“隐语”是开源的可信隐私计算框架,内置 MPC、TEE、同态等多种密态计算虚拟设备供灵活选择,提供丰富的联邦学习算法和差分隐私机制
开源项目:
github.com/secretflow
gitee.com/secretflow
以下文章来源于DataFunTalk ,作者洪澄
DataFunTalk.专注于大数据、人工智能技术应用的分享与交流。致力于成就百万数据科学家。定期组织技术分享直播,并整理大数据、推荐/搜索算法、广告算法、NLP 自然语言处理算法、智能风控、自动驾驶、机器学习/深度学习等技术应用文章。
嘉宾:洪澄
洪澄,中国科学院大学博士,目前于阿里巴巴集团安全部双子座实验室担任资深安全专家,主要从事密码学、隐私保护计算相关技术研究,带领团队在EuroCrypt、S&P(Oakland)、USENIX’SEC、SIGMOD、SIGKDD、VLDB等顶级学术会议和期刊上发表论文30余篇,获iDASH国际基因隐私计算大赛一等奖,牵头负责了安全多方计算国际标准IEEE P2842的撰写工作。

分享主题:可证明安全的隐私计算
正文:为什么隐私计算中会需要可证明安全?顾名思义,隐私计算是保护隐私的计算,那么视隐私保护程度的不同,其计算效率也不同。比如,广域网下多方合作,使用LR训练一个这么大的数据集,迭代一次需要多久呢?有的方案需要 100 秒,有的需要 0.3 秒,有的则需要 15 分钟。
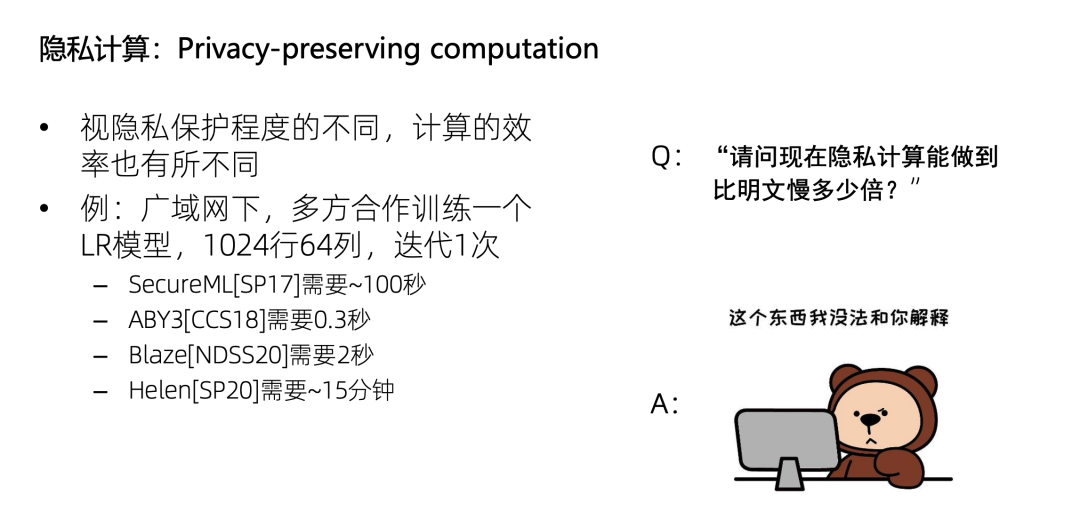
所以如果直接问隐私计算的效率现在能做到比明文慢多少倍,这是没有办法回答的;先描述隐私保护的程度,再描述计算效率,这个描述才有意义。例如,我们列一个坐标轴,X 轴是效率,Y 轴是安全性,只说效率是多少,就像只给出 X 轴的坐标,没有给出 Y 轴的坐标,那是无法判断这个方案的好坏的。
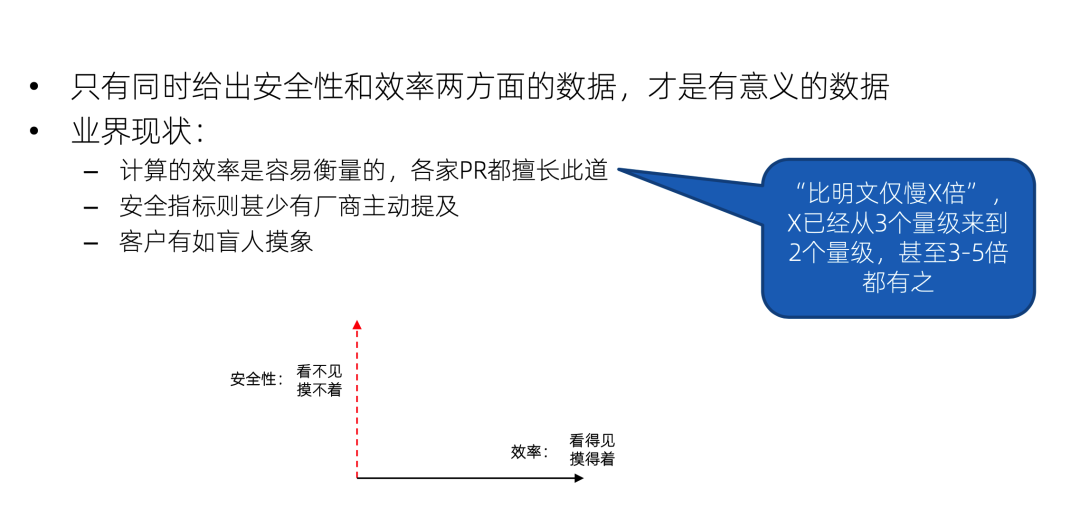
但是因为效率是最容易衡量的,大家都非常擅长 PR 这个X轴,比如能做到仅比明文计算慢多少倍,有的人说三个量级,有的人说两个量级,甚至我最近看到说比明文仅慢 3 到 5 倍的都有。但是Y轴则甚少有厂商主动提及,因为他看不见摸不着也不好描述。那客户就永远只能看到 X 轴,犹如盲人摸象,这就是业界的一个现状。
如何讲清楚一个方案在Y轴中的位置?这就需要可证明安全了。首先要明确定义安全假设,即方案能防御什么样的攻击者,不能防御什么样的攻击者;然后在这一假设下,证明方案面对攻击者的时候,能达到什么样的防护效果,有哪些信息泄露。打个比方,仅说“我的方案是安全的”,这是不够的;更合适的方法是证明“我的方案在双方都是半诚实的假设下,只会泄露行数、列数、建模结果,没有其他信息泄露”。这样就可以方便地在Y轴中找到它的位置了。
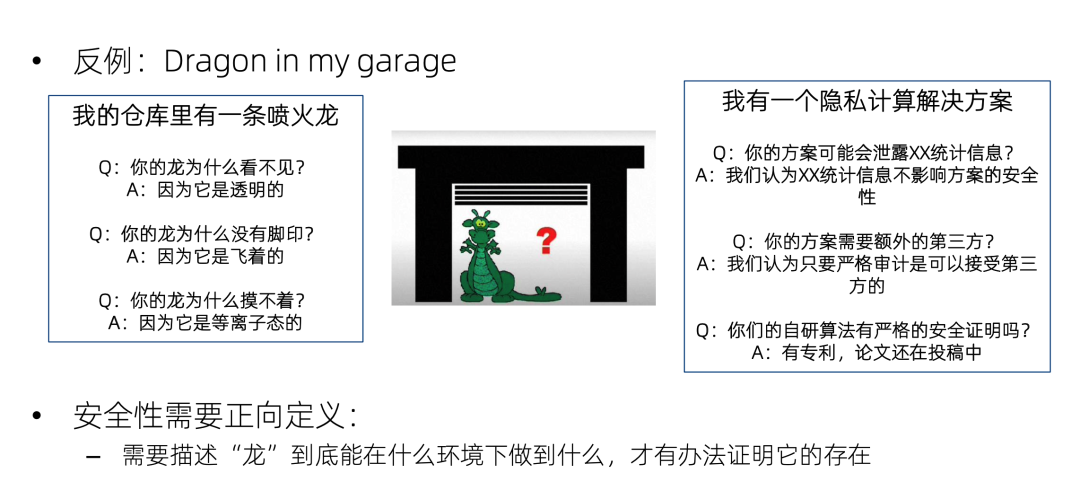
这里有一个很好的反例,就是 dragon in my garage,这是西方的一个寓言:我的仓库里有一条喷火龙。别人问我:你的龙为什么看不见?我说因为它是透明的。又问:你的龙为什么没有脚印?我说因为它是飞着的。又问:你的龙为什么摸不着?我说因为它是等离子态的。只要我没有明确地定义什么是龙,龙能干什么,那么无论你怎么问,我都可以找到一个圆过去的方法。
隐私计算的安全性也是如此,如果不使用可证明安全来正面的论证一个隐私计算方案的安全性,而是被动地等着别人来挑战,那就跟仓库喷火龙一样,无论怎么攻击都可以圆过去。比如别人问我的方案是不是泄露了统计信息?我说这不重要,不影响隐私。又问:方案是不是需要额外的第三方?我说我们会对第三方进行严格的审计,又问:你这个自创的加密算法有安全证明吗?我说为技术保密,暂时不能公布;等等。

注意一个误区,就是要求方案具备可证明安全性,并不等于要求方案具备最高级的安全性。因为最高级安全性的代价太高了,在不需要最高级安全性的场合,完全可以降低安全性以提升效率,也就是减小Y坐标来获得大一点的X坐标。但是不能只说X坐标,而不去说明Y坐标牺牲了多少。可证明安全就是一把尺子,用来对Y坐标进行严格的论证。
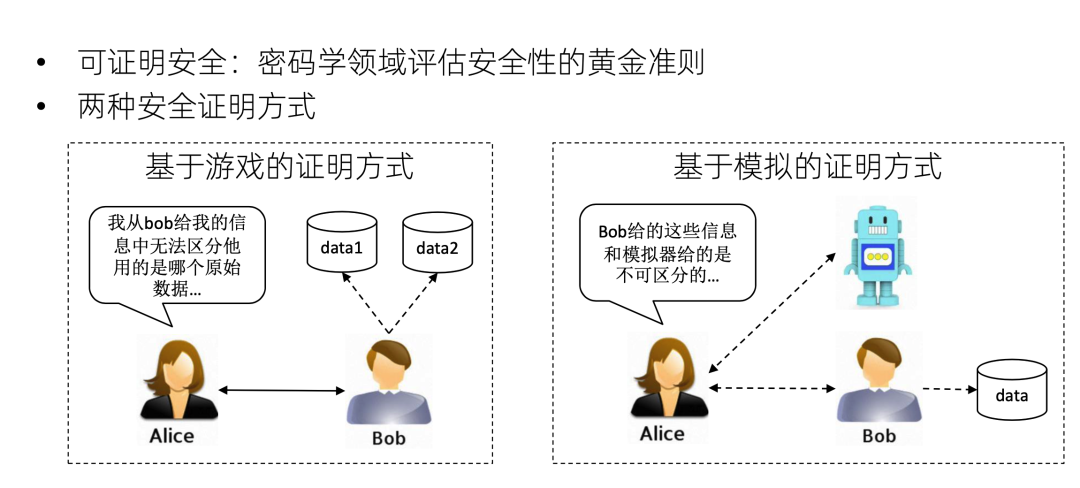
可证明安全是密码学领域评估算法安全性的黄金准则。目前有两种流行的证明方式:第一个是基于游戏的证明方式。通过一个例子来说明什么是基于游戏的证明方式。假设 Alice 是攻击者,Bob是防守者。Bob 跟 Alice 运行一个协议,然后 Bob 挑选两个数据data 1和 data 2 的其中之一。但是 Alice 从这个交互的协议过程中猜不出来 Bob 用的是 data 1 还是 data 2。如果这对任意 data 1 跟 data 2 都成立的话,就可以说这个协议是安全的,因为这可以说明Alice对Bob的原始数据的信息是一无所知的。
第二个是基于模拟的证明方式。假设 Alice 与两方交互。第一个是 Bob,它正在运行着自己的真实数据,和 Alice 跑一个真正的隐私计算协议。另一个是个机器人,是个模拟器,它并没有 Bob 的输入数据,只有整个计算的结果。Alice 跟这个机器人和 Bob 同时进行交互,它感觉不出来哪个是机器人哪个是 Bob。可以看到,这个机器人根本没有用Bob的原始数据,Alice都区分不出来。那说明这个协议确实没有对Alice泄露任何结果之外的信息。
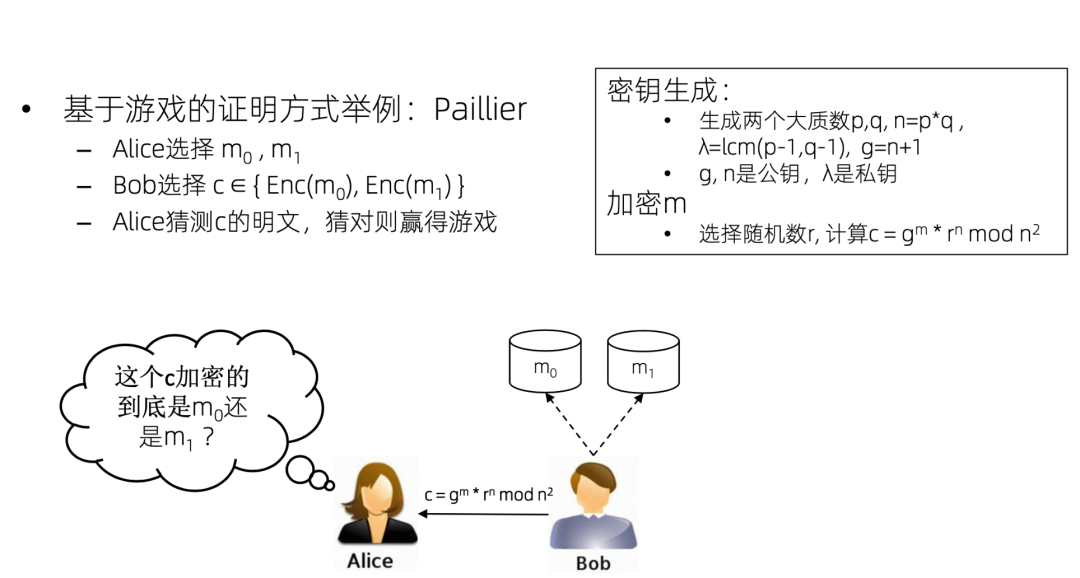
我们通过一个paillier同态加密的例子来理解如何用基于游戏的证明方式来证明paillier是安全的。
假设Alice是攻击者,Alice 可以任选两个数据m0和m1,然后让 Bob 来加密一下这两个数据。Bob 加密了这两个数据,然后从其中任意选了一个,把密文发给 Alice。Alice 去猜到底加密的是 m0 还是 m1。可以看出如果随便猜的话,那成功的概率一定是50%。但是如果Alice能够以大于 50% 的概率猜对的话,那说明paillier算法一定有问题。
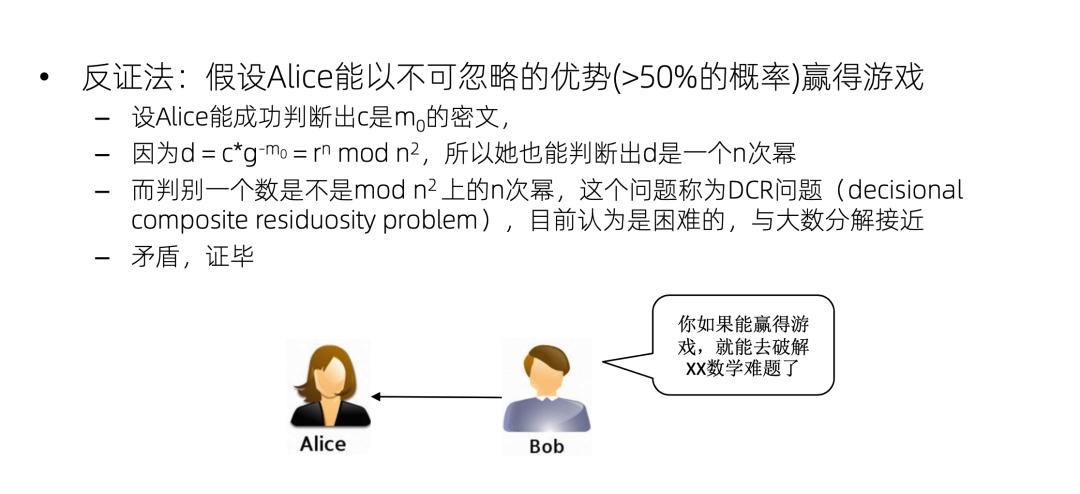
我们来做一个反证,假设Alice可以赢得这个游戏,能以大于 50% 的概率猜对这个到底是 m0 的密文还是 m1 的密文,我们不妨假设它是 m0 的密文,Alice猜对了。那么Alice能够猜出 C 是 m0 的密文,那她就可以把这个 m0 约掉。剩下 r 的 n 次方,也就是 d 是 mod n 平方上的一个 n 次幂,就是Alice可以成功地判断这样一个 n 次幂。但是这个判断叫做 dcr 问题,这个问题是困难的,一般认为它跟大数分解的难度是接近的,所以就产生了矛盾。换句话说,如果 Alice 能够赢得这个游戏,那她就可以破解 dcr 问题。所以 Alice 不能够赢得这个游戏,也就是说 Alice 只能以 50% 的概率随机地猜测,即Paillier算法在dcr假设下是安全的。
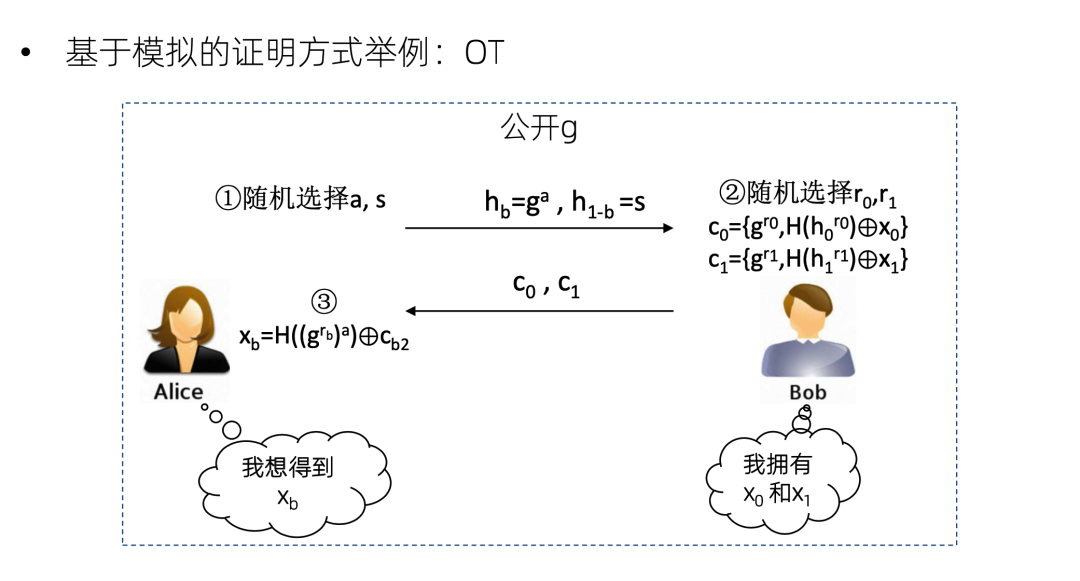
再来看一个基于模拟的证明方式的例子,以一个简单的OT协议为例。Bob 拥有两个数 x0 和x1,Alice 想得到其中一个,但她不想告诉 Bob 她想得到哪一个。协议具体内容是Alice随机选择 s ,然后发送这两个数给 Bob ,然后 Bob 就加密这两个数,发回去。因为Alice有其中一个数的离散对数,所以她可以解密其中一个。但是 Bob 并不知道Alice能解密哪个。我们看如何用基于模拟的证明方式证明这个OT的安全性。
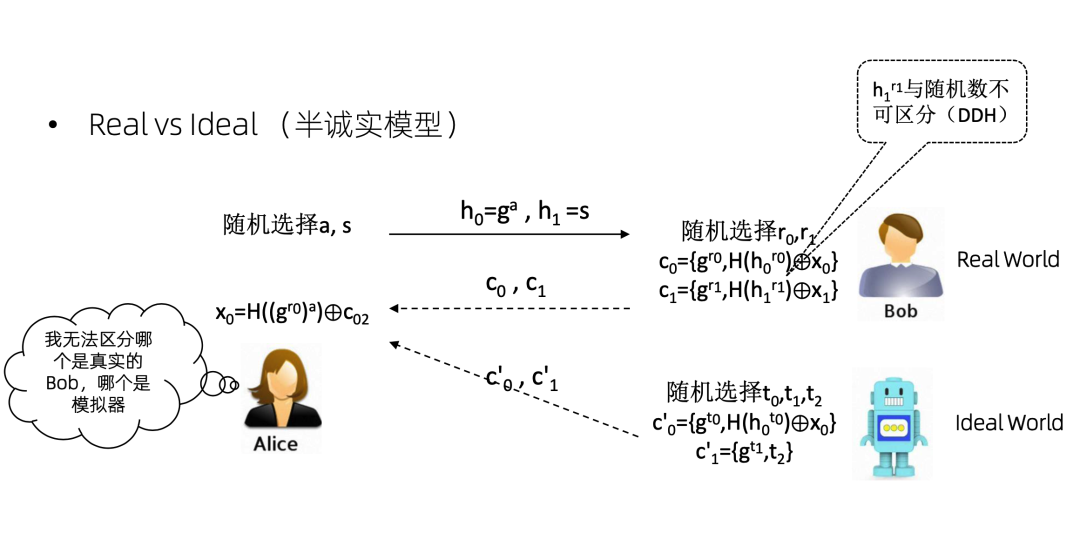
假设Alice是攻击者。假设存在一个机器人和一个 Bob,Bob 是有真实的数据 x0 和 x1 的,但是机器人没有,它只有最终的OT计算结果x0,对 x1 是一无所知的。那么机器人跟 Bob 一样,也和Alice运行一个协议。因为机器人知道 x0,所以它可以把 x0 加密。然后它不知道x1,那就弄一个随机数发过去。Alice拿到这个机器人的两个数,又拿到了 Bob 的两个数。到底哪两个数是 Bob 发来的,哪两个数是模拟器发来的,Alice是区分不出来的。因为这个 h1r1 和随机数是不可区分的。
这个就叫做 real world 和 ideal world,real world 就是真实在发生的事情。ideal world 就是模拟器在做的事情。基于模拟的证明方式就是证明攻击者没办法区分 real word 和 ideal word。当然这只是半诚实模型,如果是恶意模型,那么这个证明会非常的复杂,只能说 do not try this at home,把它交给密码学家去证明。
我们刚才只是证明了一个paillier和OT,那么如何证明整个方案的安全性?
首先,要证明整个方案的每个部分都是安全的,比如加法是安全的,乘法是安全的,relu是安全的。第二步,要判断各个模块的运行方式,如果模块之间是串行运行的话,那么整个方案可以满足可证明安全,因为可证明的安全模块之间是 sequential composable 的。如果不是串行运行,那还需要每个模块都满足 UC 特性才行。这里不做讲解了,对密码学有兴趣的同学可以去看一看。一般的单个建模任务,我们可以认为它是串行的,不需要考虑 UC 的问题。
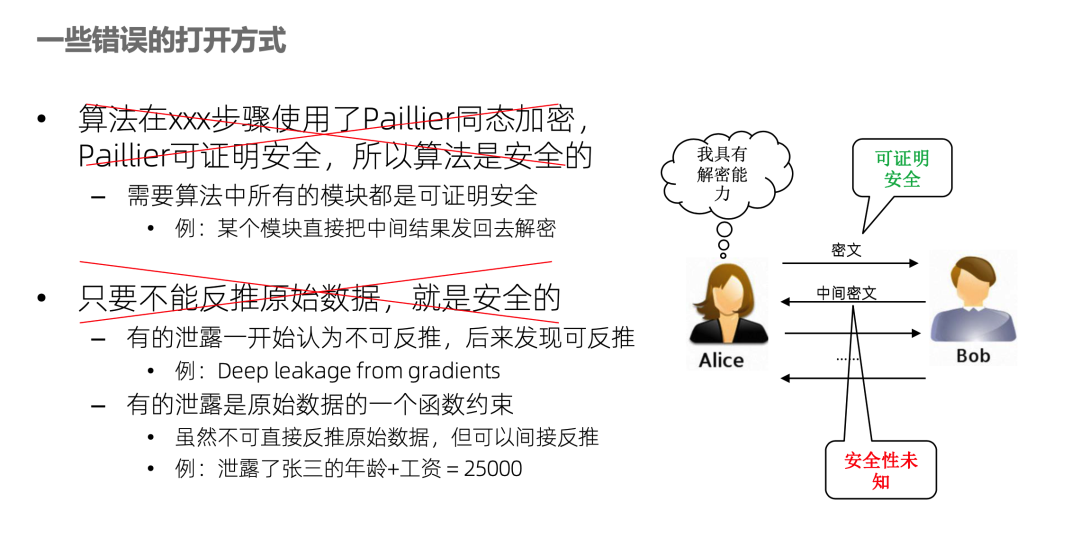
讲一下错误的打开方式,比如有人说我的算法使用了paillier加密,paillier是可证明安全的,所以我的算法是安全的。这个说法肯定是错误的,好比需要大厦的每块砖都是可证明安全的才行,不能说用了一块可证明安全的砖,所以整个大厦都是安全的。例如很多联邦学习算法,中间信息是Alice用 paillier加密发给 Bob,这步是没问题,但 Bob 计算完之后就发回去Alice解密继续做其他的计算。这一步解密产生的信息泄露如果没有论证,其风险就是未知的。
另一个错误的打开方式是只要不能反推原始数据就是安全的。首先一个问题就是很难定义什么叫反推原始数据,不具可操作性。例如要测试哪些反推算法,这是没法穷举的。有的泄露一开始认为不能反推,但过了几年大家发现可以反推了,比如deep leakage from gradients这篇文章,就是联邦学习中的梯度,大家开始认为梯度不是原始数据,传了没问题。但后来有人发现一种攻击算法可以从梯度推出原始数据。那如果再防御一下,给方案打个补丁行不行呢?再保护也只能针对某种特定的攻击,永远是道高一尺,魔高一丈,是不可证明的,永远无法在Y轴中确定方案的位置。只有严谨的正向论证,才是可证明安全。
还有一个可能性就是方案确实没有泄露原始数据,但是泄露了原始数据的一个函数约束。例如攻击者确实推不出张三的年龄,也推不出张三的工资,但是可以推出张三的年龄和工资之和是25,000。可以看出这个结论已经对攻击者很有价值了,如果攻击者将来知道了张三的年龄,工资就出来了;或者攻击者根本就不需要详细数值,只需要知道他的工资是在这个范围就行了。所以仅仅描述“不能反推原始数据”是不够的,还得把泄露的具体函数约束通过可证明的方式勾画出来。
有人说这些密码学证明太难了,还有别的方法可以证明吗?好消息是有,坏消息是也很难,并不比密码学可证明容易。这个方法就是差分隐私。差分隐私跟前面的证明方法有一些区别,也有一些联系。假设Bob有两个数据集,两个数据集的唯一区别是其中一个里面没张三,另一个数据集里面有张三。然后Bob跟 Alice 进行交互。如果对于任意的张三,两个数据集的交互信息的分布都非常接近,说明这一交互过程对 Bob 数据集里所有的行都是保护的,因为Alice连张三在不在里面都不知道,肯定是推不出张三的信息。

如何实现差分隐私?以DP-SGD 为例,SGD是机器学习里面的一个梯度下降算法,它对每份训练数据计算一个梯度,然后把梯度加到模型上去。DP-SGD就是首先把这个梯度裁剪到一个合适的大小,往里面加上一个noise,之后任意一条数据减掉或者加起来都对总体分布区别不大了,所以可以满足差分隐私。DP-SGD计算要比通常的SGD慢一点,因为它要对每条梯度进行裁剪、加噪。在 tensorflow 里面,它集成了相关的算法,这个算法可以非常容易地用于横向分割的联邦学习。
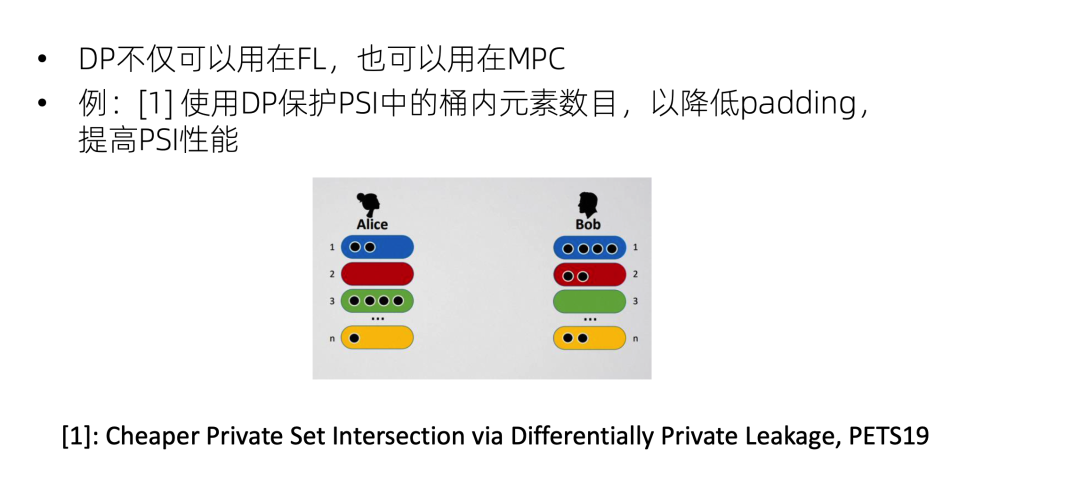
DP也可以用在 MPC,例如PSI隐私求交集,大家可能经常会用到分桶来做 PSI,因为整个全集都跟对方逐个比较性能太低了,所以一般都是分成好几个桶,比如尾号是 1 的一起比一下,尾号是 2 的一起比一下,这样会比较快,也便于并行。但是这样可能会泄露一个信息,就是尾号是 1 的数据量,这是属于ideal world没有的额外信息,因此是需要保护的,一般的 PSI 解决这个问题是通过padding填充,例如Alice原来尾号是 1 的有两个数据,现在把它填到四条,Bob也不知道Alice到底有多少条数据尾号是1。但是padding填充是会影响性能的。PETS上就有一篇工作是引入 DP 来添加padding,这样整体的 PSI 性能就会提升。
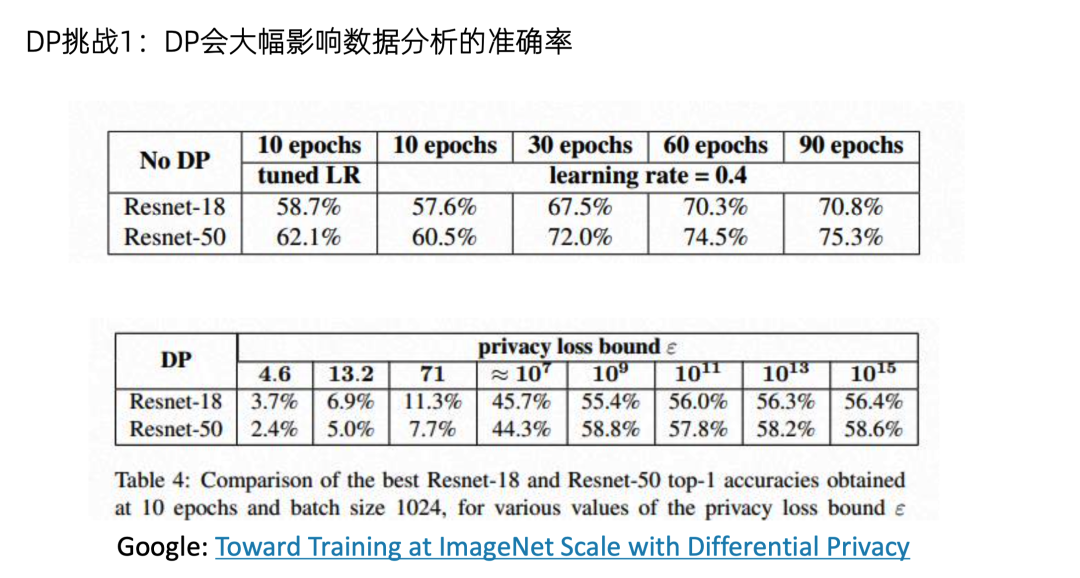
总而言之DP可以用于各种场景,和各种安全技术进行叠加。但是DP也存在一些挑战,首先就是它会大幅影响数据分析的准确率。例如Google的一篇最新的文章,在imagenet上训练一个神经网络。没有 DP 的话,准确率可以达到 60% 到 70%。但是开了 DP 之后,准确率就跌到3%~10%。所以在这种大规模数据建模场景中,如何使用差分隐私又不影响性能,是一个非常有挑战的问题。
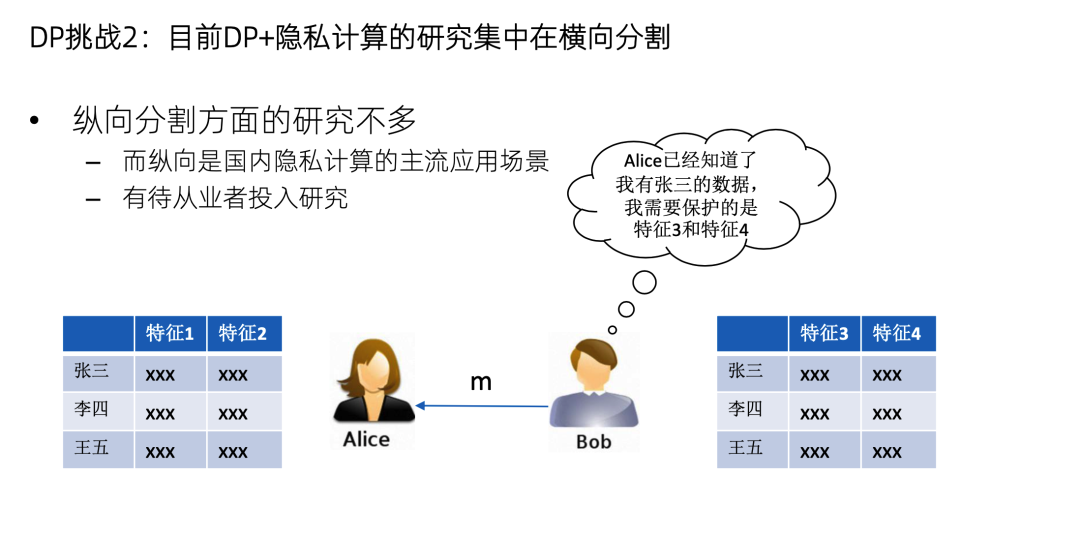
第二个挑战是现在DP的研究成果主要是用在横向分割,因为横向分割和DP-SGD的结合是非常直观的。但是DP在纵向分割方面的应用研究不多。纵向建模是已经把样本对齐了的,也就是Alice 已经知道Bob有张三的数据了,现在保护的目标不是张三的数据在不在,而是张三的特征是多少,这需要新的DP方法,但这方面的研究目前还不多。国内的主要应用场景都是纵向的,所以纵向怎么加DP,有待从业者来投入精力去研究。

总结一下,本文分享了两种可证明安全的方法。第一种是基于游戏或者模拟的密码学证明方式,其目标是刻画信息的整体泄露边界,证明在这个边界之外的信息是绝对不泄露的。第二种是基于差分隐私的证明方式,目标是防止攻击者重识别到单条数据,而不关注数据集整体泄露的信息量多少。这两种都是已经得到了业界广泛认可的安全证明方式。呼吁隐私计算业界能够做好可证明安全,让方案的安全性可以看得见摸得着。今天的分享就到这里,谢谢大家。
🏠 隐语社区:
github.com/secretflow
gitee.com/secretflow
www.secretflow.org.cn (官网)
👇 欢迎关注:
公众号:隐语小剧场
B站:隐语secretflow
邮箱:secretflow-contact@service.alipay.com