二叉搜索树
一、二叉搜索树的概念

二叉搜索树又称二叉排序树,它可以是一棵空树,若果不为空则满足以下性质:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
- 二叉搜索树中不允许出现相同的键值
提示:二叉搜索树的附加功能是排序和去重。对于一个二叉搜索树,按照左子树-根节点-右子树的顺序进行中序遍历,得到的序列就是有序的。
二、二叉树搜索树的实现
2.1 核心结构
template <class K>
struct BSTreeNode{ //搜索二叉树的节点
typedef BSTreeNode<K> Node;
Node *_left;
Node *_right;
K _key;
BSTreeNode(const K &key = K())
:_left(nullptr), //必须将指针初始化为nullptr,防止出现野指针问题。
_right(nullptr),
_key(key)
{}
};
template <class K>
class BSTree{ //搜索二叉树
typedef BSTreeNode<K> Node;
Node *_root = nullptr;
public:
BSTree() = default; //C++11的用法:使用了default关键字,表示使用编译器自动生成的默认构造函数
void InOrder(){ //中序遍历多套一层是因为递归调用需要传递根节点指针,而根节点指针_root是private权限,在类外不能访问。
_InOrder(_root);
cout << endl;
}
//......
};
template <class K>
void BSTree<K>::_InOrder(Node *root){ //中序遍历
if(root == nullptr) return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
2.2 查找
- 从根开始比较,如果key比根大则到右树去找;如果key比根小则到左树去找;
- 最多查找高度次。如果走到空节点还未找到,则说明这个键值不存在。
//迭代法查找:
template <class K>
bool BSTree<K>::Find(const K &key){
//如果是空树,直接返回false;
if(_root == nullptr) return false;
Node *cur = _root;
while(cur != nullptr)
{
if(key > cur->_key) //如果键值大,就到右树去找
{
cur = cur->_right;
}
else if(key < cur->_key) //如果键值小,就到左树去找
{
cur = cur->_left;
}
else{
//找到返回true
return true;
}
}
//如果走到空节点还未找到,则说明这个键值不存在,返回false
return false;
}
//递归法查找:
template <class K>
bool BSTree<K>::_rFind(Node *root, const K &key){
if(root == nullptr) return false; //如果是空树或者走到空节点还未找到,返回false
if(key > root->_key) return _rFind(root->_right, key); //如果键值大,就到右树去找
else if(key < root->_key) return _rFind(root->_left, key); //如果键值小,就到左树去找
else return true;//找到返回true
}
2.3 插入
插入的具体过程如下:
- 树为空,则直接新增节点,赋值给root指针
- 树不为空,按二叉搜索树性质查找插入位置,插入新节点:
- 如果找到相同的键值,则不进行插入。
- 直到找到合适的空位置,才能进行插入操作。
//迭代法插入:
template <class K>
bool BSTree<K>::Insert(const K &key){
//树为空,直接进行插入:
if(_root == nullptr)
{
_root = new Node(key);
return true;
}
//树不为空,按二叉搜索树性质查找插入位置,插入新节点:
Node *cur = _root;
Node *parent = _root;
while(cur != nullptr)
{
if(key > cur->_key) //如果键值大,就到右树去找
{
parent = cur; //移动cur指针前记录父节点指针parent,便于下一步插入操作的连接。
cur = cur->_right;
}
else if(key < cur->_key) //如果键值小,就到左树去找
{
parent = cur;
cur = cur->_left;
}
else{
return false; //如果找到相同的键值,则插入失败。
}
}
//直到找到合适的空位置,才能进行插入操作:
if(key > parent->_key) //判断该位置是父节点的左节点还是右节点
{
parent->_right = new Node(key);
}
else{
parent->_left = new Node(key);
}
return true;
}
//递归法插入:
/*传引用的好处:root是父节点内_left,_right指针的引用(对于空树就是_root的引用),修改root就是修改父节点的_left,_right指针。所以我们不需要再记录父节点的指针,也不需要再判断该位置是父节点的左节点还是右节点。*/
template <class K>
bool BSTree<K>::_rInsert(Node* &root, const K &key){
//如果树为空或者找到了合适的空位置,进行插入操作:
if(root == nullptr)
{
root = new Node(key);
return true;
}
if(key > root->_key) //如果键值大,就到右树去插入
return _rInsert(root->_right, key);
else if(key < root->_key) //如果键值小,就到左树去插入
return _rInsert(root->_left, key);
else //如果找到相同的键值,则插入失败。
return false;
}
2.4 删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情况:
- 要删除的结点是叶节点
- 要删除的结点只有左结点
- 要删除的结点只有右结点
- 要删除的结点有左、右结点
看起来待删除节点有4中情况,实际情况1可以与情况2或者3合并起来(使父节点指向nullptr),因此真正的删除过程如下:
- 使父结点指向被删除节点的左结点;然后删除该结点;–直接删除
- 使父结点指向被删除节点的右结点;然后删除该结点;–直接删除
- 找到被删除节点左树的最大值(最右)或右树的最小值(最左);将其key值与被删除节点的key值交换,保证搜索树的结构;最后删除该节点(最大或最小节点)–替换法删除
//迭代法删除:
template <class K>
bool BSTree<K>::Erase(const K &key){
Node *cur = _root;
Node *parent = _root;
while(cur != nullptr)
{
if(key > cur->_key)
{
parent = cur; //移动cur指针前记录父节点指针parent,便于下一步删除操作的连接。
cur = cur->_right;
}
else if(key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else{
//情况1,2,3 直接删除
if(cur->_left == nullptr || cur->_right == nullptr)
{
DelNode(parent, cur);
}
else{
//情况4 替换法删除
Node *lmaxp = cur; //如果cur->left就是左树的最大值,lmaxp应该指向cur
Node *lmax = cur->_left; //lmax找左树的最大值,即左树的最右节点。
while(lmax->_right != nullptr)
{
lmaxp = lmax; //移动lmax指针前记录父节点指针lmaxp,便于下一步删除操作的连接。
lmax = lmax->_right;
}
swap(cur->_key, lmax->_key); //将其key值与被删除节点的key值交换,保证搜索树的结构
//最后删除该节点。
//注意:lmax指向最右节点,但该节点可能有左树;即使是叶节点,删除后也要接nullptr;
//因此要调用DelNode删除前进行连接。替换法删除实际是将问题转化为情况1或2或3
DelNode(lmaxp, lmax);
}
return true; //完成删除马上返回
}
}
//如果是空树,或者找不到要删除的元素,删除失败。
return false;
}
//直接删除节点
template <class K>
void BSTree<K>::DelNode(Node *parent, Node *cur){
if(cur->_left == nullptr) //要删除的结点只有右结点(或者是叶节点);使其父结点指向其右结点(叶节点指向空);
{
if(cur == _root) //如果要删除的是根节点,需要特殊处理。
{
_root = cur->_right;
}
else if(parent->_left == cur) //判断要删除的结点是父节点的左节点还是右节点
{
parent->_left = cur->_right;
}
else{
parent->_right = cur->_right;
}
}
else if(cur->_right == nullptr) //要删除的结点只有左结点;使父结点指向其左结点;
{
if(cur == _root)
{
_root = cur->_left;
}
else if(parent->_left == cur)
{
parent->_left = cur->_left;
}
else{
parent->_right = cur->_left;
}
}
//最后释放删除节点
delete cur;
}
//递归法删除:
/*传引用的好处:root是父节点内_left,_right指针的引用,修改root就是修改父节点的_left,_right指针。所以我们不需要再记录父节点的指针,也不需要再判断该位置是父节点的左节点还是右节点。*/
template <class K>
bool BSTree<K>::_rErase(Node* &root, const K &key){
//如果是空树,或者找不到要删除的元素,删除失败。
if(root == nullptr) return false;
if(key > root->_key)
_rErase(root->_right, key);
else if(key < root->_key)
_rErase(root->_left, key);
else{
Node *del = root; //记录要删除的节点
//情况1,2,3 直接删除
if(root->_left == nullptr)
{
root = root->_right;
}
else if(root->_right == nullptr)
{
root = root->_left;
}
else{
//情况4 替换法删除
Node *rmin = root->_right; //rmin找右树的最小值,即右树的最左节点。
while(rmin->_left!=nullptr)
{
rmin = rmin->_left;
}
swap(rmin->_key, root->_key); //将其key值与被删除节点的key值交换,保证搜索树的结构
//最后删除该节点。
//注意:rmin指向最左节点,但该节点可能有右树;即使是叶节点,删除后也要接nullptr;
//因此要递归调用_rErase删除前进行连接。替换法删除实际是将问题转化为情况1或2或3
//交换后,已经不能从根节点开始找key了(key的位置已经不符合搜索树结构);
//应该从右子树的根节点开始找(key的位置在右子树中仍符合搜索树结构);
return _rErase(root->_right, key);
}
//释放节点
delete del;
return true;
}
}
2.5 默认成员函数
template <class K>
class BSTree{
typedef BSTreeNode<K> Node;
Node *_root = nullptr;
public:
BSTree() = default; //使用编译器自动生成的默认构造函数
//多套一层是因为递归调用需要传递根节点指针,而根节点指针_root是private权限,在类外不能访问。析构同理。
BSTree(const BSTree<K> &bst){
_root = _Copy(bst._root);
}
BSTree<K>& operator=(BSTree<K> bst){ //复用拷贝构造
swap(bst._root, _root);
return *this;
}
~BSTree(){
_Destroy(_root);
}
//......
};
拷贝构造
template <class K>
Node* BSTree<K>::_Copy(Node *root){
if(root == nullptr) return nullptr;
Node *copyroot = new Node(root->_key); //前序遍历拷贝,保证两棵树的结构顺序完全相同
copyroot->_left = _Copy(root->_left);
copyroot->_right = _Copy(root->_right);
return copyroot;
}
析构
template <class K>
void BSTree<K>::_Destroy(Node *root){
if(root == nullptr) return;
_Destroy(root->_left); //析构必须采用后序遍历
_Destroy(root->_right);
delete root;
}
三、二叉搜索树的应用
3.1 K模型
K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:(示例代码:wordchecker.cc)
- 以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树
- 在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
//wordchecker.cc
#include "BSTree_K.hpp"
#include <iostream>
#include <string>
using namespace std;
int main(){
string tmp[] = {"search", "word", "vector", "string", "dictionary", "list", "binary"};
BSTree<string> lib;
for(string &e : tmp)
{
lib.Insert(e);
}
lib.InOrder();
string input;
while(cin >> input)
{
bool ret = lib.Find(input);
if(ret)
{
cout << "拼写正确!" << endl;
}
else{
cout << "拼写错误!" << endl;
}
}
return 0;
}
3.2 KV模型
KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。
KV模型中key为关键码,二叉搜索树构建过程中的比较仍以key值为准。value只是一个对应值,附加值。
该种方式在现实生活中非常常见:
- 比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;(示例代码:dictionary.cc)
- 再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对。(示例代码:wordcounter.cc)
将二叉搜索树改造成KV模型:
//将二叉搜索树改造成KV模型
//只有少量改动,不变的内容省略不写。
#include <iostream>
using namespace std;
template <class K, class V>
struct BSTreeNode{
typedef BSTreeNode<K, V> Node;
Node *_left;
Node *_right;
K _key;
V _val; //加了一个value
BSTreeNode(const K &key = K(), const V &val = V())
:_left(nullptr),
_right(nullptr),
_key(key),
_val(val)
{}
};
template <class K, class V>
class BSTree{
typedef BSTreeNode<K, V> Node;
Node *_root = nullptr;
public:
bool Insert(const K &key, const V &val);
Node* Find(const K &key);
//......
private:
Node* _Copy(Node *root);
//......
};
template <class K, class V>
bool BSTree<K,V>::Insert(const K &key, const V &val){
if(_root == nullptr)
{
_root = new Node(key, val); //插入时要初始化value
return true;
}
//......
if(key > parent->_key)
{
parent->_right = new Node(key, val);
}
else{
parent->_left = new Node(key, val);
}
return true;
}
template <class K, class V>
BSTreeNode<K,V>* BSTree<K,V>::Find(const K &key){
if(_root == nullptr) return nullptr;
Node *cur = _root;
while(cur != nullptr)
{
//......
else{
return cur; //找到返回节点指针,便于查看和修改value
}
}
return nullptr;
}
template <class K, class V>
BSTreeNode<K,V>* BSTree<K,V>::_Copy(Node *root){
if(root == nullptr) return nullptr;
Node *copyroot = new Node(root->_key, root->_val); //拷贝也要复制value
//......
}
template <class K, class V>
void BSTree<K,V>::_InOrder(Node *root){
if(root == nullptr) return;
_InOrder(root->_left);
cout << root->_key << "-->" << root->_val << endl;
_InOrder(root->_right);
}
KV模型的应用示例:
//dictionary.cc
#include "BSTree_KV.hpp"
#include <iostream>
#include <string>
using namespace std;
int main(){
BSTree<string, string> dct;
dct.Insert("buffer", "缓冲器");
dct.Insert("error", "错误");
dct.Insert("derive", "继承自,来自");
dct.Insert("soldier", "士兵");
dct.Insert("column", "列");
dct.Insert("row", "行");
dct.InOrder();
string input;
while(cin >> input){
BSTreeNode<string,string> *ret = dct.Find(input);
if(ret != nullptr)
{
cout << ret->_val << endl;
}
else{
cout << "词库中无此单词" << endl;
}
}
}
//wordcounter.cc
int main(){
string tmp[] = {"orange", "orange","orange","strawberry", "pear","apple", "apple","apple","apple","peach","peach"};
BSTree<string, int> counter;
for(string &e : tmp)
{
BSTreeNode<string, int> *ret = counter.Find(e);
if(ret)
{
++ret->_val;
}
else{
counter.Insert(e, 1);
}
}
counter.InOrder();
return 0;
}
四、二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找次数是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。时间复杂度:O(h),h是树的深度。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
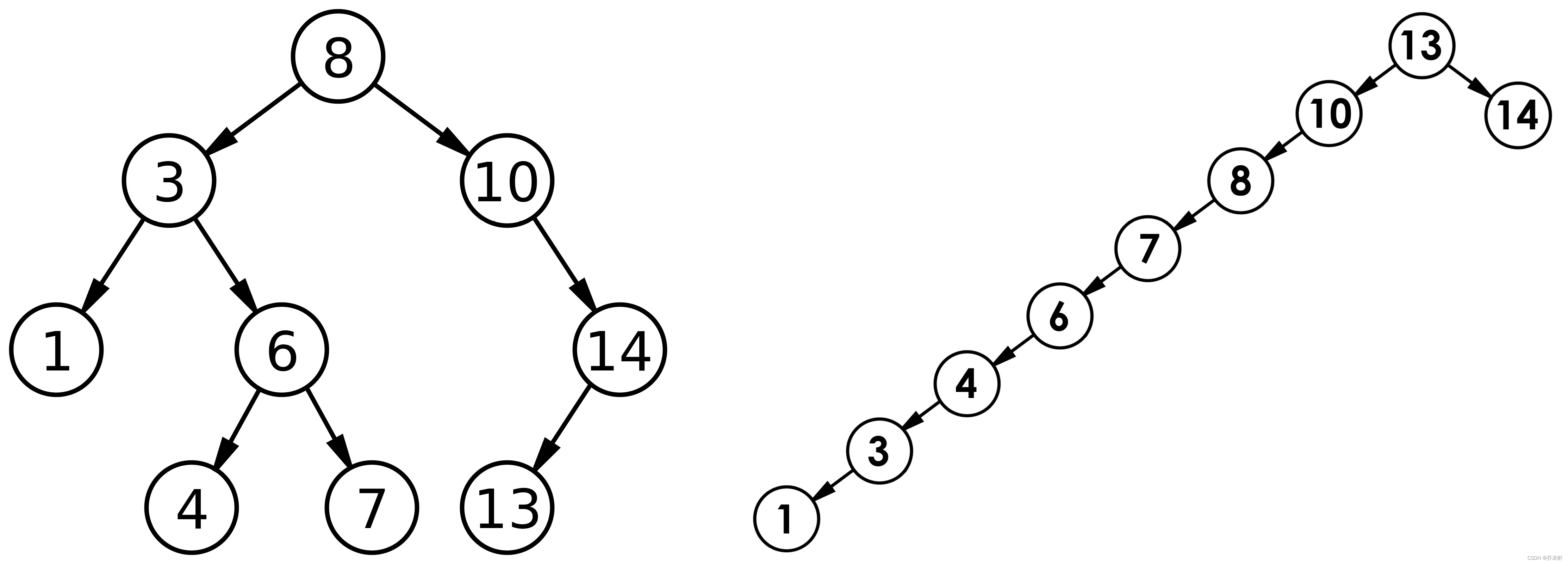
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为:log_2 N
最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为:N
问题:如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插入关键码,二叉搜索树的性能都能达到最优?那么我们后续章节学习的AVL树和红黑树就可以上场了。
五、相关练习
这些题目更适合使用C++完成,难度也更大一些
- 二叉树创建字符串。OJ链接
- 二叉树的分层遍历1。OJ链接
- 二叉树的分层遍历2。OJ链接
- 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先 。OJ链接
- 二叉树搜索树转换成排序双向链表。OJ链接
- 根据一棵树的前序遍历与中序遍历构造二叉树。 OJ链接
- 根据一棵树的中序遍历与后序遍历构造二叉树。OJ链接
- 二叉树的前序遍历,非递归迭代实现 。OJ链接
- 二叉树中序遍历 ,非递归迭代实现。OJ链接
- 二叉树的后序遍历 ,非递归迭代实现。OJ链接