文章目录
- 1. Datasets常见数据集
- 1.1 CIFAR10
- 1.2 Fashion-MNIST
- 1.3 ImageNet
- 2. DataLoader
- 2.1 shuffle
- 2.2 drop_last
1. Datasets常见数据集
Torchvision在 torchvision.datasets 模块中提供了许多内置的数据集,以及用于构建自己的数据集的实用程序类。
官方文档:Datasets
- 所有数据集都是
torch.utils.data.Dataset的子类,即它们实现了__getitem__和__len__方法。- 它们都可以被传递到
torch.utils.data.DataLoader,torch.utils.data.DataLoader可以使用torch.multiprocessing工作器并行加载多个样本。举例:
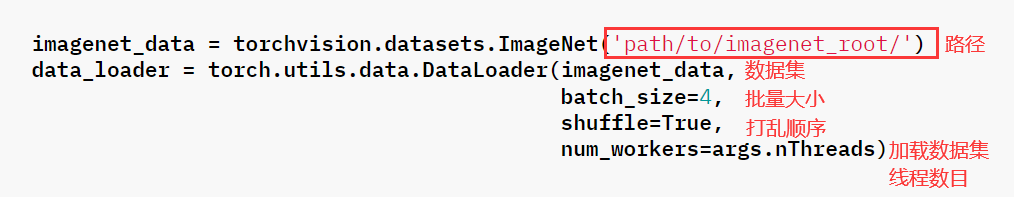
1.1 CIFAR10
数据集地址:CIFAR-10
官方文档:torchvision.datasets.CIFAR10
CLASS torchvision.datasets.CIFAR10(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
主要参数:
- root(string):数据集的根目录,其中目录 cifar-10-batches-py 存在或将保存到(如果下载设置为True)。
- train(bool,可选):如果为True,则从训练集创建数据集,否则从测试集创建。
- transform(可调用,可选):接受PIL图像并返回转换版本的函数/转换。例如, transforms.RandomCrop
- target_transform(可调用,可选):接收目标并对其进行转换的函数/transform。
- download(bool,可选):如果为true,则从Internet下载数据集并将其放在根目录中。如果数据集已下载,则不会再次下载。
CIFAR-10数据集由10个类别的60000张32 x32彩色图像组成,每个类别6000张图像。有50000张训练图像和10000张测试图像。
该数据集分为五个训练批次和一个测试批次,每个批次有10000张图像。测试批次包含从每个类别中随机选择的1000个图像。训练批次包含随机顺序的剩余图像,但是一些训练批次可能包含来自一个类的图像多于来自另一个类的图像。在它们之间,训练批次包含来自每个类的5000个图像。
以下是数据集中的类,以及每个类中的10个随机图像:

代码调用
import torchvision
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
1.2 Fashion-MNIST
数据集地址:Fashion-MNIST
官方文档:torchvision.datasets.FashionMNIST
CLASS torchvision.datasets.FashionMNIST(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
主要参数:
- root(string): FashionMNIST/raw/train-images-idx3-ubyte 和 FashionMNIST/raw/t10k-images-idx3-ubyte 存在的数据集的根目录。
- train(bool,可选):如果为True,则从 train-images-idx3-ubyte 创建数据集,否则从 t10k-images-idx3-ubyte 创建。
- download(bool,可选):如果为True,则从Internet下载数据集并将其放在根目录中。如果数据集已下载,则不会再次下载。
- transform(可调用,可选:接受PIL图像并返回转换版本的函数/转换。例如, transforms.RandomCrop。
- target_transform(可调用,可选):接收目标并对其进行转换的函数/transform。
Fashion-MNIST 是Zalando文章图像的数据集-由60,000个示例的训练集和10,000个示例的测试集组成。每个示例都是28 x28灰度图像,与来自10个类别的标签相关联。

代码调用
import torchvision
from torch.utils.data import DataLoader
train_data = torchvision.datasets.FashionMNIST("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
1.3 ImageNet
数据集地址(Kaggel):ImageNet
官方文档:torchvision.datasets.ImageNet
CLASS torchvision.datasets.ImageNet(root: str, split: str = 'train', **kwargs: Any)
主要参数:
- root(string):ImageNet数据集的根目录。
- split(string,可选):数据集分割,支持 train 或 val 。
- transform(可调用,可选):接受PIL图像并返回转换版本的函数/转换。例如, transforms.RandomCrop。
- target_transform(可调用,可选):接收目标并对其进行转换的函数/transform。
- loader:加载给定路径的图像的函数。
ImageNet最常用的子集是ImageNet大规模视觉识别挑战(ILSVRC)2012-2017图像分类和定位数据集。该数据集涵盖1000个对象类,包含1,281,167张训练图像,50,000张验证图像和100,000张测试图像。此子集在Kaggle上可用。
代码调用(注:ImageNet无法使用torchvision直接下载)
import torchvision
from torch.utils.data import DataLoader
train_data = torchvision.datasets.ImageNet("./dataset", split=train=True, transform=torchvision.transforms.ToTensor())
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
2. DataLoader
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的数据集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True,
num_workers=0,
drop_last=True)
writer = SummaryWriter("logs")
step = 0
for data in train_loader:
imgs, targets = data
writer.add_images("train_data", imgs, step)
step = step + 1
writer.close()
打开命令行
tensorboard --logdir=logs
2.1 shuffle
打乱顺序。


2.2 drop_last
丢弃最后一组不满 batch_size 的数据。
 \
\




![[Makefile] 预宏定义的使用](https://img-blog.csdnimg.cn/90a4c2fb027349008999ec25facbad1a.png)