目录
1. 背景
2. 方法
2.1 怎么把2D图像变成1D序列输入到transformer中
像素?
先提取特征图?
打成多个patch
2.2 transformer和卷积网络比较
2.3 结构
1. 背景
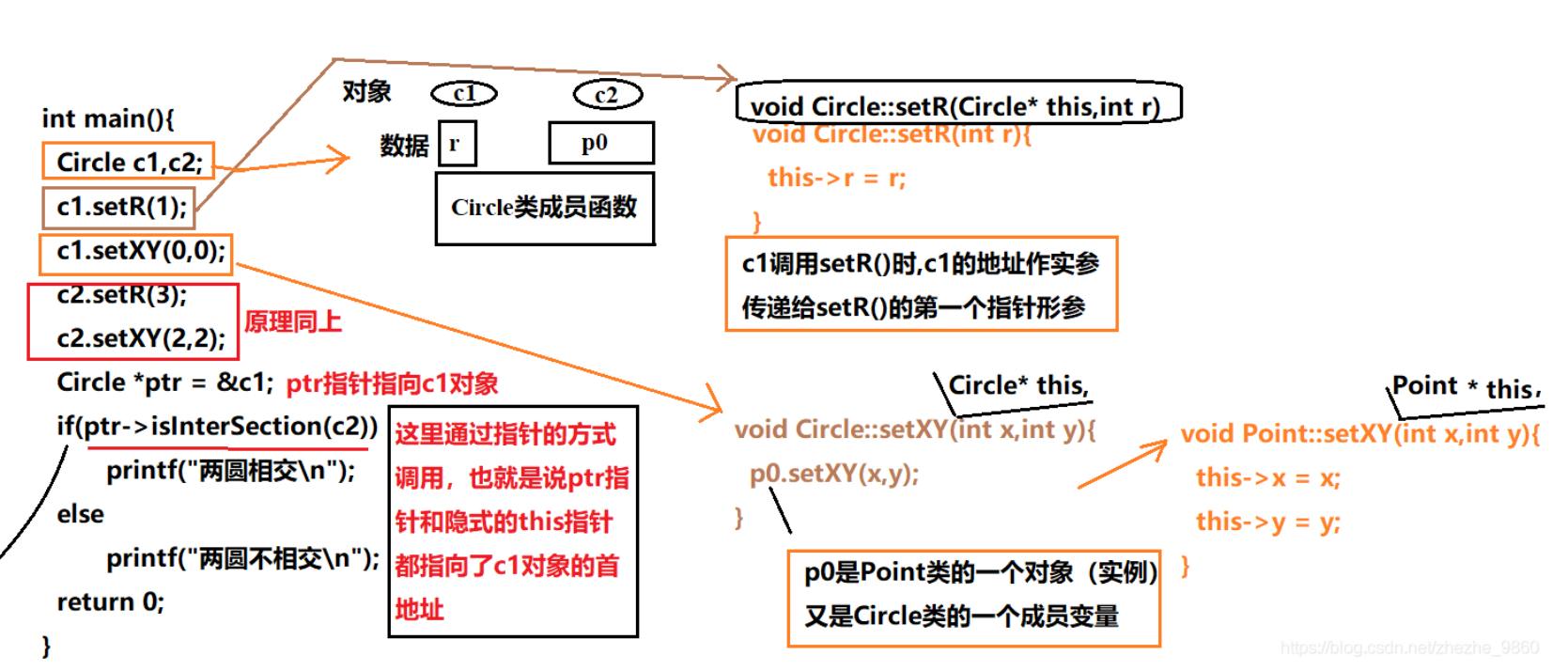
VIT是基于transformer的在图像分类大放异彩的变体,transformer是VIT的亲爹,可以和resnet相媲美
VIT指出混合卷积网络是不必要的,纯transformer的结构也可以在图像分类里面取得特别好的结果
开启了一个新的天地
2. 方法
2.1 怎么把2D图像变成1D序列输入到transformer中
但想要在视觉领域迁移应用transformer,一个最重要的问题是怎么去把2D图像变成1D序列输入到transformer中
回忆一下transformer,他本质是对输入的序列元素之间做互动,得到注意力图,然后利用自注意力图去做加权平均输出
因为两两都要做互动,所以这个计算复杂度是很大的,
而硬件能计算的序列长度大概是几百几千。比如在经典自然语言的transformer Bert中是512长度。
像素?
所以如果我们直接把图像里的每一个像素点当作一个序列元素的话,会导致序列特别长,比如一张224*224=50176的序列长度,是Bert的500倍。
先提取特征图?
之前也有一些在CV领域的transformer工作,但他们为了降低这种复杂度,是引入了卷积等操作提取特征图,再把特征图拉长为序列输入,或者只在图片的一小片区域做自注意力。
但是作者觉得NLP在自然领域的可扩展性很强,他们也想在CV领域做同样的事情,想尽可能少的改动网络结构,但是老问题回来了,序列太长怎么办?
打成多个patch
把一个图片打成很多个patch
比如对于一张图片224*224 打成16 * 16大小的patch,每一个patch展成序列的长度就是196 ,把他当作一个单词,作为序列的元素输入transformer
2.2 transformer和卷积网络比较
transformer和卷积网络相比,缺少一定的归纳偏置,一种先验知识
(1)locality 假设相邻区域会有相邻特征,靠的越近的东西相关性越强
(2)平移不变性。无论是先做平移还是先做卷积都是一样的。
所以有了这两个假设,我们可以把卷积核看作一个模板,不管一个物体移到哪里,遇到同样的卷积核都会有相同的输出。
有了先验信息,卷积网络就需要较少的数据去学习。但是transformer没有这样的先验信息,所以就需要更大的数据集才能达到比较好的效果
总结来看
transformer需要较大的数据集,才能取得和CNN相媲美的结果
2.3 结构
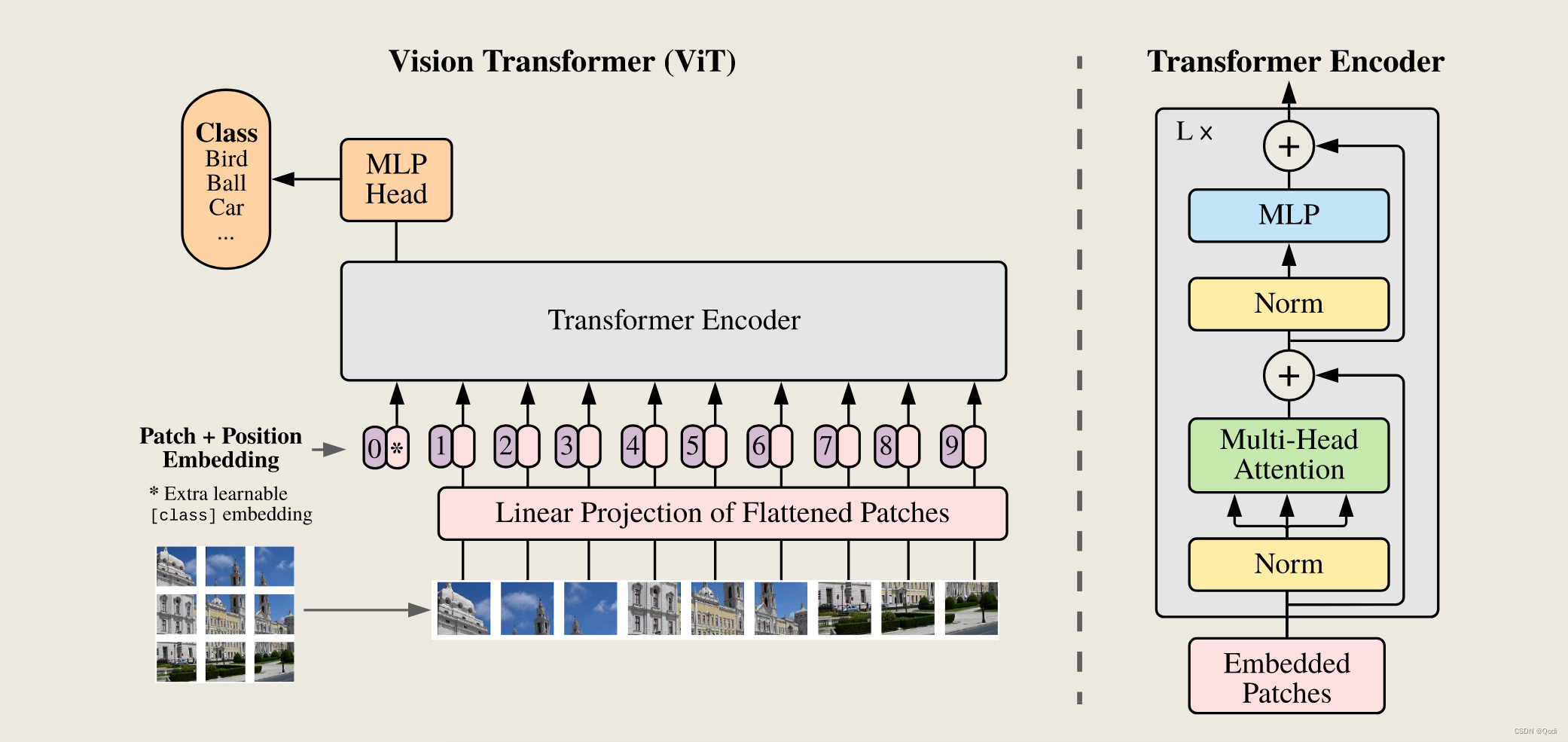
借鉴Bert的输出,我们VIT里也有特殊的字符*
加一个特殊cls Token 和其他的patch做交互进而输出分类信息,我们相信cls Token可以学习到整张图片的信息,因而我们只需要根据cls Token的信息 做最后的Mlp输出即可
我们举一个例子,把VIT的前向过程走一编
(1)假设我们输入图片X维度为 224×224×3 (长,宽,通道)
(2)将一张图片打成多个图像块(patch)
如果我们使用16×16的图像块大小(patch_size),可以得到多少图像块呢?
意味着有196个图像块,也就是196个token
此时每一个token维度 16×16×3=768
到此我们就把原来的一张图片 224×224×3 变成了 196×768了
(3)经过线性投射层
输入维度是(2)中我们算出来的768
输出维度可以调整,论文中还是768
所以最后经过线性投射层投射之后输出还是为196×768
(4)和特殊cls token合并
合并后输出为197×768
(5)加上位置编码信息
直接加
输出还是为197×768
读完这篇文章,应该明白
transformer对比卷积的优势,劣势?
VIT结构中,如果输入图像是224*224,打成16 *16的patch,头个数12,分析他每一层的形状是什么样子的?