文章目录
- DDL
- 库操作
- 表操作
- 内部表&外部表
- 分区表
- 修改表&删除表
- 数据的导入导出
- 数据导入
- 数据导出
DDL
DDL(data definition language),命令有CREATE、ALTER、DROP等。主要用在定义、修改数据库对象的结构或数据类型;
理解
库操作
- 创建
语法
CREATE(DATABASE|SCHEMA) [IF EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (properti_name=property_value,...)];
注意:
1)Hive有一个默认的数据库default,在操作HQL时,如果不明确指定使用哪个数据库,则使用默认数据库;
2)Hive的数据库名、表名均不区分大小写;
3)名字不能使用数字开头;
4)不能使用关键字,尽量不使用特殊符号;
5)基础命令跟RDBMS创建数据库命令相同,RDBMS不会指定LOCATION的HDFS的存储路径;
6)选项参数【MANAGEDLOCATION】、【WITH DBPROPERTIES】 使用较少;
- 查看
查看所有数据库
show databases;
查看数据库信息
desc database database_name;
desc database extended database_name;
describe database extended database_name;
- 使用
use database_name;
- 删除
删除一个空数据库
drop database database_name;
如果不为空,使用cascade强制删除
drop database database_name cascade;
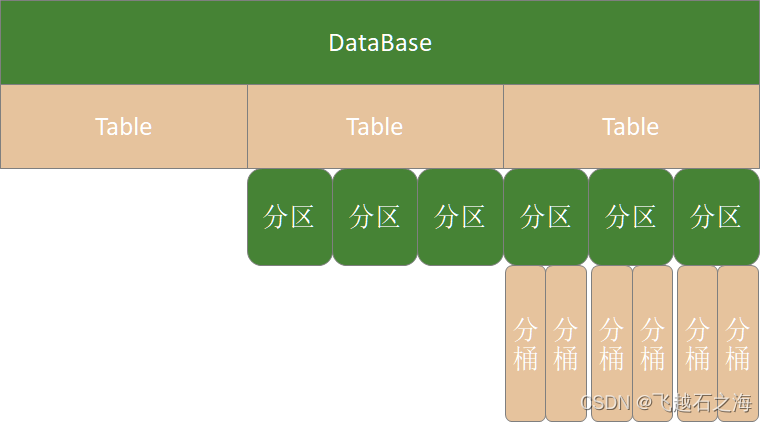
表操作
- 语法
create [external] table [IF NOT EXISTS] table_name
[(colName colType [comment 'comment'], ...)]
[comment table_comment]
[partition by (colName colType [comment col_comment], ...)]
[clustered BY (colName, colName, ...)
[sorted by (col_name [ASC|DESC], ...)] into num_buckets
buckets]
[row format row_format]
[stored as file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement];
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
- 参数说明
create table
按给定名称创建表,如果表已经存在则抛出异常。可使用if not;
external关键字
加上创建的是外部表,否则创建的是内部表(管理表);
删除内部表时,数据和表的定义同时被删除;
删除外部表时,仅仅删除了表的定义,数据保留;
在生产环境中,多使用外部表;
comment
表的注释;
partition by
对表中数据进行分区,指定表的分区字段;
clustered by
创建分桶表,指定表的分桶字段;
sorted by
对桶中的一个或多个列排序,较少使用;
存储子句
语法:
ROW FORMAT DELIMITED指定表存储中列的分隔符
[FIELDS TERMINATED BY char] 字段
[COLLECTION ITEMS TERMINATED BY char]元素
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char] | SERDE serde_name
[WITH SERDEPROPERTIES (property_name=property_value,
property_name=property_value, ...)]
SerDe是 Serialize/Deserilize 的简称, hive使用Serde进行 行对象的序列与反序列化;
建表时可指定 SerDe 。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用默认的SerDe;
建表时还需要为表指定列,在指定列的同时也会指定自定义的 SerDe。Hive通过 SerDe 确定表的具体的列的数据;
stored as SEQUENCEFILE|TEXTFILE|RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE(缺省);
如果数据需要压缩,使用 STORED ASSEQUENCEFILE(二进制序列文件);
SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件);
LOCATION
定义 hive 表的数据在 hdfs 上的存储路径,一般管理表(内部表不要自定义),但是如果定义的是外部表,则需要直接指定一个路径;
TBLPROPERTIES
定义表的属性;
AS
后面可以接查询语句,表示根据后面的查询结果创建表;
LIKE
like 表名,允许用户复制现有的表结构,但是不复制数据;
内部表&外部表
内部表
创建内部表
create table t1(
id int,
name string,
hobby array<string>,
addr map<string, string>
)
row format delimited
fields terminated by ";"
collection items terminated by ","
map keys terminated by ":";
显示表的定义,显示的信息较少
desc t1;
显示表的定义,显示的信息多,格式友好
desc formatted t1;
加载数据
load data local inpath '/home/hadoop/data/t1.dat' into table
t1;
查询数据
select * from t1;
查询数据文件
dfs -ls /user/hive/warehouse/mydb.db/t1;
删除表。表和数据同时被删除
drop table t1;
再次查询数据文件,已经被删除
外部表
创建外部表
create external table t2(
id int,
name string,
hobby array<string>,
addr map<string, string>
)
row format delimited
fields terminated by ";"
collection items terminated by ","
map keys terminated by ":";
显示表的定义
desc formatted t2;
加载数据
load data local inpath '/home/hadoop/data/t1.dat' into table
t2;
查询数据
select * from t2;
删除表。表删除了,目录仍然存在
drop table t2;
再次查询数据文件,仍然存在
使用场景
想保留数据时使用,生产多用外部表;
内部表与外部表的转换
内部表转外部表
alter table t1 set tblproperties('EXTERNAL'='TRUE');
外部表转内部表。EXTERNAL 大写,false 不区分大小
alter table t1 set tblproperties('EXTERNAL'='FALSE');
查询表信息,是否转换成功
desc formatted t1;
分区表
-
分区原因
Hive在执行查询时,一般会扫描整个表的数据。由于表的数据量大,全表扫描消耗时间长、效率低;
有时候,查询只需要扫描表中的一部分数据即可,Hive引入了分区表的概念,将表的数据存储在不同的子目录中,每一个子目录对应一个分区。
只查询部分分区数据时,可避免全表扫描,提高查询效率;在实际中,通常根据时间、地区等信息进行分区。 -
命令行
创建表
create table if not exists t3(
id int
,name string
,hobby array<string>
,addr map<String,string>
)
partitioned by (dt string)
row format delimited
fields terminated by ';'
collection items terminated by ','
map keys terminated by ':';
加载数据
load data local inpath "/home/hadoop/data/t1.dat" into table t3
partition(dt="2020-06-01");
load data local inpath "/home/hadoop/data/t1.dat" into table t3
partition(dt="2020-06-02");
//分区字段不是表中已经存在的数据,可以将分区字段看成伪列
查看分区
show partitions t3;
新增分区并设置数据
//增加一个分区,不加载数据
alter table t3 add partition(dt='2020-06-03');
//增加多个分区,不加载数据
alter table t3 add partition(dt='2020-06-05') partition(dt='2020-06-06');
//增加多个分区,拷贝数据
hdfs dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2020-06-01
/user/hive/warehouse/mydb.db/t3/dt=2020-06-07
hdfs dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2020-06-01
/user/hive/warehouse/mydb.db/t3/dt=2020-06-08
//增加多个分区,定位数据路径
alter table t3 add
partition(dt='2020-06-07') location
'/user/hive/warehouse/mydb.db/t3/dt=2020-06-07'
partition(dt='2020-06-08') location
'/user/hive/warehouse/mydb.db/t3/dt=2020-06-08';
修改数据路径
alter table t3 add
partition(dt='2020-06-07') set location
'/user/hive/warehouse/mydb.db/t3/dt=2020-06-08'
删除分区
//可以删除一个或多个分区,用逗号隔开
alter table t3 drop partition(dt='2020-06-03'),
partition(dt='2020-06-04');
修改表&删除表
创建普通表
create table course_common(
id int,
name string,
score int
)
row format delimited fields terminated by "\t";
修改表名-rename
alter table course_common rename to course_common1;
修改列名-change column
alter table course_common1 change column id cid int;
修改字段类型-change column
alter table course_common1 change column cid cid string;
//修改字段数据类型时,要满足数据类型转换的要求。如int可以转为string,但是string不能转为int
The following columns have types incompatible with theexisting columns in their respective positions
增加字段-add columns
alter table course_common1 add columns (common string);
删除字段-replace columns
//这里仅仅只是在元数据中删除了字段,并没有改动hdfs上的数据文件
alter table course_common1 replace columns(id string, cname string, score int);
删除表
drop table course_common1;
数据的导入导出
数据导入
装载数据load
语法:
LOAD DATA [LOCAL] INPATH 'filepath'
[OVERWRITE] INTO TABLE tablename [PARTITION(partcol1 = val1, partcol2 = val2...)]
参数说明
LOCAL
1)LOAD DATA LOCAL…
从本地文件系统加载数据到Hive表中。本地文件会拷贝到Hive表指定的位置;
2)LOAD DATA …
从HDFS加载数据到Hive表中。HDFS文件移动到Hive表指定的位置;
INPATH——加载数据的路径
OVERWRITE——覆盖表中已有数据;否则表示追加数据;
PARTITION——将数据加载到指定分区;
举例
装载数据之前做好准备工作
创建表
CREATE TABLE tabA (
id int
,name string
,area string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
数据文件
(~/data/sourceA.txt):
1,fish1,SZ
2,fish2,SH
3,fish3,HZ
4,fish4,QD
5,fish5,SR
拷贝文件到 HDFS
hdfs dfs -put sourceA.txt data/
装载数据
加载本地文件到hive(tabA)
LOAD DATA LOCAL INPATH '/home/hadoop/data/sourceA.txt' INTO TABLE tabA;
//检查本地文件还在
加载hdfs文件到hive(tabA)
LOAD DATA INPATH 'data/sourceA.txt' INTO TABLE tabA;
//检查HDFS文件,已经被转移
加载数据覆盖表中已有数据
LOAD DATA INPATH 'data/sourceA.txt'
OVERWRITE INTO TABLE tabA;
创建表时加载数据
hdfs dfs -mkdir /user/hive/tabB
hdfs dfs -put sourceA.txt /user/hive/tabB
CREATE TABLE tabB (
id INT
,name string
,area string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
Location '/user/hive/tabB';
插入数据insert
创建分区表
CREATE TABLE tabC (
id INT
,name string
,area string
)
partitioned by (month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
插入数据
insert into table tabC partition(month='202001') values (5, 'wangwu', 'BJ'), (4, 'lishi', 'SH'), (3,'zhangsan', 'TJ');
插入查询的结果数据
insert into table tabC partition(month='202002') select id, name, area from tabC where month='202001';
多表(多分区)插入模式
from tabC
insert overwrite table tabC partition(month='202003') select id, name, area where month='202002'
insert overwrite table tabC partition(month='202004') select id, name, area where month='202002';
创建表并插入数据 as select
根据查询结果创建表
create table if not exists tabD as select * from tabC;
使用import导入数据
import table student2 partition(month='201709') from '/user/hive/warehouse/export/student';
数据导出
将查询结果导出到本地
insert overwrite local directory '/home/hadoop/data/tabC' select * from tabC;
将查询结果格式化输出到本地
insert overwrite local directory '/home/hadoop/data/tabC2'
row format delimited fields terminated by ' '
select * from tabC;
将查询结果导出到HDFS
insert overwrite directory '/user/hadoop/data/tabC3'
row format delimited fields terminated by ' '
select * from tabC;
dfs 命令导出数据到本地。本质是执行数据文件的拷贝
dfs -get /user/hive/warehouse/mydb.db/tabc/month=202001
/home/hadoop/data/tabC4
hive 命令导出数据到本地。执行查询将查询结果重定向到文件
hive -e "select * from mydb.tabC" > a.log
export 导出数据到HDFS
//使用export导出数据时,不仅有数据还有表的元数据信息
export table tabC to '/user/hadoop/data/tabC4';
//export 导出的数据,可以使用 import 命令导入到 Hive 表中
使用 like tname创建的表结构与原表一致,create ... as select ...结构可能不一致
create table tabE like tabc;
import table tabE from '/user/hadoop/data/tabC4';
//as...select 分区表变成普通表
**截断表,清空数据。(注意:仅能操作内部表)**
truncate table tabE;
//以下语句报错,外部表不能执行 truncate 操作
alter table tabC set tblproperties("EXTERNAL"="TRUE");
truncate table tabC;