行设置:
方式 1:在 MySQL 配置文件 my.cnf | my.ini 中设置
如果客户端程序支持 --default-character-set 选项,你可以使用该选项。你可以将下列选项加入配置文件中,这样在每次建立和服务端的连接后,就会进行默认的字符集设置:
[client]
default-character-set=utf8方式 2:在建立连接后,在客户端输入下列语句
SET NAMES utf8;方式 3:部分编程语言的驱动提供了接口来实现类似的功能
对于 Java,你可以通过为连接数据库的 URL 指定 characterEncoding 属性来进行客户端所使用字符集的指定,例如:
jdbc:mysql://localhost:3306/mydatabase?useUnicode=true&characterEncoding=utf8以上三种方式等效于在客户端与服务器连接后,同时执行以下三条命令,将三个变量统一设置为相同的字符集:
SET character_set_client=utf8;
SET character_set_connection=utf8;
SET character_set_results=utf8;备注:这里的 character_set_client 有一定的迷惑性,其实它是客户端与服务端建立连接时候,双方约定的结果,也就是说,服务端会按 character_set_client 设置的字符集来接收客户端发来的 SQL 语句,但是并不能保证客户端一定就会按约定的字符集发送信息。
就像我们上面的「测试一」,在建立连接后,手动将 character_set_client 的字符集由 UTF8 改成了 GBK 字符集, 客户端仍然按 UTF8 字符集发送消息,就会造成对接时字符集错乱,导致查询结果为空。
同理,在「测试二」手动修改了 character_set_results 的值也造成了接受返回数据显示为乱码。所以我们采取上面 3 种方式来配置字符集变量的时候,一定要确保客户端环境实际采用的字符集与 character_set_client 和 character_set_results 完全一致。
参考:
MySQL配置文件my.ini详解
你真的搞懂MySQL的字符集了吗?
MySQL字符集的不同级别和效果
深入理解MySQL字符集及校对规则(一)
MySQL的字符编码体系(一)——数据存储编码
MySQL-解析客户端SQL执行字符集参数设置
MySQL中的字符集与字符序