NNI剪枝入门可参考:nni模型剪枝_benben044的博客-CSDN博客_nni 模型剪枝
1、背景
本文的剪枝操作针对CenterNet算法的BackBone,即MobileNetV3算法。
该Backbone最后的输出格式如下:
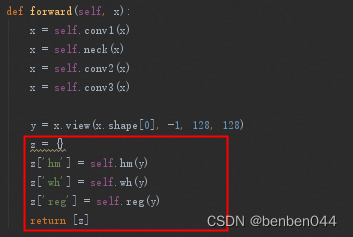
假如out = model(x),则x[-1]['hm']可获得heatmap的shape。
2、直接添加nni操作
直接添加的示例代码如下:
import torch
from torch import nn
from nni.compression.pytorch.pruning import L1NormPruner
from nni.compression.pytorch.speedup import ModelSpeedup
class hswish(nn.Module):
def __init__(self):
super(hswish, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = x * self.relu6(x + 3) / 6
return out
class hsigmoid(nn.Module):
def __init__(self):
super(hsigmoid, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = self.relu6(x + 3) / 6
return out
# 注意力机制
class SE(nn.Module):
def __init__(self, in_channels, reduce=4):
super(SE, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduce, 1, bias=False),
nn.BatchNorm2d(in_channels // reduce),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels // reduce, in_channels, 1, bias=False),
nn.BatchNorm2d(in_channels),
hsigmoid()
)
def forward(self, x):
out = self.se(x)
out = x * out
return out
class Block(nn.Module):
def __init__(self, kernel_size, in_channels, expand_size, out_channels, stride, se=False, nolinear='RE'):
super(Block, self).__init__()
self.se = nn.Sequential()
if se:
self.se = SE(expand_size)
if nolinear == 'RE':
self.nolinear = nn.ReLU6(inplace=True)
elif nolinear == 'HS':
self.nolinear = hswish()
self.block = nn.Sequential(
nn.Conv2d(in_channels, expand_size, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(expand_size),
self.nolinear,
nn.Conv2d(expand_size, expand_size, kernel_size, stride=stride, padding=kernel_size // 2, groups=expand_size, bias=False),
nn.BatchNorm2d(expand_size),
self.se,
self.nolinear,
nn.Conv2d(expand_size, out_channels, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
def forward(self, x):
out = self.block(x)
if self.stride == 1:
out += self.shortcut(x)
return out
class MobileNetV3(nn.Module):
def __init__(self, class_num):
super(MobileNetV3, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(16),
hswish()
)
self.neck = nn.Sequential(
Block(3, 16, 16, 16, 2, se=True),
Block(3, 16, 72, 24, 2),
Block(3, 24, 88, 24, 1),
Block(5, 24, 96, 40, 2, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 120, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 144, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 288, 96, 2, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
)
self.conv2 = nn.Sequential(
nn.Conv2d(96, 576, 1, bias=False),
nn.BatchNorm2d(576),
hswish()
)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.conv3 = nn.Sequential(
nn.Conv2d(576, 1280, 2, bias=False),
nn.BatchNorm2d(1280),
hswish()
)
self.hm = nn.Conv2d(20, class_num, kernel_size=1)
self.wh = nn.Conv2d(20, 2, kernel_size=1)
self.reg = nn.Conv2d(20, 2, kernel_size=1)
def forward(self, x):
x = self.conv1(x)
x = self.neck(x)
x = self.conv2(x)
x = self.conv3(x)
y = x.view(x.shape[0], -1, 128, 128)
z = {}
z['hm'] = self.hm(y)
z['wh'] = self.wh(y)
z['reg'] = self.reg(y)
return [z]
if __name__ == '__main__':
model = MobileNetV3(10)
print('-----------raw model------------')
print(model)
config_list = [{
'sparsity_per_layer': 0.8,
'op_types': ['Conv2d']
}]
pruner = L1NormPruner(model, config_list)
_, masks = pruner.compress()
for name, mask in masks.items():
print(name, ' sparsity: ', '{:.2f}'.format(mask['weight'].sum() / mask['weight'].numel()))
pruner._unwrap_model()
ModelSpeedup(model, torch.rand(2, 3, 516, 516), masks).speedup_model()
print('------------after speedup------------')
print(model)
如果参考nni入门直接添加nni压缩的代码,则会报如下错误:
RuntimeError: Only tensors, lists, tuples of tensors, or dictionary of tensors can be output from traced functions。
File "D:\programs\python37\lib\site-packages\nni\common\graph_utils.py", line 78, in _trace
self.trace = torch.jit.trace(model, dummy_input, **kw_args)
File "D:\programs\python37\lib\site-packages\torch\jit\_trace.py", line 742, in trace
_module_class,
File "D:\programs\python37\lib\site-packages\torch\jit\_trace.py", line 940, in trace_module
_force_outplace,
RuntimeError: Only tensors, lists, tuples of tensors, or dictionary of tensors can be output from traced functions
原因,返回的数据不符合torch.jit.trace的要求,而示例model返回的是一个dict,它不是tensors | lists | tuples of tensors | dictionary of tensors中的一种。
所以需要对MobileNetv3进行改造,以满足torch.jit.trace的返回要求。
3、MobileNetV3针对NNI的改造
改造方法:
(1)将输出从dict修改为tuple形式
(2)hm、wh、reg的定义从__init__()函数移到forward中。因为hm中conv的in_channel是会变化的,未剪枝前是A,剪枝后是B,所以在__init__()中定义没法动态修改in_channel值,只能放到forward中进行处理。
改造后的示例代码如下:
import torch
from torch import nn
from nni.compression.pytorch.pruning import L1NormPruner
from nni.compression.pytorch.speedup import ModelSpeedup
class hswish(nn.Module):
def __init__(self):
super(hswish, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = x * self.relu6(x + 3) / 6
return out
class hsigmoid(nn.Module):
def __init__(self):
super(hsigmoid, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = self.relu6(x + 3) / 6
return out
# 注意力机制
class SE(nn.Module):
def __init__(self, in_channels, reduce=4):
super(SE, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduce, 1, bias=False),
nn.BatchNorm2d(in_channels // reduce),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels // reduce, in_channels, 1, bias=False),
nn.BatchNorm2d(in_channels),
hsigmoid()
)
def forward(self, x):
out = self.se(x)
out = x * out
return out
class Block(nn.Module):
def __init__(self, kernel_size, in_channels, expand_size, out_channels, stride, se=False, nolinear='RE'):
super(Block, self).__init__()
self.se = nn.Sequential()
if se:
self.se = SE(expand_size)
if nolinear == 'RE':
self.nolinear = nn.ReLU6(inplace=True)
elif nolinear == 'HS':
self.nolinear = hswish()
self.block = nn.Sequential(
nn.Conv2d(in_channels, expand_size, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(expand_size),
self.nolinear,
nn.Conv2d(expand_size, expand_size, kernel_size, stride=stride, padding=kernel_size // 2, groups=expand_size, bias=False),
nn.BatchNorm2d(expand_size),
self.se,
self.nolinear,
nn.Conv2d(expand_size, out_channels, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
def forward(self, x):
out = self.block(x)
if self.stride == 1:
out += self.shortcut(x)
return out
class MobileNetV3(nn.Module):
def __init__(self, class_num, sparsity_ratio):
super(MobileNetV3, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(16),
hswish()
)
self.neck = nn.Sequential(
Block(3, 16, 16, 16, 2, se=True),
Block(3, 16, 72, 24, 2),
Block(3, 24, 88, 24, 1),
Block(5, 24, 96, 40, 2, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 120, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 144, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 288, 96, 2, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
)
self.conv2 = nn.Sequential(
nn.Conv2d(96, 576, 1, bias=False),
nn.BatchNorm2d(576),
hswish()
)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.conv3 = nn.Sequential(
nn.Conv2d(576, 1280, 2, bias=False),
nn.BatchNorm2d(1280),
hswish()
)
self.class_num = class_num
def forward(self, x):
x = self.conv1(x)
x = self.neck(x)
x = self.conv2(x)
x = self.conv3(x)
y = x.view(x.shape[0], -1, 128, 128)
in_channel = y.shape[1]
hm = nn.Conv2d(in_channel, self.class_num, kernel_size=1)
wh = nn.Conv2d(in_channel, self.class_num, kernel_size=1)
reg = nn.Conv2d(in_channel, self.class_num, kernel_size=1)
return (hm(y), wh(y), reg(y))
if __name__ == '__main__':
model = MobileNetV3(10, 0.2)
print('-----------raw model------------')
print(model)
config_list = [{
'sparsity_per_layer': 0.2,
'op_types': ['Conv2d']
}]
pruner = L1NormPruner(model, config_list)
_, masks = pruner.compress()
for name, mask in masks.items():
print(name, ' sparsity: ', '{:.2f}'.format(mask['weight'].sum() / mask['weight'].numel()))
pruner._unwrap_model()
ModelSpeedup(model, torch.rand(2, 3, 516, 516), masks).speedup_model()
print('------------after speedup------------')
print(model)
input = torch.randn(2, 3, 516, 516) # batch_size =1 会报错
out = model(input)
print(out[0].shape)